Add fast and relevant as-you-type suggestions to your application, incorporating user context and domain-specific ranking factors.
Use cases: Content Management, Catalog
Industries: Retail
Products: MongoDB Atlas, MongoDB Atlas Vector Search
Solution Overview
As-you-type functionality — also known as autocomplete, autosuggest, or predictive search — often refers to low-level character matching, as opposed to a purpose-built, comprehensive solution. This functionality helps you navigate quickly to desired, relevant content. Looking up the movie "The Matrix" by typing “matr” into the search bar is an example of as-you-type functionality.
Vector Search and full-text search are great at matching content semantically when there is a complete query, or very close word matches. However, an integrated as-you-type functionality can return relevant results with even fewer characters and more distance between the text input and the target keyword. This lexical-based solution facilitates partial matching and provides relevant, context-sensitive results.
Reference Architectures
The as-you-type suggestion solution is architecturally straightforward. As you type, requests are sent to Atlas Search, which returns relevant results. The architecture is structured around a specialized entities collection and the corresponding queries.
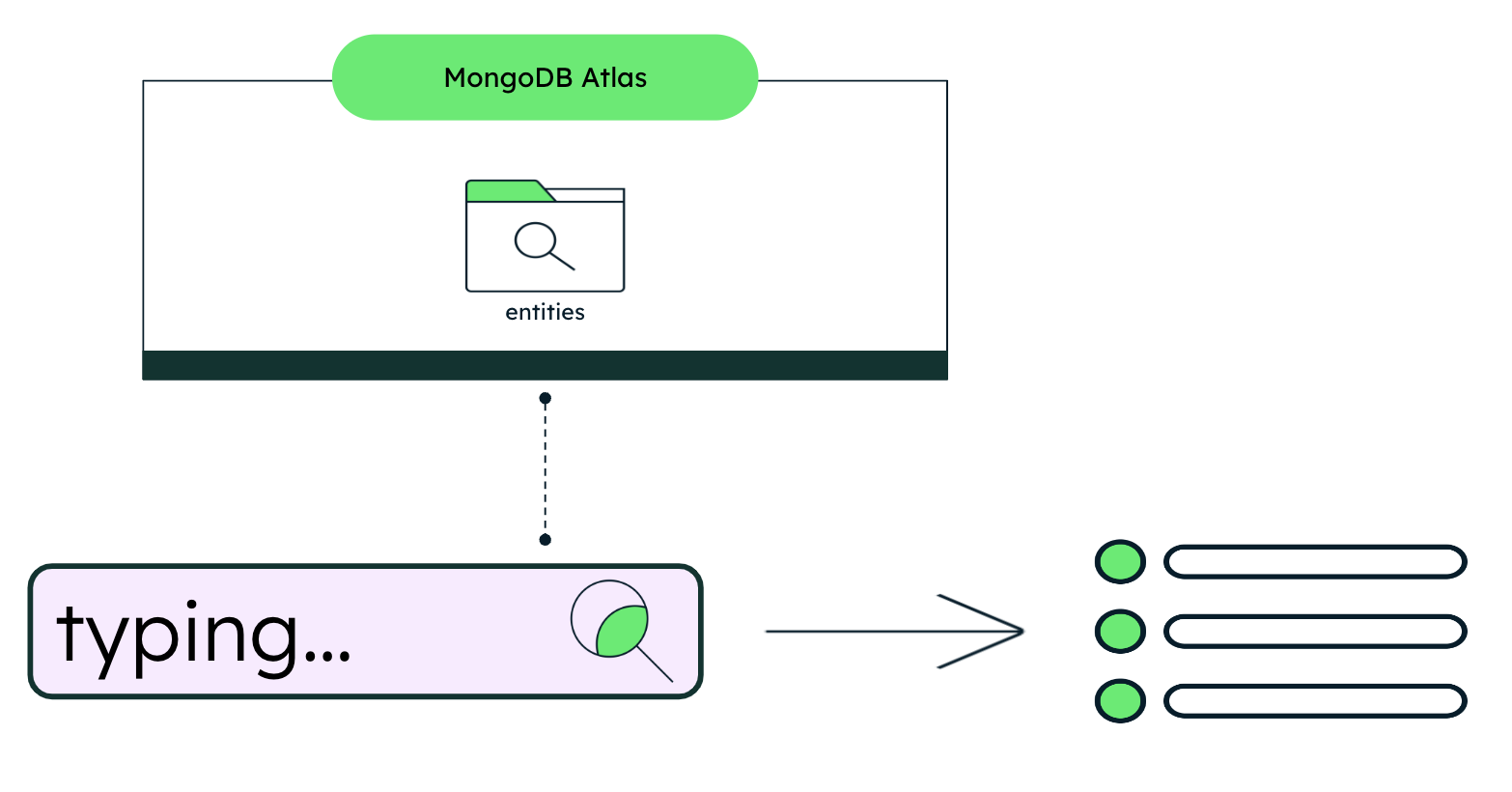
Figure 1. As-you-type solution architecture
Data Model Approach
Each suggestion presented to the user represents a unique entity of your domain. Entities must be modeled as individual documents in a specialized collection tuned for as-you-type suggestibility.
The main collection usually represents one type of entity as documents, and other domain entities as metadata fields or embedded documents. For example, consider using the sample movies data available within Atlas. As you type, the search suggests movie names. However, you can also search for cast member names. For example, you can find movies starring Keanu Reeves by typing only "kea".
The data model has the following schema:
_id: unique id for this collection in the form<type>-<natural id>.type: entity/object type, e.g. movie, brand, person product, and category.name: the name or title of the entity, which would generally be unique per type.
It’s important that entity documents have stable, unique identifiers, as the entities are regularly refreshed from the main collection. Assigning a type to each entity allows for filtering (only suggest cast members in an actor-specific lookup), grouping (organize the suggestions by type), or boosting by type (weight movies higher than cast member names).
Modeling entities directly as individual documents allows each to carry optional metadata fields to assist in ranking, displaying, filtering, or grouping them.
The document model feeds the name field through a sophisticated index configuration, which divides the values in a multitude of ways suitable for querying in several ways. The power of this solution comes from the union of multiple indexing and querying strategies.
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
Build the Solution
First, identify the suggestible entities in your data. In the movies scenario, these would include movie titles, cast member names, and perhaps genres and director names too.
The basis of this as-you-type suggestion system is as follows:
Create an
entitiescollection and populate it using the schema modeled above. As often as warranted, refresh theentitiescollection.Create an Atlas Search
entities_indexusing an index configuration as described below.Craft a robust set of query clauses, along with any pertinent boosting factors, within an aggregation pipeline that uses
$search.
Importing Entities
While there are multiple ways to populate the entities collection, one straightforward way to populate it is to run an aggregation pipeline on the main collection to bring in the unique titles across all movies:
[ { $group: { _id: "$title", }, }, { $project: { _id: {$concat: [ "title", "-", "$_id" ]}, type: "title", name: "$_id" } }, { $merge: { into: "entities" } } ]
The $project stage converts each unique movie title into the necessary entities schema. Because this collection types each document, the type is encoded as a prefix of the generated _id and appended with the actual movie title creating a reproducible identifier for each unique title. Including type in the entity identifiers allows different types of entities with the same name to be independent from one another (there could be a movie named “Adventure” as well as the “Adventure” genre).
Finally, the $merge stage adds all new titles and leaves the existing ones untouched.
The resulting title-typed document for “The Matrix” comes out simply as:
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
Each entity type potentially needs its own technique for merging into the entities collection, as in the case of the "genre" and "cast" entities, which need to be unwound from their nested arrays using $unwind.
This cast-specific entities import brings in “Keanu Reeves” as:
{ "_id":"cast-Keanu Reeves", "name":"Keanu Reeves", "type":"cast", "weight": 6.637 }
Indexing Entities
The name field is indexed in a multitude of ways, which will facilitate partial matching and ranking at query time.
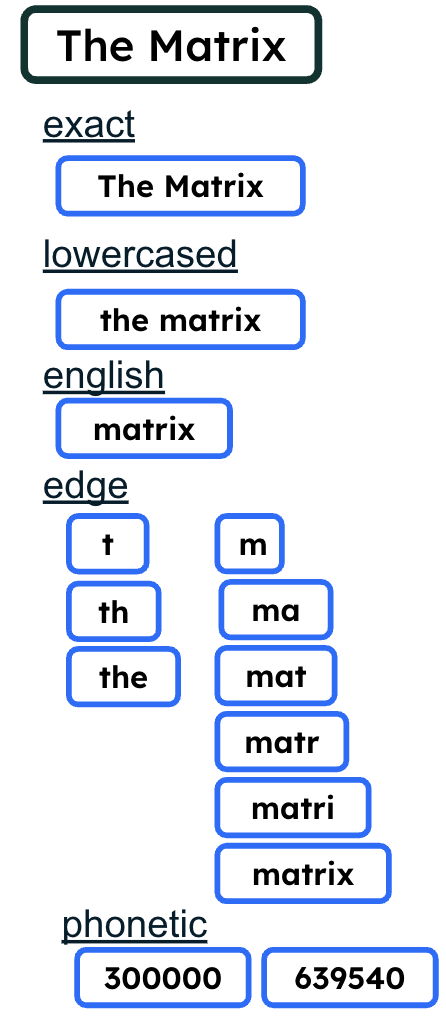
Figure 2. Multiple indexing strategies
The feature multi-analyzers uses Atlas Search index configuration to enable a single document field to be indexed in a multitude of ways.
The type field is indexed as both a token field, for equals or in filtering, and a stringFacet field to provide a means to get counts across the results of each entity type.
The index definition handles any other fields added beyond _id, type, and name, either through dynamic mapping or the static definitions you provide. In this example, weight is custom and handled dynamically as a numeric type.
Searching for Suggestions
The resulting specialized search index provides the foundation for as-you-type queries. The name field is indexed in a number of ways and matched against users typing with various tunable query operators. The idea is to compare the query operators to the differently analyzed mappings and see what matches. The more matches found, the higher the suggestion is ranked. Each of the query clauses can be independently increased and summed, giving a relevancy score for the matching entity. These scores could be further increased by other factors such as an optional entity weight field.
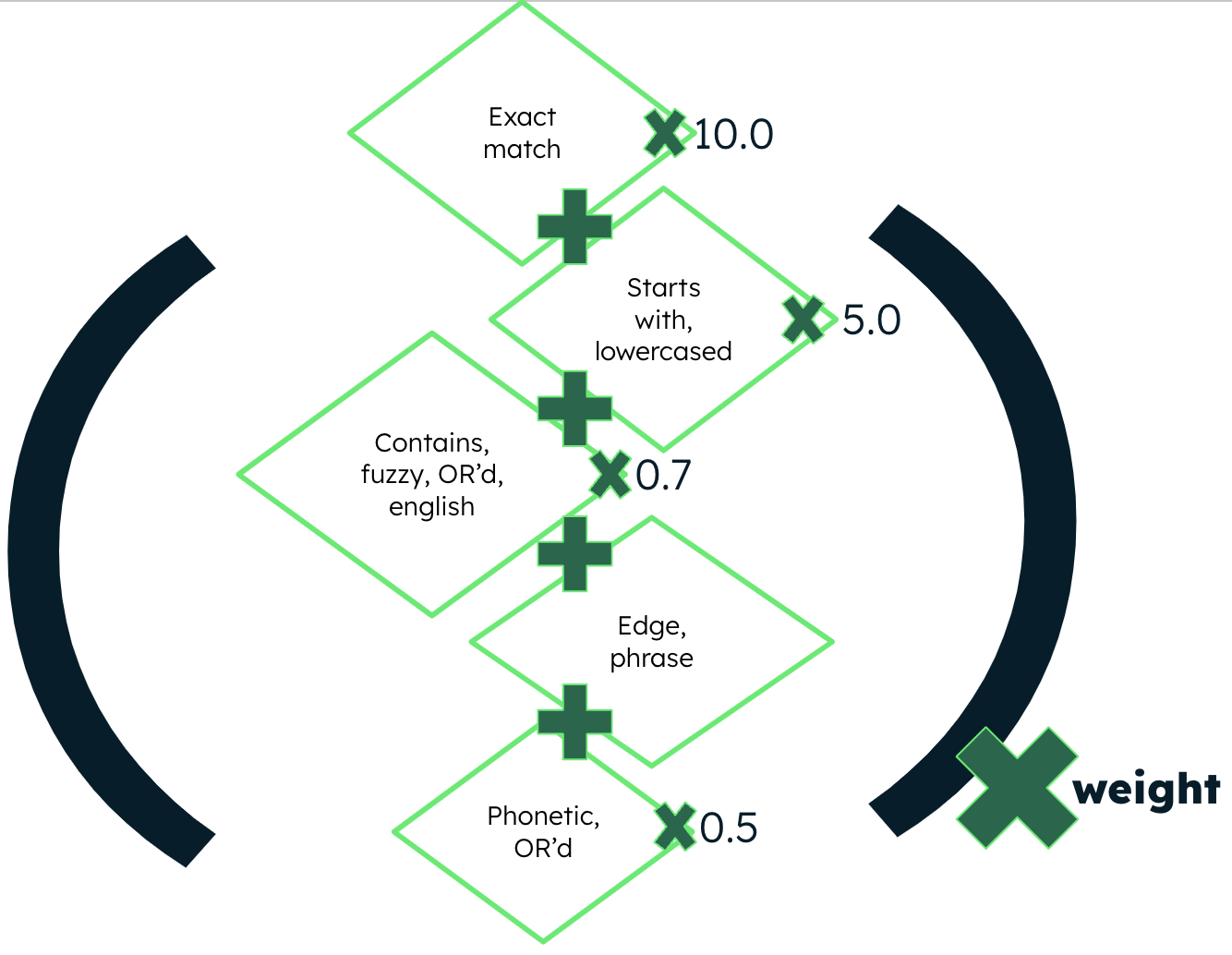
Figure 3. Example query and relevancy scoring computation
Generally, a user selecting a suggestion then performs a targeted traditional search for the selected item. The search then returns all matching items.
Visit the GitHub repository to this solution.
Key Learnings
Use a specialized index configuration to model suggestible entities as documents: Follow the steps above to create a separate collection that contains all entities from any source.
Create an index with these configurations: Use these index settings when your main collection models all suggestible entities as top-level documents.
Use the index structure to craft clever queries: Use your index to match entities and rank suggestions as desired.
Authors
- Erik Hatcher, MongoDB