Most multi-agent AI systems fail not because agents can't communicate, but because they can't remember. Production deployments have shown agents tend to duplicate work, operate on inconsistent states, and burn through token budgets, re-explaining context to each other—problems that scale exponentially as you add more agents.
A breakthrough came from context engineering for individual agents: "The right information at the right time" transforms agent effectiveness. But this principle breaks down catastrophically when multiple agents must coordinate without shared memory infrastructure.
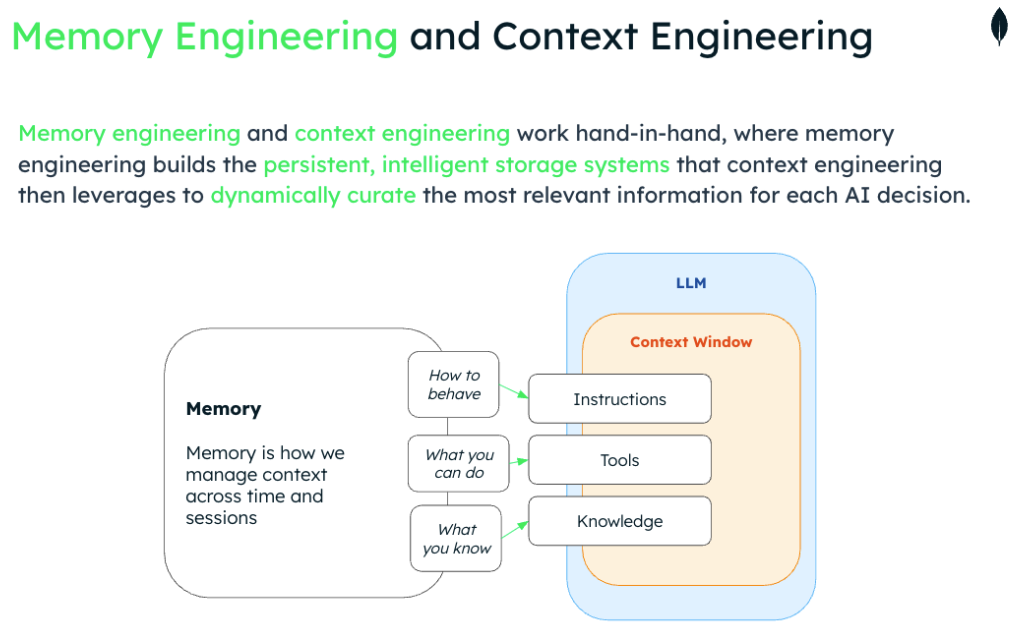
To understand multi-agent coordination, we must first establish our foundation: Agent memory (and memory management) is a computational exocortex for AI agents—a dynamic, systematic process that integrates an agent’s LLM memory (context window and parametric weights) with a persistent memory management system to encode, store, retrieve, and synthesize experiences. Within this system, information is stored as memory units (also called memory blocks)—the smallest discrete, actionable pieces of memory that pair content with rich metadata such as timestamps, strength/confidence, associative links, semantic context, and retrieval hints.
Agent memory is the key term, but the actual discipline that is the focal point of this piece is memory engineering. Memory engineering is the missing architectural foundation for multi-agent systems. Just as databases transformed software from single-user programs to multi-user applications, shared persistent memory systems enable AI to evolve from single-agent tools to coordinated teams capable of tackling enterprise-scale problems. The path from individual intelligence to collective intelligence runs through memory.
The memory crisis in multi-agent systems
Enterprise AI agents face a fundamental architectural mismatch. Without the proper data-to-memory transformation pipeline (aggregation → encoding → storage → organization → retrieval), they're built on stateless large language models but must operate in stateful environments that demand continuity, learning, and coordination. This creates cascading failure modes that become exponentially worse when agents work together.
Individual agent memory failures
Every production agent battles four core memory problems.
Context poisoning occurs when hallucinations contaminate future reasoning, creating a feedback loop of increasingly inaccurate responses.
Context distraction happens when too much information overwhelms the agent's decision-making process, leading to suboptimal choices.
Context confusion emerges when irrelevant information influences responses, while context clash creates inconsistencies when conflicting information exists within the same context window.

Recent research from Chroma reveals an additional critical issue: context rot—the systematic degradation of LLM performance as input length increases, even on trivially simple tasks. Their evaluation of 18 leading models, including GPT-4.1, Claude 4, and Gemini 2.5, demonstrates that performance degrades non-uniformly across context lengths, with models showing decreased accuracy on tasks as basic as text replication when processing longer inputs. This phenomenon is particularly pronounced when needle-question similarity decreases—as needle-question similarity decreases, model performance degrades more significantly with increasing input length—and when distractors are present, creating cascading failures in multi-agent environments where context pollution spreads between agents.
These problems are expensive. According to Manus AI's production data, agents solving complex tasks average 50 tool calls per task with 100:1 input-to-output token ratios, far exceeding simple chatbot interactions. With context tokens costing $0.30-$3.00 per million tokens across major LLM providers, inefficient memory management becomes prohibitively expensive at scale.
Multi-agent coordination failures
When multiple agents operate without proper memory coordination, individual failures become systemic problems. Research by Cemri et al. analyzing over 200 execution traces from popular multi-agent frameworks found failure rates ranging from 40% to over 80%, with 36.9% of failures attributed to inter-agent misalignment issues (Cemri et al., "Why Do Multi-Agent LLM Systems Fail?").

Work duplication occurs constantly—agents repeat tasks without knowing others have already completed them.
An inconsistent state means different agents operate on different versions of reality, leading to conflicting decisions and recommendations.
Communication overhead skyrockets as agents must constantly re-explain context and previous decisions to each other. Most critically, cascade failures spread one agent's context pollution to others through shared interactions.
The coordination chaos this creates is exactly what Anthropic's team encountered in their early development: "Early agents made errors like spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates" (Anthropic, Hadfield et al., 2025).
These coordination failures aren't just inefficient—they're architecturally inevitable without proper memory engineering. This is particularly evident in Deep Research Mode (one of three core application modes alongside Assistant and Workflow modes), where Anthropic found that multi-agent systems excel when properly architected with shared memory infrastructure.
Memory as the foundation for multi-agent coordination
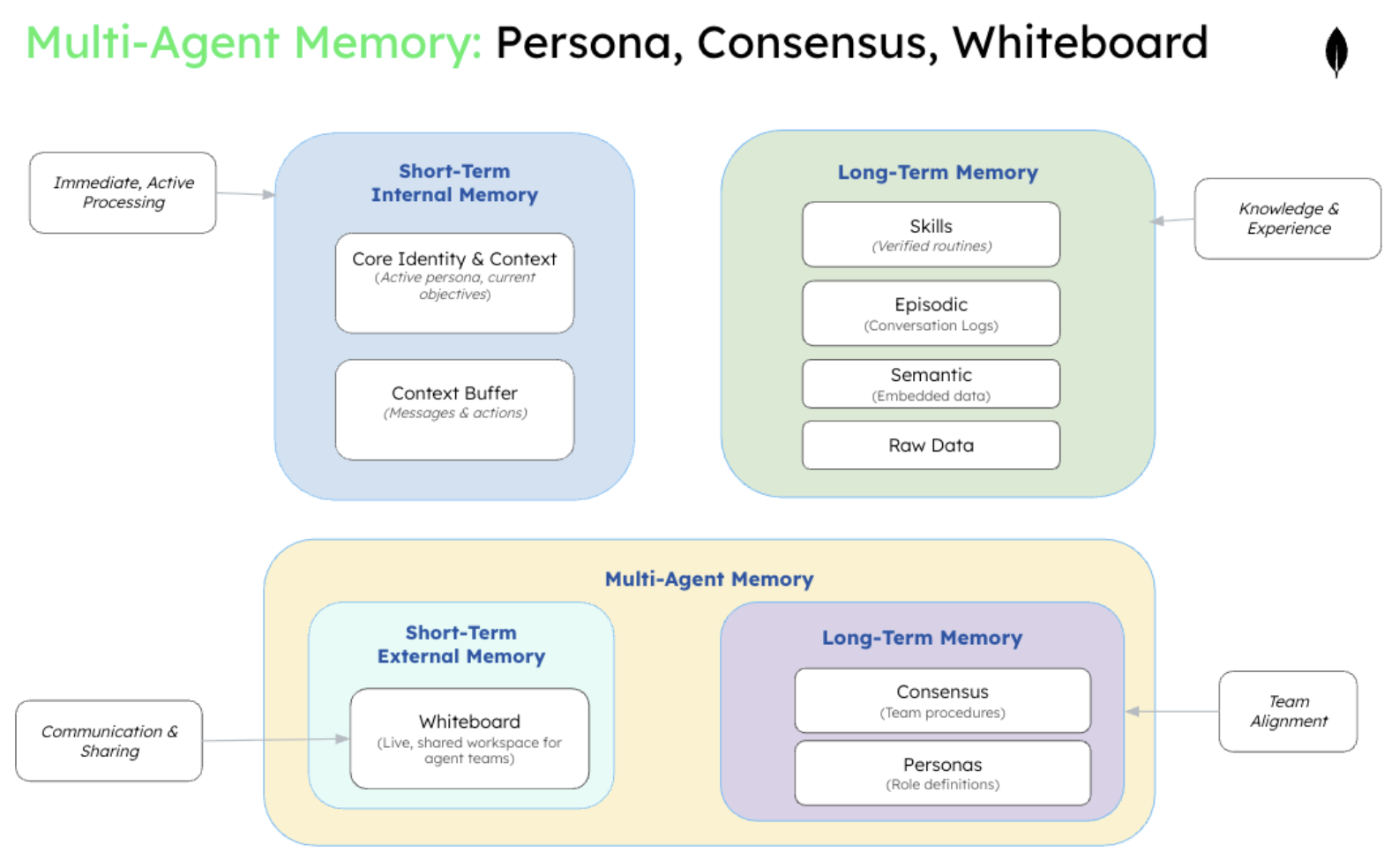
Understanding multi-agent coordination requires understanding how individual agents manage memory. Like humans, every agent operates within a memory hierarchy—from immediate working memory to long-term stored knowledge to shared cultural understanding:
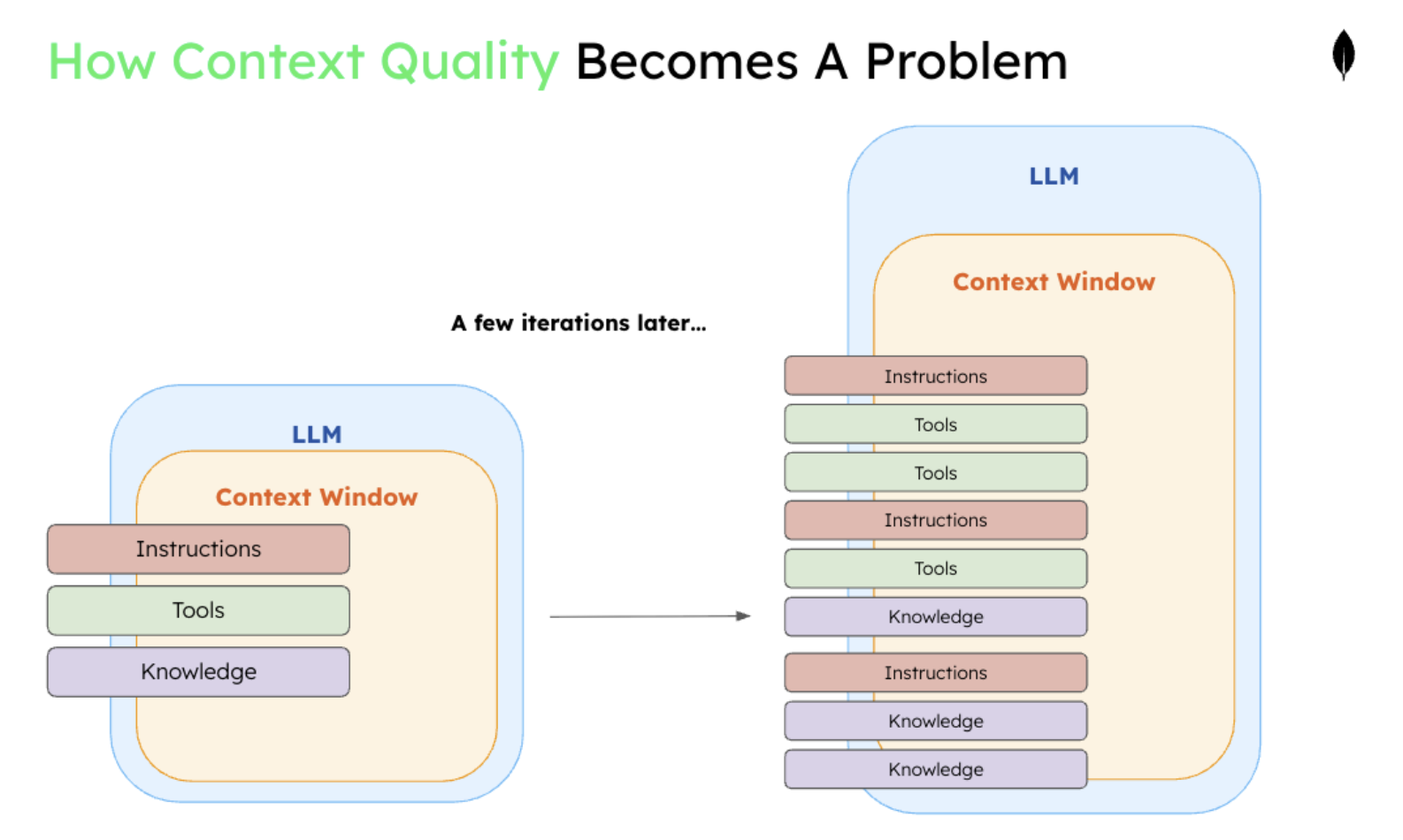
The context window challenge
A context window represents an agent's active working memory—everything it can "see" and reason about simultaneously. This includes system prompts, tool schemas, memory units, recent conversations, files, and tool responses. Even large models with 128K token limits can be exceeded by complex agent tasks, creating performance bottlenecks and cost explosions.
Context engineering emerged as the solution for individual agents: managing what information enters the context window and how it's organized. The goal is getting "the right information at the right time" to maximize agent effectiveness while minimizing costs.
This represents the natural evolution from prompt engineering to context engineering, and now to memory engineering and memory management—the operational practice of orchestrating, optimizing, and governing an agent's memory architecture. While single-agent memory management remains an active area of research, techniques like retrieval-augmented generation (RAG) for semantic knowledge access, hierarchical summarization for compressing conversation history, dynamic context pruning for removing irrelevant information, and external memory systems like MemGPT have dramatically improved individual agent reliability and effectiveness over the past few years.
The multi-agent memory challenge
Research insight: Studies show that memory management in multi-agent systems must handle "complex context data and sophisticated interaction and history information," requiring advanced memory design. These systems need both individual agent memory capabilities and sophisticated mechanisms for "sharing, integrating, and managing information across the different agents" (LLM Multi-Agent Systems: Challenges and Open Problems, Section 4).
Most memory engineering techniques developed to date focus on optimizing individual agents, not multi-agent systems. But coordination requires fundamentally new memory structures and patterns that single-agent systems never needed. Multi-agent systems demand innovations like consensus memory (a specialized form of procedural memory) for verified team procedures, persona libraries (extensions of semantic memory's persona memory) for role-based coordination, and whiteboard methods (implementations of shared memory configured for short-term collaboration)—structures that emerge only when agents work together.
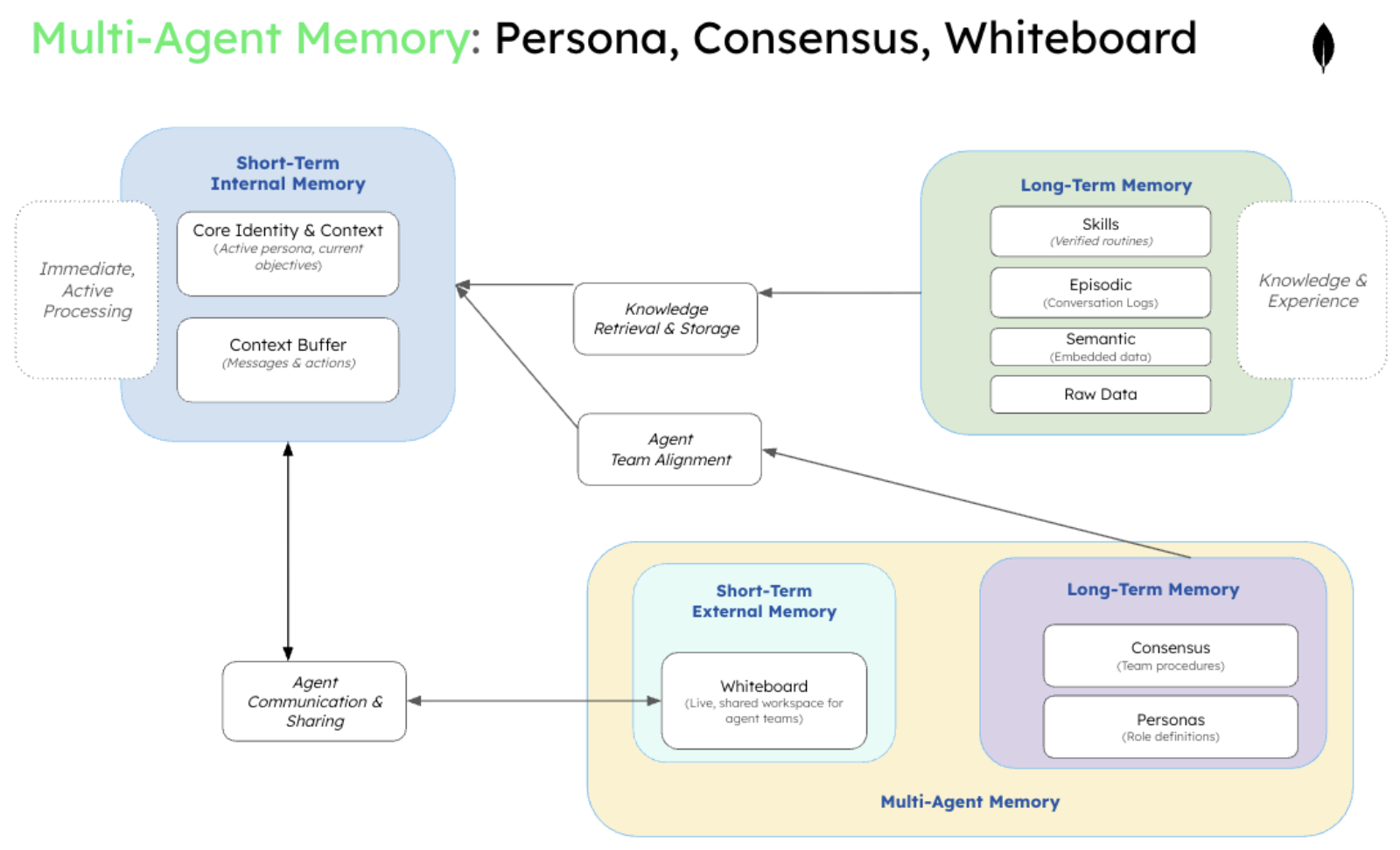
More importantly, multi-agent systems create opportunities to invest in collective memory that improves both current performance and future agent capabilities. Shared external memory enables several critical capabilities:
Persistent state across agent interactions ensures continuity when agents hand off tasks or collaborate on long-running projects.
Atomic operations provide consistent updates when multiple agents need to modify a shared state simultaneously.
Conflict resolution handles situations where agents attempt contradictory updates to the same information.
Performance optimization through caching and indexing reduces redundant operations across agent teams.
Context windows become shared resources requiring careful management.
Core memory alignment ensures agents share essential state and objectives.
Selective context sharing propagates relevant information between agents without overwhelming their individual context windows.
Memory block coordination provides synchronized access to shared memory blocks.
Cost optimization maximizes KV-cache hit rates across agent interactions, reducing the exponential cost growth that kills multi-agent deployments.
The economic impact of smart context management in multi-agent systems isn’t trivial, as Anthropic found in their multi-agent deep research deployment: "In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats" (Anthropic, Hadfield et al., 2025).
Yet when coordination and memory work together, the results are remarkable. Anthropic's research system provides compelling evidence: "We found that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval" (Anthropic, Hadfield et al., 2025). This dramatic improvement shows the multiplicative potential of well-coordinated agent teams.
The 5 pillars of multi-agent memory engineering
Successful multi-agent memory engineering requires architectural foundations that extend beyond single-agent patterns. These five pillars provide the complete framework for scalable multi-agent systems.
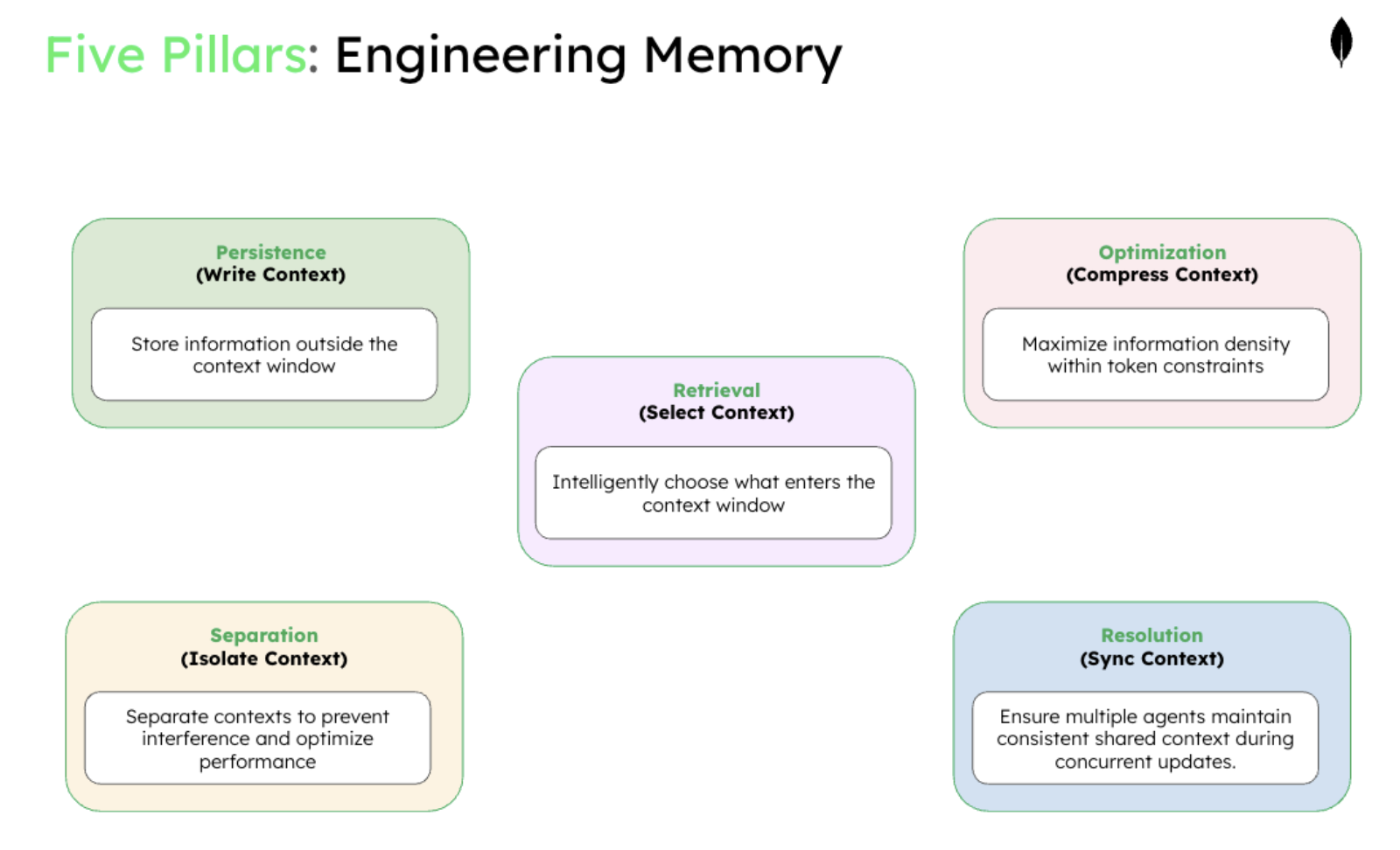
1. Persistence architecture (storage and state management)
Multi-agent systems need sophisticated storage patterns that enable coordinated state management across agent teams.
Memory units structured as YAML or JSON documents in systems like MongoDB provide the foundation for complex multi-agent state management. These memory units—structured containers with metadata and relationships—can be configured as either short-term or long-term shared memory depending on use case requirements.
Shared Todo.md patterns extend the proven individual agent pattern of constantly updated objectives to team-level coordination. A shared objective tracking system ensures all agents work toward aligned goals while maintaining visibility into team progress.
Cross-agent episodic memory captures interaction history and decision patterns between agents. This enables agents to learn from past coordination successes and failures, improving future collaboration effectiveness.
Procedural memory evolution stores workflows and coordination protocols that improve over time. As agent teams encounter new scenarios, they can update shared procedures, creating institutional memory that benefits the entire system.
2. Retrieval intelligence (selection and querying)
Retrieving the right information at the right time becomes exponentially more complex with multiple agents accessing shared memory concurrently.
Embedding-based retrieval uses vector similarity to find relevant cross-agent memory, but must account for agent-specific contexts and capabilities. A customer service agent and a technical support agent need different information about the same customer issue.
Agent-aware querying tailors memory selection based on individual agent capabilities and roles. The system understands which agents can act on specific types of information and prioritizes accordingly.
Temporal coordination manages time-sensitive information sharing. When one agent discovers urgent information, the memory system must propagate this to relevant agents quickly while avoiding information overload for agents working on unrelated tasks.
Resource orchestration coordinates access across multiple knowledge bases, APIs, and external systems. Rather than each agent independently querying resources, the memory system can optimize queries and cache results for team benefit.
3. Performance optimization (compression and caching)
Optimization becomes critical when context costs multiply across agent teams.
Hierarchical summarization compresses inter-agent communication efficiently. Rather than storing complete conversation transcripts between agents, the system can create layered summaries that preserve essential information while reducing storage and retrieval costs.
Selective preservation maintains restoration paths for complex coordination scenarios. Even when compressing information, the system preserves references to original sources, enabling agents to access full context when needed.
Intelligent eviction implements memory lifecycle management through forgetting (gradual strength degradation) rather than deleting, removing redundant information while preserving the coordination state. The system reduces memory strength attributes of outdated memory units while maintaining their structure for potential reactivation.
Cross-agent cache optimization implements shared KV-cache strategies that benefit the entire agent team. When one agent processes information, the results can be cached for other agents with similar contexts, dramatically reducing costs.
4. Coordination boundaries (isolation and access control)
Effective boundaries prevent context pollution while enabling necessary coordination.
Agent specialization creates domain-specific memory isolation. A financial analysis agent and a marketing agent can share high-level project information while maintaining separate specialized knowledge bases.
Memory management agents handle cross-team memory operations as a dedicated responsibility. Rather than every agent managing memory independently, specialized agents can optimize memory operations for the entire team.
Workflow orchestration coordinates context across specialized agent teams. The system understands how information flows between different agent roles and can manage context propagation accordingly.
Session boundaries isolate memory by project, user, or task domain. This prevents information leakage between unrelated workstreams while enabling rich context within specific collaboration boundaries.
5. Conflict resolution (handling simultaneous updates)
Multi-agent systems must gracefully handle situations where agents attempt contradictory or simultaneous updates to shared memory.
Atomic operations ensure that critical memory operations to update memory units happen entirely or not at all. When multiple agents need to perform memory operations on shared memory units simultaneously, atomic operations prevent partial updates that could leave the system in an inconsistent state.
Version control patterns track changes to shared memory over time, enabling agents to understand how information evolved and resolve conflicts based on temporal precedence or agent authority levels.
Consensus mechanisms handle situations where agents have conflicting information about the same topic. The system must determine which information is authoritative and how to propagate corrections to agents operating on outdated knowledge.
Priority-based resolution resolves conflicts based on agent roles, information recency, or confidence levels. A specialized technical agent's assessment might override a general-purpose agent's conclusion about a technical issue.
Rollback and recovery enable the system to revert problematic changes when conflicts create an inconsistent state. If a memory update causes downstream coordination failures, the system can roll back to a known-good state and retry with better conflict resolution.
Measuring multi-agent memory success
Successful multi-agent memory engineering requires understanding what good coordination looks like and how it relates to the five architectural pillars. Rather than focusing on individual agent performance, we must measure emergent behaviors that only appear when agents work together effectively.
What success looks like
Seamless coordination makes multi-agent systems reliable (through consistent access to accurate historical context), believable (through trustworthy inter-agent interactions), and capable (through leveraging accumulated collective knowledge)—the RBC framework that defines successful agent memory implementation.
Collective intelligence emerges when agent teams consistently outperform individual agents on complex tasks. The shared memory system enables capabilities that no single agent could achieve alone.
Cost-effective scaling occurs when adding agents to a team reduces per-task costs rather than multiplying them. Effective memory sharing prevents the exponential cost growth that kills most multi-agent deployments.
Resilient operations maintain continuity when individual agents fail or new agents join the team. The shared memory system preserves institutional knowledge and enables smooth transitions.
Adaptive learning allows agent teams to improve over time through accumulated experience. Shared memory becomes an investment that benefits current and future agent deployments.
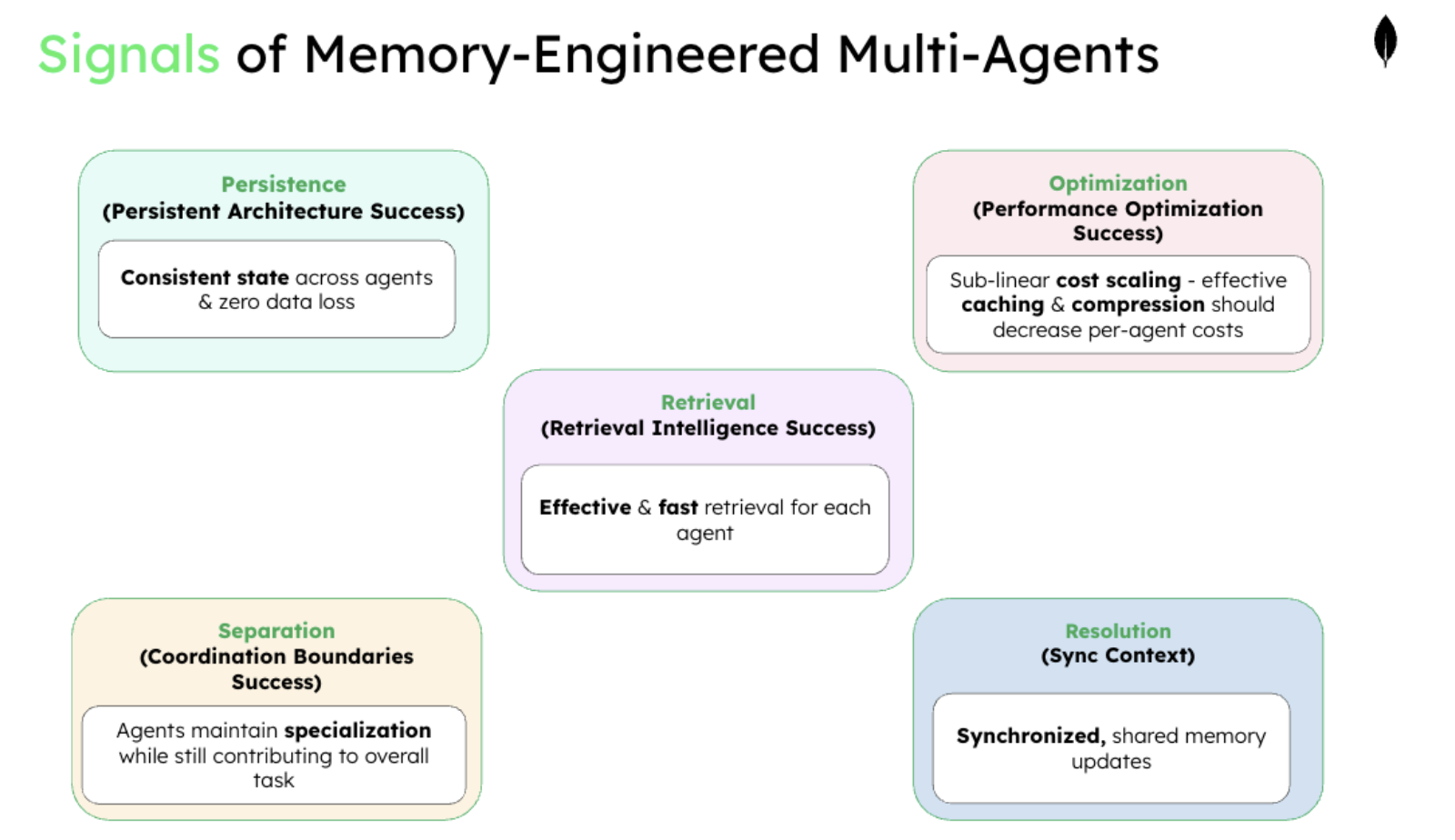
Persistence architecture success shows up as a consistent state across all agents and zero data loss during coordination. You measure this through state synchronization rates and the absence of coordination conflicts caused by inconsistent storage.
Retrieval intelligence success manifests as agents quickly finding exactly the information they need without information overload. Effective retrieval means agents spend time acting rather than searching.
Performance optimization success appears as sub-linear cost scaling as you add agents and tasks. Well-optimized systems show decreasing per-agent costs through effective caching and compression.
Coordination boundaries success prevents context pollution while enabling necessary information sharing. You see this in specialized agents maintaining their expertise while contributing to team objectives.
Conflict resolution success handles simultaneous updates gracefully and maintains system consistency even when agents discover contradictory information. The system should rarely require manual intervention to resolve conflicts.
The ultimate measure
The true test of multi-agent memory engineering is whether agent teams tackle problems that individual agents cannot solve, at costs that make deployment viable. Success means transitioning from "agents helping humans" to "agent teams solving problems independently"—the difference between tools and teammates.
Organizations implementing sophisticated memory engineering will achieve 3× decision speed improvement and 30% operational cost reduction by 2029 (Gartner prediction), demonstrating the strategic value of proper memory architecture.
The path forward
Memory engineering represents the missing infrastructure layer for production multi-agent systems. Just as relational databases enabled the transition from single-user desktop applications to multi-user web applications, shared memory systems enable the transition from single-agent tools to multi-agent intelligence.
The companies succeeding with AI agents today have figured out memory architecture, not just prompt engineering. They understand that agent coordination requires the same foundational infrastructure thinking that built the modern web: persistent state, atomic operations, conflict resolution, and performance optimization.
Research validates this approach: Enterprises implementing proper memory engineering achieve 18% ROI above cost-of-capital thresholds (IBM Institute for Business Value), while systems without memory architecture continue to struggle with the coordination failures that plague 40-80% of multi-agent deployments.
Key takeaways
Multi-agent systems fail because of memory problems, not communication problems. The real issue isn't that agents can't talk to each other—it's that they can't remember and coordinate state effectively.
Memory engineering is the key differentiator for production multi-agent systems. Companies succeeding with AI agents have figured out memory architecture, not just prompt engineering.
Individual agent memory patterns extend naturally to multi-agent coordination. The same principles (write, select, compress, isolate) that solve single-agent context problems solve multi-agent coordination problems.
Shared external memory is essential infrastructure. Just like databases enabled web applications to scale, shared memory systems enable AI agents to coordinate at enterprise scale.
To explore memory engineering further, start experimenting with memory architectures using MongoDB Atlas or review our detailed tutorials available at AI Learning Hub.