Nota
Atlas está actualmente disponible como base de conocimientos en AWS Regiones ubicadas solo en los Estados Unidos.
Puedes usar MongoDB Atlas como un base de conocimientos para Amazon Bedrock para compilar aplicaciones de IA generativa, implementar generación de recuperación aumentada (RAG) y compilar agentes.
Overview
La integración de la Base de Conocimientos Amazon Bedrock con Atlas habilita los siguientes casos de uso:
Utilice modelos base con MongoDB Vector Search para compilar aplicaciones de IA e implementar RAG. Para empezar, consulta para comenzar.
Habilita la búsqueda híbrida con MongoDB Vector Search y MongoDB Search para tu base de conocimientos. Para aprender más, consulta Búsqueda híbrida con Amazon Bedrock y Atlas.
Empezar
Este tutorial demuestra cómo empezar a usar MongoDB Vector Search con Amazon Bedrock. Específicamente, realizas las siguientes acciones:
Carga datos personalizados en un bucket de Amazon S3.
Opcionalmente, configure un servicio de punto final mediante AWS PrivateLink.
Cree un índice de Búsqueda Vectorial de MongoDB en sus datos.
Crear una base de conocimientos para almacenar datos en Atlas.
Crear un agente que utilice MongoDB Vector Search para implementar RAG.
Segundo plano
Amazon Bedrock es un servicio totalmente gestionado para crear aplicaciones de IA generativa. Permite aprovechar modelos fundacionales (FM) de varias empresas de IA como una única API.
Puedes usar MongoDB Vector Search como Base de Conocimiento para Amazon Bedrock y almacenar datos personalizados en Atlas, además de crear un agente para implementar RAG y responder preguntas sobre tus datos. Para obtener más información sobre RAG, consulta generación de recuperación aumentada (RAG) con MongoDB.
Requisitos previos
Para completar este tutorial, debes tener lo siguiente:
Un clúster Atlas M10+ ejecutando MongoDB versión 6.0.11, 7.0.2, o posterior.
Una cuenta AWS con una clave secreta que contiene credenciales para tu clúster de Atlas.
Acceso a los siguientes modelos de cimentación utilizados en este tutorial:
El AWS CLI y npm deben de estar instalados si planeas configurar un servicio de endpoint AWS PrivateLink.
Cargar datos personalizados
Si aún no tiene un bucket de Amazon S3 que contenga datos de texto, cree un nuevo bucket y cargue el siguiente PDF de acceso público sobre las mejores prácticas de MongoDB:
Descargue el PDF.
Navega a la Guía de mejores prácticas para MongoDB.
Haz clic en cualquiera Read Whitepaper o Email me the PDF para acceder al PDF.
Descargue y guarde el PDF localmente.
Carga el PDF en un bucket de Amazon S3.
Siga los pasos para crear un Bucket S3 . Asegúrese de utilizar un/a Bucket Name descriptivo/a.
Sigue los pasos para subir un archivo a tu Bucket. Selecciona el archivo que contiene el PDF que acabas de descargar.
Configurar un servicio de punto final
Por defecto, Amazon Bedrock se conecta a tu base de conocimientos a través de Internet pública. Para asegurar aún más tu conexión, MongoDB Vector Search admite la conexión a tu Base de Conocimiento a través de una red virtual mediante un AWS PrivateLink servicio de endpoint.
De manera opcional, complete los siguientes pasos para habilitar un servicio de punto final que se conecte a un punto final privado de AWS PrivateLink para su clúster Atlas:
Configura un nodo privado en Atlas.
Siga los pasos para configurar un punto de conexión privado de AWS PrivateLink para su clúster Atlas. Asegúrese de usar un descriptivo VPC ID para identificar su punto de conexión privado.
Para obtener más información, consulte Más información sobre los nodos privados en Atlas.
Configurar el servicio de punto final.
MongoDB y sus socios proporcionan un kit de desarrollo en la nube (CDK) que puede utilizar para configurar un servicio de punto final respaldado por un balanceador de carga de red que reenvía tráfico a su punto final privado.
Sigue los pasos especificados en el Repositorio de CDK en GitHub para preparar y ejecutar el script CDK.
Cree el índice de búsqueda vectorial de MongoDB
En esta sección, configuras Atlas como una base de datos vectorial, también llamada almacén de vectores, al crear un índice de MongoDB Vector Search en tu colección.
Acceso requerido
Para crear un índice de MongoDB Vector Search, debe tener Project Data Access Admin o acceso superior al proyecto Atlas.
Procedimiento
En Atlas, ve a la página Data Explorer de tu proyecto.
Si aún no aparece, se debe seleccionar la organización que contiene el proyecto en el menú Organizations de la barra de navegación.
Si aún no se muestra, seleccione su proyecto en el menú Projects de la barra de navegación.
En la barra lateral, haz clic en Data Explorer en la sección Database.
El Data Explorer se muestra.
En Atlas, vaya a la Search & Vector Search página de su clúster.
Puedes ir a la página de búsqueda de MongoDB desde la opción Search & Vector Search o desde el Data Explorer.
Si aún no aparece, se debe seleccionar la organización que contiene el proyecto en el menú Organizations de la barra de navegación.
Si aún no se muestra, seleccione su proyecto en el menú Projects de la barra de navegación.
En la barra lateral, haz clic en Search & Vector Search en la sección Database.
Si no tienes clústeres, haz clic en Create cluster para crear uno. Para obtener más información, consulta Crear un clúster.
Si el proyecto tiene varios clústeres, se debe seleccionar el clúster que se desea usar en el menú desplegable Select cluster y luego se debe hacer clic en Go to Search.
Aparece la página de Búsqueda y Búsqueda Vectorial.
Si aún no aparece, se debe seleccionar la organización que contiene el proyecto en el menú Organizations de la barra de navegación.
Si aún no se muestra, seleccione su proyecto en el menú Projects de la barra de navegación.
En la barra lateral, haz clic en Data Explorer en la sección Database.
Expanda la base de datos y seleccione la colección.
Haga clic en la pestaña Indexes para la colección.
Haga clic en el enlace Search and Vector Search en el banner.
Aparece la página de Búsqueda y Búsqueda Vectorial.
Se debe iniciar la configuración del índice.
Realiza las siguientes selecciones en la página y luego haz clic en Next.
Search Type | Seleccione el tipo de índice Vector Search. |
Index Name and Data Source | Especifique la siguiente información:
|
Configuration Method | For a guided experience, select Visual Editor. To edit the raw index definition, select JSON Editor. |
IMPORTANTE:
El índice de MongoDB Search se llama default por defecto. Si se mantiene este nombre, el índice será el índice de búsqueda por defecto para cualquier query de MongoDB Search que no especifique una opción de index diferente en sus operadores. Si se crean varios índices, recomendamos mantener una convención de nomenclatura coherente y descriptiva en todos los índices.
Defina el índice de búsqueda vectorial de MongoDB.
Esta definición de índice de tipo vectorSearch indexa los siguientes campos:
embeddingcampo como tipo de vector. Elembeddingcampo contiene las incrustaciones vectoriales creadas con el modelo de incrustación especificado al configurar la base de conocimiento. La definición del índice especifica las1024dimensiones del vector y mide la similitudcosinemediante.bedrock_metadata,bedrock_text_chunkyx-amz-bedrock-kb-document-page-numberson campos del tipo filtro para prefiltrar tus datos. También deberás especificar estos campos en Amazon Bedrock al configurar la base de conocimientos.
Nota
Si creó previamente un índice con el campo de filtro page_number, debe actualizar su definición para usar el nuevo nombre de campo de filtro x-amz-bedrock-kb-document-page-number. Amazon Bedrock ha actualizado el nombre del campo y los índices que usan el nombre antiguo ya no funcionan correctamente con las bases de conocimiento de Amazon Bedrock.
Especifique embedding como campo a indexar y especifique 1024 dimensiones.
Para configurar el índice, haga lo siguiente:
Selecciona Cosine del menú desplegable Similarity Method.
En la sección Filter Field, especifique los campos
bedrock_metadata,bedrock_text_chunkyx-amz-bedrock-kb-document-page-numberpara filtrar los datos.
Pegue la siguiente definición de índice en el editor JSON:
1 { 2 "fields": [ 3 { 4 "numDimensions": 1024, 5 "path": "embedding", 6 "similarity": "cosine", 7 "type": "vector" 8 }, 9 { 10 "path": "bedrock_metadata", 11 "type": "filter" 12 }, 13 { 14 "path": "bedrock_text_chunk", 15 "type": "filter" 16 }, 17 { 18 "path": "x-amz-bedrock-kb-document-page-number", 19 "type": "filter" 20 } 21 ] 22 }
Verifique el estado.
El índice recién creado aparece en la pestaña Atlas Search. Mientras se construye el índice, el campo Status muestra Build in Progress. Cuando se termina de construir el índice, el campo Status muestra Active.
Nota
Las colecciones más grandes tardan más en indexarse. Se recibirá una notificación por correo electrónico cuando el índice haya terminado de construirse.
Crear una base de conocimientos
En esta sección, creará una base de conocimientos para cargar datos personalizados en su tienda de vectores.
Navega a la consola de gestión de Amazon Bedrock.
Inicie sesión en la Consola de AWS. svg class="" height="" width="" role="" aria-hidden="" alt="" viewbox="">
En la esquina superior izquierda, haga clic en el menú desplegable Services.
Haga clic en Machine Learning y, a continuación, seleccione Amazon Bedrock.
Gestiona el acceso al modelo.
Amazon Bedrock no otorga acceso a FMs automáticamente. Si aún no lo has hecho, sigue los pasos para agregar acceso al modelo para Titan Embeddings G1 - Texto y Anthropic Claude V2.1 modelos.
Crea la base de conocimientos.
En la barra de navegación izquierda de la consola de Amazon Bedrock, haz clic en Knowledge Bases.
Haz clic en Create y luego selecciona Knowledge base with vector store.
Especifica
mongodb-atlas-knowledge-basecomo Knowledge Base name.Haga clic en Next.
De forma predeterminada, Amazon Bedrock crea un nuevo rol de IAM para acceder a la base de conocimiento.
Agregar una fuente de datos.
Especifique un nombre para la fuente de datos utilizada por la base de conocimiento.
Ingrese el URI del bucket S3 que contiene su fuente de datos. O bien, haga clic en Browse S3 y encuentre el depósito 3de S que contiene su fuente de datos de la lista.
Haga clic en Next.
Amazon Bedrock muestra modelos de integración disponibles que puedes usar para convertir los datos de texto de tu fuente de datos en integraciones vectoriales.
Seleccione el modelo Titan Embeddings G1 - Text.
Conecta Atlas a la base de conocimientos.
En la sección Vector database, seleccione Use an existing vector store.
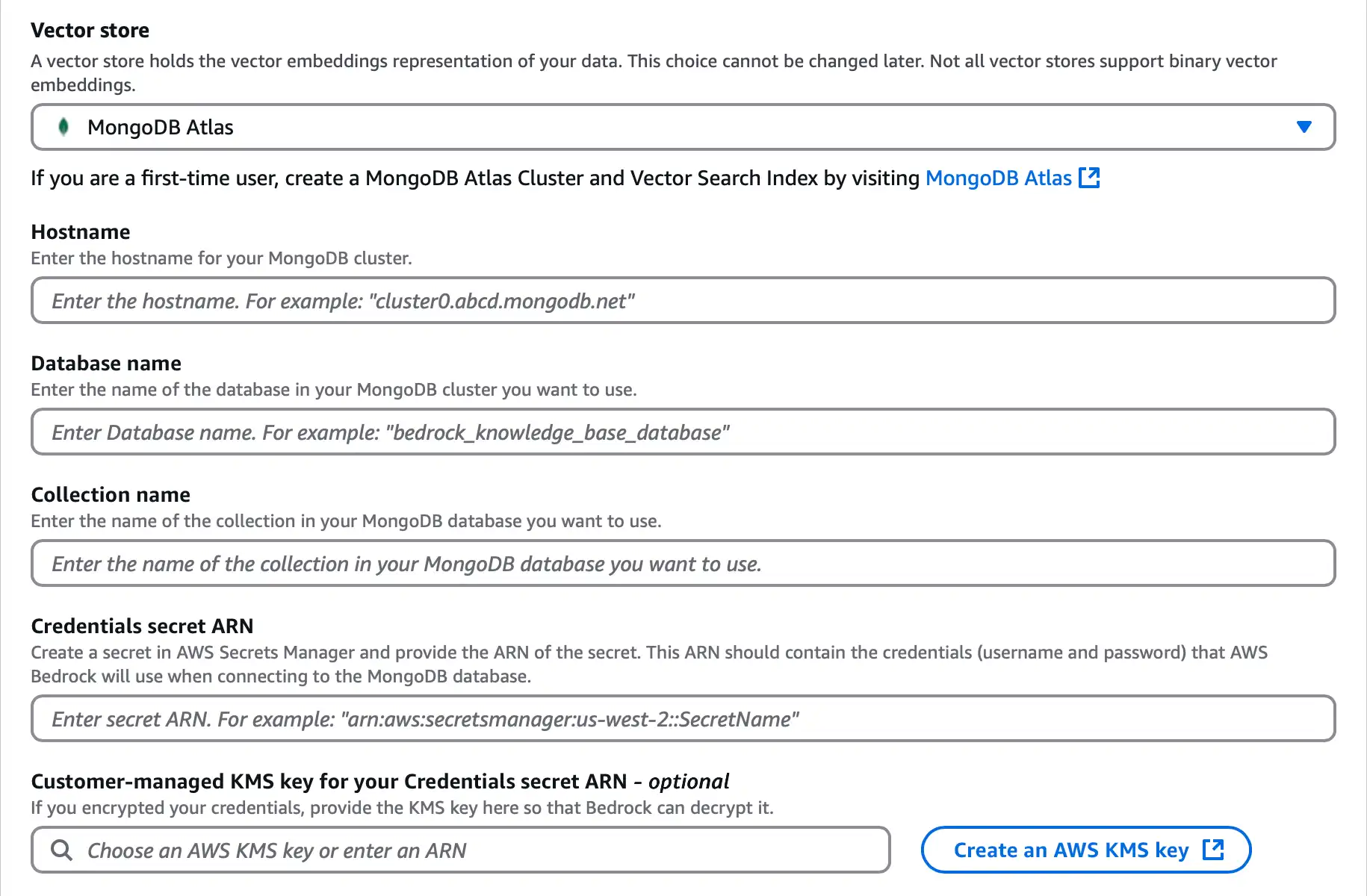
Seleccione MongoDB Atlas y configure las siguientes opciones:
![Captura de pantalla de la sección de configuración del almacén de vectores de Amazon Bedrock.]() haga clic para ampliar
haga clic para ampliarHostnamePara, introduzca la URL de su clúster Atlas, ubicada en su cadena de conexión. El nombre de host tiene el siguiente formato:
<clusterName>.mongodb.net Para el Database name, introduce
bedrock_db.Para el Collection name, introduce
test.Credentials secret ARNPara, ingrese el ARN del secreto que contiene las credenciales de su clúster Atlas. Para obtener más información, consulte los conceptos de AWS Secrets Manager.
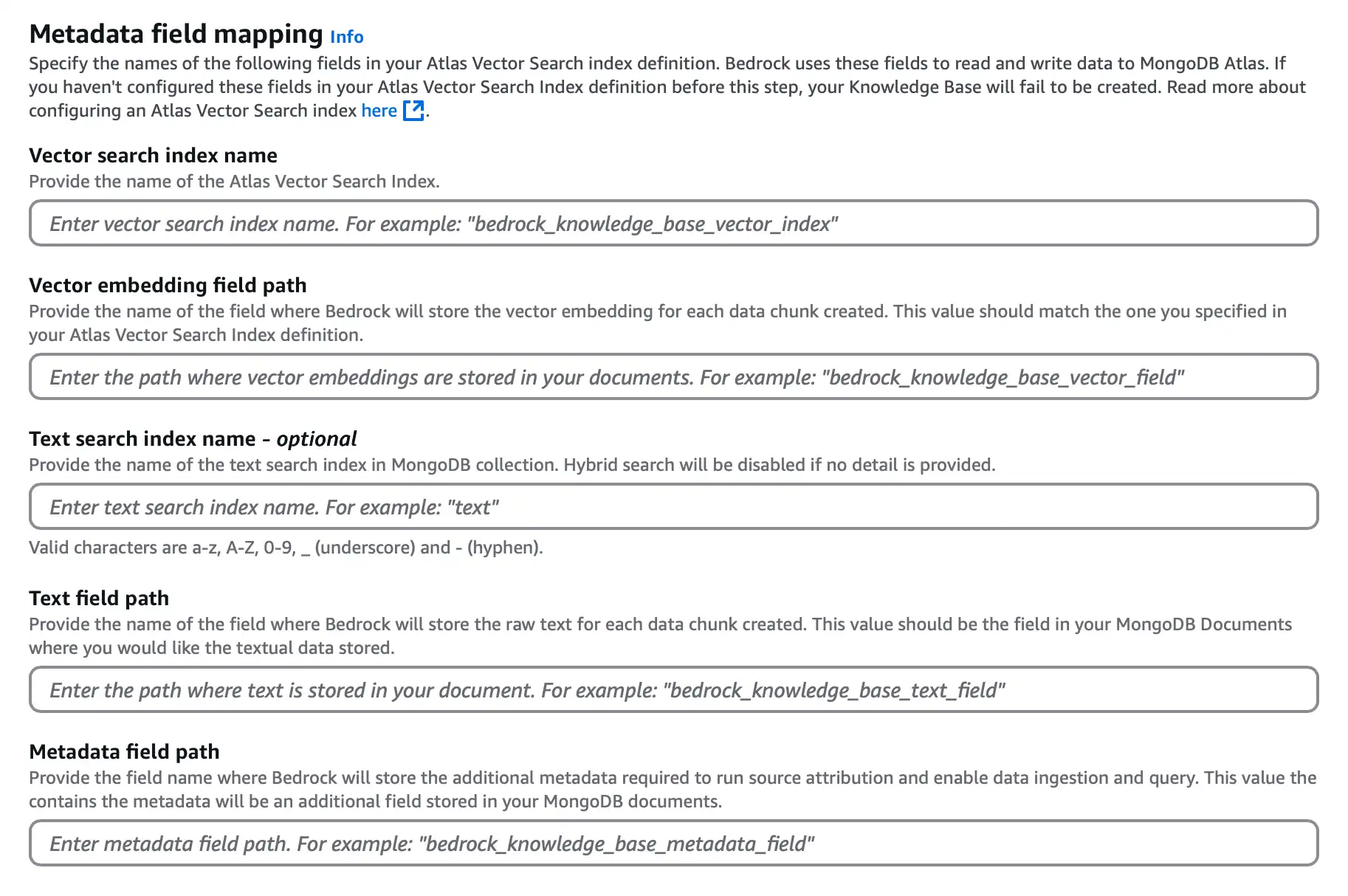
En la sección Metadata field mapping, configura las siguientes opciones para determinar el MongoDB búsqueda vectorial índice y los nombres de campo que Atlas utiliza para incorporar y almacenar tu fuente de datos:
![Captura de pantalla de la sección de configuración de mapeo de campos del almacén vectorial.]() haga clic para ampliar
haga clic para ampliarPara el Vector search index name, introduce
vector_index.Para el Vector embedding field path, introduce
embedding.Para el Text field path, introduce
bedrock_text_chunk.Para el Metadata field path, introduce
bedrock_metadata.
Nota
De forma opcional, puedes especificar el campo Text search index name para configurar la búsqueda híbrida. Para obtener más información, consulta Búsqueda híbrida con Amazon Bedrock y Atlas.
Si configuraste un servicio endpoint, ingresa tu PrivateLink Service Name.
Haga clic en Next.


Sincroniza la fuente de datos.
Después de que Amazon Bedrock crea la base de conocimientos, te solicita que sincronices tus datos. En la sección Data source, selecciona tu fuente de datos y haz clic en Sync para sincronizar los datos desde el bucket S3 y cargarlos en Atlas.
Cuando se complete la sincronización, si está usando Atlas, puede verificar sus incrustaciones vectoriales navegando al espacio de nombres en bedrock_db.test la interfaz de usuario de Atlas.
Compila un agente
En esta sección, implementas un agente que utiliza MongoDB Vector Search para implementar RAG y responder preguntas sobre tus datos. Al provocar este agente, este realiza lo siguiente:
Se conecta a tu base de conocimientos para acceder a los datos personalizados almacenados en Atlas.
Utiliza la Búsqueda Vectorial de MongoDB para recuperar documentos relevantes de tu almacén vectorial según el mensaje dado.
Aprovecha un modelo de chat de IA para generar una respuesta contextual basada en estos documentos.
Complete los siguientes pasos para crear y probar el agente RAG:
Selecciona un modelo y proporciona un aviso.
De forma predeterminada, Amazon Bedrock crea un nuevo IAM rol para acceder al agente. En la sección Agent details, especifique lo siguiente:
En los menús desplegables, selecciona Anthropic y Claude V2.1 como proveedor y modelo de IA utilizado para responder preguntas sobre tus datos.
Nota
Amazon Bedrock no concede acceso a FMs automáticamente. Si aún no lo has hecho, sigue los pasos para añadir acceso al modelo para el Anthropic Claude V2.1 modelo.
Proporcione instrucciones para que el agente sepa cómo completar la tarea.
Por ejemplo, si usas los datos de muestra, puedes pegar las siguientes instrucciones:
You are a friendly AI chatbot that answers questions about working with MongoDB. Haga clic en Save.
Agregar la base de conocimientos.
Para conectar el agente a la base de conocimientos que has creado:
En la sección Knowledge Bases, haga clic en Add.
Selecciona mongodb-atlas-knowledge-base del menú desplegable.
Describa la base de conocimientos para determinar cómo debe interactuar el agente con la fuente de datos.
Si utilizas los datos de muestra, pega las siguientes instrucciones:
This knowledge base describes best practices when working with MongoDB. Haz clic en Add y después en Save.
Pruebe el agente.
Haga clic en el botón Prepare.
Haz clic en Test. Amazon Bedrock muestra una ventana de pruebas a la derecha de los detalles del agente si aún no está mostrada.
En la ventana de prueba, introduce un mensaje. El agente pregunta al modelo, usa MongoDB Vector Search para recuperar documentos relevantes y luego genera una respuesta basada en los documentos.
Si usaste los datos de muestra, introduce el siguiente mensaje. La respuesta generada puede variar.
What's the best practice to reduce network utilization with MongoDB? The best practice to reduce network utilization with MongoDB is to issue updates only on fields that have changed rather than retrieving the entire documents in your application, updating fields, and then saving the document back to the database. [1] Tip
Haz clic en la anotación de la respuesta del agente para ver el fragmento de texto que recuperó MongoDB Vector Search.
Otros recursos
Para solucionar problemas, consulta Solución de problemas de la integración con Amazon Bedrock Base de Conocimiento.