在本指南中,您学习;了解如何使用 Voyage AI生成第一个向量嵌入并构建基本应用程序。
使用可运行版本的本教程以作为 Python 笔记本。
创建模型API密钥
要访问权限Voyage AI模型,请在MongoDB Atlas用户界面中创建模型API密钥。
注册一个免费的Atlas帐户或登录。
如果您是Atlas的新用户,它会为您创建一个组织和项目。
为您的项目创建模型API密钥。
在Atlas项目中,从导航栏中选择 AI Models。
单击 Create model API key(连接)。
为API密钥命名,然后单击 Create。
要学习;了解详情,请参阅 模型API密钥。
生成您的第一个嵌入
在本部分中,您将使用 Voyage AI嵌入模型和Python客户端生成向量嵌入。

创建脚本。
在项目中创建一个名为 quickstart.py 的文件,并将以下代码粘贴到其中。此代码初始化 Voyage AI客户端,定义示例文本,并使用客户端访问权限Voyage API以使用 voyage-4-large 模型生成向量嵌入。
有关详细信息,请参阅Python客户端或浏览完整的API规范。
import voyageai # Initialize Voyage client vo = voyageai.Client() # Sample texts texts = [ "hello, world", "welcome to voyage ai!" ] # Generate embeddings result = vo.embed( texts, model="voyage-4-large" ) print(f"Generated {len(result.embeddings)} embeddings") print(f"Each embedding has {len(result.embeddings[0])} dimensions") print(f"First embedding (truncated): {result.embeddings[0][:5]}...")
构建基本 RAG 应用程序
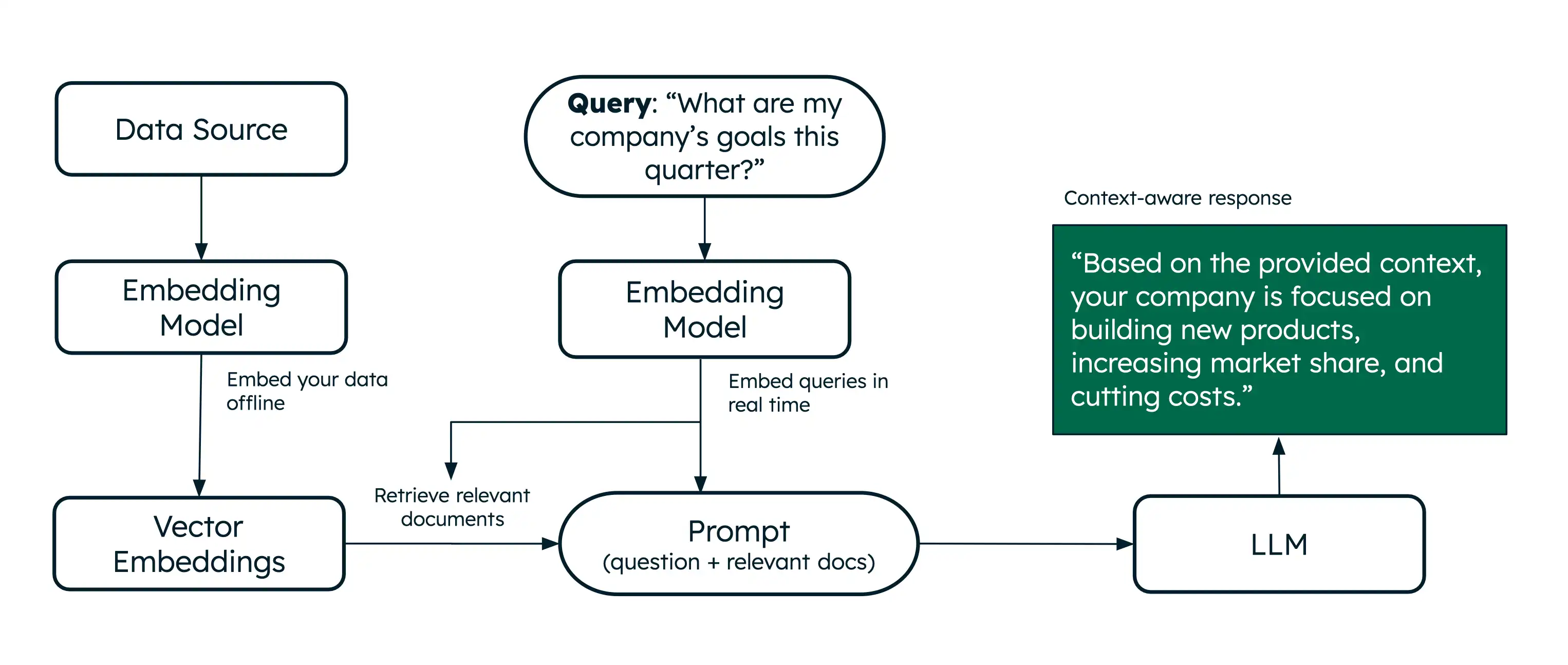
现在您已经知道如何生成向量嵌入,构建一个基本的 RAG应用程序,以学习;了解如何使用 Voyage AI模型来实现AI搜索和检索。 RAG 使法学硕士能够在生成答案之前从数据中检索相关信息,从而生成上下文感知的响应。
注意
RAG 申请需要访问权限法学硕士学位。本教程提供了使用 Anthropic 或 OpenAI 的示例,但您也可以使用您选择的任何 LLM提供商。

学习总结
现在您已经使用 Voyage AI创建了第一个应用程序,请展开以下部分以学习;了解有关本快速入门中涵盖的概念的更多信息:
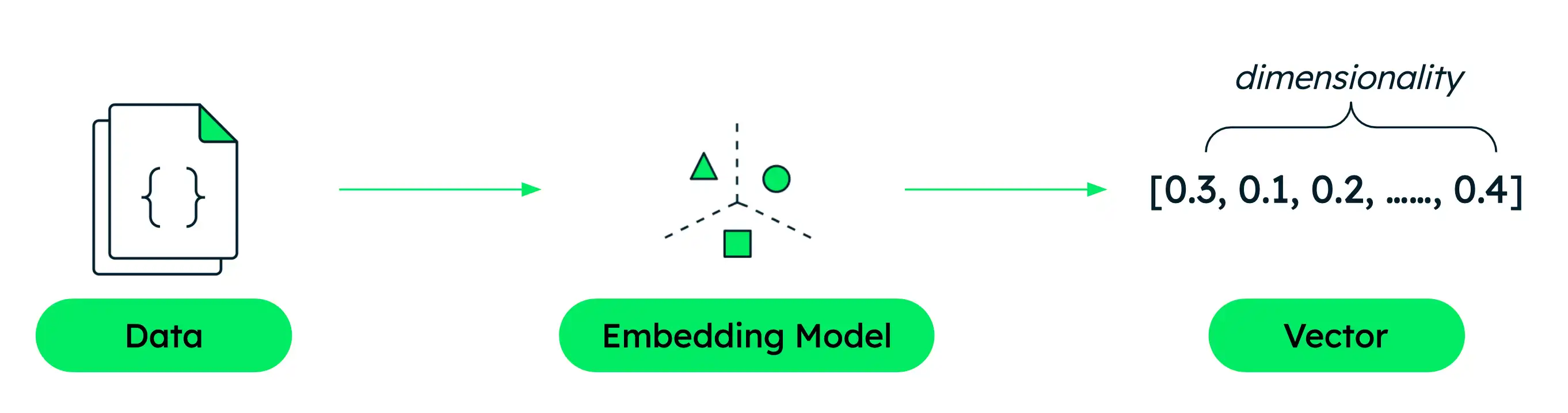
您使用 voyage-4-large 嵌入模型将文本转换为 1024 维向量。每个维度代表一个学习到的功能,捕获文本含义的各个方面。
您还使用了 rerank-2.5 重新排名模型来根据查询优化搜索结果。分数越高表示查询和文档内容之间的相似性越强。
您使用voyageai Python SDK访问权限Embedding and Reranking API。使用 SDK 调用模型时,您指定了input_type 参数以提高搜索准确性:
document:优化表示数据的嵌入。query:优化查询嵌入。
您使用点积相似度函数查找语义相似的文档。 Numpy 是一个开源库,可为向量运算提供内置函数,该应用程序使用 dot() 和 argsort() 函数来计算查询与文档嵌入之间的点积相似度,然后按文档的索引对文档进行排序。相似度分数。
要学习;了解有关语义搜索的更多信息,请参阅使用 Voyage AI嵌入进行语义搜索。有关文本嵌入用法和 input_type参数的更多详细信息,请参阅用法。
您将语义搜索和重新排名与法学硕士相结合,创建了一个基本的 RAG 系统。系统使用语义搜索相关文档,对它们重新排名,然后向法学硕士提供最相关的文档,以对您的查询生成准确、有根据的响应。
要学习;了解有关 RAG 的更多信息,请参阅使用 Voyage AI进行检索增强生成 (RAG)。
后续步骤
要继续学习,请参阅以下资源: