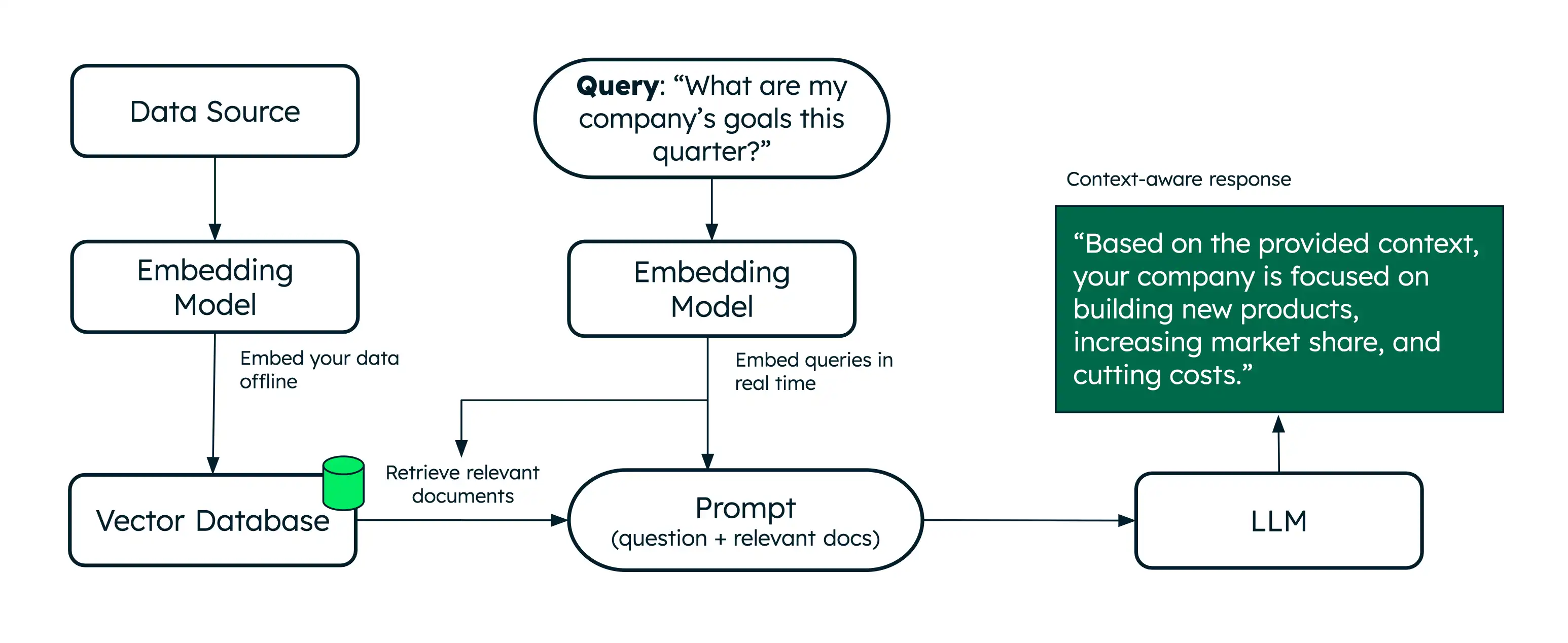
Retrieval-augmented generation (RAG) is an architecture that uses semantic search to augment large language models (LLMs) with additional data, enabling them to generate more accurate responses.
While semantic search retrieves relevant documents based on meaning, RAG takes this a step further by providing those retrieved documents as context to an LLM. This additional context helps the LLM generate a more accurate response to a user's query, reducing hallucinations. Voyage AI provides best-in-class embedding and reranking models to power retrieval for your RAG applications.
To try RAG without writing any code, use the Playground to build an AI chatbot powered by Voyage AI. To learn more, see Chatbot Demo Builder.
Tutorial
The following tutorial demonstrates how to implement RAG with Voyage embeddings.
You can also work with the code for this tutorial by cloning the GitHub repository.
Why use RAG?
When working with LLMs, you might encounter the following limitations:
Stale data: LLMs are trained on a static dataset up to a certain point in time. This means that they have a limited knowledge base and might use outdated data.
No access to additional data: LLMs don't have access to local, personalized, or domain-specific data. Therefore, they can lack knowledge about specific domains.
Hallucinations: When using incomplete or outdated data, LLMs can generate inaccurate responses.
RAG addresses these limitations by adding a retrieval step, typically powered by semantic search, to get relevant documents in real time. Providing additional context helps LLMs generate more accurate responses. This makes RAG an effective architecture for building AI chatbots that deliver personalized, domain-specific question answering and text generation.
What are Vector Databases?
Vector databases are specialized databases designed to store and efficiently retrieve vector embeddings. While storing vectors in memory is suitable for prototyping and experimentation, production RAG applications typically require a vector database to perform efficient retrieval from a larger corpus.
MongoDB has native support for vector storage and retrieval, making it a convenient choice for storing and searching vector embeddings alongside your other data. To learn more, see MongoDB Vector Search Overview.
Next Steps
For additional tutorials, see the following resources:
To learn how to implement RAG with popular LLM frameworks and AI services, see MongoDB AI Integrations.
To build AI agents and implement agentic RAG, see Build AI Agents with MongoDB.