Key takeaways
- Retrieval‑augmented generation (RAG) is a technique to fetch relevant data and combine it with a language model to give accurate, context‑aware answers.
- A keyword search produces search results based on the given input keywords, whereas vector search uses semantic search to produce context aware results. A hybrid search combines both.
- Reranking reorders results from multiple retrieval methods, ensuring the most relevant documents appear at the top.
- RRF is an efficient reranking algorithm that combines rankings from multiple search methods into a single ranking, improving accuracy and relevance.
- Some important use cases of RRF are healthcare support and research, product search, financial forecasting, and market analysis.
Table of contents
- Search results using keyword search
- Search results using vector search
- Hybrid search
- Different types of retrieval methods
- Retrieval-augmented generation (RAG) using hybrid search
- Example query translation
- Use cases of RAG with RRF
- FAQs
- Related content
Reciprocal rank fusion (RRF) is a popular algorithm to implement hybrid search. It aggregates rankings from multiple searches—for example, a keyword search, vector search, and so on—into a single ranking that is more accurate.
Before diving into RRF, let’s discuss the limitations posed by keyword search and vector search, when used individually.
Search results using keyword search
Keyword search solely relies on the keywords given in the user query. The search results are based only on the keyword matches and disregard any contextual relevance, particularly in the case of ambiguous queries. For example, if you search for reciprocal rank fusion using keyword search, it will return only those results that contain these exact keywords, but you may not get related yet contextually appropriate results, like reranking, retrieval-augmented generation, and hybrid search.
Search results using vector search
Vector search looks for semantically appropriate results, based on the KNN algorithm. There are two types of searches:
Sparse vector search
This method extends the keyword search by using weighted, high-dimensional sparse vectors that look for frequencies (less/more/absence/presence) of search terms. However, it does not fully capture the context or meaning of a search query.
Dense vector search
Dense vectors represent data (for example, text) as numerical vectors in multiple dimensions, where each dimension captures some detail of the data. These dense vectors are created using a deep learning model. When a query is fired, the similarity between the vectors is measured to identify which vector representations are closest to each other. The closer the vectors are, the more related they are contextually. This way, dense vector search gives semantically appropriate search results.
Hybrid search
Hybrid search combines various types of searches, like keyword and vector search, to produce multiple lists of relevant documents. These combined results can then be passed to a reranking module, which optimizes the final ranking order based on relevance signals or learned scoring. An example is shown below:
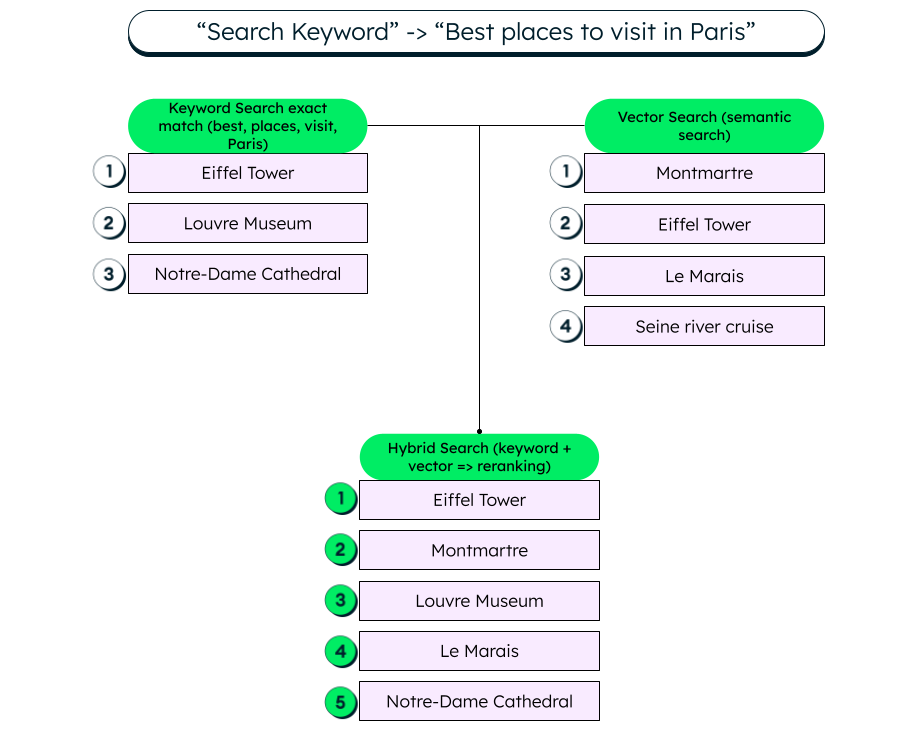
Different types of retrieval methods
From basic to more advanced retrieval methods, each one provides pros and cons and can be suitable for different use cases. Below is a quick overview of some important retrieval methodologies:
BM25
BM25 is the traditional keyword search algorithm, where the results are based on the exact input words given by the user. If you want an exact match result, like in a document search, BM25 is an excellent choice.
Vector search
Vector search retrieval captures semantic similarity between the input terms and tries to provide contextually relevant results. It uses dense vector embeddings to find close proximity words and improve the relevance of responses. It is quite useful for LLM-based question-answer systems and chatbots.
Multi-query retrieval
The multi-query retriever uses a large language model (LLM) to produce multiple versions or interpretations of the same user query. The search outcomes of each query are then aggregated to get a more comprehensive final query response. This can be useful for product recommendation systems, document retrievals, and academic research.
Ensemble
Ensemble retriever combines keyword search (sparse retriever like BM25) and dense retriever (vector search) to produce a list of relevant documents. It uses methods like reciprocal rank fusion to combine scores from multiple retrieval methods and provide the final ranking and unified result. Combining semantic matches with keyword matches produces more effective and accurate results. Ensemble retriever is a good choice for search engines, recommendation systems, and many more use cases.
Retrieval-augmented generation (RAG) using hybrid search
Using hybrid search greatly enhances RAG, as the results are more accurate compared to just keyword or semantic search. Reranking of search results using reciprocal rank fusion further ensures high quality results. The following diagram illustrates a hybrid search RAG pipeline that uses reranking.
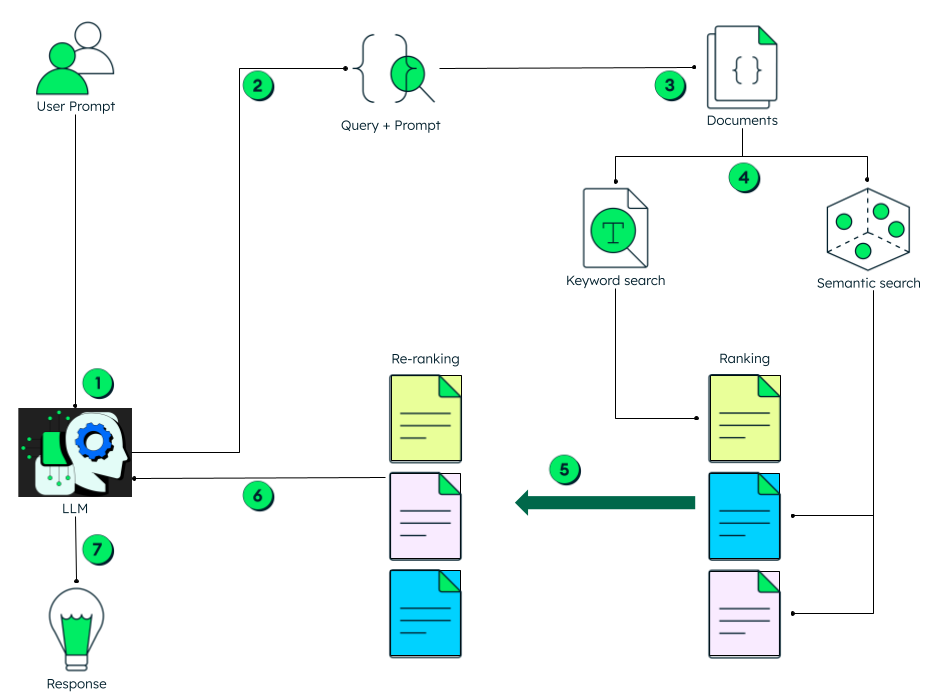
Once the LLM receives a user prompt, it generates a query and sends both the query and the prompt to the data store to retrieve relevant documents. Since hybrid search is used, two separate ranked lists with scores are generated—one from keyword search and another from vector search. These scores are then combined, typically using a fusion technique such as reciprocal rank fusion, followed by reranking. The final set of results is returned to the LLM, which uses the information to generate a response for the end user.
Why RRF?
Implementing reciprocal rank fusion has several advantages. It combines the strength of various methods, including sparse and dense vector results. This improves the relevance of the results. An RRF algorithm assigns a reciprocal rank score based on the document ranks from multiple retrieval methods. This reduces hallucination and mitigates errors that might occur due to the use of individual methods, thus improving performance and reliability of search results. The accuracy and reliability is crucial in RAG applications like content summarization, information retrieval, and question answer systems.
How RRF works
As a first step, whenever a user fires a query, multiple searches are kicked off. It can be a keyword search, semantic search, or both. Each of these methods generates a ranking (of results). The next step is to calculate the reciprocal rank score of each of the generated results. The score is calculated as:
k is a constant that helps in balancing the influence of individual rankings. The value of k decides the sensitivity to rank positions.
In the above formula, rank is the position of the document in the list.
In some implementations, different search strategies can be assigned different weights before combining their scores. This allows the system to favor one retrieval method—such as semantic search—over another, depending on the use case or domain requirements.
The next step is to combine the scores obtained from each strategy and sum them to obtain a single score. Then, rank the documents again (rerank), based on the combined score. Documents having higher scores will be placed on the top in the final ranking.
The final fused ranking is the list obtained from the above step, which is a blended result rather than the normalized result, a more accurate way to rank the results.

Example query translation
Let’s consider our previous example of Best places to visit in Paris, to illustrate how reciprocal rank fusion is applied to the results of multiple algorithms to produce the most relevant results.
First, we will calculate the reciprocal ranking scores of the results obtained through keyword search, keeping the value of k as 60:
- Eiffel Tower = 1/(1+60) = 0.0164
- Louvre Museum = 1/(2+60) = 0.0161
- Notre-Dame Cathedral = 1/(3+60) = 0.0159
Next, we calculate the reciprocal ranking scores of the results obtained through semantic search:
- Montmartre = 1/(1+60) = 0.0164
- Eiffel Tower = 1/(2+60) = 0.0161
- Le Marais = 1/(3+60) = 0.0159
- Seine River Cruise = 1/(4+60) = 0.0156
Now, let’s add the scores and combine the results, with the highest score on top:
- Eiffel Tower = 0.0164 + 0.0161 = 0.0325
- Montmartre = 0.0164
- Louvre Museum = 0.0161
- Le Marais = 0.0158
- Notre-Dame Cathedral = 0.0158
While keyword search focuses on exact keywords, like sight-seeing locations, semantic search also considers individuals’ personal experiences, gathered from blogs or reviews. Combining both can give the best of both worlds to a user.
Use cases of RAG with RRF
Some popular use cases of RAG with RRF are:
- E-commerce and retail: Customers don’t need to search for the exact product names, and can simply type what they want. Reranking helps produce results that are most useful to the user based on his search terms.
- Healthcare and medical research: Getting search data based on keyword (exact search words) and semantic search (similar studies) gives the most relevant evidence for diagnosis or treatment.
- Market analysis: Using data from multiple sources—like news reports, transcripts, blogs, and filings—and merging it with domain-specific data searches, produces a much more accurate and unified view of the financial data for analysis.
- Recruitment process: RAG can speed up the recruitment process by combining the resume details, along with the interview transcripts of a person. RRF can then produce accurate ranking of multiple candidates based on the practical interview experience as well as the data from the resume.