Você pode implementar o MongoDB Search e o Vector Search em seu cluster Kubernetes para criar experiências de pesquisa avançadas diretamente em seus aplicativos. Usando o MongoDB Search e o Vector Search , você pode criar recursos de pesquisa de texto tradicional e pesquisa vetorial baseados em IA que são sincronizados automaticamente com um banco de dados MongoDB local. Isso elimina a necessidade de manter sistemas separados sincronizados e, ao mesmo tempo, fornecer recursos avançados de pesquisa. Para saber mais, consulte:
Para habilitar as funcionalidades de pesquisa, como pesquisa de texto completo e pesquisa semântica em implantações locais, você deve implantar o processo MongoDB Search e pesquisa vetorial (mongot) e conectá-lo à sua implantação de banco de dados MongoDB (mongod). A implantação do mongot é opcional e é necessária somente se você planeja utilizar os recursos de pesquisa que ela oferece.
Os processos do Banco de Dados MongoDB (mongod) atuam como o proxy para todas as queries de pesquisa para mongot. O mongod encaminha a consulta para mongot, que processa a consulta. O mongot retorna os resultados da query para o mongod, que encaminha os resultados para você. Você nunca interage diretamente com o mongot.
Cada processo do mongot tem seu próprio volume persistente que não é compartilhado com o banco de dados ou outros nós de pesquisa. O armazenamento é usado para manter índices que são criados a partir dos dados obtidos continuamente do banco de dados. As definições do índice (metadados) são armazenadas no próprio banco de dados .
O mongot executa as seguintes ações:
Gerencia o índice.
O
mongoté responsável por atualizar as definições de índice no banco de dados.Obtém os dados do banco de dados.
Os nós do
mongotestabelecem conexões permanentes com o banco de dados para atualizar índices do banco de dados em tempo real.Processa queries de pesquisa.
Quando
mongodrecebe uma query, ou, ele direciona a query para um$search$searchMeta$vectorSearchdosmongotnós. Omongotque recebe a query processa a query, agrega os dados e retorna os resultados paramongod, que encaminha ao usuário.
Os componentes do mongot são fortemente associados a um único conjunto de réplicas MongoDB e não podem ser compartilhados entre vários bancos de dados ou conjuntos de réplicas. Para uma implantação de conjunto de réplicas, um grupo de nós de pesquisa dedicados atende ao conjunto de réplicas. Para um cluster fragmentado, cada fragmento mantém seu próprio grupo independente de mongot nós. Os fragmentos não compartilham instâncias mongot.
A conectividade de rede entre mongot e mongod vai em ambas as direções:
mongotestabelece conexão com o conjunto de réplicas para obter os dados usados para construir índices e executar query.mongodconecta-se aomongotpara encaminhar operações relacionadas à pesquisa, como gerenciamento de índice e consulta de dados.
O campo spec.replicas controla quantas instâncias do mongot o Operador Kubernetes implanta. Para uma origem do conjunto de réplicas, o spec.replicas define o número total de pods do mongot. Para uma origem de cluster fragmentado, spec.replicas define o número de mongot pods por fragmento.
Se você definir spec.replicas como um valor maior que 1, deverá colocar um balanceador de carga L7 entre mongod e os pods mongot. O processo mongod abre uma única conexão TCP de longa duração para mongot, portanto, um balanceador de carga L4 não pode distribuir queries em várias instâncias mongot — todo o tráfego flui por essa conexão. Um balanceador de carga L7 entende HTTP/2 e gRPC, o que lhe permite distribuir fluxos gRPC individuais em pods mongot enquanto fixa cada fluxo em um único mongot durante o cursor de query.
Sistema de pesquisa Vector Search do MongoDB
Não há muitas diferenças entre a arquitetura de implantação de pesquisa com ou sem o Kubernetes Operator. O Operador Kubernetes simplifica as etapas necessárias para distribuir nós de pesquisa totalmente funcionais, especialmente quando o banco de dados também é gerenciado pelo Operador Kubernetes.
Para implantar, você aplica o MongoDBSearch Custom recurso (CR), que o Operador do Kubernetes pega e começa a distribuir mongot pods e solicita armazenamento persistente especificado no spec. O MongoDB Search e a pesquisa vetorial implementados por meio do Kubernetes operador podem direcionar um conjunto de réplicas do MongoDB ou um cluster implantado pelo Kubernetes operador dentro do mesmo cluster do Kubernetes, ou uma implantação externa completamente independente do MongoDB (conjunto de réplicas ou cluster). Para aprender como implantar e configurar o mongot para usar:
Um conjunto de réplicas do MongoDB no Kubernetes, consulte Instalar e usar com o MongoDB Community Edition ou Instalar e usar a pesquisa com o MongoDB Enterprise Edition
Um conjunto de réplicas MongoDB externo,consulte Instalar Search com MongoDB Enterprise Externo.
Pré-requisitos
Para usar o MongoDB Search e a pesquisa vetorial em seu:
A implantação da MongoDB Community , você deve ter um MongoDB 8.2 totalmente funcional ou posterior conjunto de réplicas ou cluster fragmentado implantado dentro de um cluster Kubernetes usando o Operador Kubernetes.
A implantação do MongoDB Enterprise , você deve ter um conjunto de réplicas totalmente funcional do MongoDB 8.2 ou posterior ou um cluster fragmentado implantado de uma das seguintes maneiras:
Dentro de um cluster Kubernetes usando o Operador Kubernetes
Fora de um cluster Kubernetes
Instância do Cloud Manager ou do Ops Manager
Antes de começar, considere o seguinte:
Você deve ter um
StorageClassfuncional para a criação de volumes persistentes no cluster Kubernetes. Sem isso, seuPersistentVolumeClaimspode permanecer pendente e o MongoDB pode não ter armazenamento durável.Você deve ter uma rede de cluster configurada corretamente. Serviços como ClusterIP, NodePort ou LoadBalancer devem ser capazes de rotear o tráfego. Se os clientes externos precisarem de acesso, configure um ingresso ou um balanceador de carga.
Seu banco de dados e os nós de pesquisa devem ter CPU, memória e espaço em disco suficientes alocados porque as cargas de trabalho do banco de dados MongoDB, da pesquisa MongoDB e da pesquisa vetorial fazem uso intensivo de recursos. Recomendamos usar solicitações e limites nas especificações do Pod para evitar despejo ou limitação.
Sua versão do Kubernetes deve ser suportada pelo operador MongoDB ou gráfico Helm que você deseja usar. Alguns CRDs ou APIs diferem entre versões. Para saber mais, veja Controladores MongoDB para Compatibilidade do operador Kubernetes.
Você deve criar quaisquer funções e vinculações de funções RBAC necessárias para que o Kubernetes operador e os processos em execução nos Pods possam gerenciar recursos.
Se você quiser várias instâncias
mongot(spec.replicasmaiores que1), precisará de um balanceador de carga. O Operador Kubernetes pode implantar e gerenciar um proxy Envoy automaticamente (spec.loadBalancer.managed: {}) ou você pode fornecer seu próprio balanceador de carga L7 (spec.loadBalancer.unmanaged).Se você quiser um cluster com várias instâncias
mongot, verifique se você tem recursos de cluster suficientes para o número total de Pods em todos os fragmentos. Cada fragmento obtém seu próprio grupo independente demongotpods. O balanceador de carga despacha tráfego para o grupomongotcorreto. Ele lê o campo TLS SNI no tráfego recebido para identificar o fragmento de origem e roteia o tráfego paramongotpods que pertencem a esse fragmento. Portanto, você deve configurar cada fragmento com um nome de host de pesquisa distinto.
Tarefas de configuração
A tabela a seguir mostra as tarefas de configuração que o Kubernetes Operator executa automaticamente e as ações que você deve executar para implantar com êxito o MongoDB Search e a pesquisa vetorial no Kubernetes e conectar-se a um conjunto de réplicas do MongoDB ou cluster no Kubernetes ou a uma implantação externa do MongoDB.
Tarefa | (Dentro do Kubernetes) Executado por | ( MongoDB externo) Executado por |
|---|---|---|
Implemente o Ops Manager dentro do Kubernetes | Kubernetes Operator | Kubernetes Operator |
Implemente o Cloud Manager ou o Ops Manager fora do Kubernetes | você | você |
Distribua o conjunto de réplicas do MongoDB ou o cluster fragmentado | Kubernetes Operator | você |
Criar recurso personalizado do MongoDBSearch | você | você |
Fornecer string de conexão para a implantação do MongoDB | Kubernetes Operator | você |
Criar YAMLde configuração | Kubernetes Operator | Kubernetes Operator |
Definir os parâmetros necessários do conjunto de réplicas em cada processo | Kubernetes Operator | você |
Criar usuário para | Kubernetes Operator e você aplicando o recurso MongoDBUser | você |
Configurar conjunto de réplicas do MongoDB com um usuário que tenha as permissões necessárias para consultar a pesquisa | você | você |
Criar índices de MongoDB Search e Vector Search | você | você |
Exponha pods de pesquisa ou balanceador de carga externamente para conectar a partir de cada nó | Não necessário | você |
Exponha | Não necessário | você |
Configurar balanceador de carga gerenciado (quando | Kubernetes Operator | Kubernetes Operator |
Configurar balanceador de carga não gerenciado (quando | você | você |
Provisionar certificados TLS por fragmento (clusters fragmentados com TLS) | você | você |
Expor o balanceador de carga externamente ( MongoDB externo + LS gerenciado) | Não necessário | você |
O diagrama a seguir mostra a arquitetura de implementação de uma única instância do MongoDB Search e Vector Search com um conjunto de réplicas do MongoDB Enterprise em um cluster Kubernetes.
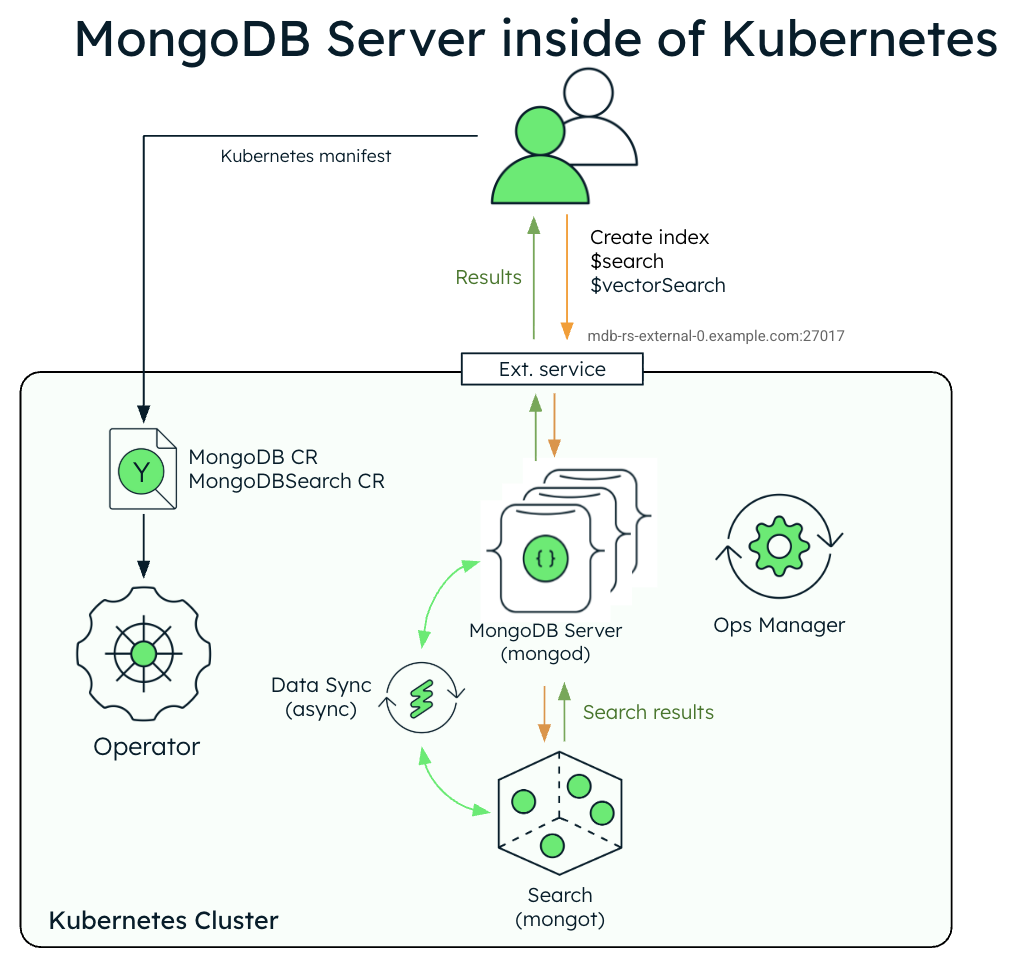
O diagrama a seguir mostra os componentes que o Operador Kubernetes implementa em um cluster do Kubernetes para MongoDB Search e Vector Search com um conjunto de réplicas MongoDB Enterprise Edition.
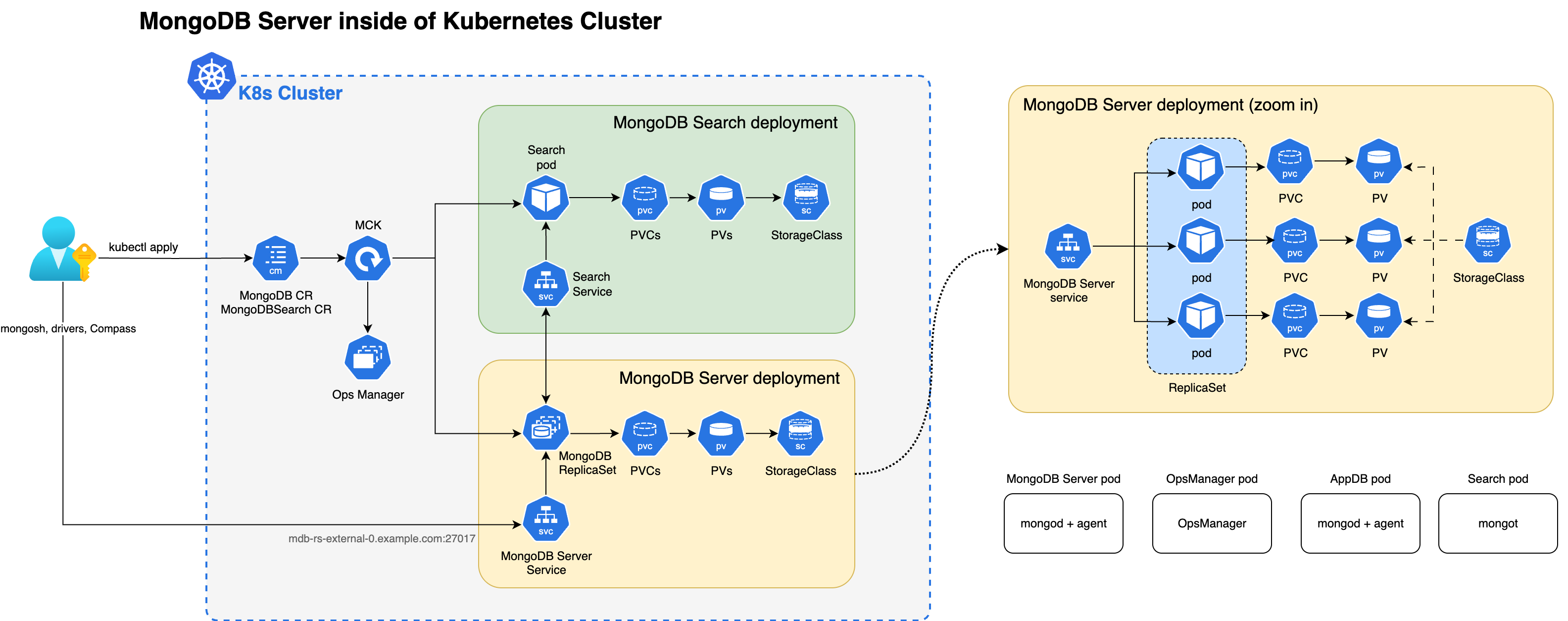
Quando os processos mongot e mongod são implantados dentro do cluster Kubernetes, o Operador Kubernetes executa a configuração para ambos os processos automaticamente. Especificamente, o Operador Kubernetes executa as seguintes operações:
Localiza o MongoDB CR referenciado pelo MongoDBSearch usando
spec.source.mongodbResourceRef, ou por uma convenção de nomenclatura procurando MongoDB CR com o mesmo nome que MongoDBSearch. Para clusters fragmentados, o Operador Kubernetes descobre automaticamente a topologia de fragmento (nomes de fragmentos, membros do conjunto de réplicas e roteadores mongos) a partir do recursoMongoDBreferenciado.Gera configuração do
mongotem um arquivo YAML e salva em um mapa de configuração denominado<MongoDBSearch.metadata.name>-search-config.O mapa de Configuração é montado pelos pods de pesquisa e a configuração YAML é usada pelo processo do
mongotna inicialização. O YAML gerado contém todas as informações sobre como se conectar ao conjunto de réplicas, configurações do TLS e assim por diante.Implanta o conjunto stateful do MongoDB Search e Pesquisa Vetorial denominado
<MongoDBSearch.metadata.name>-searchcom os requisitos de armazenamento e recursos configurados de acordo com as configuraçõesspec.persistenceespec.resourceRequirementsna CR. Para fontes de cluster, o Operador Kubernetes cria um StatefulSet por fragmento. Cada StatefulSet usa o padrão de nomenclatura<name>-search-0-<shardName>e contémspec.replicaspods, que é padronizado como1. O0no padrão de nomenclatura reserva um índice de cluster para futura compatibilidade de vários clusters.Implanta uma única implantação de proxy Envoy para o cluster MongoDB se você precisar de um balanceador de carga (
spec.loadBalancer.managed). O proxy Envoy lida com o roteamento L7, o encerramento do mTLS e a fixação de fluxo gRPC entre os podsmongodemongot.Atualiza a configuração de cada processo
mongodadicionando as opçõessetParameternecessárias, incluindo os nomes de host e números de porta dos hostsmongot. Ao configurar um balanceador de carga,mongotHostesearchIndexManagementHostAndPortponto para o ponto de extremidade do balanceador de carga em vez dos podsmongot. Para clusters fragmentados, os processosmongodde cada fragmento recebem o ponto de extremidade do balanceador de carga para esse fragmento.
Você deve executar as seguintes ações:
Crie um usuário no conjunto de réplicas utilizando um recurso personalizado do
MongoDBUser. Omongotutiliza as credenciais deste usuário para conectar ao conjunto de réplica para obter os dados:O nome de usuário é arbitrário (nos exemplos, usamos
search-sync-source-user), mas ele deve ter o conjunto de funçõessearchCoordinator.O nome de usuário e a senha deste usuário são passados em
MongoDBSearch.spec.source.usernameeMongoDBSearch.spec.source.passwordSecretRef, respectivamente.O segredo da senha pode se referir ao mesmo segredo contendo a senha do usuário que foi usada para criar a especificação
MongoDBUser(emMongoDBUser.spec.source.passwordSecretKeyRef).
Configure e aplicar o recurso personalizado MongoDBSearch.
Para saber mais sobre as configurações de CR para o processo mongot, consulte Configurações de pesquisa do MongoDB e Vector Search.
O diagrama a seguir mostra a arquitetura de implementação do MongoDB Search e do Vector Search em um cluster Kubernetes usando um conjunto de réplicas externo do MongoDB Enterprise Edition.
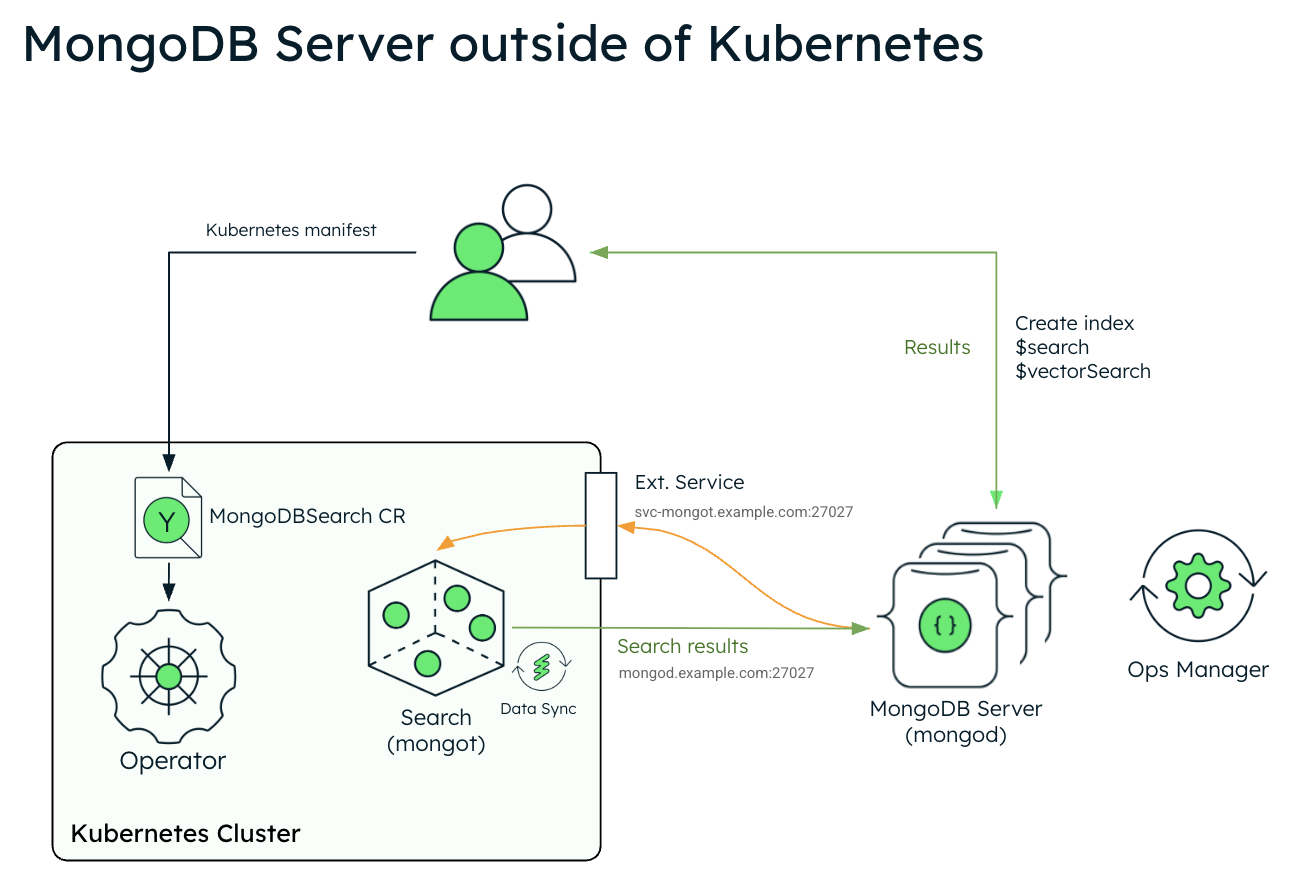
O diagrama a seguir mostra os componentes que o Operador Kubernetes implementa em um cluster Kubernetes para MongoDB Search e Vector Search.
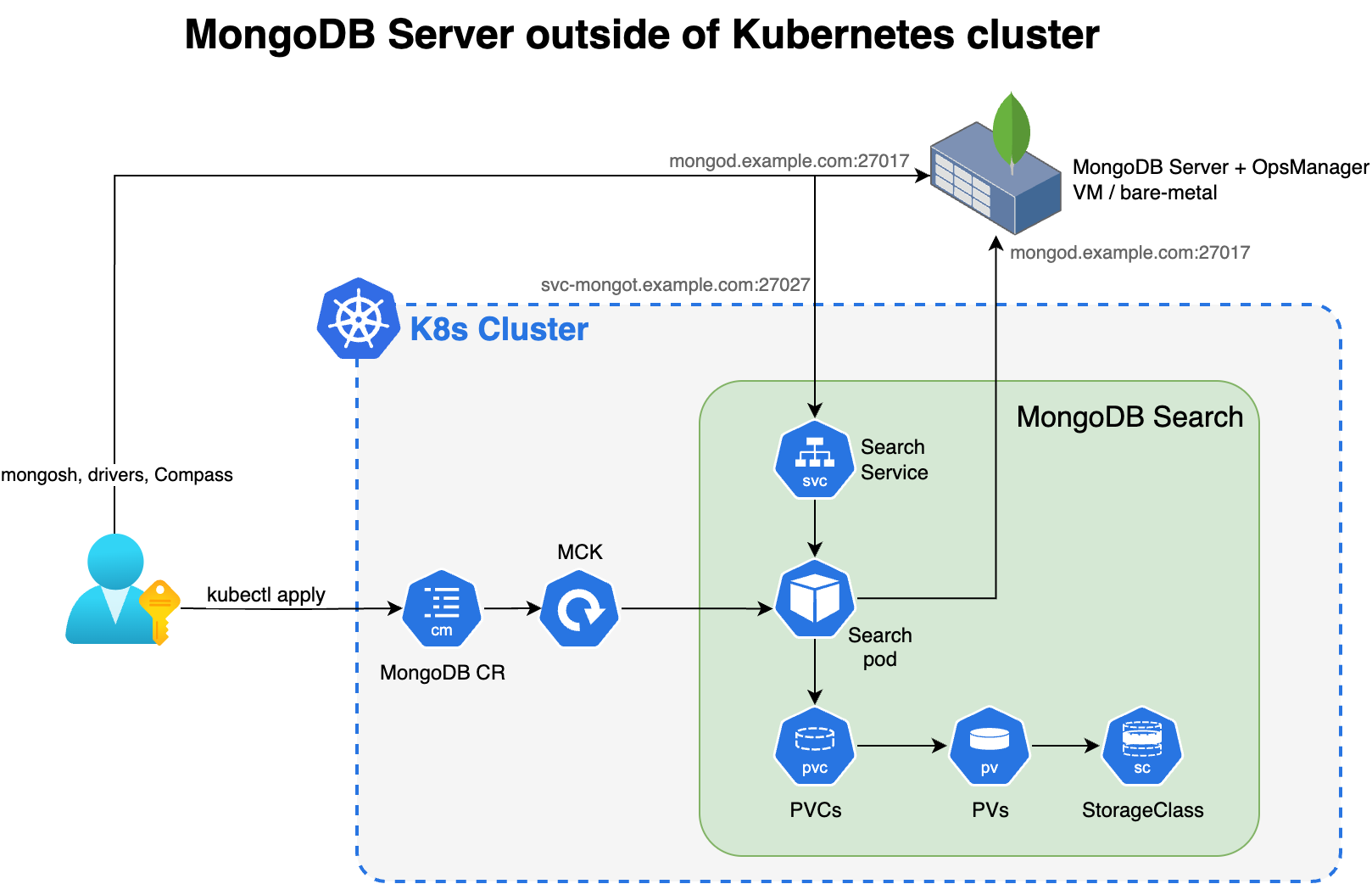
Para usar o MongoDB Search e a pesquisa vetorial quando tiver seu MongoDB implantação fora do Kubernetes, implantar mongot usando o Kubernetes operador e execute algumas etapas manualmente. O Operador Kubernetes lida com a configuração dos pods de pesquisa. No entanto, quando a implantação do MongoDB estiver fora do Kubernetes, você deverá reconfigurar os nós do MongoDB e a rede.
Você é responsável pelas seguintes configurações manuais:
Configuração externa do conjunto de réplicas
Configure o parâmetro a seguir usando
setParameterem cada processomongodem seu conjunto de réplicas externa. Ao configurar, substitua<search-service-hostname>:27028pelo nome do host real resolvível e pela porta do serviço MongoDBSearch.setParameter: mongotHost: "<search-service-hostname>:27028" searchIndexManagementHostAndPort: "<search-service-hostname>:27028" skipAuthenticationToSearchIndexManagementServer: false searchTLSMode: "disabled" # or "requireTLS" for TLS deployments useGrpcForSearch: true Para uma única instância
mongot(sem balanceador de carga),mongotHostaponta diretamente para o nome do host de serviçomongot(<name>-search-svc:27028).Para várias instâncias do
mongotcom um balanceador de carga,mongotHostaponta para o ponto de extremidade do balanceador de carga.Para balanceadores de carga gerenciados, o Operador Kubernetes configura o
mongotHostautomaticamente utilizandospec.source.mongodbResourceRef.Para implantações externas do MongoDB, você deve definir
mongotHostcomo o ponto de extremidade do balanceador de carga especificado emspec.loadBalancer.managed.externalHostnameouspec.loadBalancer.unmanaged.endpoint.
Crie um usuário no conjunto de réplicas externa para o processo de sincronização de pesquisa. Este usuário deve ter a função
searchCoordinator.- userName: "search-sync-source" password: "<your-search-sync-password>" database: "admin" roles: - role: "searchCoordinator" db: "admin"
Configuração de cluster fragmentado externo
Importante
Em uma implantação de cluster fragmentado MongoDB padrão, os clientes se conectam somente a roteadores mongos e nunca diretamente a conjuntos de réplicas de fragmentos. No entanto, quando você implanta mongot, os processos mongot em cada grupo de fragmentos se conectam aos roteadores mongos e a todos os processos mongod nesse fragmento. Portanto, você deve expor o conjunto de réplicas de cada fragmento diretamente aos processos mongot. Certifique-se de que suas regras de rede e firewall permitam a conectividade direta do cluster Kubernetes para as instâncias mongod de cada fragmento, não apenas para os roteadores mongos.
Os valores shardName especificados em spec.source.external.shardedCluster.shards devem seguir as regras de nomenclatura do Kubernetes:
Conter apenas caracteres alfanuméricos minúsculos,
-ou..Comece com um caractere alfabético e termine com um caractere alfanumérico.
Não contém sublinhados. Se os nomes dos fragmentos do MongoDB usarem sublinhados, substitua-os por traços.
O comprimento combinado de
MongoDBSearch.metadata.nameeshardNamedeve ter menos de 50 caracteres.
O shardName não precisa corresponder ao nome exato do fragmento no MongoDB. O Operador Kubernetes utiliza-o apenas para nomear recursos Kubernetes.
Ao conectar o MongoDBSearch a um cluster fragmentado externo, você deve:
Configure o
spec.source.external.shardedClusterno MongoDBSearch CR com os hosts do roteadormongose hosts do conjunto de réplicas por fragmento.Defina os parâmetros
mongotHostesearchIndexManagementHostAndPortnos processosmongodde cada fragmento. Aponte cada fragmento para seu próprio grupomongot(ou para seu próprio ponto de extremidade do balanceador de carga se você usar várias instânciasmongot).Garantir a conectividade de rede bidirecional entre:
Os nós
mongodde cada fragmento e os podsmongotcorrespondentes (ou balanceador de carga).Os pods
mongote os roteadoresmongos(para roteamento de queries).Os
mongotpods e os nósmongodde cada fragmento (para sincronização de dados).
Se você usar um balanceador de carga gerenciado com um cluster fragmentado externo, especifique spec.loadBalancer.managed.externalHostname com um espaço reservado {shardName} (por exemplo, {shardName}.search-lb.example.com). Exponha o serviço Envoy externamente para que os nós mongod de cada fragmento possam acessá-lo usando um nome de host exclusivo para esse fragmento. O balanceador de carga lê o campo TLS SNI a partir das conexões de entrada para determinar de qual fragmento o tráfego se origina e o despacha para os pods mongot que pertencem a esse fragmento. Esse roteamento baseado em SNIé o único mecanismo que o balanceador de carga usa para distinguir o tráfego entre fragmentos, e é por isso que cada fragmento deve se conectar por meio de um nome de host diferente.
Configuração do Kubernetes
Configure e aplique o MongoDBSearch CR com
spec.source.externalapontando para seus hospedars MongoDB externos.Crie um segredo do Kubernetes para a senha do usuário de sincronização de pesquisa.
apiVersion: v1 kind: Secret metadata: name: search-sync-source-password stringData: password: "your-search-sync-password" Configure a rede e o DNS para garantir a conectividade bidirecional entre o MongoDB externo e os pods de pesquisa. Seu ambiente MongoDB externo deve ser capaz de resolver seu nome de host do serviço de pesquisa (
<search-service-hostname>).
Para saber mais sobre as configurações de CR do processo mongot para se conectar a um processo mongod externo, consulte Configurações de pesquisa e Vector Search do MongoDB.
Segurança
A imagem seguinte ilustra a configuração de segurança para o processo do mongot. Se o servidor MongoDB estiver dentro do cluster do Kubernetes, o operador Kubernetes configurará automaticamente a autenticação de arquivo de chave para a pesquisa MongoDB e a pesquisa vetorial. Se o servidor MongoDB for externo, você deverá criar um Kubernetes Secret contendo a credencial de arquivo de chave do conjunto de réplica e referenciá-lo no MongoDBSearch CR.

Autenticação
O processo do mongot autentica conexões do mongod utilizando mTLS. Quando você habilita o TLS, o processo mongot usa o certificado TLS do servidor MongoDB como certificado do cliente para autenticação. Este certificado é verificado em relação ao certificado CA com o qual o mongot está configurado. Para que a autenticação funcione corretamente, você deve configurar mongot e mongod com o TLS habilitado.
Quando configurado para indexar um recurso MongoDB no mesmo cluster do Kubernetes, o operador do Kubernetes propaga automaticamente o certificado CA do mongod para mongot e habilita o mTLS para conexões de query de pesquisa se os recursos do MongoDB e MongoDBSearch estiverem configurados para TLS. Se o conjunto de réplicas do MongoDB for implantado fora do Kubernetes, você deverá criar um segredo do Kubernetes contendo o certificado CA do conjunto de réplicas e referenciá-lo no campo MongoDBSearch.spec.source.external.tls.ca para habilitar a autenticação mTLS para solicitações de query de pesquisa.
Segurança da camada de transporte
O MongoDBSearch pode proteger dados e credenciais em trânsito usando TLS. Para comandos de gerenciamento de índice e query de pesquisa, defina o campo spec.security.tls e forneça um certificado TLS. Você pode definir esse campo como um objeto vazio ({}) para habilitar o TLS com as configurações padrão.
Descontinuado desde a versão 1.8.0. : spec.security.tls.certificateKeySecretRef está descontinuado. Para implantações de conjunto de réplicas, o operador Kubernetes ainda oferece suporte a certificateKeySecretRef, mas você deve migrar para spec.security.tls.certsSecretPrefix. Para implantações de cluster sharded, você não pode usar certificateKeySecretRef porque o operador Kubernetes lê um segredo de certificado de servidor mongot separado para cada shard.
spec.security.tls.certsSecretPrefix é um campo opcional. Quando você o especifica, o Kubernetes Operator acrescenta <certsSecretPrefix>- a todos os nomes secretos de certificado que lê. O Operador do Kubernetes lê os seguintes segredos de certificado:
mongot Certificados
Topologia de cluster | mongot Certificado |
|---|---|
réplicaSet |
|
cluster fragmentado |
|
Certificados de balanceador de carga
Se você definir spec.loadBalancer.managed, o certificado do cliente do balanceador de carga será [<certsSecretPrefix>-]<name>-search-lb-0-client-cert. A tabela a seguir mostra os certificados de servidor do balanceador de carga:
Topologia de cluster | Certificado |
|---|---|
réplicaSet |
|
cluster fragmentado |
|
O certificado TLS deve ser emitido e assinado pela mesma CA que emitiu o certificado CA que o conjunto de réplicas MongoDB utiliza.
Quando MongoDBSearch e MongoDB são implantados pelo Operador Kubernetes, a configuração subjacente do mongot e mongod é em grande parte manipulada pelo próprio Operador Kubernetes. Se você implantar o conjunto de réplicas do MongoDB fora do cluster do Kubernetes:
.spec.source.external.tlso campo deve ser preenchido com um secret do Kubernetes contendo o mesmo certificado CA que você usou para configurar omongod.searchTLSModeO parâmetro deve ser definido comorequireTLSna configuraçãomongod.
Balanceador de carga mTLS
Sem um balanceador de carga, o mongod conecta diretamente ao mongot utilizando mTLS. O mongod apresenta seu próprio certificado de cliente e o mongot o valida em relação a uma CA confiável.
Se você configurar um balanceador de carga gerenciado (spec.loadBalancer.managed), o proxy Envoy encerra a conexão mTLS do mongod e estabelece uma nova conexão mTLS para o mongot. Como o balanceador de carga encerra e restabelece a conexão, ele usa seu próprio certificado de cliente ao se conectar ao mongot, não ao certificado mongod original. A CA mongot deve confiar na autoridade de certificação que emitiu o certificado de cliente do balanceador de carga. O Kubernetes operador gerencia a configuração do Envoy TLS automaticamente. Exige os seguintes certificados:
Certificado de servidor para o proxy Envoy, ao qual o
mongodse conecta. O balanceador de carga usa esse certificado para encerrar a conexão mTLS de entrada.Certificado do cliente para o proxy Envoy, que o balanceador de carga apresenta ao
mongotao estabelecer a conexão mTLS upstream.
Provisione estes certificados como Segredos Kubernetes seguindo a convenção de nomenclatura que o spec.security.tls.certsSecretPrefix define. Consulte Configurações de pesquisa do MongoDB e pesquisa vetorial para obter o padrão de nomenclatura completo.