The LLM is the smallest part of a production agent system. This series covers everything else.
Production agent systems share more in common with production ML systems than most teams realize. The model gets the attention. The infrastructure around the model—memory, state, orchestration, observability, evals, security, and the data layer that feeds all of it—determines whether anything actually works.
This series is a guide to that infrastructure. Seven architectural deep dives, each covering one layer of what it takes to build agents that survive past the demo.
The gap between adoption and production
Gartner predicts1 40% of enterprise applications will embed AI agents by the end of 2026, and 40% of agentic AI projects2 will be cancelled by the end of 2027. McKinsey’s 2025 State of AI report3 found 23% of enterprises self-report scaling agents, and roughly 5% in full production.
The gap is not primarily a model quality problem. Enterprise agent projects tend to stall at predictable points: at security review, where there is no industry-standard set of controls for autonomous systems; at cost ceilings, when context windows aren’t compressed intelligently and token budgets run out mid-run; and at evaluation, when teams try to apply deterministic success criteria to non-deterministic systems. Inside organizations the picture is uneven—some teams ship sophisticated agents while others, in the same company, make one-shot LLM calls and label the output as AI. The pattern across these failure modes is consistent: the infrastructure around the model is underbuilt relative to what production deployment requires.
A common pain point we've heard from teams evaluating agent infrastructure: “I have a thousand solutions that require me to put twelve pieces together, then read articles about why it’s not performing.” And from engineering leaders at large enterprise software companies: “Building an agent is a small thing in today’s world with Cursor and Copilot. Post-building that agent is where the real challenge kicks in — how do I monitor, manage, containerize?” That is the problem this series addresses.
What this series covers
The industry has not yet converged on a shared vocabulary for this infrastructure. There is no equivalent to the DORA metrics for software delivery, and no established definition of “production-grade” for autonomous systems. The harness engineering conversation—the idea that the system around the model matters more than the model itself—has gained traction among practitioners at Anthropic4, LangChain, and ThoughtWorks, but it tends to stop at the harness layer. The infrastructure required to run many agents across many teams over time is less well-developed.
Each post in this series covers one component of the harness, or of the infrastructure underneath it.
The agent, the harness, and the platform
The word “agent” gets used loosely. It can refer to the thing that acts, the code that runs the thing, or the entire production system — sometimes in the same sentence. This series separates three things.
An agent has four capabilities: perception (taking in information), planning (reasoning and deciding, handled by the LLM), memory (what the agent knows), and action (tool calls, function calls, API calls). These capabilities run in a loop: perceive, plan, act, observe, perceive again.
An agent system coordinates multiple agents—a supervisor delegating to sub-agents, for example—through shared state and a handoff protocol. Each agent in the system has its own four capabilities.
Figure 1. The anatomy of an agentic workflow, single versus multi-agent workflows.
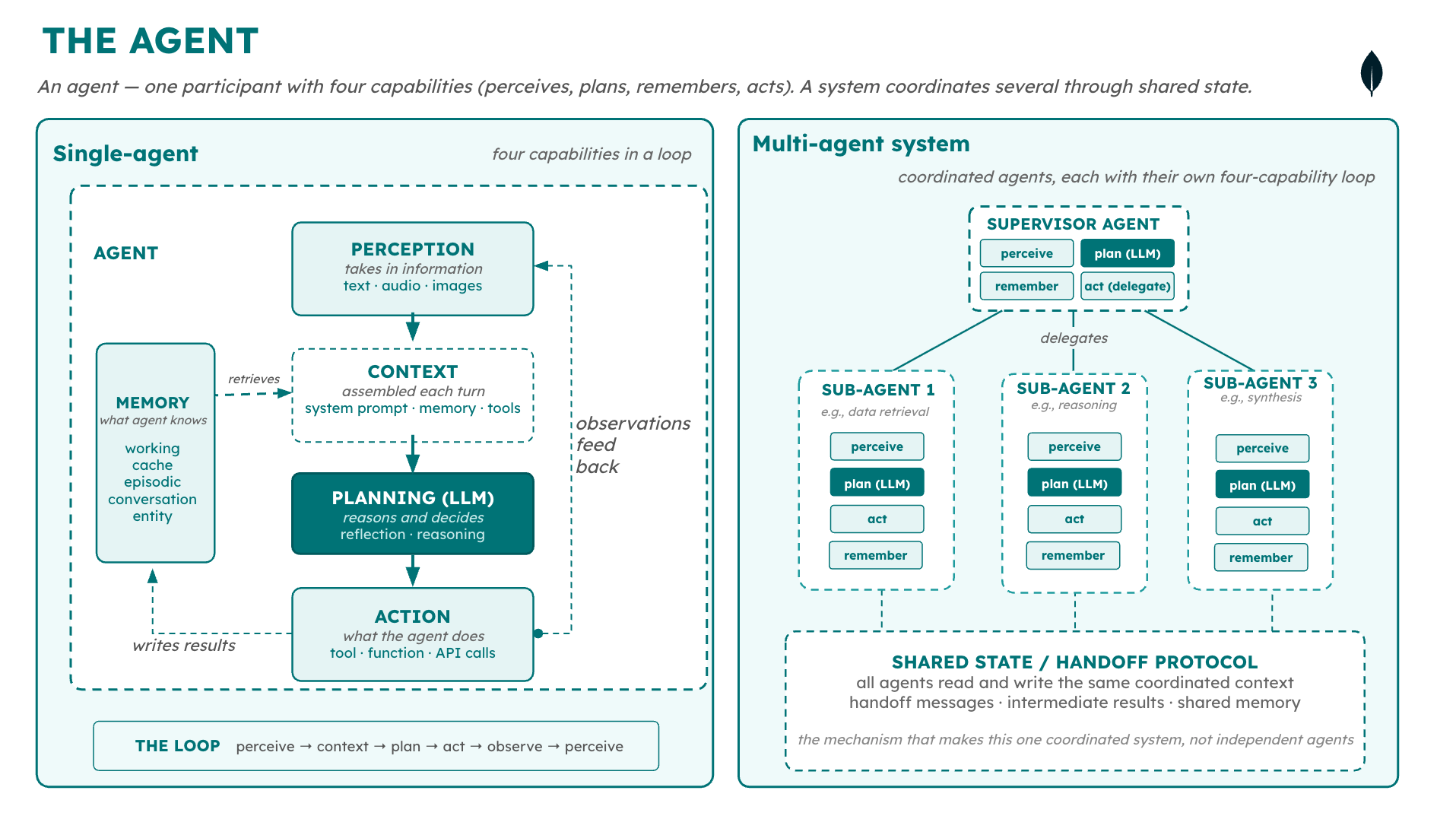
A harness is the code and runtime that manages agent execution: the orchestration loop, tool calls, state, memory, security, observability, evals. A harness can run a single agent or a full agent system. What makes it a harness is that it runs as one coordinated thing.
A platform is the infrastructure that runs many harnesses across many teams over time—durable execution, fleet-wide governance, cross-harness identity, lifecycle management.
Figure 2. A platform enables the execution of many harnesses and agents, across a diverse set of use cases, domains, and frameworks.
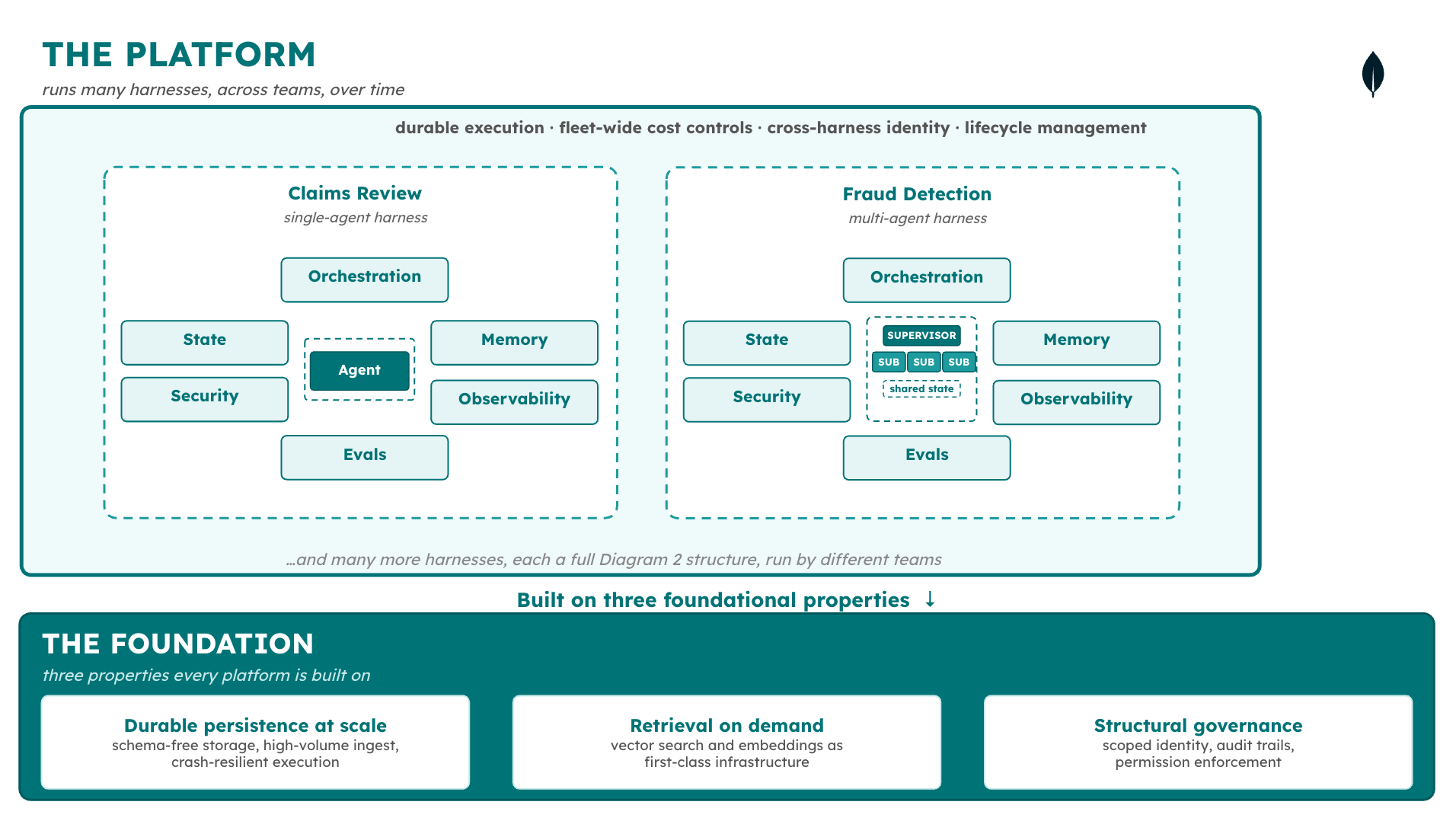
What's inside the harness
A harness is made up of six components, each with its own engineering discipline and failure modes. Part 1 of this series walks through each in detail; here’s a short version:
State and persistence: checkpoints, resume, and crash recovery for long-running agents.
Security and governance: identity propagation, permission scoping, and audit trails. The layer where most enterprise projects stall before production.
Orchestration and tool use: the decision loop that drives the agent and the mechanism that reaches external systems. MCP5 gave agents standardized connectivity; it did not give them coordination, access control, or rate limiting.
Memory: what the agent knows across sessions, and how enterprise data from existing systems becomes usable context.
Observability: not whether the agent responded, but whether its decision was correct, what information it used, and what happened as a result.
Evals: out-of-band measurement of whether the system is good enough to ship. As of early 2026, there is no widely accepted framework for agent eval.
The harness manages the model’s interaction loop. What manages the harness—durable execution across many harnesses, fleet-wide cost controls, governance as a structural property rather than an enterprise pricing tier—is a separate layer, addressed in Part 1 and throughout the series.
Three properties form the foundation every production platform is built on: durable persistence at scale for the schema-free data harnesses generate; retrieval on demand through embeddings and vector search; and structural governance—scoped identity, audit trails, permission enforcement—provided by the platform rather than bolted on per-harness. A platform missing any of these produces harnesses that appear to work in controlled conditions and fail under production load.
The series
Over the past year, the MongoDB Developer Blog has covered agent memory engineering, bounded autonomy, design patterns, and agent skills as standalone topics. This series connects them into a single architectural argument, with each post covering one layer of the harness or the infrastructure underneath it.
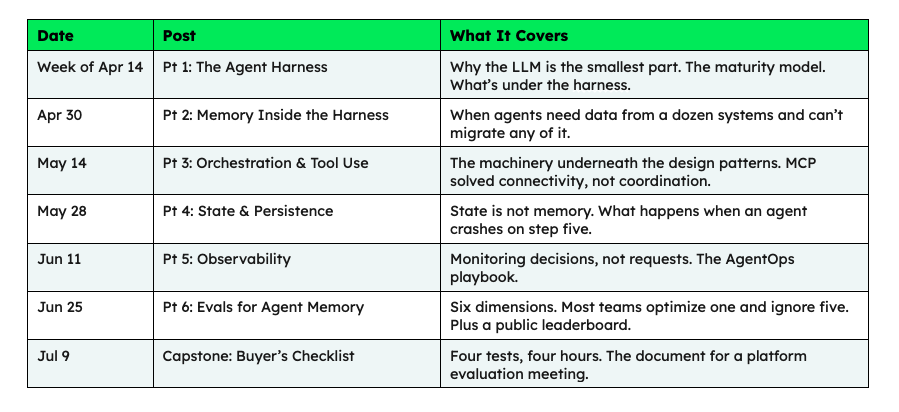
Each post makes the architectural argument for one component. The posts stand on their own—the reader does not need anything beyond them to follow the series.
Foundational reading
The following posts cover territory this series builds on. They are referenced throughout rather than repeated:
“Why Multi-Agent Systems Need Memory Engineering” (Sept 2025)
“The Case for Bounded Autonomy” (Feb 2026)
Conclusion
Enterprises making agent platform decisions now will be making them with framework-level thinking applied to platform-level problems. The decisions themselves will shape infrastructure investment for the next several years—which cloud provider, which identity layer, which database, which observability stack.
This series provides the vocabulary and the evaluation criteria for making those decisions more deliberately. The first post, published this week, covers the harness as an architectural frame: what it contains, where it came from, and why it’s a useful organizing concept for the layers that follow.
Next Steps
Interested in building production-grade agent systems with MongoDB? Check out our resources on agent memory with LangGraph + MongoDB, building AI agents with Atlas Vector Search, and context engineering for enterprise AI.
REFERENCES
1. Gartner predicts: https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025
2. Forty percent of agentic AI projects: https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
3. McKinsey’s 2025 State of AI report: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
4. Anthropic: https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
5. Model Context Protocol (MCP): https://modelcontextprotocol.io
Authors
Mikiko Bazeley, Staff Developer Advocate, MongoDB. Mikiko focuses on agentic AI systems and enterprise agent infrastructure, writing about agent memory engineering, context engineering, and the POC-to-production gap in AI systems.
Ashish Kumar, Technical Fellow, MongoDB. Ashish joined MongoDB over two years ago through the acquisition of Grainite, a database startup he co-founded. Before that, he spent many years at Google, most recently responsible for Google's native database suite—Bigtable, Spanner, Datastore, and Firestore—across Google's own products and Google Cloud. His passion is large-scale distributed systems, and at MongoDB he focuses on architectural improvements across the product stack.
Charlie Xu, Senior Product Manager, AI and Emerging Products, MongoDB. Charlie leads product thinking, customer research, positioning and architectural priorities for MongoDB's agentic AI offerings.