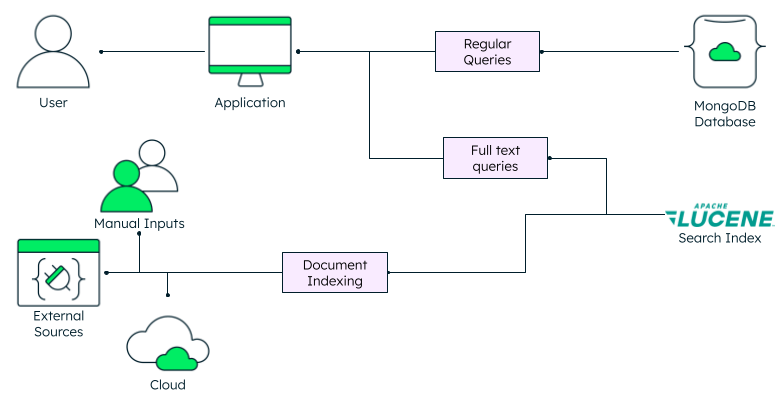
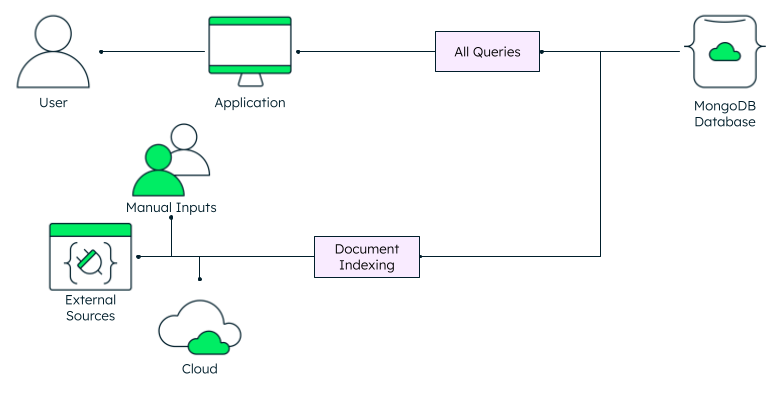
Summary of full-text index characteristics
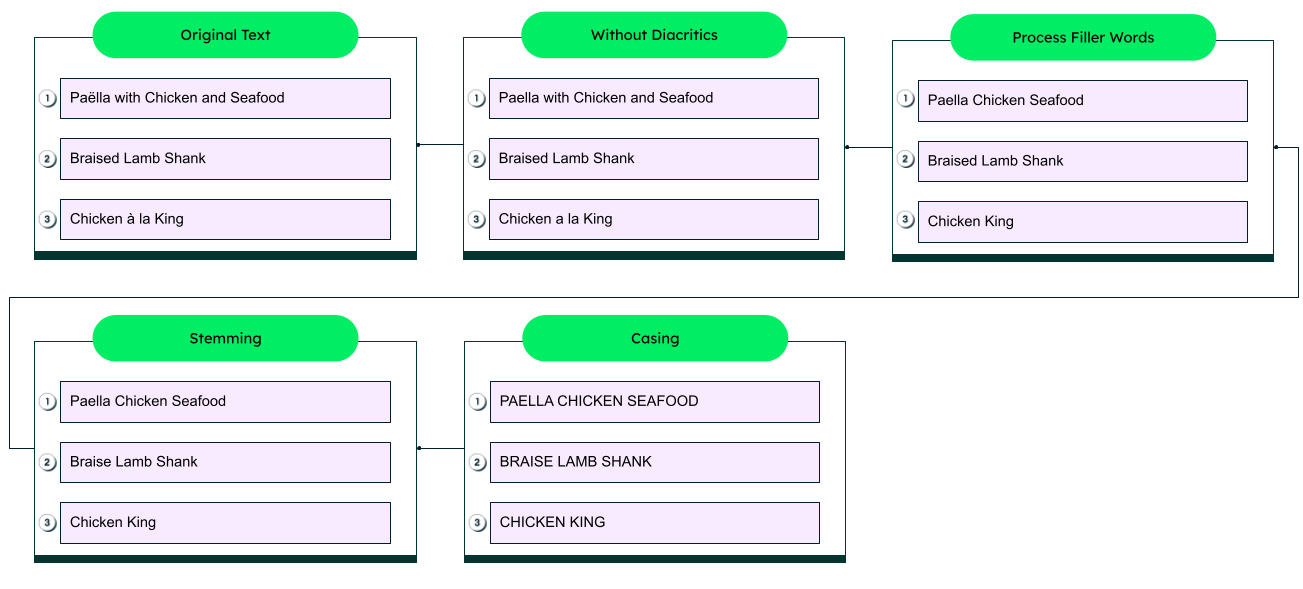
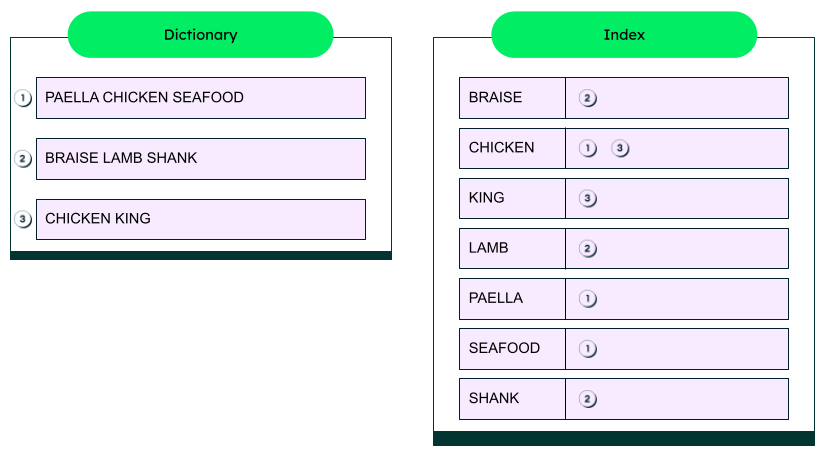
Mapping terms to documents: The main function of full-text indexes is to map terms (e.g., words, phrases, numbers) back to the documents where they reside. During the creation of the index, document content is reviewed and a link between terms and their respective documents is created.
Enhanced query speed: Once the full-text index is created, it allows for fast lookup and retrieval of documents relevant to a user's search query. Instead of scanning through all the content of every document or all web pages, the search engine can quickly identify the documents that contain the specified terms by consulting the index.
Optimization: In addition to enhanced query speed, additional optimizations to enhance index speed and storage efficiency are applied. Data caching, data compression, and other data structure optimizations are often employed to create leading-class full-text search systems.
Full-text index types
There are various types of full-text indexes to choose from. Search requirements, data type and volume, and query complexity are key points of consideration for the user when selecting the full-text index method. In addition, some users may choose to employ more than one indexing method to optimize performance and address data storage concerns. Two common full-text indexes include inverted indexes and B-tree indexes.
Inverted index: Inverted indexes are the most commonly used. These indexes store the mapping of terms to the documents in which they're contained. They enable rapid lookups during searches (i.e., search the index rather than all the documents) and optimize the search process.
Within inverted indexes, some of the additional functions occurring behind the scenes include:
- Compression: Data compression techniques are applied to reduce index data storage requirements.
- Positioning: Additional information related to where the selected term(s) appear in a document is included, enabling proximity and phrase queries.
- Frequency: Rather than mapping terms, documents are mapped. This is useful when analyzing the number of times a term appears in a document.
- N-grams: Text is broken down into N-grams (i.e., a contiguous sequence of characters or words). For example, the phrase "The slow tortoise beat the lazy hare" could be broken down into N-1, "Tortoise beat the lazy hare"; N-2, "The slow tortoise beats"; N-3, "Tortoise beats the lazy"; etc. N-gram indexing enables partial matching and wildcard queries.
- B-trees and B+ trees: B-trees and B+ trees are often used when full-text search is integrated into a relational database. Specifically, they are often used for range queries (e.g., a date range, a range of currency values).