Você pode implementar o MongoDB Search e o Vector Search em seu cluster Kubernetes para criar experiências de pesquisa avançadas diretamente em seus aplicativos. Usando o MongoDB Search e o Vector Search , você pode criar recursos de pesquisa de texto tradicional e pesquisa vetorial baseados em IA que são sincronizados automaticamente com um banco de dados MongoDB local. Isso elimina a necessidade de manter sistemas separados sincronizados e, ao mesmo tempo, fornecer recursos avançados de pesquisa. Para saber mais, consulte:
Para habilitar os recursos de pesquisa, como pesquisa de texto completo e semântica em sistemas locais, você deve distribuir o processo de pesquisa e Vector Search do MongoDB (mongot) e conectá-lo ao implantação de banco de dados MongoDB (mongod) . A implantação do mongot é opcional e é necessária somente se você planeja aproveitar os recursos de pesquisa que ela oferece.
Os processos do Banco de Dados MongoDB (mongod) atuam como o proxy para todas as queries de pesquisa para mongot. O mongod encaminha a consulta para mongot, que processa a consulta. O mongot retorna os resultados da query para o mongod, que encaminha os resultados para você. Você nunca interage diretamente com o mongot.
Cada processo do mongot tem seu próprio volume persistente que não é compartilhado com o banco de dados ou outros nós de pesquisa. O armazenamento é usado para manter índices que são criados a partir dos dados obtidos continuamente do banco de dados. As definições do índice (metadados) são armazenadas no próprio banco de dados .
O mongot executa as seguintes ações:
Gerencia o índice.
O
mongoté responsável por atualizar as definições de índice no banco de dados.Obtém os dados do banco de dados.
Os nós do
mongotestabelecem conexões permanentes com o banco de dados para atualizar índices do banco de dados em tempo real.Processa queries de pesquisa.
Quando
mongodrecebe uma query, ou, ele direciona a query para um$search$searchMeta$vectorSearchdosmongotnós. Omongotque recebe a query processa a query, agrega os dados e retorna os resultados paramongod, que encaminha ao usuário.
Os componentes do mongot são fortemente associados a um único conjunto de réplicas MongoDB e não podem ser compartilhados entre vários bancos de dados ou conjuntos de réplicas. Isso significa que um sistema de conjunto de réplicas tem seus próprios nós de pesquisa dedicados.
A conectividade de rede entre mongot e mongod vai em ambas as direções:
mongotestabelece conexão com o conjunto de réplicas para obter os dados usados para construir índices e executar query.mongodconecta-se aomongotpara encaminhar operações relacionadas à pesquisa, como gerenciamento de índice e consulta de dados.
Sistema de pesquisa Vector Search do MongoDB
Não há muitas diferenças entre a arquitetura de implantação de pesquisa com ou sem o Kubernetes Operator. O Operador Kubernetes simplifica as etapas necessárias para distribuir nós de pesquisa totalmente funcionais, especialmente quando o banco de dados também é gerenciado pelo Operador Kubernetes.
Para implantar, você aplica o MongoDBSearch Recurso Personalizado (CR), que o Operador do Kubernetes pega e começa a distribuir mongot pods e solicita armazenamento persistente especificado no spec. O MongoDB Search e a Vector Search implementados usando o Kubernetes Operator podem direcionar o conjunto de réplicas do MongoDB distribuído pelo Kubernetes Operator dentro do mesmo cluster do Kubernetes ou de um banco de dados MongoDB externo completamente independente. Para aprender como implantar e configurar o mongot para utilizar:
Um conjunto de réplicas do MongoDB no Kubernetes, consulte Instalar e usar a pesquisa com o MongoDB Enterprise Edition
Para definir um conjunto de réplicas do MongoDB externo, consulte Instalar e usar o MongoDB Search e o Vector Search com o MongoDB Enterprise Edition.
Pré-requisitos
Para aproveitar o MongoDB Search e o Vector Search em sua implantação do MongoDB Enterprise , você deve ter o seguinte:
MongoDB 8.0.10+ totalmente funcional conjunto de réplicas distribuído de uma das seguintes maneiras:
Dentro de um cluster Kubernetes usando o Operador Kubernetes
Fora de um cluster Kubernetes
Instância do Cloud Manager ou do Ops Manager
Tarefas de configuração
A tabela a seguir mostra as tarefas de configuração que o Kubernetes Operator executa automaticamente e as ações que você deve executar para implantar com êxito a Pesquisa do MongoDB e a Vector Search no Kubernetes e conectar-se a um conjunto de réplicas do MongoDB no Kubernetes ou a um conjunto de réplicas externo do MongoDB .
Tarefa | (Inside Kubernetes) Performed by | (External MongoDB) Performed by |
|---|---|---|
Implemente o Ops Manager dentro do Kubernetes | Kubernetes Operator | Kubernetes Operator |
Implemente o Cloud Manager ou o Ops Manager fora do Kubernetes | você | você |
Implementar conjunto de réplicas do MongoDB | Kubernetes Operator | você |
Criar | você | você |
Fornecer string de conexão para o conjunto de réplicas do MongoDB | Kubernetes Operator | você |
Criar | Kubernetes Operator | Kubernetes Operator |
Definir os parâmetros necessários do conjunto de réplicas em cada processo | Kubernetes Operator | você |
Função polyfill | Kubernetes Operator | você |
Criar usuário para | Kubernetes Operator e você aplicando o recurso MongoDBUser | você |
Configurar conjunto de réplicas do MongoDB com um usuário que tenha as permissões necessárias para consultar a pesquisa | você | você |
Criar índices de MongoDB Search e Vector Search | você | você |
Exponha pods de pesquisa externamente para conexão a partir de cada nó | Não necessário | você |
Expor pods mongod externamente para conexão a partir de nós | Não necessário | você |
O diagrama a seguir mostra a arquitetura de implementação de uma única instância do MongoDB Search e Vector Search com um conjunto de réplicas do MongoDB Enterprise em um cluster Kubernetes.

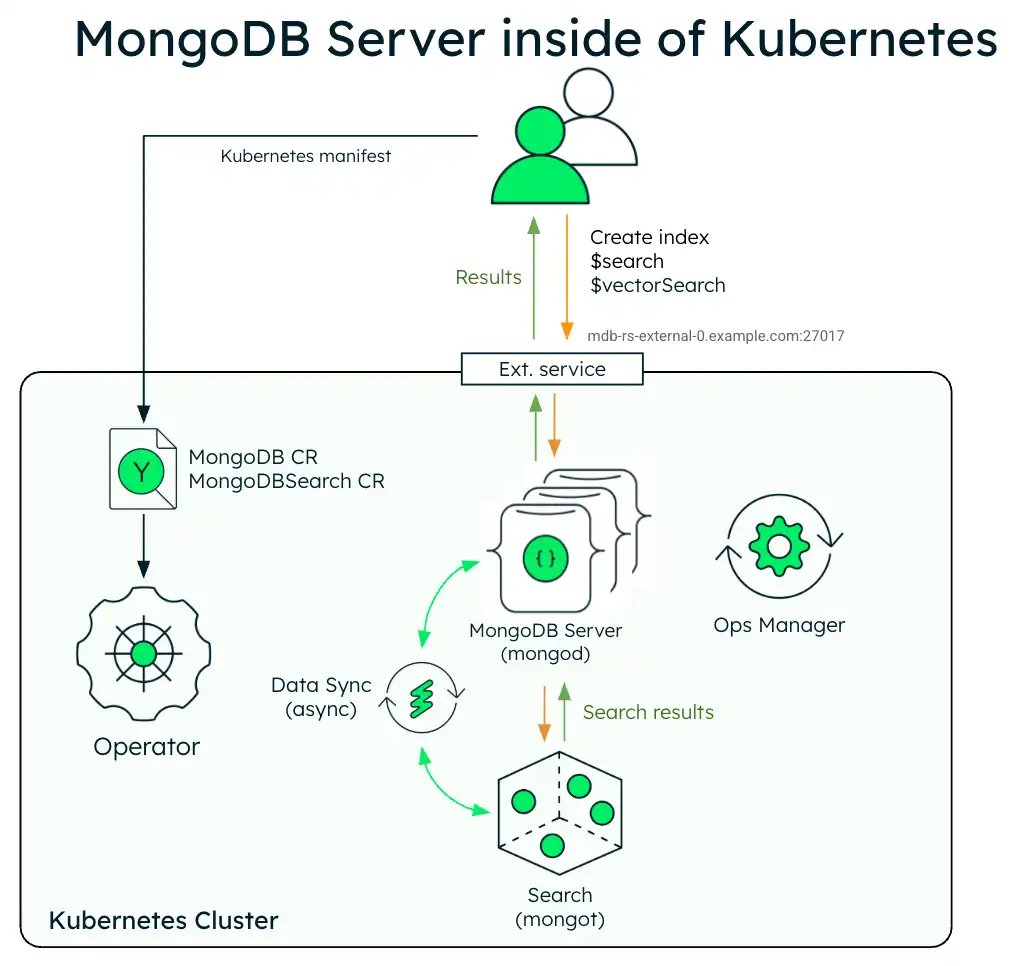
O diagrama a seguir mostra os componentes que o Operador Kubernetes implementa em um cluster do Kubernetes para MongoDB Search e Vector Search com um conjunto de réplicas MongoDB Enterprise Edition.

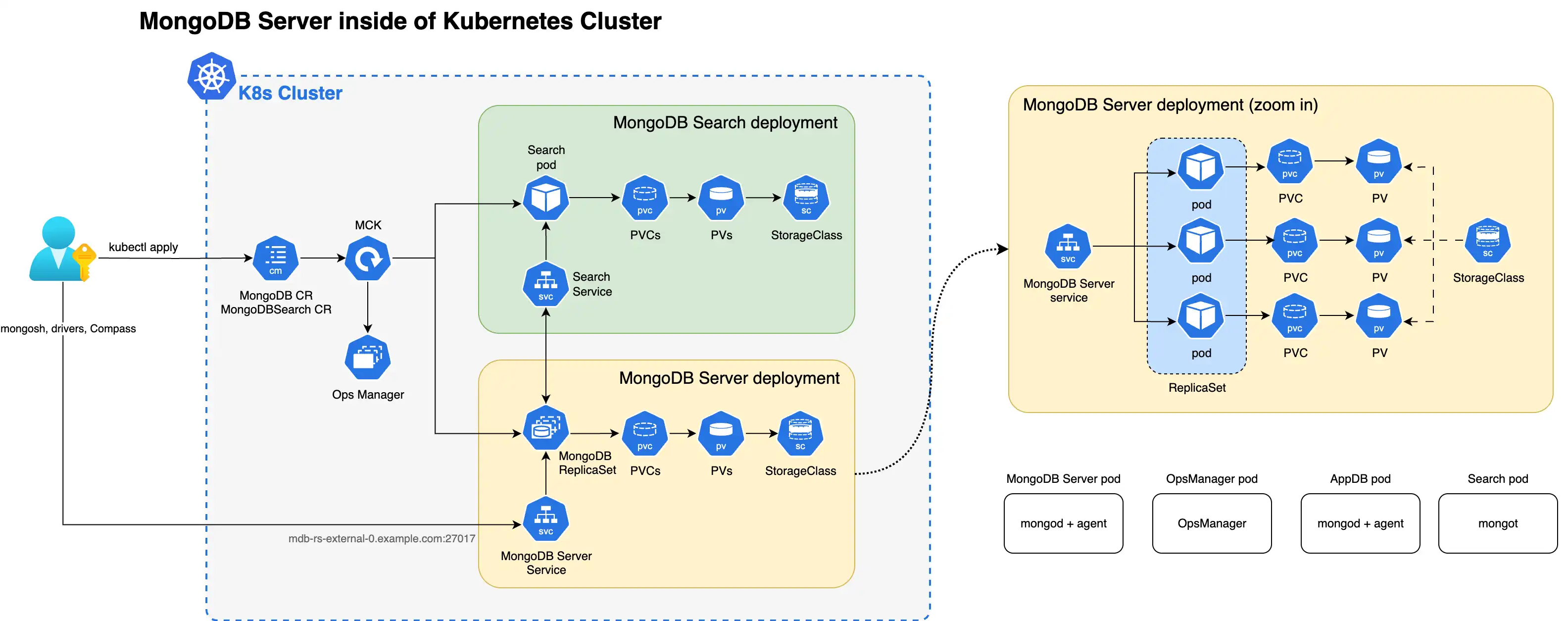
Quando os processos mongot e mongod são implantados dentro do cluster Kubernetes, o Operador Kubernetes executa a configuração para ambos os processos automaticamente. Especificamente, o Operador Kubernetes executa as seguintes operações:
Localiza o MongoDB CR referenciado por
MongoDBSearchusandospec.source.mongodbResourceRef, ou por uma convenção de nomenclatura procurando MongoDB CR com o mesmo nome queMongoDBSearch.Gera configuração do
mongotem um arquivo YAML e salva em um mapa de configuração denominado<MongoDBSearch.metadata.name>-search-config.O mapa de Configuração é montado pelos pods de pesquisa e a configuração YAML é usada pelo processo do
mongotna inicialização. O YAML gerado contém todas as informações sobre como se conectar ao conjunto de réplicas, configurações do TLS e assim por diante.Implementa o conjunto stateful do MongoDB Search e Vector Search denominado
<MongoDBSearch.metadata.name>-searchcom os requisitos de armazenamento e recursos configurados de acordo com as configuraçõesspec.persistenceespec.resourceRequirementsna CR.Atualiza a configuração de cada processo do
mongodadicionando as opções dosetParameternecessárias, incluindo os nomes de host e números de porta dos hosts mongot. opçõessetParameternecessárias, incluindo os nomes de host e números de porta dos membros do conjunto de réplicas do MongoDB .Para a versão do MongoDB anterior à v8.2, cria a função personalizada
searchCoordinatorcom todas as permissões necessárias que o processomongotexige. A partir do MongoDB 8.2, osearchCoordinatoré um role embutido.
Você deve executar as seguintes ações:
Crie um usuário no conjunto de réplicas utilizando um recurso personalizado do
MongoDBUser. Omongotutiliza as credenciais deste usuário para conectar ao conjunto de réplica para obter os dados:O nome de usuário é arbitrário (nos exemplos, usamos
search-sync-source-user), mas ele deve ter o conjunto de funçõessearchCoordinator.O nome de usuário e a senha deste usuário são passados em
MongoDBSearch.spec.source.usernameeMongoDBSearch.spec.source.passwordSecretRef, respectivamente.O segredo da senha pode se referir ao mesmo segredo contendo a senha do usuário que foi usada para criar a especificação
MongoDBUser(emMongoDBUser.spec.source.passwordSecretKeyRef).
Configure e aplique o recurso personalizado do
MongoDBSearch.
Para saber mais sobre as configurações de CR para o processo mongot, consulte Configurações de pesquisa do MongoDB e Vector Search.
O diagrama a seguir mostra a arquitetura de implementação do MongoDB Search e do Vector Search em um cluster Kubernetes usando um conjunto de réplicas externo do MongoDB Enterprise Edition.

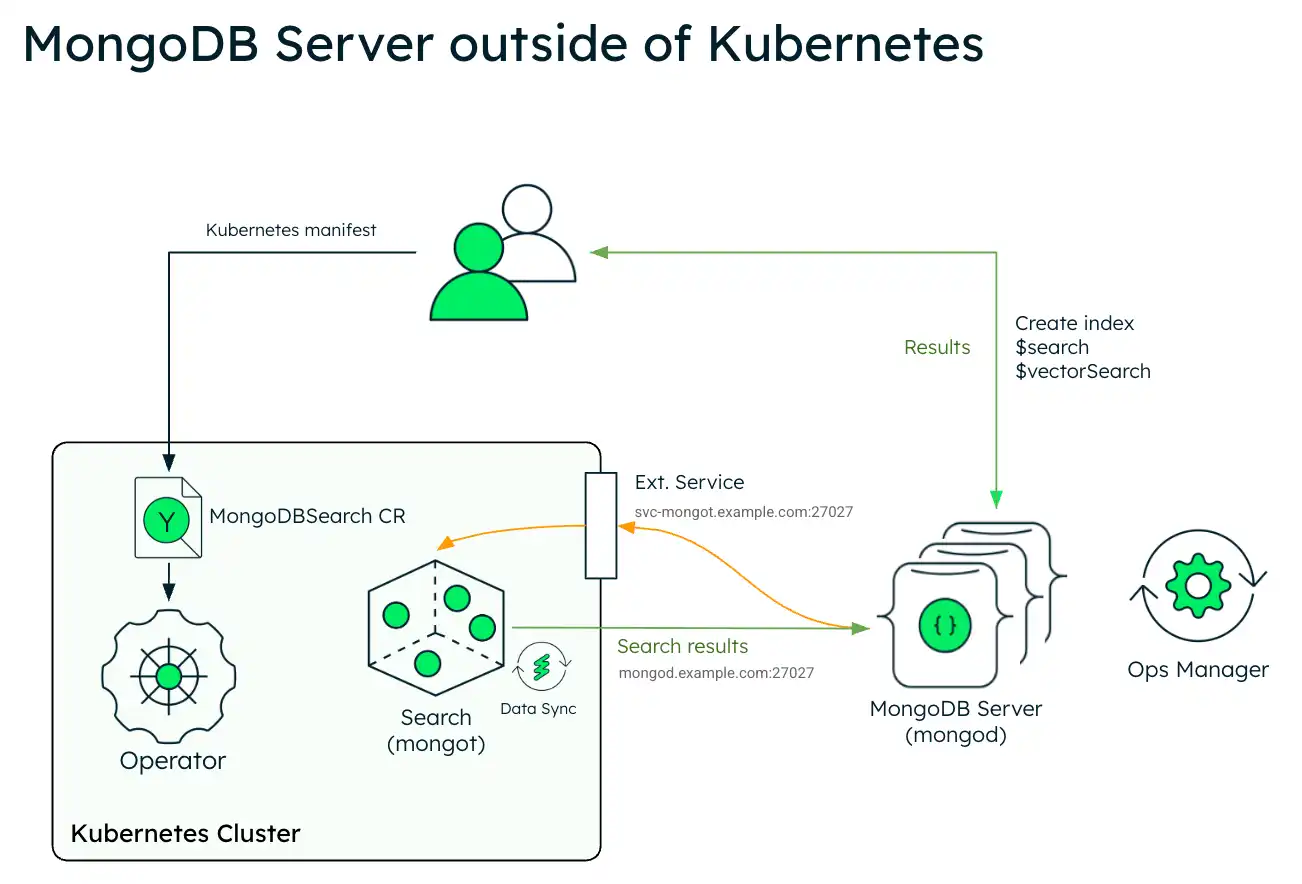
O diagrama a seguir mostra os componentes que o Operador Kubernetes implementa em um cluster Kubernetes para MongoDB Search e Vector Search.

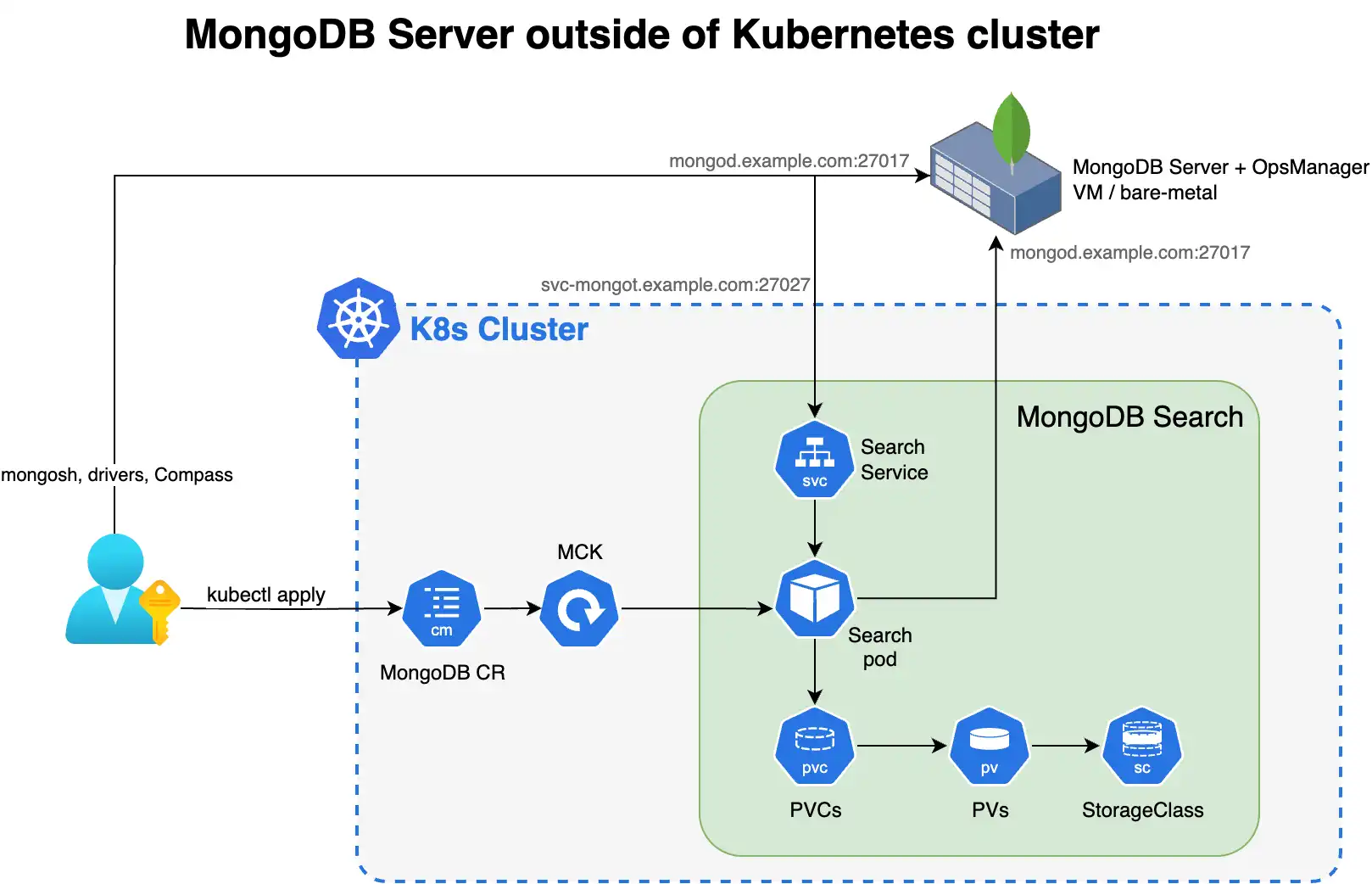
Para aproveitar o MongoDB Search e o Vector Search quando tiver seu sistema do MongoDB fora do Kubernetes, você implementa o mongot utilizando o Operador do Kubernetes e você deve executar algumas etapas manualmente. O Operador Kubernetes lida com a configuração dos pods de pesquisa. No entanto, quando o conjunto de réplicas do MongoDB estiver fora do Kubernetes, você deverá reconfigurar os nós do MongoDB e a rede.
Você é responsável pelas seguintes configurações manuais:
Configuração externa do MongoDB
Configure o parâmetro a seguir usando
setParameterem cada processomongodem seu conjunto de réplicas externa. Ao configurar, substitua<search-service-hostname>:27027pelo nome do host real resolvível e pela porta do seu serviçoMongoDBSearch.setParameter: mongotHost: "<search-service-hostname>:27027" searchIndexManagementHostAndPort: "<search-service-hostname>:27027" skipAuthenticationToSearchIndexManagementServer: false searchTLSMode: "disabled" # or "requireTLS" for TLS deployments (Somente para a versão do MongoDB inferior a (
<) 8.2) Crie a função personalizadasearchCoordinatorcom todas as permissões necessárias.No MongoDB 8.2+,
searchCoordinatoré uma função embutida e, portanto, você pode pular esta etapa.Crie um usuário no conjunto de réplicas externa para o processo de sincronização de pesquisa. Este usuário deve ter a função
searchCoordinator.- userName: "search-sync-source" password: "<your-search-sync-password>" database: "admin" roles: - role: "searchCoordinator" db: "admin"
Configuração do Kubernetes
Configure e aplique o
MongoDBSearchCR comspec.source.externalapontando para seus hosts MongoDB externos.Crie um segredo do Kubernetes para a senha do usuário de sincronização de pesquisa.
apiVersion: v1 kind: Secret metadata: name: search-sync-source-password stringData: password: "your-search-sync-password" Crie um segredo de arquivo de chave contendo as mesmas chaves especificadas no arquivo de chave usado pelo conjunto de réplicas MongoDB externo.
Configure a rede e o DNS para garantir a conectividade bidirecional entre o MongoDB externo e os pods de pesquisa. Seu ambiente MongoDB externo deve ser capaz de resolver seu nome de host do serviço de pesquisa (
<search-service-hostname>).
Para saber mais sobre as configurações de CR do processo mongot para se conectar a um processo mongod externo, consulte Configurações de pesquisa e Vector Search do MongoDB.
Segurança
A imagem seguinte ilustra a configuração de segurança para o processo do mongot. Se o servidor MongoDB estiver dentro do cluster do Kubernetes, o operador Kubernetes configurará automaticamente a autenticação de arquivo de chave para MongoDB Search e Vector Search. Se o servidor MongoDB for externo, você deverá criar um Kubernetes Secret contendo a credencial de arquivo de chave do conjunto de réplica e referenciá-lo no MongoDBSearch CR.

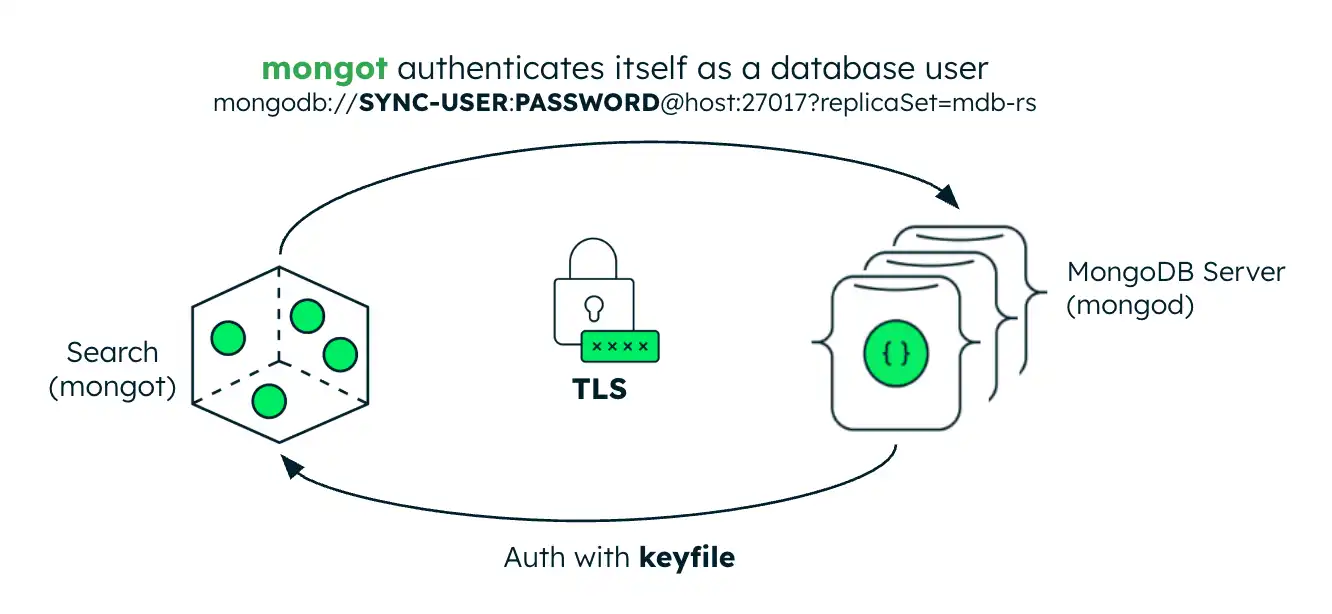
Autenticação
Ao se conectar ao mongod, o mongot se autentica como um usuário de banco de dados. Ao implantar o MongoDB Search e o Vector Search, você deve criar o usuário de banco de dados. Você deve passar as credenciais de usuário armazenadas em um Kubernetes Secret para mongot preenchendo os campos spec.source.username e spec.source.passwordSecretRef no MongoDBSearch CR.
Ao aceitar uma conexão do mongod, o mongot autentica a solicitação remota usando autenticação interna com keyfiles, semelhante à autenticação interna do membro do conjunto de réplicas do MongoDB . Quando configurado para indexar um recurso MongoDB no mesmo cluster Kubernetes, o Operador Kubernetes configura automaticamente a autenticação de arquivo-chave para MongoDBSearch. Se o conjunto de réplicas do MongoDB for implantado fora do Kubernetes, você deverá criar um segredo de Kubernetes contendo a credencial de arquivo de chaves do conjunto de réplicas e referenciá-lo no campo MongoDBSearch.spec.source.external.keyfileSecretRef.
Segurança da camada de transporte
MongoDBSearch pode proteger dados e credenciais em trânsito usando TLS. Para comandos de gerenciamento de índice e consultas de query, especifique (mesmo um objeto vazio, {}) o campo spec.security.tls e forneça um certificado TLS em um Kubernetes Secret no campo spec.security.tls.certificateKeySecretRef. Este certificado TLS deve ser emitido e assinado pela mesma CA que emitiu o certificado CA que o conjunto de réplicas MongoDB utiliza.
Quando MongoDBSearch e MongoDB são implantados pelo Operador Kubernetes, a configuração mongot e mongod subjacente é em grande parte manipulada pelo próprio Operador Kubernetes. Quando o conjunto de réplicas do MongoDB é implantado fora do Kubernetes, o campo .spec.source.external.tls deve ser preenchido com um segredo do Kubernetes contendo o mesmo certificado CA com o qual mongod está configurado, e a própria configuração mongod deve ter o parâmetro searchTLSMode definido como requireTLS.