了解如何使用 MongoDB Atlas 和 Google Cloud 工具套件来创建语音驱动的实时汽车体验。将车辆数据、用户上下文和汽车手册嵌入向量整合到一个智能且可扩展的车载助手中,以满足驾驶员的需求。
行业: 制造与移动
产品: MongoDB Atlas,MongoDB Atlas Vector Search
合作伙伴: Google Cloud Platform、PowerSync
解决方案概述
汽车制造商面临着越来越大的压力,需要通过智能、用户友好的数字系统使他们的汽车脱颖而出。车载语音助手是实现这一目标的关键方法,但大多数仅限于控制导航或音乐等基本命令。生成式人工智能使您能够超越这些限制,在驾驶时提供个性化的动态交互。
该解决方案演示了如何构建由Gen AI和MongoDB Atlas提供支持的实时语音助手。该架构集成了车辆遥测、用户偏好和汽车手册,以创建适应每个驱动程序需求的车内助手。通过使用MongoDB Atlas 灵活的document model和内置向量搜索,开发者可以简化数据复杂性并更快地提供功能,从而提供更好的车内体验。
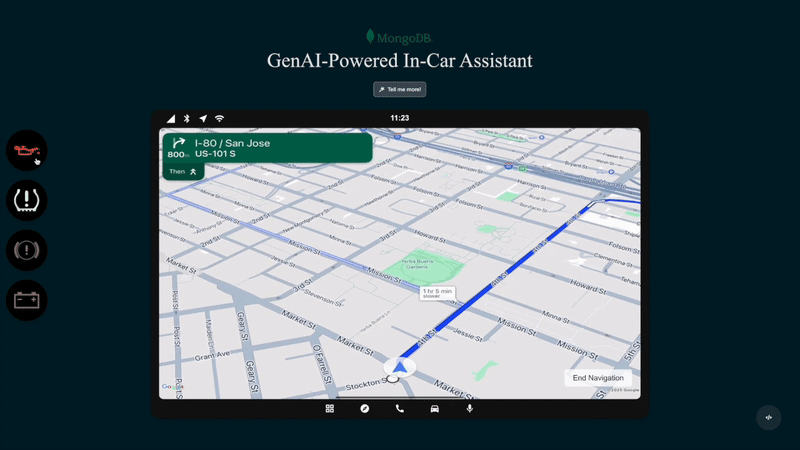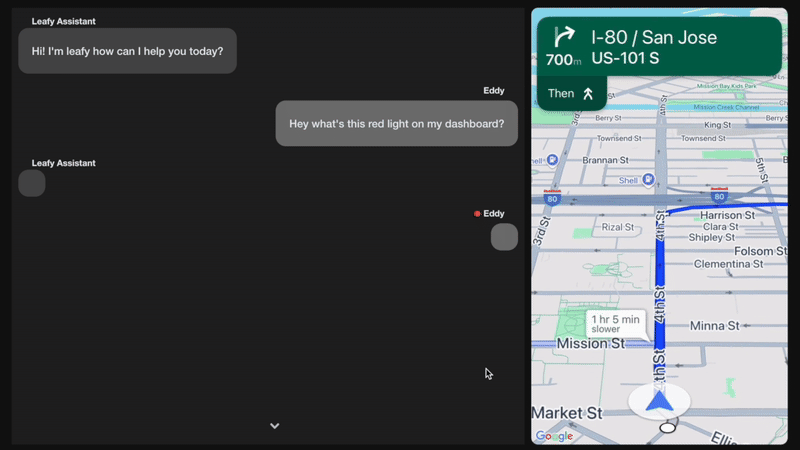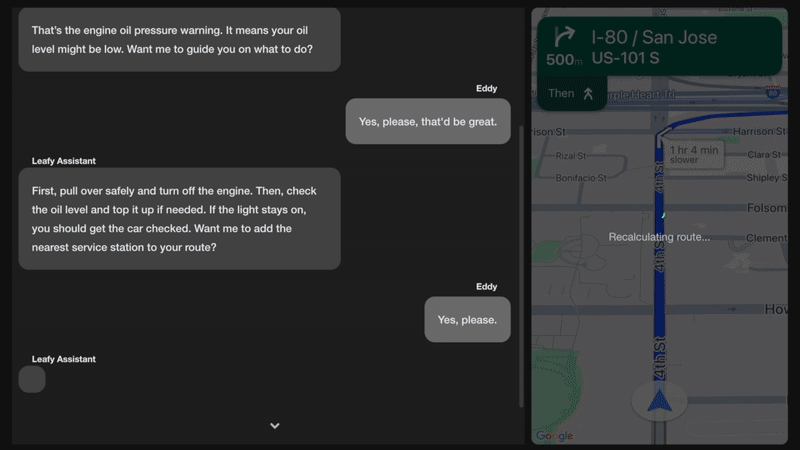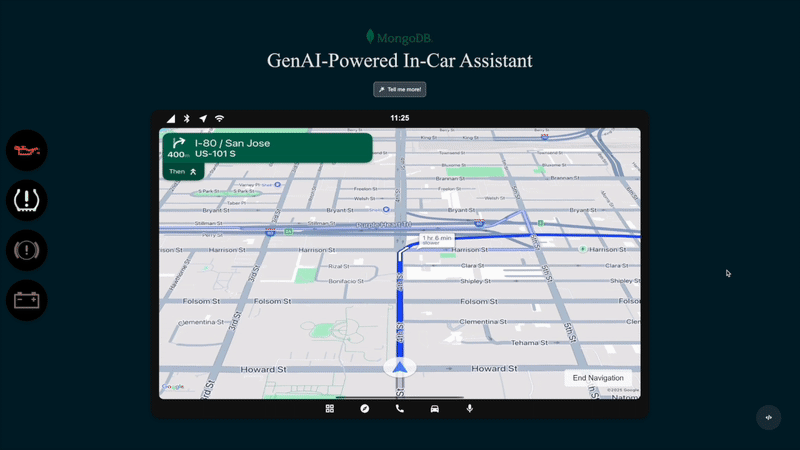
图 1. 生成式人工智能车载助手实景演示
利用该解决方案,您可以:
统一结构化和非结构化数据,以增强 AI 系统的上下文。
启用与可扩展的云原生架构的实时交互。
通过 Atlas Vector Search 提供支持的语义搜索,提供个性化体验。
虽然该解决方案专注于汽车行业,但它也可以应用于交通运输、医疗保健、酒店和消费电子产品等行业,以提高客户互动,减少摩擦并简化支持。这种架构为语音转发、数据驱动的体验(例如智能家居助手、数字礼宾和支持AI的医疗分流系统)奠定了基础。各行各业的公司正在利用语音、生成式人工智能和MongoDB的力量来改变用户体验。
参考架构
该架构使用MongoDB Atlas作为数据层,并结合 Google Cloud 的AI功能,确保快速、个性化且可靠的交互。

图 2.生成式 AI 车载助手的参考架构
该解决方案使用托管在车辆和云的组件。
板载组件
这些应用程序在车内运行,靠近驾驶员,并支持实时语音交互。
车载控制台:用户与助手交谈并获取响应的车内界面。该演示使用一个 Web应用程序来代表真实车辆中的嵌入式系统。
本地数据存储:车辆使用 PowerSync SDK 在本地存储关键信号,该 SDK 是一个基于 SQLite 的轻量级边缘数据库。这可确保快速访问诊断数据,并使数据与 MongoDB Atlas 保持同步。
助手后端:此组件管理对话。它使用 Google Cloud Speech-to-Text 处理语音转录。根据查询的不同,它可以直接响应,也可以调用工具来获取更多数据或采取操作。此演示包括四个示例操作:
查阅手册:使用 Atlas Vector Search 从汽车手册中检索相关信息。
运行诊断:从本地车辆数据中提取当前诊断代码。
重新计算路线:如果司机增加了一站,则调整进程。
关闭聊天:优雅地结束对话。
此解决方案使用以下对象来定义助手后端的工具。该解决方案会在启动聊天功能时将该对象传递给 Google Cloud。
const functionDeclarations = [ { functionDeclarations: [ { name: "closeChat", description: "Closes the chat window when the conversation is finished. By default it always returns to the navigation view. Ask the user to confirm this action before executing.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: { view: { type: FunctionDeclarationSchemaType.STRING, enum: ["navigation"], description: "The next view to display after closing the chat.", }, }, required: ["view"], }, }, { name: "recalculateRoute", description: "Recalculates the route when a new stop is added. By default this function will find the nearest service station. Ask the user to confirm this action before executing.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: {}, }, }, { name: "consultManual", description: "Retrieves relevant information from the car manual.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: { query: { type: FunctionDeclarationSchemaType.STRING, description: "A question that represents an enriched version of what the user wants to retrieve from the manual. It must be in the form of a question.", }, }, required: ["query"], }, }, { name: "runDiagnostic", description: "Fetches active Diagnostic Trouble Codes (DTCs) in the format OBD II (SAE-J2012DA_201812) from the vehicle to assist with troubleshooting.", parameters: { type: FunctionDeclarationSchemaType.OBJECT, properties: {}, }, }, ], }, ];
云组件
这些组件存储在 Google Cloud 或MongoDB Atlas中,提供AI智能、可扩展的存储和数据处理功能。
数据摄取:非结构化内容(如汽车手册)被上传至 Google Cloud 存储。这会触发一个使用 Pub/Sub、Cloud Run 和 Document AI 的管道,将 PDF 文件分割成数据块。Vertex AI 为这些数据块生成嵌入,然后将其存储在 MongoDB Atlas 中以进行语义搜索。
提供语音 API:Google Cloud 的 Text-to-Speech 和 Speech-to-Text处理自然语音交互。Vertex AI为搜索查询提供文本嵌入,并为 Gemini(助手使用的LLM)提供支持。
数据存储和检索: MongoDB Atlas 存储:
通过 Atlas Vector Search 手动对嵌入向量进行分块以进行检索。
用户偏好和会话数据。
车辆信号 - 最新值和完整时间序列遥测数据。
Atlas Vector Search用于将用户问题与最相关的手册部分进行匹配,从而实现检索增强生成 (RAG) 流程。MongoDB 在一个地方对结构化、半结构化和向量数据提供原生支持,从而简化了助手逻辑并加快了开发速度。
数据同步:该解决方案使用 PowerSync 实现车辆和云之间的双向同步:
车辆到云:车辆发送遥测数据,例如诊断代码、速度或加速度。Cloud Run 函数会处理并将其存储在 Atlas 中。
云到车辆:支持将更新或操作远程发送到汽车,例如 OTA 更新或远程锁定。
对话式AI中的MongoDB
MongoDB Atlas通过以下方式改进了该解决方案架构:
统一操作数据和向量数据:车辆信号、向量嵌入和用户会话一起存储在单个平台中。
实现更相关的响应: Atlas Vector Search立即从大型文档中检索正确的数据块,从而促进准确且上下文丰富的响应。
为企业级规模而构建:无论是单个模型还是全球范围的集群,MongoDB Atlas 都提供内置的横向可扩展性、高可用性以及企业级安全保障。
简化边缘和云同步:PowerSync 和 MongoDB 协同工作,顺畅连接车内和云环境。
这种架构旨在扩展、发展和适应,就像它支持的车辆一样。以MongoDB为核心,汽车制造商可以减少对数据管道的关注,而更多地关注于提供智能、有用的车内体验,真正改变道路。
数据模型方法
在AI驱动的体验中,数据的质量、结构和可访问性极为重要。在此解决方案中,MongoDB 的 document model 为构建智能车载助手的开发者提供了灵活性、速度和扩展。
与依赖严格表格和复杂联接的传统关系数据库不同, MongoDB将数据存储为灵活的文档。这样可以更轻松地表示现实世界的数据结构,例如车辆遥测或嵌入式知识数据块,就像在代码中使用的一样。这还意味着您可以更快地进行迭代,无需停机即可调整模型,并随着应用程序的发展构建新功能。
为创新和速度而构建
document model 是为开发者设计的。MongoDB 灵活的模式使您能够轻松更改和更新数据模型。随着新的车辆功能的推出或用户期望的变化,团队可以动态发展数据模型,而无需昂贵的迁移或应用停机。此外,由于每个文档都是独立的,因此查询更快、更简单。
AI 工作负载的自然选择
生成式人工智能 的蓬勃发展依赖于丰富、多样的非结构化数据。嵌入、上下文元数据和结构化引用都有助于改进AI系统。您可以使用MongoDB执行以下操作:
将向量嵌入、元数据和源内容存储在一个文档中。
将结构化数据与向量数据结合,无需在系统之间切换。
同时查询向量字段和非向量字段,以获得上下文准确的结果。
示例 1:汽车手册嵌入
使用检索增强生成 (RAG) 方法时,分块和嵌入的质量直接影响 AI 响应的质量。内容分割不当或上下文缺失可能会导致回答含糊或不准确。技术手册通常包含密集的文本、图表和特定领域的术语,这使得检索正确的信息变得困难。
该解决方案将手册的每个数据块表示为一个文档。文档不仅包括文本及其向量嵌入,还包括内容类型等元数据(例如安全和诊断)、页码、数据块长度以及相关数据块的链接。这种额外的上下文有助于系统了解信息片段是如何相互关联的,这在技术性很强或相互依赖的主题中尤其重要。
MongoDB 灵活的文档模型可以轻松捕获这种复杂性。随着手册的发展或新需求的出现,您可以逐步添加字段或调整结构,而无需进行完整的模式迁移。这样可以实现更精确的检索和更有用的AI响应。
以下示例文档代表一个手动数据数据块:
{ "_id": { "$oid": "67cc4b09c128338a8133b59a" }, "text": "Oil Pressure Warning Lamp. If it illuminates when the engine is running this indicates a malfunction. Stop your vehicle as soon as it is safe to do so and switch the engine off. Check the engine oil level. If the oil level is sufficient, this indicates a system malfunction.", "page_numbers": [ 23 ], "content_type": [ "safety", "diagnostic" ], "metadata": { "page_count": 1, "chunk_length": 1045 }, "id": "chunk_0053", "prev_chunk_id": "chunk_0052", "next_chunk_id": "chunk_0054", "related_chunks": [ { "id": "chunk_0048", "content_type": [ "safety" ], "relation_type": "same_context" }, { "id": "chunk_0049", "content_type": [ "safety" ], "relation_type": "same_context" }, ... ], "embedding": [ -0.002636542310938239, -0.005587903782725334, ... ], "embedding_timestamp": "2025-03-08T13:50:00.887107" }
示例 2:车辆信号数据
对于车辆信号,该解决方案使用 COVESA 车辆信号规范 (VSS) 对数据进行建模。VSS 提供标准化的分层结构来描述实时信号,例如速度、加速度或诊断故障代码 (DTC)。它是一种开放、可扩展的格式,可以简化跨车辆平台的协作、系统集成和数据重用。
由于 MongoDB 的 document model 本身可以处理嵌套结构,因此表示 VSS 层次结构非常简单。信号可以进行逻辑分组,就像它们在 VSS 模型中一样,这与规范的基于树的结构一致。

图 3. VSS 数据模型是一种分层树结构,由可灵活组合的模块构建。来源:https://covesa.global/vehicle-signal-specification/
这种结构可加快开发速度,并确保AI工具和工作流程能够一致访问权限干净、结构化且有意义的数据。
以下文档是符合 VSS 的车辆信号的示例表示。
{ "_id": { "$oid": "67e58d5f672b23090e57d478" }, "VehicleIdentification": { "VIN": "1HGCM82633A004352" }, "Speed": 0, "TraveledDistance": 0, "CurrentLocation": { "Timestamp": "2020-01-01T00:00:00Z", "Latitude": 0, "Longitude": 0, "Altitude": 0 }, "Acceleration": { "Lateral": 0, "Longitudinal": 0, "Vertical": 0 }, "Diagnostics": { "DTCCount": 0, "DTCList": [] } }
MongoDB 的文档模型不只是存储数据。它反映了现实世界的复杂性,使构建更智能的系统变得更容易,这些系统可以实时响应、适应用户需求并与平台一起成长。无论您是存储车辆诊断信息还是矢量编码手册, MongoDB都能为您提供更快构建智能体验的工具。
构建解决方案
构建此解决方案可分为以下步骤。您可以使用MongoDB Atlas托管数据,使用 Google Cloud 提供AI服务,使用 PowerSync流车辆数据,并使用全栈应用将所有内容绑定在一起。您可以在GitHub存储库中找到所需的所有资产和资源。有关更详细的说明,请参阅存储库的 README。
复制该演示数据库
在您的Atlas帐户中预配一个集群,并使用演示所需的数据填充数据库。可以在存储库中找到数据转储,以便通过一个快速 mongorestore 命令快速复制包含所有必要数据和元数据的数据库。
配置您的 Google Cloud 环境
创建Google Cloud Platform项目并启用所需的 API:Speech-to-Text、Text-to-Speech、Document AI和Vertex AI。对于本地开发,请配置应用程序默认凭据,以便应用可以与 Google 服务无缝进行身份验证。Google Cloud Platform文档中提供了详细说明。
运行应用程序。
将存储库克隆到本地,并使用提供的模板创建 .env文件。配置环境后,运行npm install 以安装依赖项,然后使用 npm run
dev 启动开发服务器。该应用可从http://localhost:3000.获取。
关键要点
对话式AI从正确的数据基础开始:丰富、上下文相关且可访问的数据为智能语音助手提供了动力。MongoDB Atlas将结构化遥测、非结构化手册和向量嵌入统一在一个开发者友好的平台中,消除了数据孤岛,更轻松地提供服务相关的实时响应。
MongoDB加速从工厂到终点的创新:从预测性维护和诊断到数字驾驶舱系统,现代汽车应用程序需要灵活性和速度。MongoDB 灵活的模式、实时同步功能和横向可扩展性可帮助团队更快地行动、更有效地协作并提供让其车辆设立的功能。
驾驶员已为下一代语音助手做好准备:随着电动汽车、自动驾驶和智能安全系统的出现,客户对车载系统寄予了很高的期望。生成式人工智能使助手能够提供细致入微的交互式对话,而MongoDB为开发者提供了扩展构建这些体验的工具。
作者
Dr. Humza Akhtar, MongoDB
Rami Pinto,MongoDB