Bringing Attention To Memory In AI Agents and Agentic Systems
This piece brings together key learnings we've obtained from working with our customers on Retrieval-Augmented Generation (RAG)—an AI approach combining information retrieval with generative models, AI agents, and agentic applications, specifically addressing the fundamental challenges of reliability, believability, and capability in AI agents.
Key problem to solve: Transforming stateless AI applications into intelligent agents capable of learning, maintaining continuity, and adapting from interactions across sessions.
Agent memory definition: Agent Memory is the persistent system that enables agents to accumulate knowledge, maintain context, and adapt behavior—the cognitive architecture transforming reactive systems into intelligent agents.
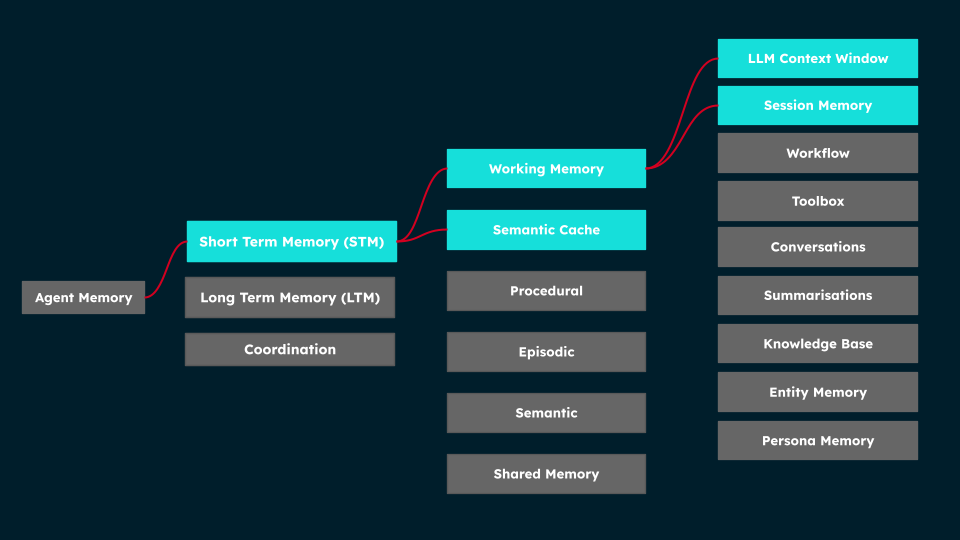
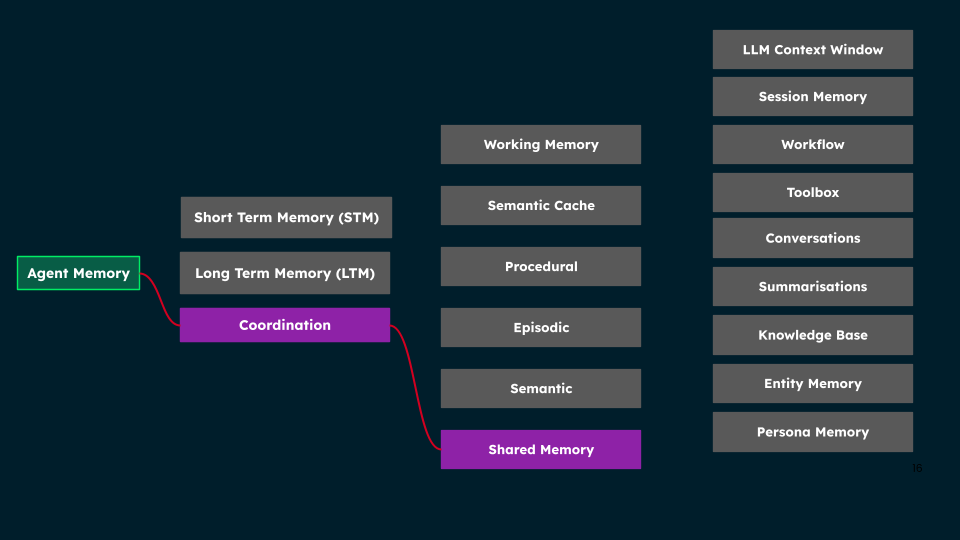
Memory types mentioned: Short-term memory (Working Memory, Semantic Cache, Shared Memory) and long-term memory (Episodic, Semantic, Procedural, and Associative Memory) serve different temporal and functional roles in Agent memory.
Application modes: There are three common operational patterns in AI applications leveraging LLMs: Assistant Mode for conversational interactions, Workflow Mode for multi-step processes, and Deep Research Mode for comprehensive analysis.
MongoDB relevance in AI: MongoDB provides unified memory capabilities with multi-model retrieval, flexible storage, and optimization features—eliminating multiple specialized databases while enabling memory engineering for reliable AI agents.
Through our exploration and unique position in the AI stack, we find that memory—or more broadly, an AI agent's ability to retain, recall, and reuse information—provides a critical pathway to making AI agents genuinely valuable and operationally effective.
Agent Memory (and Memory Management) is a computational exocortex for AI agents—a dynamic, systematic process that integrates an agent’s LLM memory (context window and parametric weights) with a persistent memory management system to encode, store, retrieve, and synthesize experiences. Inspired by human cognitive memory, it enables agents to accumulate knowledge, maintain conversational and task continuity, and adapt behavior based on history—making them more reliable, believable, and capable.
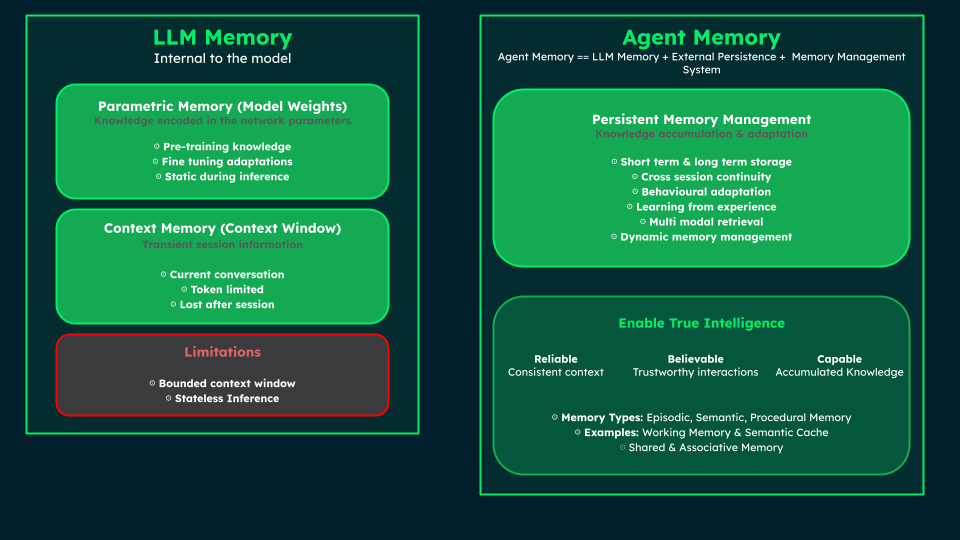
Comparison of LLM Memory and Agent Memory, showing how LLMs rely on bounded parametric and context memory, while Agent Memory adds persistent storage, continuity, and adaptive retrieval to enable reliable, believable, and capable intelligence.
Customer engagements have consistently revealed that while agents can demonstrate impressive capabilities in isolated interactions, their long-term utility depends critically on their ability to maintain relevant context, learn from past experiences, and adapt their behavior based on accumulated knowledge. This insight has shaped our understanding that memory management systems are a core component of AI infrastructure that transforms reactive agents into intelligent, adaptive agents capable of sustained value creation.
We’ll cover definitions, pipeline, engineering, and practical insights. Specifically, we will:
Establish clear definitions for often-ambiguous terms like agent memory and memory management.
Examine the data transformation pipeline that converts information into actionable memory.
Explore how memory engineering is becoming a critical specialization within AI engineering, requiring new approaches to data architecture, retrieval optimization, and lifecycle management.
Provide practical insights needed to build AI agents that don't just respond intelligently, but learn, adapt, and grow more capable with every interaction.
This work aims to provide AI developers and engineers with foundational insights into agentic memory systems, deepening their understanding of memory engineering, context engineering, and management approaches while advancing toward a comprehensive answer to the essential question: How should we model memory in AI agents to maximize their reliability, believability, and capability?
Why Agent Memory matters in modern AI systems
Software development has undergone a remarkable transformation with artificial intelligence (AI) now at the forefront of application development. Systems built with embedded LLMs don't simply process data—their features and performance depend heavily on contextual information, model reasoning capabilities, and parametric knowledge.
We're observing the evolution from narrow, reactive architectures to sophisticated AI systems that process multi-modal inputs, demonstrate complex reasoning, and operate with goal-oriented behaviors. Applications now incorporate advanced natural language understanding, complex problem-solving workflows, and multi-step task execution that would have been impossible just years ago.
Despite these advanced capabilities, applications remain fundamentally stateless. They lack persistent memory across interactions; cannot accumulate knowledge from previous engagements, and must process each request in isolation.
Without Agent memory, there are several critical limitations:
Inability to maintain conversation continuity - cannot build upon or reference earlier dialogue
No behavioral adaptation - cannot learn from user feedback or adjust approaches
Lack of persistent objectives - cannot maintain goals across sessions
Missing personalization - cannot develop user-specific preferences or understanding
Research validates these limitations: Microsoft and Salesforce's study "LLMs Get Lost in Multi-Turn Conversation" found that LLMs experience significant performance drops in extended conversations, primarily because they make premature assumptions early on and fail to recover when these assumptions prove incorrect. This directly demonstrates the conversational continuity problem identified above.
The research demonstrates that LLMs struggle particularly with "information dispersed across multiple turns," directly validating the essential role of memory systems that can consolidate, organize, and retrieve contextual information effectively. The paper's suggested workarounds—such as starting new conversations when LLMs get lost or manually consolidating information before retrying—represent exactly the type of reliability issues that well-designed memory systems should eliminate. This research highlights why sophisticated memory architectures are crucial for production AI agents. The solution lies in implementing comprehensive agentic memory systems that address each of these limitations directly.
Agentic memory becomes critical as we build more personalized AI systems across various form factors. The ability to maintain user memories enables adaptive learning through each previous interaction, allowing agents to understand individual preferences, communication styles, and behavioral patterns. Without access to past data from prior conversations, even the most sophisticated agents cannot provide the personalized experiences users increasingly expect from AI systems.
Data retrieval serves as a fundamental component of agent memory architecture, but its implementation extends far beyond simple database queries. Effective data retrieval systems must intelligently surface relevant context from vast stores of user memories and past data. This requires sophisticated algorithms that can identify which elements from previous conversations provide the most relevant context for current interactions, enabling true adaptive learning that compounds over time.
What these advanced systems require is not just data in its traditional sense, but a higher-order form of information retrieval, organization, and retention that mirrors human cognitive processes—what we now recognize as Agent Memory. This represents the fundamental shift from stateless applications to truly intelligent agents capable of learning, adapting, and evolving with each interaction.
When does data become memory?
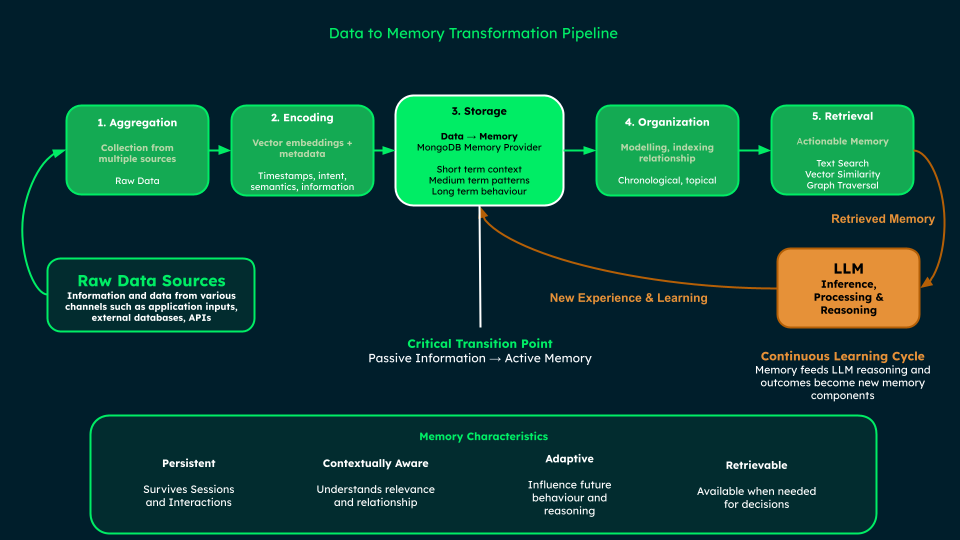
Data-to-Memory Transformation Pipeline illustrating how raw data from multiple sources is aggregated, encoded, stored, organized, and retrieved to create persistent, contextually aware, adaptive, and retrievable memory that feeds LLM reasoning in a continuous learning cycle.
Within AI application development, particularly in agent engineering, "data" and "memory" are often used interchangeably. However, understanding their conceptual distinction is crucial for building effective AI agents. It’s fair to refer to memory as simply data, because it is.
On that note, data becomes memory through a five-stage transformation pipeline that incrementally transforms raw inputs into functional memory units.
A memory unit can be understood as a structured container that holds not just information, but also the metadata and relationships that make that information useful for agent reasoning. Unlike traditional data storage treats all information as equally accessible and static, memory units carry attributes like temporal context (when the information was learned), strength indicators (how relevant or reliable the information is), associative links (how it connects to other memories), semantic contextual data (meaning captured), and retrieval metadata (how and when it should be accessed). Examples of memory units for various memory types are shown in later sections of this piece.
Memory units is also synonymous with memory blocks, another term used to describe a single discrete piece of structured information within an agent's memory system that support fundamental memory operations including storage, retrieval, and update memory functions, while maintaining the current memory unit/block contextual relationships to other memory components.
More broadly, memory units encapsulate not just data but the cognitive attributes and metadata essential for intelligent reasoning. Consider a customer chatbot on an e-commerce website to understand the stages that transform data into memory units:
Aggregation: Collecting data from various sources—customer chat input, order database records, product catalog information, and previous conversational history. At this point, all information is classified as raw data.
Encoding: Transforming data into processable formats. The chatbot converts text messages into vector embeddings that capture semantic meaning, while adding contextual metadata like timestamps and intent classification.
Storage: Persisting encoded data in optimized layers where the boundary between data and memory emerges. How information is modeled and stored directly impacts its use within the agent's context window. This is where MongoDB's role as a memory provider for AI agents and agentic systems becomes evident—a unified database system that can handle short-term conversation context, medium-term interaction patterns, and long-term behavioral data in a single platform, avoiding the scalability issues and tech sprawl of maintaining separate specialized databases. This unified approach creates a hierarchical memory architecture while providing the security guarantees essential for production AI systems.
Organization: Structuring data through informed design of modeling, indexing, and relationships. Conversation histories are organized chronologically, product information is structured hierarchically in nested documents, and multiple dimensions index product order data.
Retrieval: The most crucial stage where information becomes actionable memory through sophisticated memory operations. The chatbot employs the core retrieval methods essential to modern AI applications—traditional text search for exact matches, vector search for semantic similarity, and graph traversal for complex relationships.
Effectively, data becomes memory when it transitions from passive information to an active, intentionally persisted component that can be retrieved and utilized to inform an agent's behavior and reasoning. This transformation occurs at the point of storage, where data is collected and stored with the intent of enabling adaptation and coherent interaction over time.
Understanding this data-to-memory transformation provides the foundation for examining how memory functions within AI agents specifically. While we've explored the general principles of how information becomes memory, the practical implementation of memory systems in AI agents requires more precise definitions and architectural considerations.
What is Agent Memory
When exploring memory in AI applications today, we often encounter terms like LLM memory, Agent memory, and AI memory. Understanding their distinctions is key.
LLM memory refers to the information and knowledge captured within the large language models themselves. It exists in two primary layers:
Parametric Memory (Weights and parameters): The knowledge encoded in the model's network parameters during training phases such as pre-training, supervised fine-tuning, and alignment training (including RLHF and instruction tuning). This form of memory remains static during inference but can be updated through additional training procedures such as fine-tuning or continued pre-training.
Contextual Memory (Context Window): The transient information the model can access during inference, including the current input and conversation history within token limits. This information persists only within the current session and is lost when the session ends or when older tokens are truncated due to context window constraints–unless retained externally.
Crucially, LLM memory isn't Agent memory, but a critical component of it.
An LLM is a component—the cognitive engine—of a broader AI agent. The limitations of LLM memory, such as a bounded context window and stateless inference, necessitate a more robust, persistent memory system for the agent to achieve true continuity, adaptability, and, essentially, learn.
This is where external memory becomes essential. In its simplest form, external memory is what AI Engineers leverage when implementing RAG applications and pipelines—typically involving retrieving information from a database outside the LLM and concatenating it with a user prompt before conducting inference. However, for truly intelligent agents, we need memory systems that go far beyond basic retrieval to enable genuine learning and adaptation.
This brings us to the definition of an AI Agent itself. Although there have been debates around the definition of an AI agent, we can collectively agree that AI agents are information explorers that require essential capabilities before venturing into complex problem-solving terrain.
We define an AI Agent as a computational entity aware of its environment and equipped with four core faculties:
cognitive abilities via an LLM
action through tool use
memory for short-term and long-term persistence of information,
and perception through multi-modal inputs.
These capabilities must work cohesively for agents to navigate the complex landscape of real-world problem-solving effectively. We continue to hold the strong conviction that long-term memory is non-negotiable for an agent to deliver meaningful value. An agent without an augmented memory is merely a reflex agent, reacting only to the current input without learning from the previous iterations or sessions.
Therefore, returning to our earlier definition of Agent Memory as both the LLM memory and the external memory management system that enables knowledge accumulation and behavioral adaptation, we can see how this definition encompasses the essential capabilities that distinguish true AI agents from stateless applications.
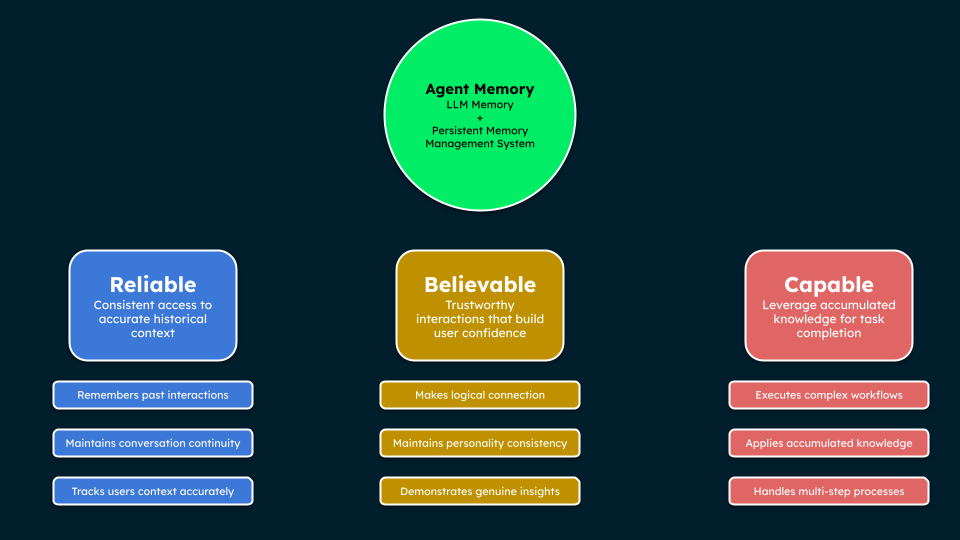
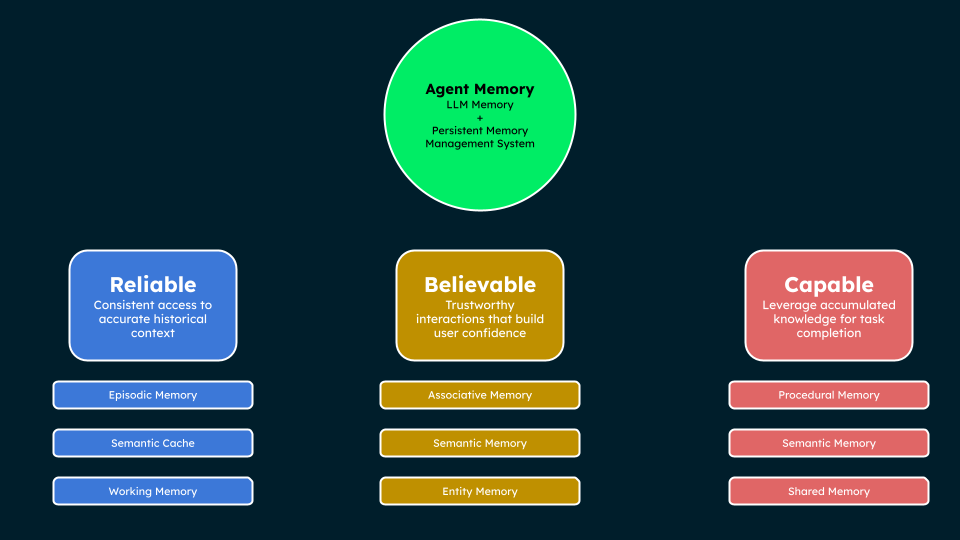
Agent Memory combines LLM memory with persistent memory management to enable reliability, believability, and capability—ensuring accurate historical context, trustworthy interactions, and effective task execution through accumulated knowledge.
Agent memory is a core component required for building agents that are reliable, believable, and capable.
Reliable: Through consistent access to accurate historical context.
Believable: Through consistent, trustworthy interactions that build user confidence.
Capable: Through the ability to leverage accumulated knowledge and resources for task completion.
As long as LLM context windows remain finite, the development of intelligent external memory systems—an exocortex for LLMs—will remain a critical frontier of research, positioning memory at the core of next-generation AI systems.
The interchangeability between "AI Memory" and "Agent Memory" reflects a fundamental shift in how we conceptualize software architecture. As our industry has increasingly embraced the reality that the dominant form factor of intelligent software will be primarily agentic, the distinction between AI systems and agent systems has become largely semantic.
Traditional software applications are evolving into autonomous entities capable of reasoning, planning, and executing complex workflows—essentially becoming agents by default. This transformation means that when we discuss AI memory systems, we are inherently discussing agent memory systems, since the AI applications of tomorrow will predominantly operate as intelligent agents rather than passive tools.
The convergence of these terms signals not just linguistic evolution, but a foundational shift toward software that thinks, remembers, and acts with increasing autonomy in pursuit of user objectives.
Key memory types in AI agents
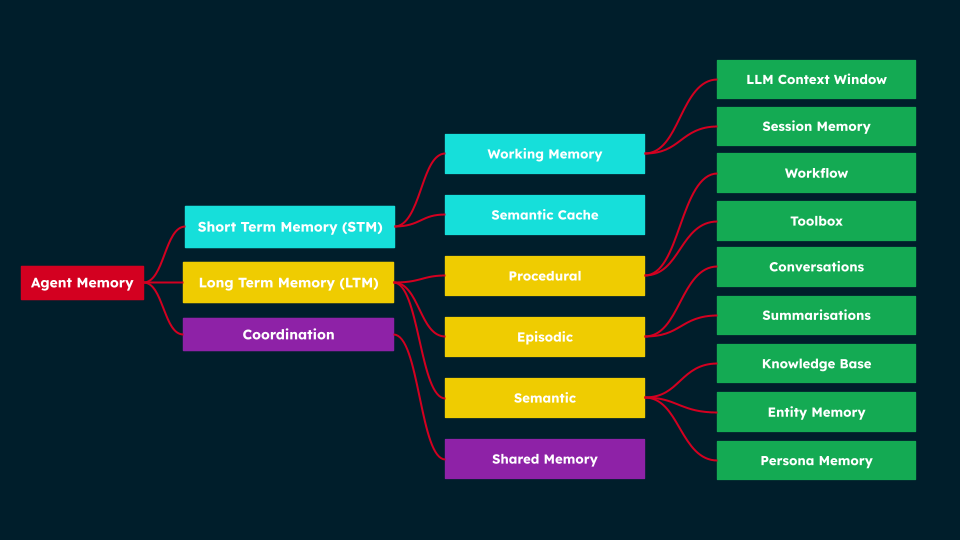
Structure of Agent Memory, showing how short-term, long-term, and shared memory types connect to specialized components that support tasks like workflows, conversations, and persona management.
Having established the definition of Agent Memory and distinguished it from LLM memory—while noting its interchangeability with AI memory—we can now examine the key types of memory that comprise agentic Memory systems.
The performance of an LLM typically degrades as the amount of content in its context window increases. Research shows that information placed around the midpoint of a long context is especially difficult to retrieve, because attention mechanisms struggle to prioritize and maintain focus on relevant tokens buried deep within extensive inputs. This “lost in the middle” problem leads to decreased retrieval accuracy and weaker reasoning performance.
MongoDB's Chief AI Scientist, Tengyu Ma, often uses the library analogy: you don't expect a librarian to be aware of the contents of every single book in the library simultaneously just to direct you to the right one.
Similarly, just as a librarian relies on catalogs, indexes, and reference guides to manage and retrieve information efficiently, understanding the different types of memory becomes essential for effective agent design and engineering. Memories in agentic systems are distinguished by their temporal (how long they last) and functional (what they are for) characteristics, with each type serving specific roles in decision making and knowledge retention.
A simple entry point is the temporal distinction:
Short-term memory (STM) - Information retained for immediate use during active processing. Examples of this are working memory, semantic cache, temporary file systems, etc.
Long-term memory (LTM) - Information persistently stored for extended periods and future retrieval. Examples are stored conversational history, entity memory, knowledge bases, etc.
Short-Term Memory functional forms
Focused view of Agent Memory highlighting short-term memory pathways, linking working memory and semantic cache to components like the LLM context window, session memory, and related functions.
Short-term Memory serves as temporary storage for information currently being processed or recently accessed. Memory units within short-term memory typically have limited lifespans ranging from seconds to days, depending on the specific use case, implementation requirements, and application mode. And while working memory and short-term memory are often used interchangeably in literature, let’s make a clear distinction: working memory represents a specialized, functional subset of short-term memory designed for active information manipulation during task execution, whereas short-term memory encompasses the broader category of temporary information retention across various operational contexts.
Working Memory
Working memory can be thought of as the agent's "scratchpad" for active information manipulation during a task. It's a partitioned area in the LLM's context window or a temporary file that exists only for the duration of a session, maintaining chat history and enabling real-time memory operations to update memory blocks as conversations progress. Working memory in some technical literature is also referred to as active memory.
Research efforts like MemGPT implement a "working context" to manage this active workspace systematically. For example, a research agent analyzing market trends would use their working memory to hold onto search results, identify companies, and synthesize notes for the report they're generating. This enables real-time decision-making based on immediately available information. Additionally, in the absence of an external memory system, an LLM’s working memory is effectively limited to its context window. Therefore, the main types of working memory we see in AI applications are session-based, temporary file systems, and LLM context window dependent.
Semantic Cache
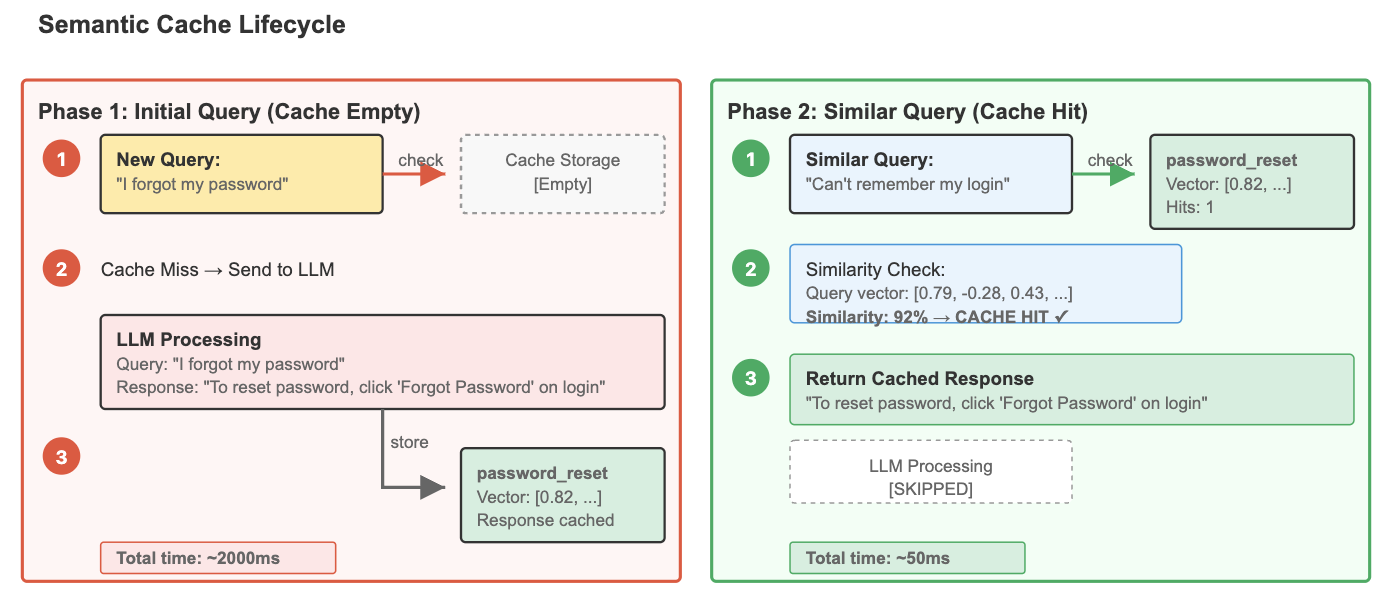
Semantic Cache Lifecycle: Two-phase diagram showing how an initial query triggers LLM processing and cache storage, while similar future queries are matched via vector similarity and answered instantly from the cache.
Semantic cache stores recent prompts and their corresponding LLM responses. When a similar query arrives, the system retrieves the cached response instead of reprocessing it, saving time and computational cost. It uses vector similarity to match the semantic meaning of queries, not just exact keyword matches. A customer support bot handling password resets would use a semantic cache to instantly answer the same question phrased in dozens of different ways—"I forgot my password," "Can't remember my login," or "Need to reset my account access"—all triggering the same cached response. This immediate retrieval of pre-computed responses mirrors what psychologist Daniel Kahneman describes as System 1 thinking in "Thinking, Fast and Slow"—the fast, automatic, intuitive cognitive processes that provide instant responses without deliberate reasoning.
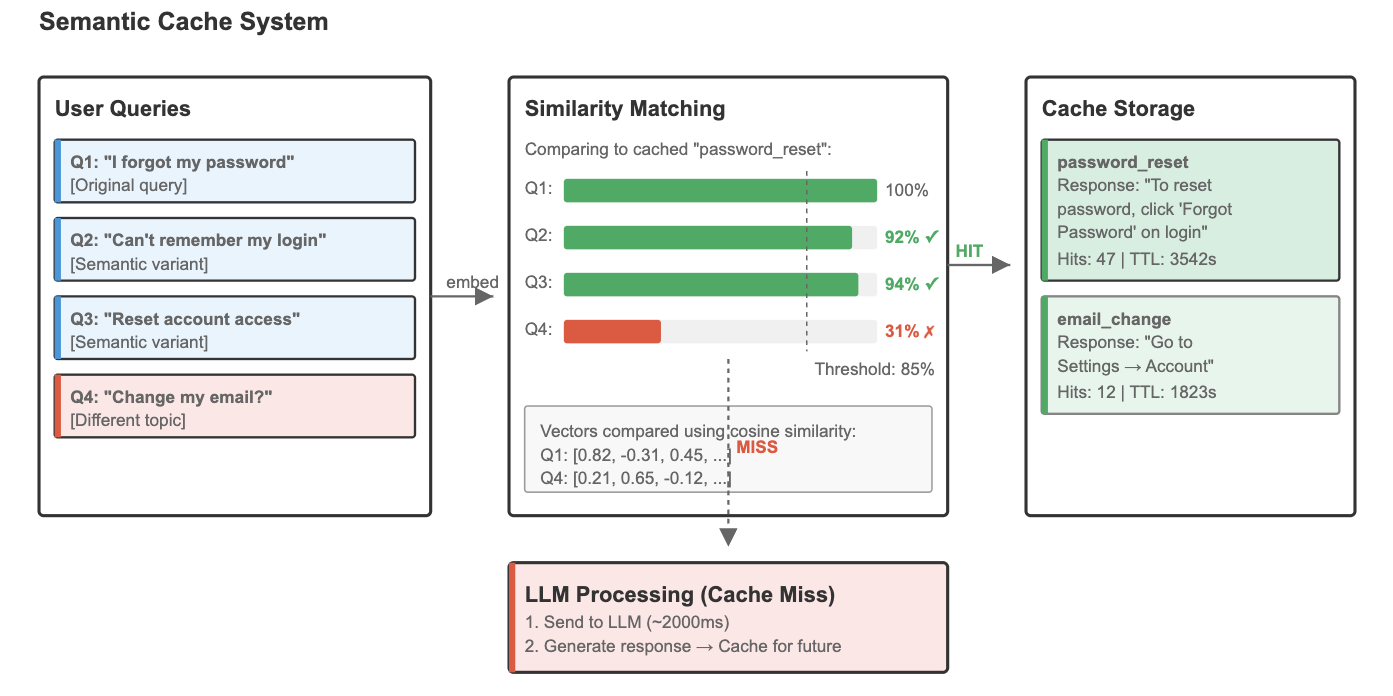
Semantic Cache System: Diagram showing how user queries are embedded, compared to cached entries via cosine similarity, and either returned instantly on a match or sent to the LLM on a miss.
Semantic cache in practical scenarios presents a significant advancement over traditional keyword-based caching systems, leveraging the semantic understanding capabilities of embedding models to create more intelligent and effective memory systems. An implementation of semantic cache leveraging MongoDB Atlas and Langchain can be found here. We also previously sat with Cisco's Agent Engineer, where we discussed how they built their production chatbot and agentic platform with MongoDB and semantic cache.
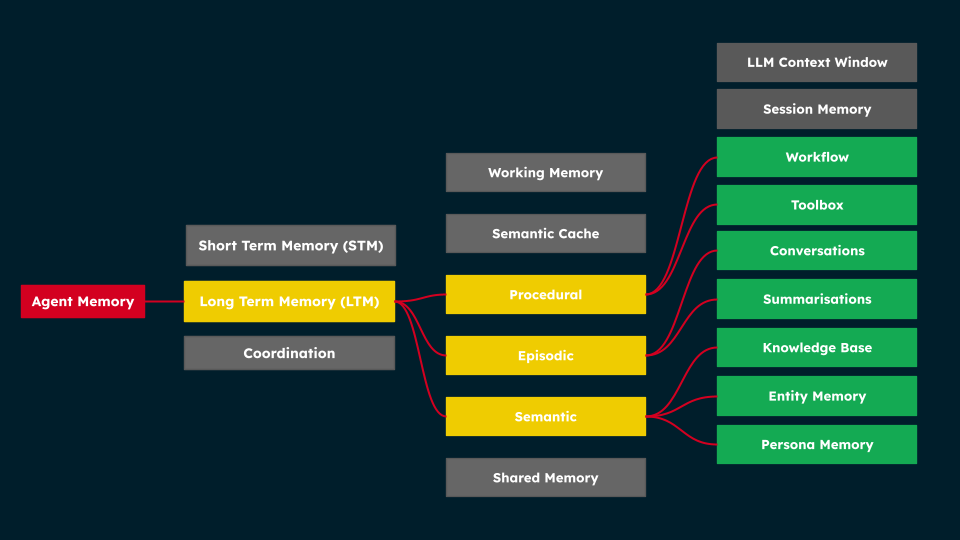
Long-Term Memory functional forms
Focused view of Agent Memory highlighting long-term memory pathways, where procedural, episodic, and semantic memory connect to functions such as workflows, conversations, knowledge bases, and persona memory.
Long-term memory is the foundational knowledge base of an agent, enabling continuity and learning over extended periods. It encompasses several functional forms, each demanding specific storage and retrieval capabilities. A unified data platform like MongoDB is advantageous here, as it can handle the diverse requirements of different LTM types—from vector search for semantic memory to graph traversal for associative memory—within a single system, reducing complexity and preventing tech stack sprawl.
Episodic Memory
Episodic memory is the agent's record of specific events and interactions, analogous to a human's autobiographical memory. It stores conversational history, summaries of key events, or discrete occurrences with attached metadata (timestamps, participants). A customer service agent uses episodic memory to recall a specific user's past support tickets, accessing relevant facts to provide personalized and context-aware service. Common types of episodic memories include conversational and summary types, also referred to as observations.
Conversational memory: A subset of episodic memory specifically focused on storing chat history, maintaining complete conversation transcripts with speaker turns, and contextual metadata stored as discrete memory blocks. This enables agents to maintain conversational coherence, reference earlier discussions, and adapt communication style based on historical interaction patterns with specific users. The system continuously performs memory operations to update memory blocks as new dialogue occurs, ensuring chat history remains current and contextually relevant.
Summarization memory: This is a compressed representation of longer interactions or documents that preserves key insights while reducing storage and retrieval overhead. Summarization memory maintains distilled versions of full transcripts that capture essential facts, decisions, and outcomes—allowing agents to quickly reference the gist of past interactions without processing full historical records.
Depiction of a memory unit being extracted from the LLM’s context window
Episodic memory in agents—covering conversational memory and summarisation—works as follows. The system records turn-by-turn interactions between the agent and a human (or other workflow entities such as tools or peer agents). Periodically, the ongoing conversation is compressed into a concise summary and stored in a dedicated summarisation store. Summarisation can be triggered by context-window token-limit thresholds, importance heuristics, a schedule, or exposed as a tool the agent can invoke at its discretion. This leverages the LLM’s ability to process input, reason over it, and act based on signals present in the current context and environment. In future pieces, we will explore summarisation techniques and recommended best practices in more detail.
Semantic Memory
Semantic memory can be seen as the agent's repository of organized knowledge about facts, concepts, and relationships, independent of specific events. This includes knowledge bases, information about specific entities (entity memory), and role-based knowledge that steers agents to certain behavior (persona memory). Semantic memory can be understood as the structured "world knowledge" that allows an agent to reason consistently. The most common implementation we see is for RAG systems, where vector embeddings of factual documents are stored and retrieved in a structured format.
Typical forms of semantic memory are:
Knowledge base: A formally organized component of semantic memory containing verified, structured information typically ingested from authoritative sources. Knowledge bases are often pre-populated with domain expertise, documentation, policies, and reference materials that provide the foundational truth the agent operates from, such as company policies, technical specifications, or scientific facts.
Entity memory: Maintains detailed profiles of specific entities (people, organizations, products, concepts), including their attributes, relationships, and historical interactions. This memory enables personalized interactions and relationship-aware responses in AI agents' interactions.
Persona memory: Stores the encoded behavioral patterns, communication style, and role-specific knowledge that defines its consistent personality and expertise.
Associative memory: The ability to link and traverse relationships between stored facts, enabling pattern discovery and inference. Associative functions are often implemented using graph-like structures within a semantic memory framework, allowing agents to “connect the dots” between related concepts. MongoDB’s document model and make it well-suited for these hybrid semantic–associative designs.
Procedural Memory
This is the agent's repository of learned skills, routines, decision trees, workflows, and multi-step processes. It stores the sequences of actions required to complete complex, multi-step tasks without explicit instructions. Just as humans learn to ride a bike automatically, agents with procedural memory can execute established routines.
Examples of procedural memory include toolbox memory (knowledge of available tools and their use) and workflow memory (captured data for recurring processes). A software deployment agent uses procedural memory to follow release protocols automatically.
In the code snippet below the `Toolbox` class serves as the toolbox memory component, acting as a registry that allows agents to register Python functions as discoverable tools with searchable metadata, storing both the actual callable functions in memory and their semantic embeddings in persistent storage so the agent can automatically find and execute the right tool based on task requirements without manual lookup. More specifically, this can also scale tool use in an agentic system by retrieving semantically similar subsets of tools in the toolbox memory that match the input query or objective.
During the implementation of memory types and the conversion of context window content into memory units, AI Engineers can identify specific flags in LLM execution responses and establish processes for extracting key information based on response attributes.
The code snippet below demonstrates this extraction process in action: after each function call execution, the system automatically captures workflow steps by appending results to the message history, then extracts key metadata including the tool ID, arguments, results, timestamp, and any error messages to create structured memory units that are stored as part of the complete workflow when execution finishes. Below is how this approach applies to workflow memory and its associated memory units.
Workflow Extraction Process
LLM Response Processing: When LLM requests tool calls, the system doesn't wait for a complete response but processes each tool call immediately
Real-Time Workflow Building: For each tool execution:
Creates a workflow step with: _id, arguments, result, timestamp, error
Tracks execution outcome (SUCCESS/FAILURE)
Updates workflow metadata
Step Data Structure: Each workflow memory unit contains:
4. Memory Storage: The Complete workflow is stored in MemoryType.WORKFLOW_MEMORY with embedding for semantic retrieval
5. Future Reference: Stored workflows are retrieved in future queries to provide execution context and learning from past experiences
Shared Memory
Focused view of Agent Memory highlighting coordination through shared memory, enabling multiple components to access and contribute to common information for synchronized operations.
Shared memory, commonly found in multi-agent systems, enables coordination by providing a collaborative space accessible to multiple agents simultaneously. It allows distributed teams of agents to coordinate activities, share findings and plans, and maintain a synchronized state across the system. Shared memory can be configured as either long-term or short-term depending on the use case and scenario—for example, persisting strategic goals over the lifetime of a project (long-term) versus holding intermediate search results during a single research session (short-term). For instance, a research team of agents—one specializing in searching academic papers, another for verifying citations, and a third for synthesizing findings—would utilize shared memory to avoid duplicating work and build incrementally on each other’s discoveries in real time.
In this memory type, we find that ACID compliance (Atomicity, Consistency, Isolation, Durability) at the database level becomes critical to prevent race conditions and ensure data integrity as multiple agents simultaneously read from and write to the shared memory space. Without these guarantees, agents might overwrite each other’s contributions, work with stale data, or encounter inconsistent states that could compromise the entire system’s reliability.
It's crucial to understand that these memory types are conceptual blueprints inspired by human cognition, not direct biological replications. Each memory type serves distinct cognitive functions in an AI agent, and their coordination determines an agent's ability to demonstrate what we referred to earlier, reliability, believability, and capability–let’s refer to this as the RBCs of AI agents.
Agent Memory enables reliability, believability, and capability by leveraging different memory types—such as episodic, semantic, associative, entity, procedural, and shared memory—to provide accurate context, trustworthy interactions, and effective task execution.
Application modes shape Agent memory
Through MongoDB's work with numerous companies building AI applications and agentic systems, we have observed that organizations consistently apply agentic solutions to similar types of use cases. While each implementation has its unique variations, these recurring use case patterns have led us to identify what we call "application modes"—common problem domains where agentic architectures consistently provide value.
Application mode refers to the fundamental operational pattern that characterizes how an AI agent interacts with its environment, encompassing specific behavioral expectations, interaction styles, and memory architecture requirements. This pattern is domain-agnostic, focusing on how the agent operates rather than the specific field or subject matter it addresses.
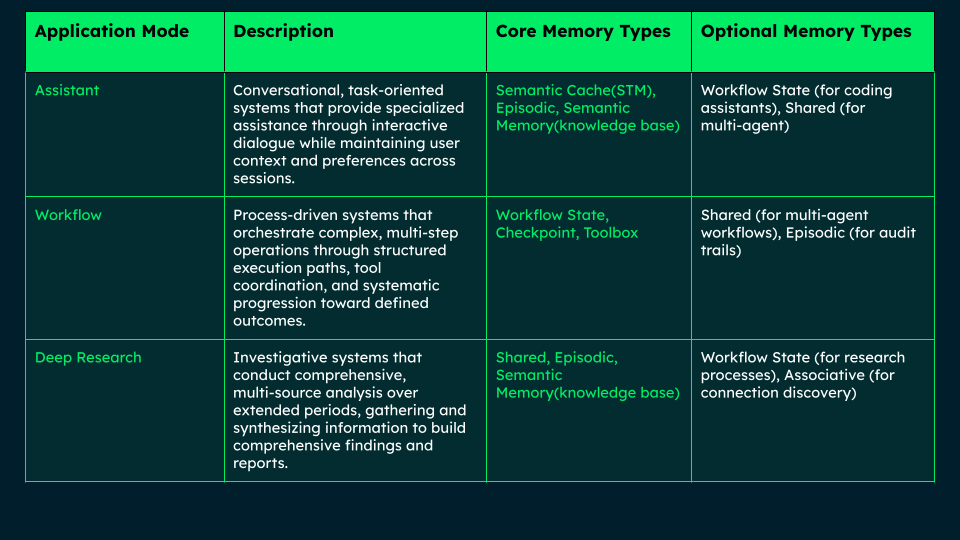
Based on our observations across diverse implementations, three core application modes emerge, each representing distinct operational patterns with specific memory architecture requirements:
Assistant Mode: Conversational, task-oriented interactions where agents provide specialized assistance through interactive dialogue while maintaining user context and preferences across sessions.
Workflow Mode: Process-driven operations where agents orchestrate complex, multi-step procedures through structured execution paths with systematic state tracking and tool coordination.
Deep Research Mode: Investigative operations involving comprehensive, multi-source analysis over extended timeframes with progressive knowledge building and synthesis capabilities.
These distinct application modes require tailored memory systems specifically optimized for their unique operational characteristics. Each mode demands particular memory types with well-defined schemas and attributes—some attributes being explicit structural elements (such as timestamps, entity relationships, and access patterns), while others represent implicit properties that emerge from usage patterns and semantic relationships within the stored data.
Application Modes and Memory Architecture Requirements for AI Agents.
Below, we focus extensively on two modes: Assistant and Workflow, as these represent the most commonly requested use cases in current enterprise implementations. Deep Research mode, while conceptually powerful, remains a niche application that is both technically challenging to implement and computationally intensive given current LLM limitations.
For now, organizations achieve the most significant immediate value by focusing on Assistant and Workflow modes, which provide clear ROI through enhanced user interactions and process automation. Deep Research capabilities often emerge organically from well-implemented Assistant modes as AI Engineering teams become more sophisticated in their agentic memory architectures.
Assistant Mode
Assistant Mode is designed for conversational, task-oriented interactions where agents provide specialized assistance while maintaining user context and relationship continuity. This mode's primary objective is to create agents that can engage in meaningful dialogue while maintaining personality consistency and adaptive responses based on user needs.
This mode demands multiple specialized memory types working in coordination. Contextual memory maintains detailed conversation history with temporal context, enabling agents to reference specific past interactions and build upon previous discussions. Semantic cache stores dialogue patterns, user preferences, and communication styles discovered through interaction history. Shared memory ensures consistent personality traits and behavioral patterns that users can rely upon for predictable, authentic interactions.
The memory system must support relationship dynamics that evolve over time, requiring systems that can identify and reinforce interaction patterns while learning from user feedback. Memory compression techniques become essential to distill lengthy interaction histories into key relationship insights and user preferences, ensuring important contextual information remains accessible across extended engagements.
Within Assistant Mode, the specific role determines memory system requirements. Research assistants must synthesize information from multiple sources and maintain comprehensive investigation states, while coding assistants execute complex procedures requiring step-by-step coordination and tool management. Research assistants typically employ distributed memory architectures, particularly in multi-agent scenarios where specialized agents handle distinct workflow aspects. Coding assistants commonly use single-agent architectures requiring toolbox memory for maintaining development tools and their capabilities, alongside checkpoint memory for tracking multi-step development processes.
Workflow Mode
Workflow Mode is designed for completing multi-step processes and orchestrating complex operational sequences, requiring sophisticated state management and process coordination capabilities. The primary objective is ensuring reliable, deterministic execution of intricate procedures while maintaining operational integrity and error recovery across multiple execution stages.
This mode demands a memory architecture that can track process state, manage intermediate results, and coordinate tool usage throughout extended workflows. Workflow state memory implements attributes capturing current execution status, completed steps, pending actions, and decision points, enabling agents to resume operations after interruptions or failures. Checkpoint memory provides systematic snapshots of workflow progress, supporting recovery and rollback capabilities when needed.
The combination of workflow state and checkpoint memory with toolbox memory provides agents with learned optimizations from previous executions, enabling continuous improvement in workflow efficiency. The memory architecture must support complex dependency management, where subsequent steps rely on outputs from previous stages, requiring careful state preservation and data flow coordination. We worked closely with the Langchain engineering team to implement one of the first state checkpointers for workflows and agents built with LangGraph.
While these application modes provide a useful framework for designing memory architectures, they should be viewed as adaptable guidelines rather than rigid rules. Each AI implementation will have unique operational requirements, and memory strategies should be tailored to the specific context, constraints, and goals of the system. The real value in identifying application modes lies in providing a shared language and reference model that accelerates design decisions, ensures architectural consistency, and helps teams align on the memory capabilities required to deliver reliable, efficient, and impactful AI agents.
Memory Engineering
As AI agents evolve from stateless tools into learning entities, the profound challenge of building their memory has spurred the need for a dedicated specialization: Memory Engineering. This discipline moves beyond basic data storage to encompass the intricate task of designing cognitive-inspired memory architectures. It involves optimizing retrieval and synthesis mechanisms and implementing sophisticated lifecycle management strategies, such as active reflection and managed forgetting, to ensure that as an agent experiences more, it grows wiser, not just more cluttered with information.
This specialization addresses fundamentally different challenges from general agent engineering. While AI engineers building agents focus on business logic, integrations, and user-facing functionality, memory engineering operates at the foundational architecture level, answering the question: "How do we model and manage memory in agents?" This involves a spectrum of complexity, from simple context window management to sophisticated systems where memories are dynamically modified, intelligently enriched, and retrieved via multi-model retrieval techniques.
The discipline is evolving steadily. Early AI development efforts focused on prompt engineering. The focus has since shifted to context engineering and context management. As noted by research from Anthropic and Cognition AI, simply having a large context window is insufficient; success depends on "careful context management strategies" that curate and prioritize what information the agent attends to. This requires advanced memory engineering, such as creating systems that intelligently compress content in running context windows into key insights that are persisted.
This evolution leads to the broader discipline of Memory Management—the operational practice of orchestrating, optimizing, and governing an agent's memory architecture. Key engineering challenges include:
Memory lifecycle management: Deciding when to consolidate, archive, or "forget" information.
Selecting Memory types: Establishing the appropriate primary and complementary memory types to utilize for the application being developed.
Memory fragmentation: Avoiding scattered storage of related information across different systems, which makes retrieval inefficient.
Forgetting vs. Deleting: Implementing intelligent degradation of information (forgetting) rather than complete removal (deleting), which mimics human memory and preserves valuable long-term patterns. For example, a coding assistant might gradually reduce the memory strength attribute of an old code pattern or function usage, making it less likely to be retrieved during active development sessions, but the memory unit remains intact and can be re-strengthened if the current context causes it to be retrieved again or the developer explicitly references it again.
Evaluation of Agent Memory: Systematically measuring the performance of memory systems.
As organizations scale their AI implementations, the need for this memory engineering specialization will become undeniable. Enterprise development teams will likely either form dedicated AI Memory teams or find that memory engineering becomes the dominant and most critical component of the modern AI Engineer's role.
How MongoDB enables Agent Memory
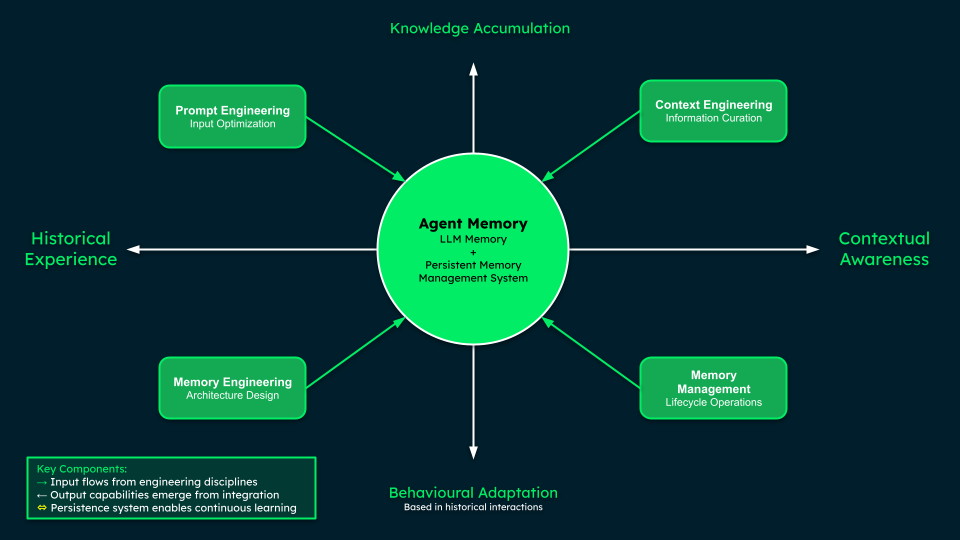
Agent Memory integrates LLM memory with persistent memory management, combining prompt engineering, context engineering, memory management, and engineering to enable knowledge accumulation, contextual awareness, behavioural adaptation, and learning from historical experience.
As we progress from stateless AI applications to stateful AI agents with continuous learning paradigms, the database's role is fundamentally evolving. It is transforming from a simple data store into a core component of intelligent agentic systems. The database is becoming the memory provider for AI agents and agentic systems.
This transformation aligns with the evolution of AI engineering disciplines we've discussed—from prompt engineering to context engineering, agent engineering, and now memory engineering. Each discipline requires sophisticated data management capabilities that traditional databases weren't designed to handle.
The fundamental distinction between these approaches lies in their core architectural intent:
Traditional databases were designed for transactional systems where data integrity and consistency are paramount. They excel at storing structured information and executing complex queries, but they treat all data as equally important and static over time.
Specialized databases emerged to solve specific problems: vector databases for finding semantically similar information in high-dimensional space, and graph databases for enabling efficient relationship traversal and pattern discovery. They represent significant advancements for AI applications—vector databases enabling efficient similarity search across millions of embeddings, while graph databases excel at exploring complex relationships and multi-hop connections between entities. However, they remain fundamentally single-purpose tools focused exclusively on their specialized operations: vector similarity or graph traversal.
Throughout this piece, we've demonstrated that agent memory is not monolithic. A one-size-fits-all approach fails because different memory types have distinct requirements. Contextual memory needs structured logs with timestamps. Semantic cache requires efficient vector search alongside rich metadata for hybrid retrieval. Workflow state demands complex document relationships and graph traversal capabilities.
Consider a customer service scenario: In a traditional database, each interaction might be stored as a separate record with timestamps. To understand a user's history, you'd query for all related records and manually piece together the narrative. There's no inherent understanding of which information is most relevant or how preferences have evolved.
A vector database could store embeddings of past conversations and retrieve semantically similar interactions. This provides better context than keyword matching, but it can't distinguish between "John preferred Italian food last month" and "John now prefers Thai food"—both statements about food preferences would cluster similarly in vector space.
An Agent Memory system would maintain these as distinct, temporally-ordered memories with different strength attributes. As the agent observes John consistently choosing Thai restaurants, the "Italian preference" memory would gradually weaken while the "Thai preference" memory strengthens. The system understands not just what John said, but how his preferences have evolved and which information is currently most predictive of his behavior.
While PostgreSQL can technically perform text search (via tsvector), vector similarity (via pgvector with HNSW), and graph traversals (via recursive CTEs or extensions like Apache AGE), these capabilities require orchestrating multiple extensions, query patterns, and optimization strategies. For memory engineering teams who need to rapidly experiment with hybrid retrieval patterns combining semantic similarity, metadata filtering, and relationship traversal, this fragmented approach creates unnecessary complexity and longer development cycles.
Additionally, the experimental nature of agentic memory architectures often requires restructuring relationships between different memory types—not just individual document schemas—which can still require careful migration planning on large, heavily-indexed tables.
This fragmented approach we described with PostgreSQL exemplifies precisely why MongoDB is increasingly adopted as a memory provider for leading AI/Agent frameworks, including LangGraph, Agno, Mastra, and many others. Rather than providing a restrictive, black-box memory solution, MongoDB Atlas empowers developers to dive deep into memory engineering by providing all the essential capabilities:
Multi-model Retrieval Mechanisms: Supporting traditional text search, vector similarity search, and graph traversal within a unified query interface
Flexible Document Model: The MongoDB JSON-like document model natively stores diverse and evolving memory types—from conversational snippets to complex procedural knowledge—without rigid schemas that lock developers into predetermined structures
Advanced Optimization Features: Including quantization for efficient vector storage, dedicated search nodes for isolated operations, and intelligent indexing strategies
MongoDB’s recent acquisition of Voyage AI represents a significant step forward, bringing state-of-the-art embedding models and rerankers directly into the database platform. This integration will dramatically reduce application code complexity for RAG pipelines and agentic applications. Still, more importantly, it transforms MongoDB into a solution where developers simply provide data and receive sophisticated memory unit components and capabilities in return.
Rather than forcing AI engineers to stitch together multiple specialized databases and manage complex embedding pipelines, MongoDB Atlas will handle the entire data-to-memory transformation pipeline—from ingestion and vectorization to storage, organization, and AI-powered retrieval.
The choice between these approaches ultimately depends on whether you're building information systems or intelligent agents.
For traditional applications requiring semantic search, vector databases provide excellent focused capabilities. For applications requiring adaptive intelligence that learns and evolves, MongoDB provides the cognitive architecture that transforms stateless applications into genuinely intelligent agents.
This unified approach enables the memory engineering specialization we've explored, providing the technical foundation necessary to build reliable, believable, and capable AI agents. To explore memory engineering further, start experimenting with memory architectures using MongoDB Atlas or review our detailed tutorials available at AI Learning Hub.
FAQs
Memory type is a specialized cognitive function within an AI agent's memory, much like how human memory has different systems for different purposes. A memory type defines both the temporal characteristics (how long information lasts) and functional characteristics (what specific purpose it serves) of stored information within an agent's memory architecture.
Common high-level memory types are short-term and long-term memory, which have distinct memory types within them.
Short-term memory types handle immediate, temporary information needs. Working Memory acts as the agent's "scratchpad" for active information manipulation during current tasks - imagine it as the mental workspace where an agent holds relevant details while solving a problem. Semantic Cache stores recent query-response pairs, enabling instant retrieval of similar requests without reprocessing - like having quick answers ready for frequently asked questions. Shared Memory enables coordination between multiple agents by providing a collaborative workspace where different agents can access and contribute information simultaneously.
Long-term memory types provide the foundation for persistent learning and adaptation. Episodic Memory maintains records of specific events and interactions, similar to your autobiographical memories of particular conversations or experiences. Semantic Memory serves as the agent's organized knowledge repository about facts, concepts, and relationships - think of it as a well-structured library of world knowledge. Procedural Memory stores workflows and skills, enabling agents to execute complex multi-step processes automatically, much like how you can ride a bicycle without consciously thinking about each movement. Finally, Associative Memory creates and maintains relationships between different pieces of information, allowing agents to "connect the dots" and make inferences by traversing these connections.
An application mode represents the fundamental operational pattern that characterizes how an AI agent interacts with its environment and users. Think of it as the agent's primary "way of being" - the behavioral framework that shapes how it approaches problems, manages information, and delivers value.
There are three core application modes based on extensive observation of real-world implementations. Assistant Mode focuses on conversational, task-oriented interactions where agents provide specialized help while building and maintaining relationships with users over time. This mode emphasizes personality consistency and adaptive responses based on evolving user needs. Workflow Mode centers on orchestrating complex, multi-step processes with systematic coordination and state management - imagine an agent that can manage entire business procedures from start to finish. Deep Research Mode involves comprehensive, multi-source analysis over extended periods, requiring progressive knowledge building and synthesis capabilities.
Understanding application modes helps you choose the right memory architecture for your specific use case, since each mode demands different combinations of memory types and optimization strategies.
Agent Memory (and Memory Management) is a computational exocortex for AI agents—a dynamic, systematic process that integrates an agent’s LLM memory (context window and parametric weights) with a persistent memory management system to encode, store, retrieve, and synthesize experiences. Inspired by human cognitive memory, it enables agents to accumulate knowledge, maintain conversational and task continuity, and adapt behavior based on history—making them more reliable, believable, and capable.
Memory units are the fundamental building block of agent memory - the smallest discrete piece of information that has been transformed from raw data into actionable memory. A memory unit is a structured container that holds not just information, but also the metadata and relationships that make that information useful for agent reasoning. Unlike simple data records, memory units carry attributes like temporal context (when the information was learned), strength indicators (how relevant or reliable the information is), associative links (how it connects to other memories), and retrieval metadata (how and when it should be accessed).
LLM memory exists within the language model itself and operates in two distinct layers. Parametric Memory represents the knowledge encoded in the model's neural network weights during training phases - this is the "baked-in" knowledge that remains static during inference but represents the model's core understanding of language, facts, and patterns learned from training data. Context window memory refers to the transient information the model can access during a single session within its context window limits - essentially the "working memory" of the current conversation that disappears when the session ends or when older information gets pushed out due to token limits.
Agent Memory is a combination of both the LLM memory and an external persistence management system that provides a computational exocortex that enables true continuity and learning within AI Agents. While the LLM serves as the cognitive engine processing information and generating responses, Agent Memory acts as the persistent substrate that accumulates knowledge, maintains context across sessions, and enables behavioral adaptation based on historical patterns.
Get started with Atlas today
Get started in seconds. Our free clusters come with 512 MB of storage so you can play around with sample data and get oriented with our platform.