This section contains the following pages, which provide information about our MongoDB Vector Search performance benchmark and how you can use it to test, evaluate, and improve your own vector search performance:
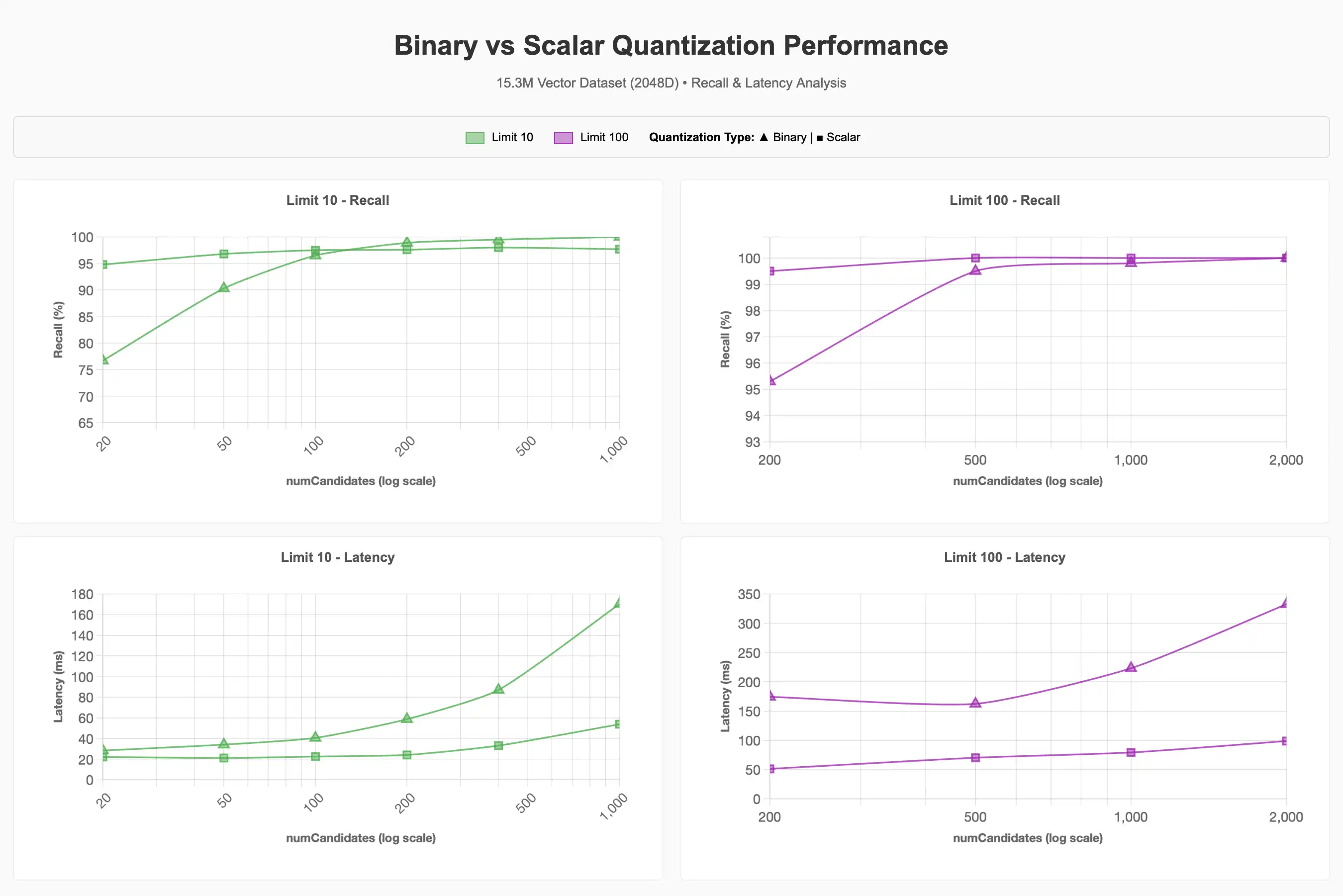
To view the full chart, see the Claude artifact.
How to Use This Benchmark
The primary goal for these pages is to significantly reduce friction for your first vector test at scale (>10M vectors) when evaluating performance for MongoDB Vector Search.
These pages provide a set of initial configurations (embedding model
dimensionality, quantization regime, numCandidates selection, filtering
criteria, Search Node configuration) that you can use to run tests confidently.
You might need to modify your configuration based on the dataset and query
patterns relevant to your use case, as this is only meant to be a starting point.
Reading Recommendations
When reading these pages, we recommend that you focus on the primary concern that is most relevant to your use case. We provide guidance for the following primary concerns: Recall, Cost, and Latency/Throughput.
Use the guidance that is most appropriate for your use case:
Read these sections in the following order:
The following sections in the Benchmark Overview:
The following sections in the Benchmark Results:
Read these sections in the following order:
The following sections in the Benchmark Overview:
The following sections in the Benchmark Results:
Read these sections in the following order:
Changelog
Date | Description |
|---|---|
2025-07-21 | Release of benchmark guide and results demonstrating how MongoDB Vector Search scales
on a 5.5M Multidimensional and 15.3M 2048d Amazon Dataset with Voyage AI's
|