Industries: Insurance, Financial Services, Healthcare
Products and tools: Time Series, MongoDB Atlas Charts, MongoDB Connector for Spark, MongoDB Atlas Database, MongoDB Materialized Views, Aggregation Pipelines
Partners: Databricks
Solution Overview
This solution demonstrates how to use MongoDB, Machine Learning and real-time data processing to automate the digital underwriting process for connected cars. You can use this solution to offer customers personalized, usage-based premiums that take into account their habits and behaviors.
To do this, you'll need to gather data, send it to a machine learning platform for analysis, and then use the results to create personalized premiums for your customers. You’ll also visualize the data to identify trends and gain insights. This unique, tailored approach will give your customers greater control over their insurance costs and help you to provide more accurate and fair pricing.
The GitHub repo contains detailed, step-by-step instructions on how to load the sample data and build the transformation pipeline in MongoDB Atlas, as well as how to generate, send, and process events to and from Databricks.
By the end of this demo, you’ll create a data visualization with Atlas Charts that tracks automated insurance premium changes in near real time.
You can apply the concepts of this solution to other industries, including:
Financial Services: Banks and financial institutions must be able to make sense of time-stamped financial transactions for trading, fraud detection, and more.
Retail: Retailers require real-time insights into current market data.
Healthcare: From the modes of transportation to the packages themselves, IoT sensors enable supply chain optimization while in-transit and on-site.
Reference Architectures
The diagram below describes the architecture as follows:

Figure 1. Reference architecture with MongoDB
First, load a dataset including the total distance driven in car journeys
into MongoDB and run a daily cron job every day at midnight to
summarize the daily trips. Then, compile the daily trips into a document stored in a
new collection called customerTripDaily.
Run a monthly cron job on the 25th day of each month, aggregating the daily
documents and creating a new collection called customerTripMonthly.
Every time a new monthly summary is created, an Atlas function posts the total
distance for the month and baseline premium to Databricks for ML prediction. The
ML prediction is then sent back to MongoDB and added to customerTripMonthly.
As a final step, visualize all of your data with MongoDB Charts.
Data Model Approach
For this use case, a basic data model covers the customers, the trips they take, the policies they buy, and the vehicles insured by those policies.
This example builds three MongoDB collections, and two materialized views. You can find the full data model for defining MongoDB objects in the GitHub repository.

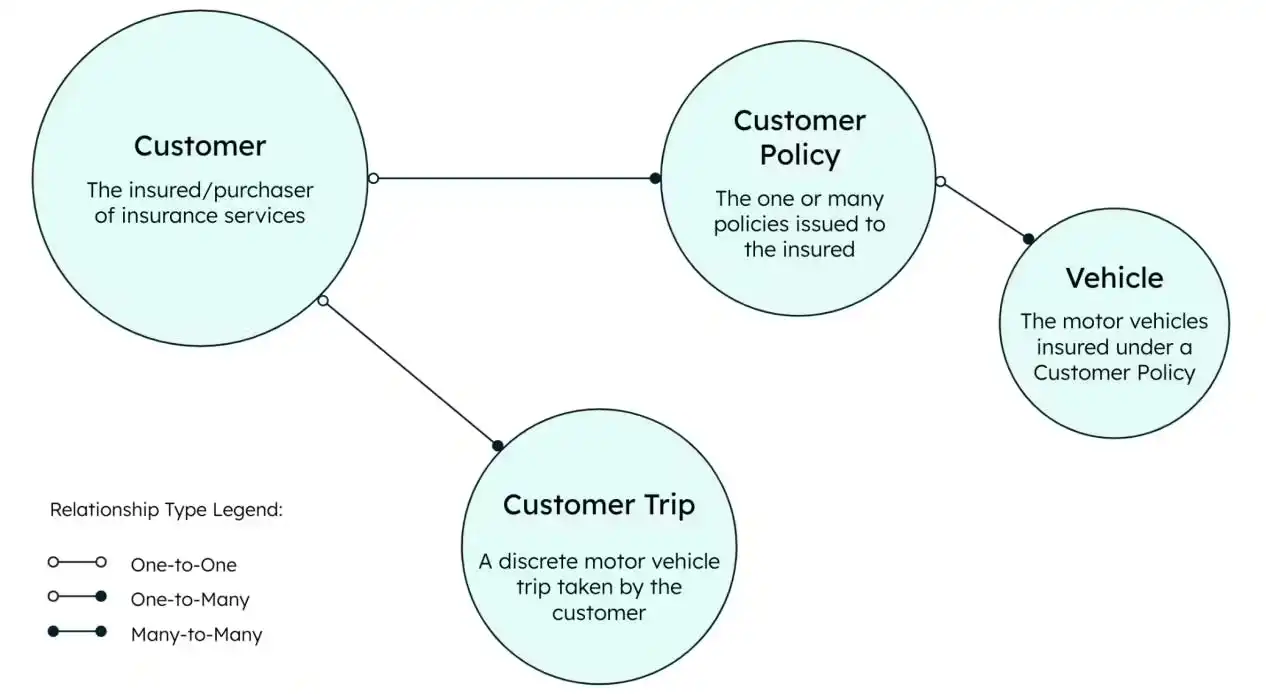
Figure 2. MongoDB data model approach
Build the Solution
To replicate this solution, check its
GitHub repository.
Follow the repository's README, which covers the following steps in more detail.
Create a data processing pipeline with a materalized view
The data processing pipeline component consists of
sample data, a daily materialized view, and a monthly materialized
view. A sample dataset of IoT vehicle telemetry data represents
the motor vehicle trips taken by customers. It’s loaded into the
collection named customerTripRaw.
The dataset can be found on GitHub
and can be loaded via mongoimport or other methods. To create a
materialized view, a scheduled trigger executes a function that
runs an aggregation pipeline. This then generates a daily summary
of the raw IoT data and places it in a materialized view
collection named customerTripDaily.
Similarly for a monthly materialized view, a scheduled trigger executes a
function that runs an aggregation pipeline that summarizes the information in
the customerTripDaily collection on a monthly basis and places
it in a materialized view collection named customerTripMonthly.
Check the following Github repos to create the data processing pipeline:
Step 1: Load the sample data.
Step 2: Setup a daily cron job.
Step 3: Setup a monthly cron job.

Figure 3. Create a data processing pipeline
Automate insurance premium calculations with a machine learning model
The decision-processing component consists of a
scheduled trigger that collects the necessary data and posts the payload
to a Databricks ML Flow API endpoint. This model was
previously trained using the MongoDB Spark Connector on
Databricks. It then waits for the model to respond with a
calculated premium based on the monthly miles driven by a given customer.
Then the scheduled trigger updates the customerPolicy collection to
append a new monthly premium calculation as a new subdocument within the
monthlyPremium array.
Check the following Github repos to create the data processing pipeline:
Step 5: Setup the Databricks connection.
Step 6: Write the machine learning model prediction to MongoDB.

Figure 4. Automating calculations with machine learning model
Key Learnings
Learn how to build materialized view on time series data: refer to steps 1-3 in the GitHub repo.
Leverage aggregation pipelines for cron expressions: refer to steps 2 or 3 in the GitHub repo.
Serve machine learning models with MongoDB Atlas data: refer to step 4 in the GitHub repo.
Write a machine learning model prediction to an Atlas database: refer to steps 5 and 6 in the GitHub repo.
Visualize near-real-time insights of continuously changing model results: refer to the Bonus step in the GitHub repo.
Authors
Jeff Needham, MongoDB
Ainhoa Múgica, MongoDB
Luca Napoli, MongoDB
Karolina Ruiz Rogelj, MongoDB