The harness comprises six components around the model. The layer underneath them is what turns a harness into a platform.
In Part 0 of this series—“Designing an Agentic Platform: The Infrastructure That Makes Agents Work”—we argued that the LLM is the smallest part of a production agent system. This post walks through the other parts: the six components that make up the harness, and the infrastructure layer underneath that determines whether any of the system survives contact with production.
These components—state and persistence, security and governance, orchestration and tool use, memory, observability, and evals—are the subject of the rest of this blog series. This post defines each component, walks through the problem they solve (and why they are non-trivial), and then frames the debate the industry is currently having about where the engineering value lives.
The lesson from MLOps
The Sculley diagram
In 2015, a team at Google published a diagram that changed how the industry thought about machine learning systems. The diagram showed ML code as a tiny black box at the center of a vast infrastructure: data collection, feature extraction, serving, monitoring, configuration, and a dozen other systems that had nothing to do with the model itself. The paper—“Hidden Technical Debt in Machine Learning Systems” by Sculley et al.¹—became one of the most cited in the field, and the diagram became the founding image of MLOps. It took the ML community years to internalize the lesson: the model is the easy part.
Figure 1. The famous MLOps diagram that encapsulated the real state of production machine learning for most teams.
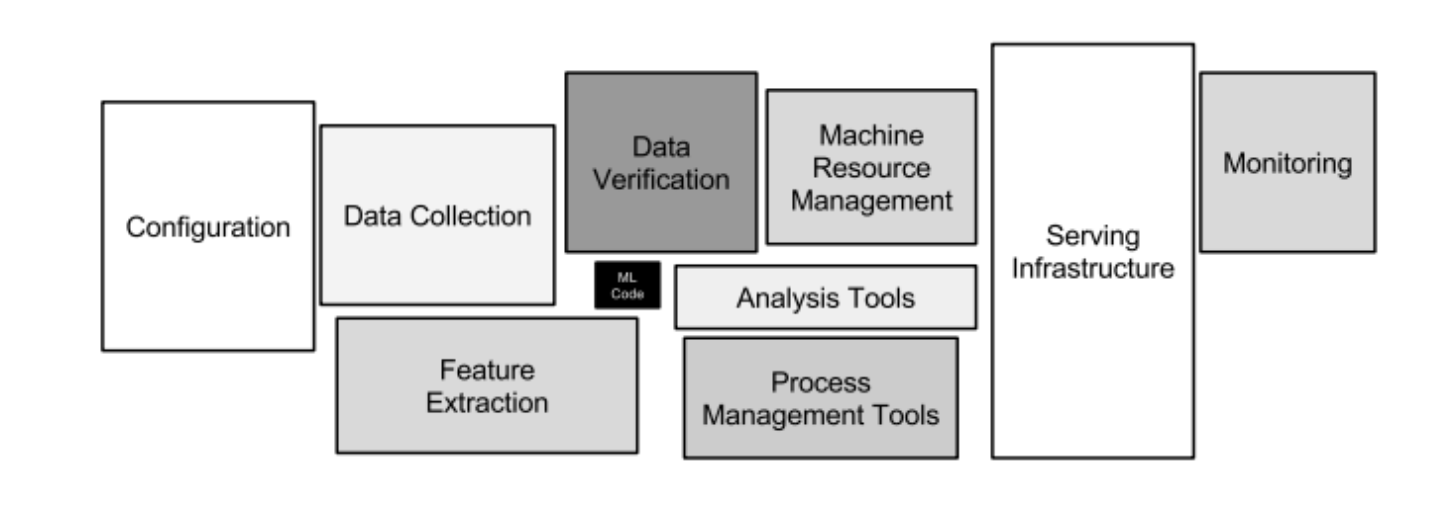
Agent systems are repeating the same mistake faster. The LLM sits at the center of a production agent system, the same way ML code sat at the center of a production ML system—important, but tiny relative to the infrastructure that makes it work. Memory, orchestration and tool use, state and persistence, security and governance, observability, and evals are the actual engineering problems.
What practitioners describe
Practitioners deploying at scale describe the ratio directly. Building an agent itself has become the easy part; a working prototype can be assembled in days with a coding assistant. The surrounding infrastructure is where the time goes. Deployment, monitoring, containerization, scaling, noisy-neighbor isolation, cost management, and re-testing hundreds of use cases every time a framework changes are the boxes in the agent version of the Sculley diagram. The LLM API call is a few lines of code. The shared framework, evaluation tooling, security guardrail calibration, embedding management, and data pipelines that surround it are the system.
One way to feel the difference: the ratio of surrounding code to model interaction. A weekend chatbot is roughly one line of glue code per token the model produces — a prompt, an API call, a response handler. A governed agent platform — with identity propagation, durable execution, audit trails, cost attribution, and recovery logic — is closer to fifty lines per token, and most of those lines have nothing to do with the model. The Claude Code source leak in late March made this concrete: the codebase shipped roughly 512,000 lines of TypeScript across 1,900 files¹², of which the model interaction itself accounts for a small fraction. The rest is the harness.
The harness engineering convergence
The harness engineering conversation² has started to name this. Anthropic³, ThoughtWorks, LangChain⁴, and a growing number of practitioners are converging on the idea that the system around the model matters at least as much as the model itself. Vercel deleted eighty percent of their agent’s tools⁵ and watched the success rate jump from eighty to one hundred percent. LangChain moved from Top 30 to Top 5 on Terminal Bench 2.0⁶ by changing only the harness. Harvey’s legal agents⁷ more than doubled their accuracy through harness optimization alone.
But the conversation has a gap. Most of it stops at the harness layer—the model’s interaction loop. What manages the harness? What provides a durable state, cost controls, governance, and the data layer that bridges an enterprise’s scattered systems to the agent’s context window? That is not the harness. That is the infrastructure underneath it.
The harness and its components
Taxonomy: agent, system, harness, platform
The previous blog post separated the terms: an agent has four capabilities (perception, planning, memory, action) running in a loop; an agent system coordinates multiple agents through shared state and a handoff protocol; a harness is the code and runtime that manages agent execution, running either one agent or a full system as one coordinated runtime. A platform, in turn, is the infrastructure that runs many harnesses across many teams over time. LangChain’s Vivek Trivedy defines the harness as “every piece of code, configuration, and execution logic that isn’t the model itself.” That includes system prompts, tools, middleware, memory, skills, and orchestration logic. It is a useful definition, but it leaves out the infrastructure that the harness itself depends on.
Figure 2. The six components of the agent harness.
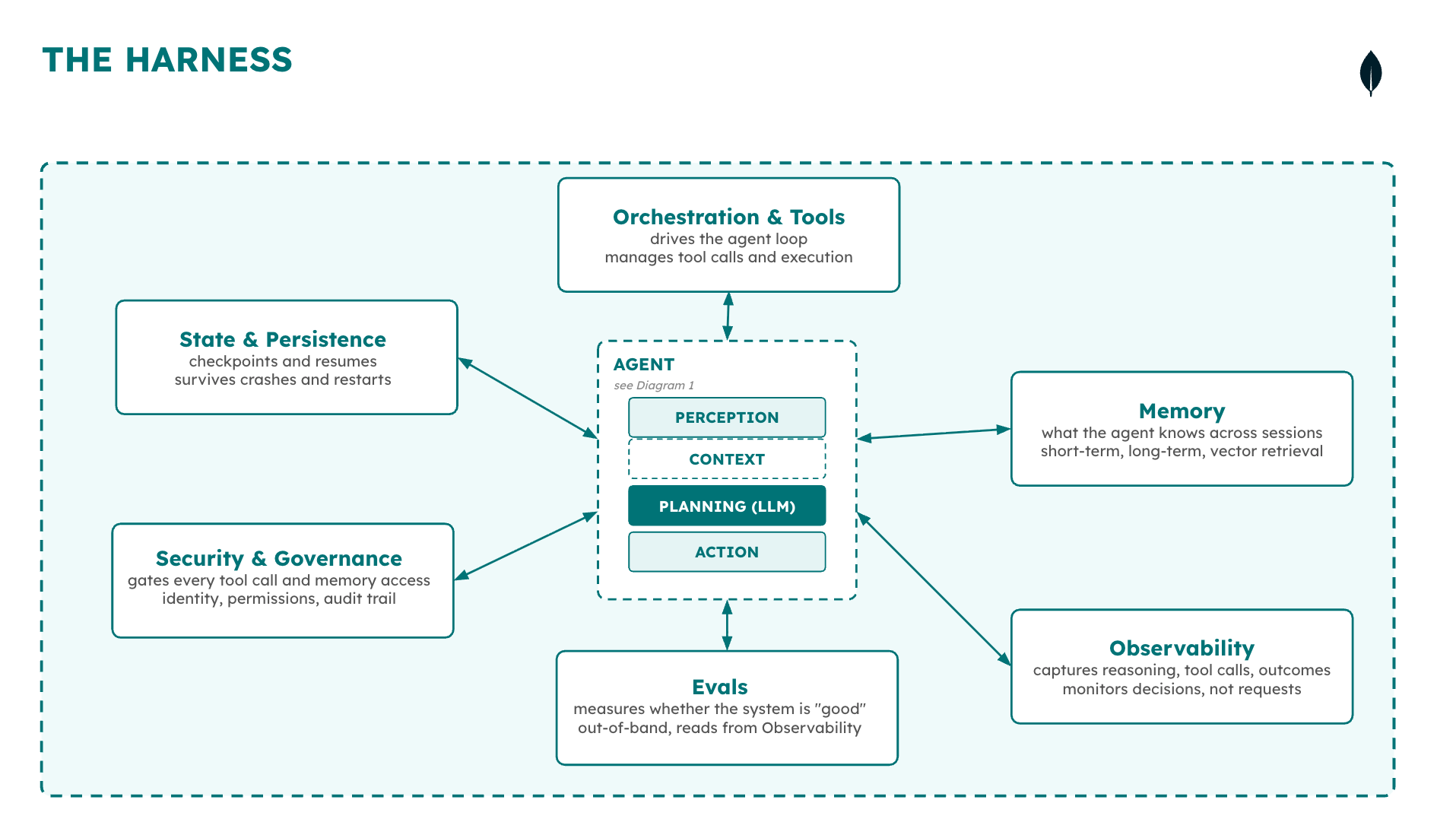
Each component below is the subject of a later post. The walkthrough names the problem each one solves, the mechanism, and why it is non-trivial.
State and persistence
State and persistence stores and retrieve an agent’s execution context—checkpoints, intermediate outputs, and the agent’s position within a multi-step task. When an agent crashes partway through a run, this layer determines whether it resumes from the last successful step or starts over. State artifacts accumulate quickly in long-running agents and need the same lifecycle management applied to operational data: backup, retention, and access control. They also continue to consume infrastructure while an agent is paused—for instance, waiting on human approval—which is a common source of unexpected cost at scale.
Security and governance
Security and governance controls what an agent is permitted to do, on whose authority it acts, and what record is produced of its actions. It covers identity propagation, permission scoping, and auditability. This is where most enterprise agent projects stall before production. Assurance and compliance teams typically require an industry-standard set of controls for autonomous systems, which for agents does not yet exist; each organization ends up building its own, usually late in the project. The failure modes cluster into three: data exfiltration when scoped identity does not propagate through tool calls; prompt injection when context is not sanitized; and inaccurate access controls when the agent acts under a shared system identity rather than the originating user’s.
Orchestration and tool use
Orchestration and tool use drive the agent loop: when to perceive, plan, act, and which tool to call. Tool use reaches external systems—APIs, databases, search services, and other agents. MCP⁸, introduced by Anthropic in late 2024, solved connectivity: agents can now reach tools through a common interface. It did not solve coordination, access control, rate limiting, or sandboxed execution. Production incidents tend to originate in that gap. A common pattern is an agent that successfully calls a tool, receives a response it was not designed to handle, and loops indefinitely while consuming tokens—the connectivity worked; the surrounding coordination did not.
Memory
Memory has two levels. Agent-side memory is working memory—the context assembled for the current turn. Harness-side memory is the persistent store: a short-term cache plus long-term episodic, conversation, and entity stores, accessed through a vector index. Each turn, the agent reads from the persistent store into working memory; the action layer writes results back. The infrastructure characteristics are volume (schema-free data accumulates fast) and retrieval (quality depends on embedding accuracy and vector search). Memory also connects to a separate problem: enterprise data. Agents that need to reason over existing operational data meet the memory layer at the same entry point.
Observability
Observability records what the agent did, what it decided, what it used, and what happened as a result. It is fundamentally different from application monitoring: the question is not whether the system responded but whether the decision it made was correct. Three signals are essential—the output, the reasoning trace (why the agent chose this path), and the memory fragments and tool calls that contributed to the decision. As of early 2026, no widely accepted AgentOps playbook exists; each team is assembling its own from database observability tools, LLM observability vendors, and custom instrumentation.
Evals
Evals run out-of-band, reading from observability after the fact. They determine whether an agent is ready to deploy and whether it should remain deployed. An eval suite consists of test cases, success criteria, and the infrastructure to run those tests repeatedly over time. The difficulty is that deterministic success criteria do not map cleanly onto non-deterministic systems. A production agent has to work reliably across many runs, not pass once. As of early 2026, there is no widely accepted eval framework for agent quality; the measurement problem is ahead of the tooling.
The platform layer
The six harness components sit on top of a second layer the current discourse rarely names: the platform. Where a harness manages one agent system as one coordinated runtime, the platform provides the infrastructure that makes many harnesses operable across many teams over time. It has four properties. Durable execution keeps an agent’s work intact through process crashes and long pauses, so the harness can resume from a checkpoint instead of starting over. Governance propagates identity and produces audit evidence automatically, so the harness does not have to reimplement it per deployment. Cost visibility surfaces spend at the agent and action level, not aggregated across a team, so budgets stay traceable. Data integration reaches enterprise systems without requiring migration, so the harness’s memory layer can hit the data that already exists.
The Big Model vs. Big Harness debate, covered next, is a conversation about how to optimize the top of the diagram. The production reliability conversation is about the platform layer underneath it.
The harness debate, and what it misses
The harness engineering conversation has converged on a real question: given a fixed model, how much does the scaffolding around it matter? Swyx frames the tension⁹ as Big Model versus Big Harness. The honest answer is that harness value varies by task type and model capability—and that framing the question this way leaves out the platform layer underneath both.
The evidence, briefly
On one side, harness changes drive large measured improvements. Vercel removed eighty percent of its agent’s tools and watched success rates climb from eighty to one hundred percent, with tokens dropping by more than half and latency falling from 724 seconds to 141—same model. LangChain’s coding agent moved from the bottom of Terminal Bench 2.0 to the top five (52.8 percent to 66.5) by changing only the harness. Princeton’s CORE-Bench¹⁰ found the same model scoring 42 percent with one scaffold and 78 percent with another. Harvey’s legal agents more than doubled their accuracy through harness optimization alone. On the other side, Scale AI’s SWE-Atlas found harness choice within the margin of error for some model families, and METR’s benchmarks show Claude Code and Codex do not consistently outperform a basic scaffold. Both effects are real; they dominate in different regimes.
What the debate skips
The more important problem is that both sides of the debate are optimizing the model’s interaction loop. A common pain-point we’ve heard from engineering leaders deploying at scale: the framework provides the agent workflow—the loop, the tool calls, the context passing. The platform layer underneath provides security propagation, governance, cost tracking, and the ability to suspend a long-running agent without paying for idle compute while it waits on an external trigger or human approval. One pattern we hear repeatedly: hundreds of engineers across product teams all start building agents independently; each individual agent is easy to build; a year later, the operational surface is unmanageable. Another: a firm that prefers to buy infrastructure wherever possible reluctantly builds its own agent runtime because nothing available meets its needs, and the investment in orchestration and compliance evidence dwarfs the investment in agent logic.
Neither of these is a harness problem. They are platform problems. The harness debate takes the harness as the outer ring of the system; production reliability starts where the harness ends.
Where teams actually are
Three stages of agent maturity
Most teams building agents today fall into one of three stages, and the difference between them is not how clever the agent is. It is how much of the surrounding system has actually been built.
The stages are cumulative. Stage 2 contains everything from Stage 1, plus harness engineering. Stage 3 contains everything from Stage 2, plus the platform layer. A team that calls itself Stage 3 but does not have observability across multiple agents is actually a Stage 2 team with one well-instrumented agent. The label is not the achievement. Three observations follow from these definitions, each of which the rest of the series will return to:
- Most teams that describe themselves as advanced are at Stage 2. ServiceNow’s Enterprise AI Maturity Index¹¹ found global maturity scores dropped from 44 to 35 year-over-year on a 100-point scale, with fewer than one percent of organizations scoring above 50. Practitioner assessments consistently show teams overestimating their stage by one or two levels because they evaluate based on their best use case rather than their organizational average. A team with one production agent and good context engineering is doing real work. It is also still a Stage 2 team.
- The gap between Stage 2 and Stage 3 is where most production failures cluster. A common pain-point we’ve heard from engineering teams running their own AI gateways: “Most everything we’re doing is prompt engineering and using LLM APIs.” Teams that pride themselves on being advanced discover they have not solved long-term memory, or cost controls at per-agent granularity, or evaluation that runs automatically on every change. The gap shows up when someone asks about a dimension the in-house solution never thought about — and the honest answer is “we haven’t gotten there yet.”
- The move from Stage 2 to Stage 3 is not a technical upgrade. It is the moment when the platform layer becomes a separate object of engineering — owned by a different team, built on different cadences, evaluated against different criteria than the agents that run on it. The discipline does not have an established name yet. Each organization builds its own version. Whoever builds it first defines the vocabulary the rest of the market uses.
What a well-designed platform should do
The platform layer defined above gives teams a concrete thing to audit against. The question is not “does this platform do everything?” but “where does it break, and does the layer underneath catch it?” Can the agent resume from a checkpoint? Can the platform produce an audit trail? Can teams see cost per action? If the answer to any of these is “not yet,” the platform is short of production regardless of what the architecture diagram says.
Four diagnostic questions
Four diagnostic questions follow from the two-layer model. First, at what layer is the stack actually operating? A framework plus a vector database plus hand-rolled state management is not the platform layer—it is the harness layer with gaps. Second, what metrics are being tracked, and do they match the layer? A team measuring task completion rate but not cost per task, observability coverage, or governance compliance is measuring the harness with the harness’s own infrastructure. Third, can any single layer be swapped independently—model, framework, data store, observability tool—without rebuilding everything above it? If not, the coupling will become locked in. Fourth, are bills arriving that cannot be traced to specific agents or actions? Unexplained cost is a signal that the platform’s cost-visibility property is missing; the remediation is not a better dashboard, but the infrastructure that produces the data the dashboard would show.
Conclusion
The harness is the six components around the model. The platform is the layer underneath that makes many harnesses operable over time. The distinction matters because most teams building agents today are making harness-layer decisions with harness-layer thinking when the problem in front of them—security review, cost at scale, fleet-wide evaluation—sits at the layer below.
Figure 3. The relationship between agents, harnesses, and platforms.
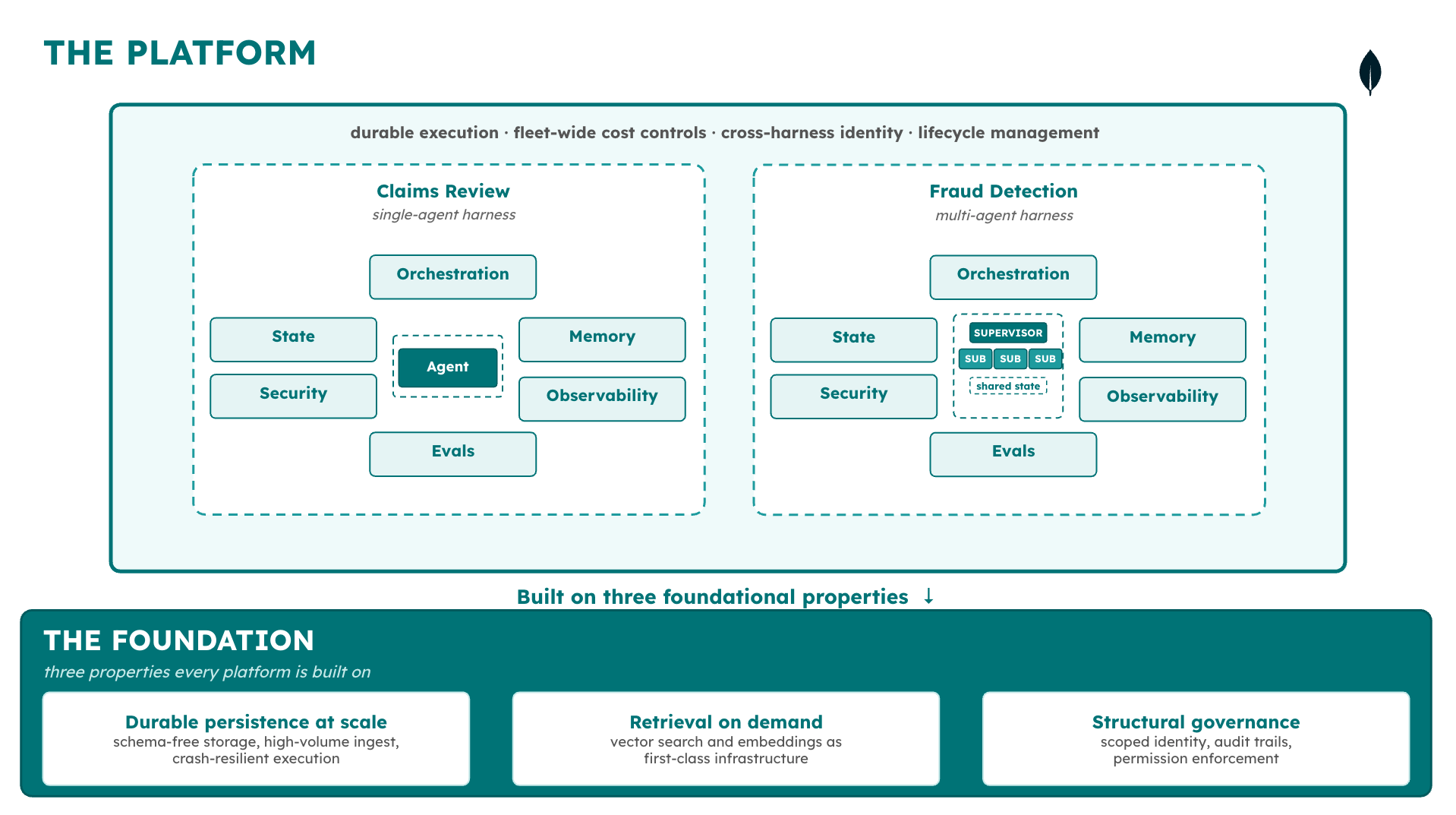
The rest of the series examines each component in turn, starting with the one most production agent deployments encounter first as a reliability problem: state and persistence. Part 2 builds on the autonomy framing in “The Case for Bounded Autonomy”—a system cannot exercise bounded autonomy if it cannot recover from the state it is in.
Next Steps
Interested in building production-grade agent systems with MongoDB? Check out our resources on agent memory with LangGraph + MongoDB, building AI agents with Atlas Vector Search, and context engineering for enterprise AI.
References
- Sculley et al., “Hidden Technical Debt in Machine Learning Systems” (NeurIPS 2015) — https://papers.neurips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
- Böckeler / Fowler, “Harness Engineering” (martinfowler.com, Feb 2026) — https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
- Anthropic, “Effective Harnesses for Long-Running Agents” (Jan 2026) — https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- LangChain, “The Anatomy of an Agent Harness” (Mar 2026) — https://blog.langchain.com/the-anatomy-of-an-agent-harness/
- Vercel, “We Removed 80% of Our Agent’s Tools” (Dec 2025) — https://vercel.com/blog/we-removed-80-percent-of-our-agents-tools
- LangChain, “Improving Deep Agents with Harness Engineering” (Feb 2026) — https://blog.langchain.com/improving-deep-agents-with-harness-engineering/
- Artificial Lawyer, “Harvey Drives Legal Agent Learning via Harness Engineering” (Apr 2026) — https://www.artificiallawyer.com/2026/04/07/harvey-drives-legal-agent-learning-via-harness-engineering/
- Model Context Protocol (MCP) — https://modelcontextprotocol.io
- Swyx / Latent Space, “Is Harness Engineering Real?” (Mar 2026) — https://www.latent.space/p/ainews-is-harness-engineering-real
- CORE-Bench Leaderboard, Princeton HAL (2025) — https://hal.cs.princeton.edu/corebench_hard
- ServiceNow, Enterprise AI Maturity Index (2025) — https://www.servicenow.com/enterprise-ai-maturity-index.html
- Layer5, “The Claude Code Source Leak: 512,000 Lines, a Missing .npmignore, and the Fastest-Growing Repo in GitHub History” (Mar 2026) — https://layer5.io/blog/engineering/the-claude-code-source-leak-512000-lines-a-missing-npmignore-and-the-fastest-growing-repo-in-github-history/
Authors
Mikiko Bazeley, Staff Developer Advocate, MongoDB. Mikiko focuses on agentic AI systems and enterprise agent infrastructure, writing about agent memory engineering, context engineering, and the POC-to-production gap in AI systems.
Ashish Kumar, Technical Fellow, MongoDB. Ashish joined MongoDB two years ago through the acquisition of Grainite, a database startup he co-founded. Before that, he spent many years at Google, most recently responsible for Google’s native database suite — Bigtable, Spanner, Datastore, and Firestore — across Google’s own products and Google Cloud. His passion is large-scale distributed systems, and at MongoDB, he focuses on architectural improvements across the product stack.
Charlie Xu, Senior Product Manager, Cloud Product, MongoDB. Charlie leads product thinking, customer research, positioning and architectural priorities for MongoDB's agentic AI offerings.