At MongoDB we are all about letting developers innovate with data. Time series is the fastest-growing data-intensive workload, and our native time series capabilities let you build applications faster and get more insight from time series data with less cognitive load.
It’s common for time series data to have gaps, such as when an IoT sensor goes offline. But in order to perform analytics and ensure correct results, time series data needs to be continuous. You may also want to create histograms or correlate data sets to enable more complex operational analytics in the context of app development. Gap filling, now available in MongoDB 5.3 Rapid Release, in combination with the densification we introduced in MongoDB 5.1, helps you better handle missing data to easily create and surface valuable insight.
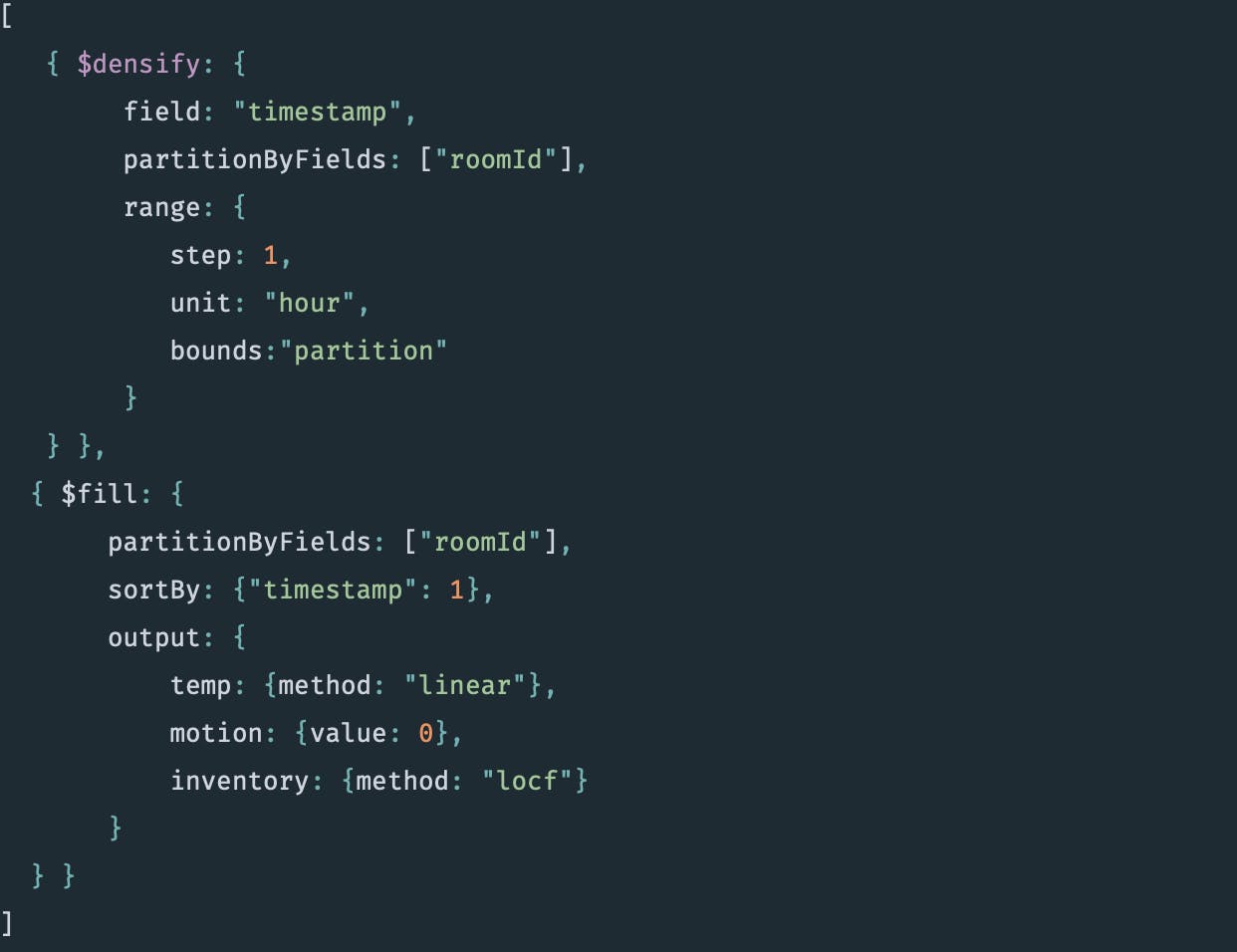
The two new aggregation stages create a simple, streamlined way to deal with missing data across time series and regular collections powering analytics for any use case. The $densify stage creates new documents to eliminate the gaps in the time or numeric domain at the required granularity level, and $fill sets values for the fields when a value is null or missing. Filling missing values can be done with a constant or using linear interpolation, carrying over the last observation or carrying backward the next observation.
Input documents: tracking of temperature, motion, and inventory in a storage room
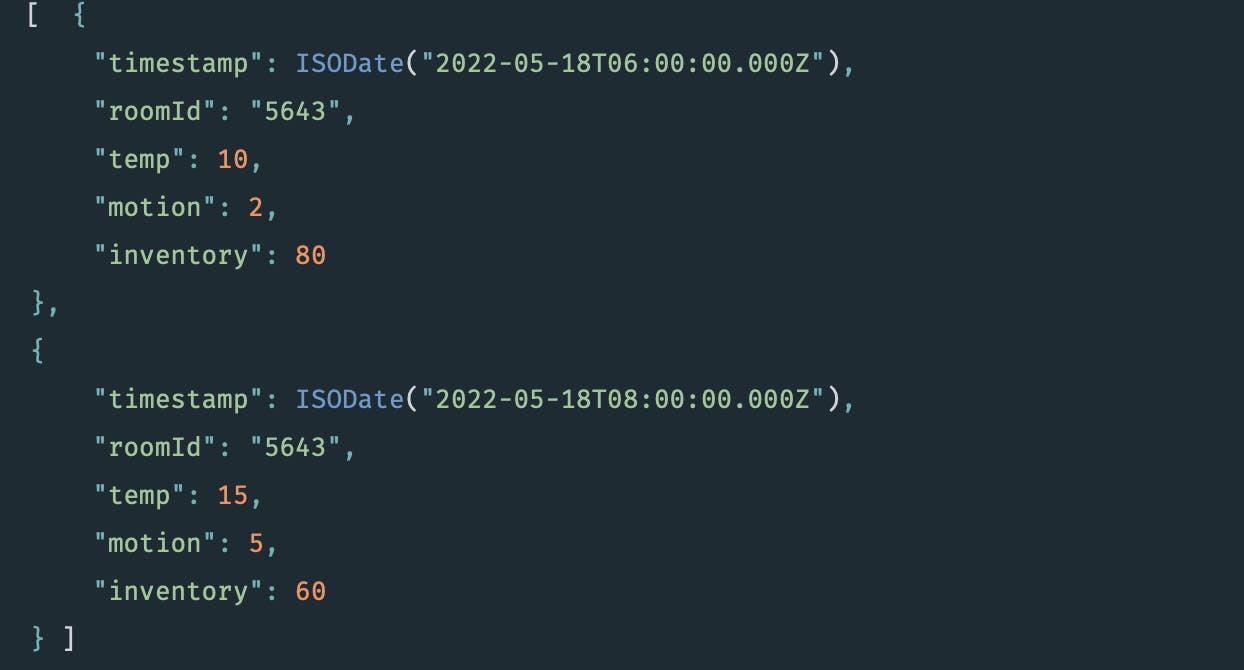
This function produces an hourly view of the metrics for each storage room. When temperature data is missing it should be interpolated linearly, motion should default to 0, and quantity of inventory should be carried over from the last known point.
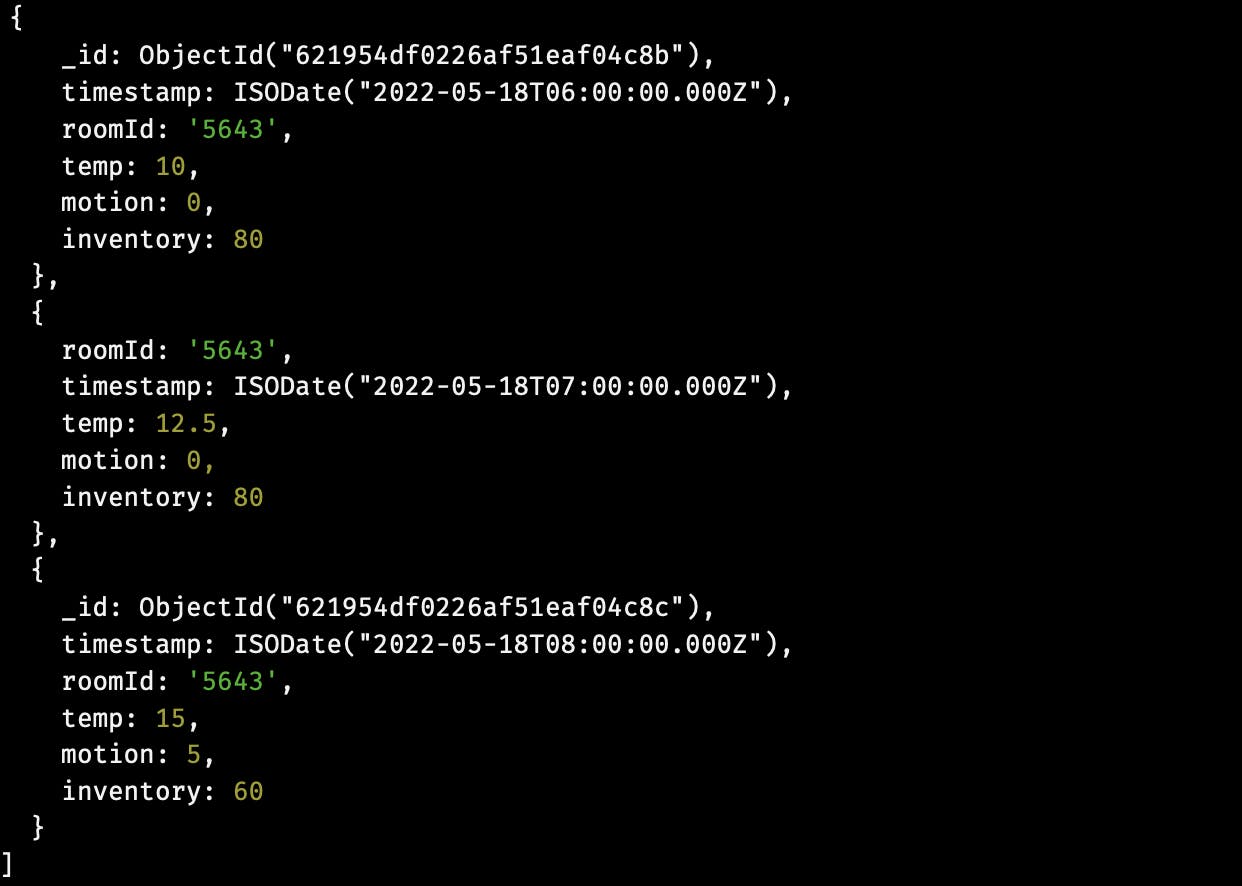
Output: The second document was generated based on the two surrounding documents.
Previously these types of complex analytics were possible only in specialized systems such as dedicated time series databases or data warehouses. Architecturally, technology practitioners had to make the no-win trade-off between a niche, often immature technology dedicated solely to time series workloads and disconnected from systems of record containing the full complement of enterprise data and exporting time series data into data warehouses, thereby making it hard to operationalize insights. Both involve managing multiple data silos and fragile ETL pipelines driving up complexity and cost. Workarounds to these approaches often involve developers building complex data pipelines to fill in the gaps, potentially at the application layer, leading to poor query performance or limiting analytics to small data sets. With MongoDB 5.3, developers can build rich analytics on time series data in flight and deliver operational insight to their users as part of the application experience.
MongoDB 5.3 is available now. If you are running Atlas Serverless instances or have opted in to receive Rapid Releases in your dedicated Atlas cluster, then your deployment will be automatically updated to 5.3 starting today. MongoDB 5.3 is also available as a Development Release for evaluation purposes only from the MongoDB Download Center. Consistent with the new release cadence announced last year, the functionality available in 5.3 and the subsequent Rapid Releases will roll up into MongoDB 6.0, our next Major Release scheduled for delivery later this year.
Safe Harbor Statement
The development, release, and timing of any features or functionality described for our products remains at our sole discretion. This information is merely intended to outline our general product direction, and it should not be relied on in making a purchasing decision. Nor is this a commitment, promise, or legal obligation to deliver any material, code, or functionality.