Nota
Vertex AI Extensions están en vista previa y sujetos a cambios. Comuníquese con su representante de Google Cloud para obtener información sobre cómo acceder a esta funcionalidad.
Además de usar Vertex AI con MongoDB Vector Search para implementar RAG, puede usar Extensiones de Vertex IA Para personalizar aún más la interacción con Atlas mediante los modelos de Vertex AI. En este tutorial, creará una extensión de Vertex AI que le permitirá consultar sus datos en Atlas en tiempo real mediante lenguaje natural.
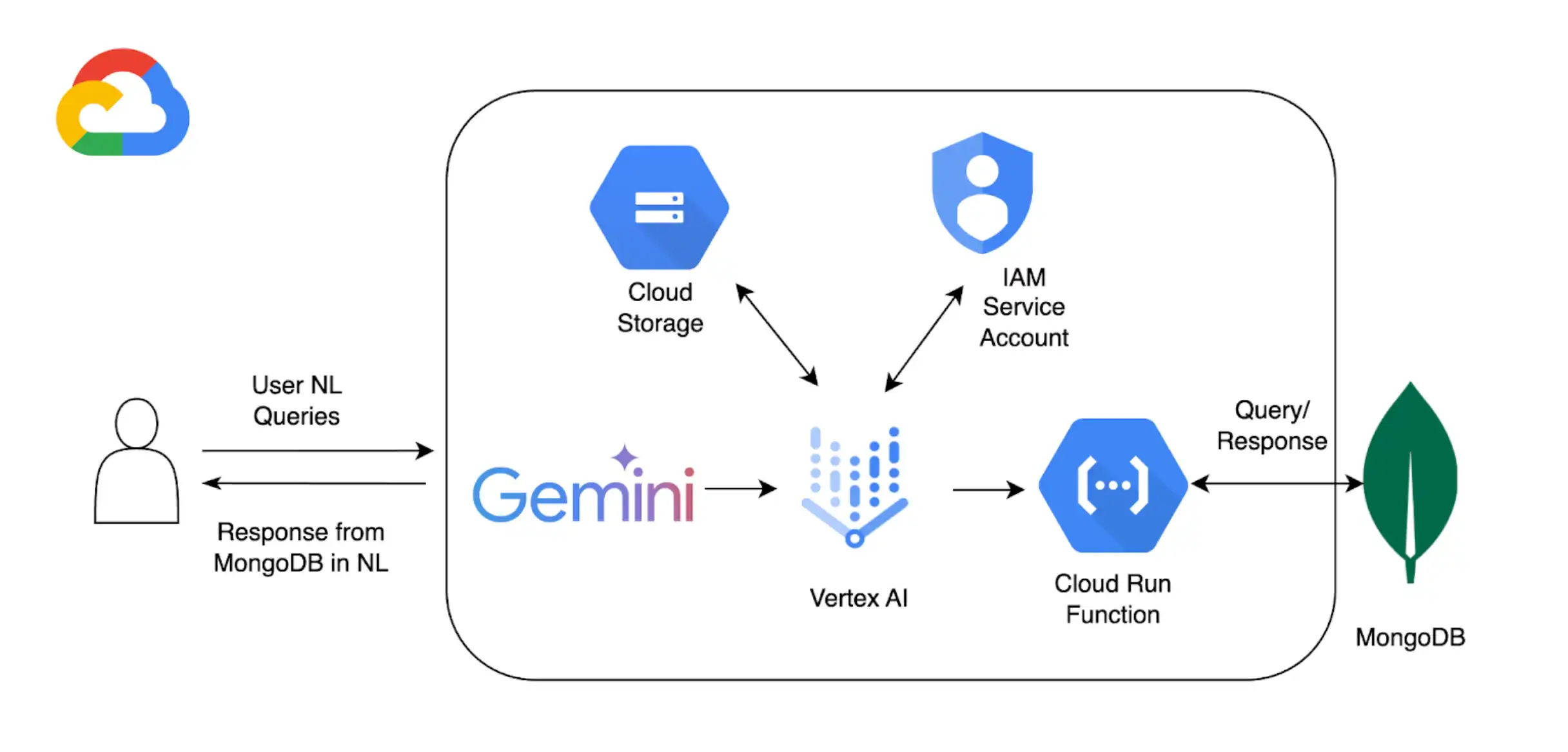
Segundo plano
Este tutorial utiliza los siguientes componentes para habilitar la consulta en lenguaje natural con Atlas:
SDK de Google Cloud Vertex AI para gestionar modelos de IA y habilitar extensiones personalizadas para Vertex AI. Este tutorial utiliza el 1.5 modelo Gemini Pro.
Google Cloud Run para implementar una función que sirva como un endpoint API entre Vertex IA y Atlas.
Especificación OpenAPI 3 para API de MongoDB para definir cómo se asignan las consultas en lenguaje natural a operaciones de MongoDB. Para obtener más información, consulte Especificación OpenAPI.
Vertex AI Extensions para habilitar la interacción en tiempo real con Atlas desde Vertex AI y configurar cómo se procesan las consultas en lenguaje natural.
Google Cloud Secrets Manager para almacenar tus claves API de MongoDB.
Nota
Para obtener instrucciones detalladas sobre el código y la configuración, consulta el repositorio de GitHub de este ejemplo.
Requisitos previos
Antes de empezar, debe contar con lo siguiente:
Una cuenta de MongoDB Atlas. Para registrarte, utiliza Google Cloud Marketplace o Registrarse para una nueva cuenta.
Un clúster de Atlas con el dataset de muestra cargado. Para obtener más información, consulte Crear un clúster.
Un proyectode Google Cloud
Un bucket de almacenamiento en Google Cloud para almacenar la especificación OpenAPI.
Las siguientes API están habilitadas para su proyecto:
API de Cloud Build
nube Functions API
nube Logging API
API de Nube Pub/Sub
Un entorno Colab Enterprise.
Crear una función de Google Cloud Run
En esta sección, creará una función de Google Cloud Run que actúa como punto final de API entre Vertex AI Extension y su clúster Atlas. Esta función gestiona la autenticación, se conecta a su clúster Atlas y realiza operaciones de base de datos según las solicitudes de Vertex AI.
Crear una nueva función.
En la consola de Google Cloud, abre la página Cloud Run y haz clic Write a function.
Configurar la función.
Especifique un nombre de función y una región de Google Cloud donde desea implementar su función.
Seleccione la última versión Python disponible como Runtime.
En el Authentication section, selecciona Allow unauthenticated invocations.
Utiliza los valores por defecto para la configuración restante y luego haz clic en Next.
Para obtener pasos detallados de configuración, consulta la documentación de Cloud Run.
Definir el código de función.
Pega el siguiente código en sus respectivos archivos:
Después de pegar el siguiente código, reemplace <connection-string>
con tu cadena de conexión de Atlas.
Se debe sustituir <connection-string> por la cadena de conexión del clúster Atlas o de la implementación local de Atlas.
Su cadena de conexión debe usar el siguiente formato:
mongodb+srv://<db_username>:<db_password>@<clusterName>.<hostname>.mongodb.net
Para obtener más información, consulta Conectar a un clúster a través de bibliotecas de clientes.
Su cadena de conexión debe usar el siguiente formato:
mongodb://localhost:<port-number>/?directConnection=true
Para obtener más información, consulta Cadenas de conexión.
import functions_framework import os import json from pymongo import MongoClient from bson import ObjectId import traceback from datetime import datetime def connect_to_mongodb(): client = MongoClient("<connection-string>") return client def success_response(body): return { 'statusCode': '200', 'body': json.dumps(body, cls=DateTimeEncoder), 'headers': { 'Content-Type': 'application/json', }, } def error_response(err): error_message = str(err) return { 'statusCode': '400', 'body': error_message, 'headers': { 'Content-Type': 'application/json', }, } # Used to convert datetime object(s) to string class DateTimeEncoder(json.JSONEncoder): def default(self, o): if isinstance(o, datetime): return o.isoformat() return super().default(o) def mongodb_crud(request): client = connect_to_mongodb() payload = request.get_json(silent=True) db, coll = payload['database'], payload['collection'] request_args = request.args op = request.path try: if op == "/findOne": filter_op = payload['filter'] if 'filter' in payload else {} projection = payload['projection'] if 'projection' in payload else {} result = {"document": client[db][coll].find_one(filter_op, projection)} if result['document'] is not None: if isinstance(result['document']['_id'], ObjectId): result['document']['_id'] = str(result['document']['_id']) elif op == "/find": agg_query = [] if 'filter' in payload and payload['filter'] != {}: agg_query.append({"$match": payload['filter']}) if "sort" in payload and payload['sort'] != {}: agg_query.append({"$sort": payload['sort']}) if "skip" in payload: agg_query.append({"$skip": payload['skip']}) if 'limit' in payload: agg_query.append({"$limit": payload['limit']}) if "projection" in payload and payload['projection'] != {}: agg_query.append({"$project": payload['projection']}) result = {"documents": list(client[db][coll].aggregate(agg_query))} for obj in result['documents']: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) elif op == "/insertOne": if "document" not in payload or payload['document'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_one(payload['document']) result = {"insertedId": str(insert_op.inserted_id)} elif op == "/insertMany": if "documents" not in payload or payload['documents'] == {}: return error_response("Send a document to insert") insert_op = client[db][coll].insert_many(payload['documents']) result = {"insertedIds": [str(_id) for _id in insert_op.inserted_ids]} elif op in ["/updateOne", "/updateMany"]: payload['upsert'] = payload['upsert'] if 'upsert' in payload else False if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/updateOne": update_op = client[db][coll].update_one(payload['filter'], payload['update'], upsert=payload['upsert']) else: update_op = client[db][coll].update_many(payload['filter'], payload['update'], upsert=payload['upsert']) result = {"matchedCount": update_op.matched_count, "modifiedCount": update_op.modified_count} elif op in ["/deleteOne", "/deleteMany"]: payload['filter'] = payload['filter'] if 'filter' in payload else {} if "_id" in payload['filter']: payload['filter']['_id'] = ObjectId(payload['filter']['_id']) if op == "/deleteOne": result = {"deletedCount": client[db][coll].delete_one(payload['filter']).deleted_count} else: result = {"deletedCount": client[db][coll].delete_many(payload['filter']).deleted_count} elif op == "/aggregate": if "pipeline" not in payload or payload['pipeline'] == []: return error_response("Send a pipeline") docs = list(client[db][coll].aggregate(payload['pipeline'])) for obj in docs: if isinstance(obj['_id'], ObjectId): obj['_id'] = str(obj['_id']) result = {"documents": docs} else: return error_response("Not a valid operation") return success_response(result) except Exception as e: print(traceback.format_exc()) return error_response(e) finally: if client: client.close()
Implementa la función.
Cambie el nombre de Entry Point a
mongodb_crud.Haz clic en Deploy para implementar la función.
Copie y almacene el punto final HTTPS para activar la función en la nube localmente.
Navegue hasta la página Details de la función y copie y almacene el nombre de la cuenta de servicio utilizada por la función.
Crea una extensión de Vertex IA
En esta sección, creas una Extensión Vertex IA que permite hacer consultas en lenguaje natural sobre tus datos en Atlas utilizando Gemini 1.5 Modelo Pro. Esta extensión utiliza una especificación OpenAPI y la función Cloud Run que creaste para mapear el lenguaje natural a operaciones de base de datos y consultar tus datos en Atlas.
Para implementar esta extensión, se utiliza un notebook interactivo de Python, que permite ejecutar fragmentos de código Python de manera individual. Para este tutorial, crea un cuaderno llamado mongodb-vertex-ai-extension.ipynb en un entorno de Colab Enterprise.
Configura el entorno.
Autentica tu cuenta de Google Cloud y configura el ID del proyecto.
from google.colab import auth auth.authenticate_user("GCP project id") !gcloud config set project {"GCP project id"} Instale las dependencias necesarias.
!pip install --force-reinstall --quiet google_cloud_aiplatform !pip install --force-reinstall --quiet langchain==0.0.298 !pip install --upgrade google-auth !pip install bigframes==0.26.0 Reinicie el kernel.
import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) Establece las variables de entorno.
Reemplace los valores de muestra con los valores correctos que correspondan a su proyecto.
import os # These are sample values; replace them with the correct values that correspond to your project os.environ['PROJECT_ID'] = 'gcp project id' # GCP Project ID os.environ['REGION'] = "us-central1" # Project Region os.environ['STAGING_BUCKET'] = "gs://vertexai_extensions" # GCS Bucket location os.environ['EXTENSION_DISPLAY_HOME'] = "MongoDb Vertex API Interpreter" # Extension Config Display Name os.environ['EXTENSION_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # Extension Config Description os.environ['MANIFEST_NAME'] = "mdb_crud_interpreter" # OPEN API Spec Config Name os.environ['MANIFEST_DESCRIPTION'] = "This extension makes api call to mongodb to do all crud operations" # OPEN API Spec Config Description os.environ['OPENAPI_GCS_URI'] = "gs://vertexai_extensions/mongodbopenapispec.yaml" # OPEN API GCS URI os.environ['API_SECRET_LOCATION'] = "projects/787220387490/secrets/mdbapikey/versions/1" # API KEY secret location os.environ['LLM_MODEL'] = "gemini-1.5-pro" # LLM Config
Descarga la especificación de Open API.
Descargue la especificación de API abierta desde GitHub y cargue el archivo YAML en el depósito de Google Cloud Storage.
from google.cloud import aiplatform from google.cloud.aiplatform.private_preview import llm_extension PROJECT_ID = os.environ['PROJECT_ID'] REGION = os.environ['REGION'] STAGING_BUCKET = os.environ['STAGING_BUCKET'] aiplatform.init( project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET, )
Crea la extensión Vertex AI.
El siguiente manifiesto es un objeto JSON estructurado que configura los componentes clave para la extensión. Reemplaza <service-account> con el nombre de la cuenta de servicio utilizada por tu función Cloud Run.
from google.cloud import aiplatform from vertexai.preview import extensions mdb_crud = extensions.Extension.create( display_name = os.environ['EXTENSION_DISPLAY_HOME'], # Optional. description = os.environ['EXTENSION_DESCRIPTION'], manifest = { "name": os.environ['MANIFEST_NAME'], "description": os.environ['MANIFEST_DESCRIPTION'], "api_spec": { "open_api_gcs_uri": ( os.environ['OPENAPI_GCS_URI'] ), }, "authConfig": { "authType": "OAUTH", "oauthConfig": {"service_account": "<service-account>"} }, }, ) mdb_crud
Validar la extensión.
Valida la extensión e imprime el esquema y los parámetros de la operación:
print("Name:", mdb_crud.gca_resource.name) print("Display Name:", mdb_crud.gca_resource.display_name) print("Description:", mdb_crud.gca_resource.description) import pprint pprint.pprint(mdb_crud.operation_schemas())
Ejecutar consultas de lenguaje natural
En Vertex AI, Extensions haga clic en en el menú de navegación izquierdo. Su nueva extensión, llamada,MongoDB Vertex API Interpreter aparecerá en la lista de extensiones.
Los siguientes ejemplos demuestran dos consultas de lenguaje natural diferentes que puede utilizar para consultar sus datos en Atlas:
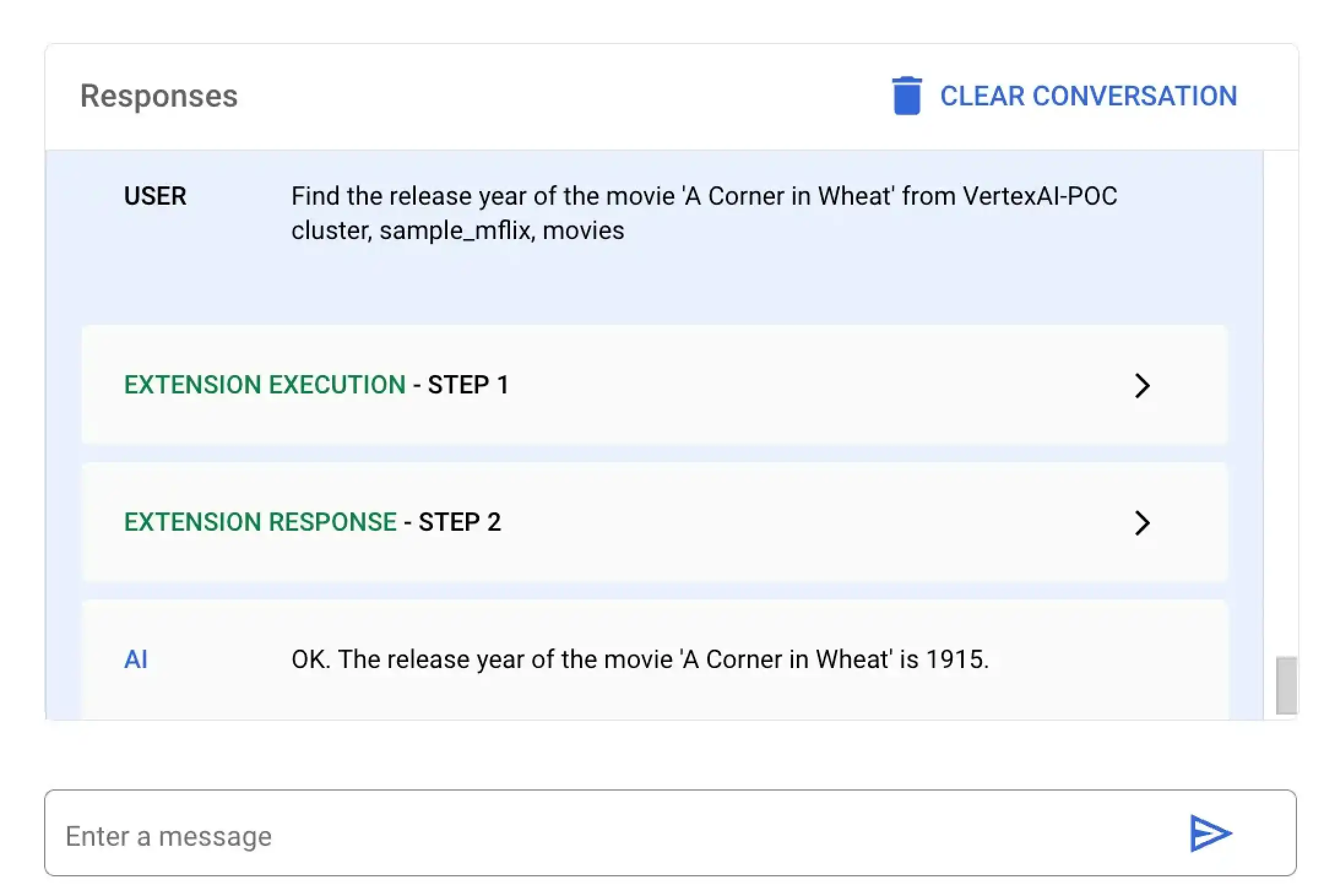
En este ejemplo, le pide a Vertex AI que encuentre el año de estreno de una película específica titulada A Corner in Wheat. Puede ejecutar esta consulta en lenguaje natural utilizando la plataforma Vertex IA o su notebook Colab:
Seleccione la extensión llamada MongoDB Vertex API Interpreter e introduzca la siguiente query en lenguaje natural:
Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies

Pega y ejecuta el siguiente código en mongodb-vertex-ai-extension.ipynb para encontrar la fecha de lanzamiento de una película específica:
## Please replace accordingly to your project ## Operation Ids os.environ['FIND_ONE_OP_ID'] = "findone_mdb" ## NL Queries os.environ['FIND_ONE_NL_QUERY'] = "Find the release year of the movie 'A Corner in Wheat' from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" ### Test data setup os.environ['TITLE_FILTER_CLAUSE'] = "A Corner in Wheat" from vertexai.preview.generative_models import GenerativeModel, Tool fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findOneResponse = fc_chat.send_message(os.environ['FIND_ONE_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findOneResponse)
response = mdb_crud.execute( operation_id = findOneResponse.candidates[0].content.parts[0].function_call.name, operation_params = findOneResponse.candidates[0].content.parts[0].function_call.args ) print(response)
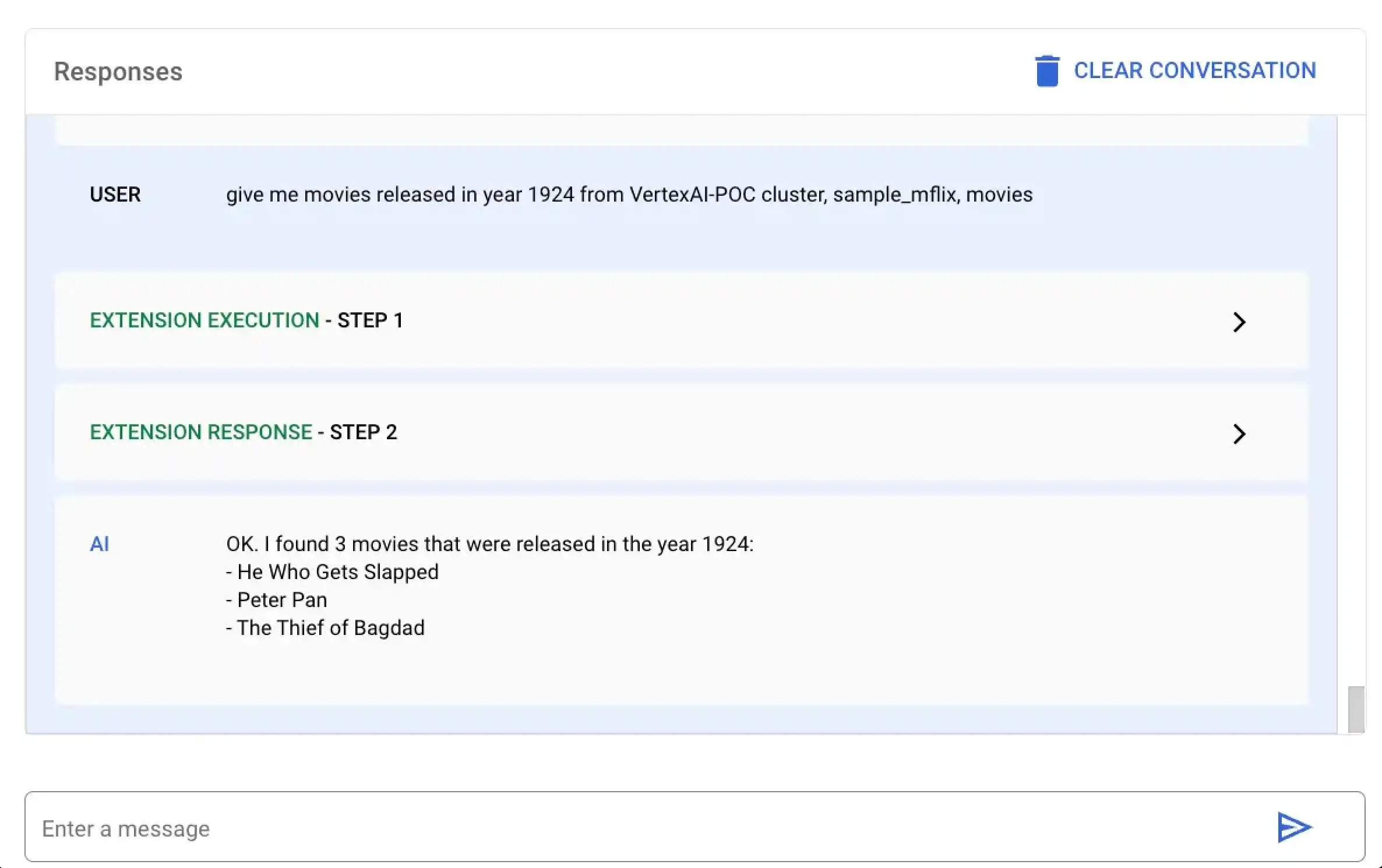
En este ejemplo, le pide a Vertex AI que encuentre todas las películas estrenadas en el año 1924. Puede ejecutar esta query en lenguaje natural utilizando la plataforma Vertex IA o su cuaderno Colab:
Seleccione la extensión llamada MongoDB Vertex API Interpreter e introduzca la siguiente query en lenguaje natural:
give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies

Pegue y ejecute el siguiente código en mongodb-vertex-ai-extension.ipynb para encontrar todas las películas estrenadas en un año específico:
## This is just a sample values please replace accordingly to your project ## Operation Ids os.environ['FIND_MANY_OP_ID'] = "findmany_mdb" ## NL Queries os.environ['FIND_MANY_NL_QUERY'] = "give me movies released in year 1924 from VertexAI-POC cluster, sample_mflix, movies" ## Mongodb Config os.environ['DATA_SOURCE'] = "VertexAI-POC" os.environ['DB_NAME'] = "sample_mflix" os.environ['COLLECTION_NAME'] = "movies" os.environ['YEAR'] = 1924 fc_chat = GenerativeModel(os.environ['LLM_MODEL']).start_chat() findmanyResponse = fc_chat.send_message(os.environ['FIND_MANY_NL_QUERY'], tools=[Tool.from_dict({ "function_declarations": mdb_crud.operation_schemas() })], ) print(findmanyResponse)
response = mdb_crud.execute( operation_id = findmanyResponse.candidates[0].content.parts[0].function_call.name, operation_params = findmanyResponse.candidates[0].content.parts[0].function_call.args ) print(response)