O MongoDB Atlas possui um conjunto robusto de métricas, telemetria e logs integrados que você pode utilizar diretamente no Atlas ou integrar à sua pilha de observabilidade e alertas de terceiros. Isso permite que você monitore e gerencie suas implantações do Atlas e responda a incidentes de forma proativa e em tempo real.
Monitorar seu sistema permite que você:
Compreender a integridade e o status do seu cluster
Saiba como as operações em execução no cluster estão afetando o banco de dados
Saiba se o seu hardware tem restrição de recursos
Executar otimização de volume de trabalho e query
Detecte e reaja a problemas em tempo real para melhorar a pilha do seu aplicativo
O Atlas fornece várias métricas para monitoramento e alertas. Você pode acompanhar a integridade, a disponibilidade, o consumo e o desempenho de suas implantações em dashboards e por meio de API. Você também pode visualizar várias métricas de cluster, monitorar o desempenho do banco de dados, configurar alertas e notificações de alerta, e baixar logs de atividades.
Recursos para monitoramento e alertas do Atlas
Métricas | As métricas de implantação fornecem informações sobre o desempenho do hardware e a eficiência da operação do banco de dados . O Atlas coleta métricas para seus servidores, bancos de dados e processos do MongoDB e armazena dados de métricas em vários níveis de granularidade. Para cada nível de granularidade, o Atlas processa métricas como médias das métricas relatadas no próximo nível de granularidade mais fina. Muitas métricas têm um equivalente de relatório de intermitência. Você pode monitorar métricas na IU do Atlas usando a visualização de métricas, o painel de desempenho em tempo real, o profiler de query, o Performance Advisor e a página de Insights de namespace. Você também pode usar a Atlas CLI ou a API de administração do Atlas para canalizar métricas para uma ferramenta de sua escolha. A visualização de métricas da IU do Atlas a seguir mostra a variedade de métricas disponíveis para monitorar um conjunto de réplicas de três nós de exemplo: 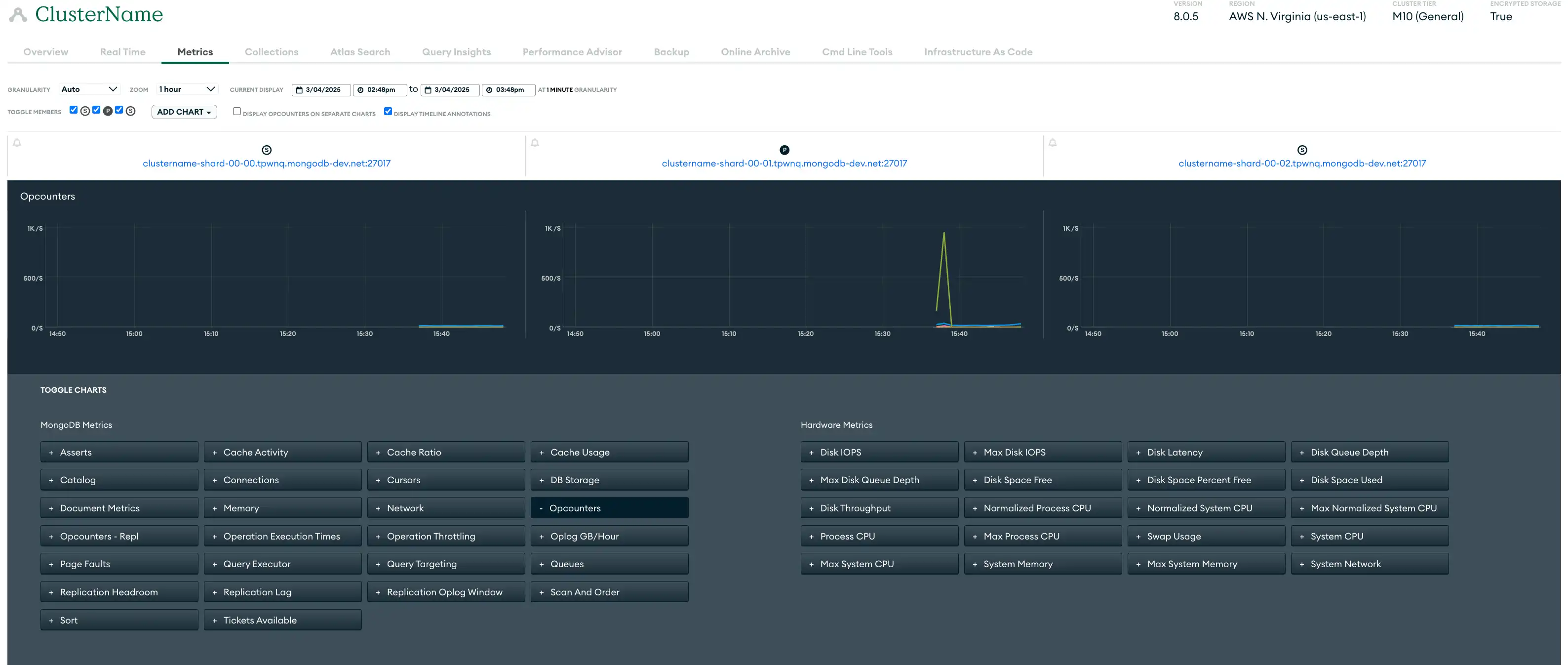 clique para ampliar |
Alertas | O Atlas oferece alertas para mais de 200 tipos de eventos, permitindo que você personalize os alertas para um monitoramento preciso. O Atlas emite alertas para as condições do banco de dados e do servidor que você ajusta nas suas configurações de alerta. Quando uma condição aciona um alerta, o Atlas exibe um símbolo de aviso no cluster e envia notificações de alerta. Você pode usar a UI do Atlas , a API de administração do Atlas , o Atlas CLI e o recurso Terraform integrado para configurar alertas e a notificação de alerta . |
Monitoramento | As visualizações de monitoramento do Atlas fornecem insights sobre várias métricas principais, incluindo desempenho de hardware e eficiência da operação de banco de dados . Ferramentas como painéis de desempenho em tempo real para visibilidade de rede e operações, analisadores de query para rastrear tendências de eficiência e sugestões de índice automatizadas permitem monitorar e solucionar problemas com mais eficiência, gerando maior eficiência operacional. Por exemplo, esses gráficos podem ajudá-lo a entender o impacto das reinicializações e das eleições do servidor no desempenho do banco de dados . |
Registros | O Atlas fornece registros para cada processo no cluster. Cada processo mantém uma conta de sua atividade em seu próprio arquivo de log. Você pode baixar logs usando a IU do Atlas, a Atlas CLI e a API de administração do Atlas. Para saber mais, consulte Orientação para auditoria e registro do Atlas. |

Recomendações para Monitoramento e Alertas do Atlas
Implantações de região única não apresentam considerações exclusivas para integrações com ferramentas de alerta de terceiros, como Datadog e Prometheus. Consulte Todas as Recomendações de Paradigma de Implantação.
Em clusters multirregionais, considere os possíveis custos de transferência de dados associados ao envio de logs e métricas entre regiões. Recomendamos que você configure o seu sistema de logs e auditoria para minimizar as transferências de dados entre regiões, possivelmente mantendo os logs locais na região onde são gerados.
Todas as Recomendações de Paradigmas de Implantação
As seguintes recomendações se aplicam a todos os paradigmas de implantação.
Monitorar usando métricas
Para monitorar o desempenho do seu cluster ou banco de dados, você pode visualizar métricas do cluster, como taxa de transferência histórica, desempenho e métricas de utilização. A tabela a seguir lista algumas (mas não todas as) categorias importantes de métricas a serem monitoradas:
Operações do cluster do Atlas e métricas de conexão |
|
Métricas de hardware |
|
Métricas de replicação |
|
Você pode usar a UI do Atlas , a API de administração do Atlas e o Atlas CLI para visualizar as métricas do Atlas cluster. Além disso, o Atlas oferece integrações internas com ferramentas de terceiros, como Datadog e Prometheus, e você também pode aproveitar a API de administração do Atlas para integrar-se a outras ferramentas de métricas personalizadas.
Para saber mais, consulte Revisar métricas de cluster.
Monitore configurando alertas
O Atlas se integra à sua pilha de observabilidade existente, permitindo que você receba alertas e tome decisões baseadas em dados sem precisar substituir suas ferramentas atuais ou alterar seus fluxos de trabalho. O Atlas pode enviar notificações de alerta com ferramentas de terceiros, como Microsoft Teams, PagerDuty, DataDog, Opsgenie, Splunk On‑Call e outras ferramentas para oferecer visibilidade tanto do desempenho do banco de dados quanto da pilha completa no mesmo local.
Configure alertas e notificações para eventos de segurança, como tentativas de login mal‑sucedidas, padrões de acesso incomuns e violações de dados. Em ambientes de desenvolvimento e teste, recomendamos configurar alertas para clusters que estiveram inativos por sete ou mais dias para ajudar a identificar quais clusters podem ser desligados para economizar custos.
Ao visualizar alertas na UI do Atlas, recomendamos que você use os filtros disponíveis para limitar os resultados por host, conjunto de réplicas, cluster, shard e muito mais, para ajudar a focar nos alertas mais críticos.
Configurações recomendadas de alerta do Atlas
No mínimo, recomendamos configurar os seguintes alertas. Essas recomendações de alertas fornecem uma linha de base, mas você deve ajustá-las com base nas características do volume de trabalho. Onde as condições de "alta prioridade" forem especificadas na tabela a seguir, recomendamos que você configure vários alertas para a mesma condição, um para um nível de gravidade de baixa prioridade e outro para um nível de gravidade de alta prioridade . Isso permite que você defina as configurações de notificação de alerta para cada um separadamente.
O Atlas configura alguns alertas por padrão. Para saber mais sobre as configurações padrão para alertas, consulte Configurações padrão para alertas.
Condição | Limite de alerta recomendado: baixa prioridade | Limite de alerta recomendado: alta prioridade | Insights Chave |
|---|---|---|---|
Oplog window | < 24h por 5 minutos | < 1h por 10 minutos | Monitore a janela de oplog de replicação, juntamente com o headroom de replicação, para determinar se o secundário pode precisar de uma ressincronização completa em breve. A janela de oplog geralmente ajuda a determinar com antecedência a resiliência dos secundários às interrupções planejadas e não planejadas. |
> 3 por 5 minutos | > 30 por 5 minutos | Monitore os eventos de eleição, que ocorrem quando um nó primário é desativado e um nó secundário é eleito como o novo nó primário. Eventos de eleição frequentes podem interromper operações e impactar a disponibilidade, causando indisponibilidade temporária de gravação e possível rollback de dados. Manter os eventos de eleição ao mínimo garante operações de gravação consistentes e desempenho estável do cluster. | |
Ler IOPS | > 4000 por 2 minutos | > 9000 por 5 minutos | Monitore se o IOPS de disco se aproxima do IOPS máximo provisionado. Determine se o cluster pode lidar com volumes de trabalho futuros. |
Gravar IOPS | > 4000 por 2 minutos | > 9000 por 5 minutos | Monitore se o IOPS de disco se aproxima do IOPS máximo provisionado. Determine se o cluster pode lidar com volumes de trabalho futuros. |
Latência de leitura | > 20ms por 5 minutos | > 50 s por 5 minutos | Monitore a latência do disco para acompanhar a eficiência da leitura e gravação do disco. |
Latência de gravação | > 20ms por 5 minutos | > 50ms por mais de 5 minutos | Monitore a latência do disco para acompanhar a eficiência da leitura e gravação do disco. |
Trocar o uso | > 2GB por 15 minutos | > 2GB por 15 minutos | Monitore a memória para determinar se é necessário atualizar para uma camada de cluster superior. Essa métrica representa o valor médio durante o período especificado pela granularidade da métrica. |
Anfitrião inativo | 15 minutos | 24 horas | Monitore seus hosts para detectar imediatamente o tempo de inatividade. Um host inativo por mais de 15 minutos pode impacto a disponibilidade, enquanto o tempo de inatividade superior a 24 horas é crítico, colocando em risco a acessibilidade aos dados e o desempenho dos aplicação . |
Não primário | 5 minutos | 5 minutos | Monitore o status dos seus conjuntos de réplicas para identificar instâncias onde não há nó primary. A falta de um primary por mais de 5 minutos pode interromper as operações de gravação e impacto a funcionalidade do aplicação . |
Ativo ausente | 15 minutos | 15 minutos | Monitore o status dos processos |
Falhas na Página | > 50/segundo por 5 minutos | > 100/segundo por 5 minutos | Monitore as falhas da página para determinar se deve aumentar sua memória. Essa métrica exibe a taxa média de falhas de página nesse processo por segundo durante o período de amostra selecionado. Em ambientes não Windows, isso se aplica somente a falhas de páginas rígidas. |
atraso de replicação | > 240 segundo por 5 minutos | > 1 hora por 5 minutos | Monitore o atraso da replicação para determinar se o secundário pode sair do oplog. |
Falha no backup | Qualquer ocorrência | none | Monitore as operações de backup para garantir a integridade dos dados. Um backup com falha pode comprometer a disponibilidade dos dados. |
Backup restaurado | Qualquer ocorrência | none | Verifique os backups restaurados para garantir a integridade dos dados e a funcionalidade do sistema. |
Falha no snapshot fallback | Qualquer ocorrência | none | Monitore as operações de snapshot de fallback para garantir a redundância de dados e a capacidade de recuperação. |
Cronograma de backup atrasado | > 12 horas | > 12 horas | Verifique os agendamentos de backup para garantir que estejam no caminho certo. Atrasar pode correr o risco de perda de dados e comprometer os planos de recuperação. |
Leituras enfileiradas | > 0-10 | > 10+ | Monitore as leituras em fila para garantir a recuperação eficiente de dados. Altos níveis de leituras em fila podem indicar restrições de recursos ou gargalos de desempenho, exigindo otimização para manter a capacidade de resposta do sistema. |
Gravações em fila | > 0-10 | > 10+ | Monitore as gravações em fila para manter o processamento de dados eficiente. Altos níveis de gravações em fila podem indicar restrições de recursos ou gargalos de desempenho, exigindo otimização para manter a capacidade de resposta do sistema. |
Reinicia a última hora | > 2 | > 2 | Acompanhe o número de reinicializações na última hora para detectar problemas de instabilidade ou configuração. As reinicializações frequentes podem indicar problemas subjacentes que exigem pesquisa imediata para manter a confiabilidade e o tempo de atividade do sistema. |
Qualquer ocorrência | none | Monitore as eleições primárias para garantir operações de cluster estáveis. Eleições frequentes podem indicar problemas de rede ou restrições de recursos, afetando potencialmente a disponibilidade e o desempenho do banco de dados. | |
Manutenção não é mais necessária | Qualquer ocorrência | none | Revise as tarefas de manutenção desnecessárias para otimizar recursos e minimizar as interrupções. |
Manutenção iniciada | Qualquer ocorrência | none | Acompanhe o início das tarefas de manutenção para assegurar que as atividades planejadas prossigam sem contratempos. A supervisão adequada contribui para manter o desempenho do sistema e reduzir o tempo de inatividade durante a manutenção. |
Manutenção programada | Qualquer ocorrência | none | Monitore a manutenção programada para se preparar para possíveis impactos no sistema. |
> 5% para 5 minutos | > 20% para 5 minutos | Monitore o roubo de CPU em clusters AWS EC2 com desempenho dimensionável para identificar quando o uso da CPU excede a linha de base garantida devido a núcleos compartilhados. Altas porcentagens de roubo indicam que o saldo de crédito da CPU está esgotado, o que afeta o desempenho. | |
CPU | > 75% para 5 minutos | > 75% para 5 minutos | Monitore o uso da CPU para determinar se os dados são recuperados do disco em vez da memória. |
Uso da partição do disco | > 90% | > 95% para 5 minutos | Monitore o uso da partição de disco para garantir disponibilidade de armazenamento suficiente. Altos níveis de uso podem levar à degradação do desempenho e possíveis interrupções do sistema. |
Para saber mais, consulte Configurar e resolver alertas.
Monitore utilizando as ferramentas integradas do Atlas
O Atlas fornece várias ferramentas que permitem monitorar e melhorar de forma proativa o desempenho do seu banco de dados.
Painel de desempenho em tempo real
O Real-Time Performance Panel (RTPP) na UI do Atlas fornece insights sobre o tráfego de rede atual, operações de banco de dados e estatísticas de hardware sobre os hosts em uma granularidade de um segundo na UI do Atlas . Recomendamos que você use o RTPP para:
Identifique visualmente as operações relevantes do banco de dados
Avaliar os tempos de execução da consulta
Avalie a proporção de documentos digitalizados para documentos devolvidos
Monitore a carga e a taxa de transferência da rede
Descubra a possível latência de replicação em membros secundários de conjuntos de réplicas
Elimine as operações antes que elas sejam concluídas para liberar recursos valiosos
O RTPP não está disponível para monitorar a partir da API de administração do Atlas, mas você pode ativar e desativar o RTPP a partir da API de administração do Atlas com Atualizar configurações de um projeto.
Para aprender mais, consulte Monitorar o desempenho em tempo real.
Perfilador de consulta
O Profiler de query identifica consultas lentas e gargalos e sugere o refinamento de índices e a reestruturação de consultas para melhorar o desempenho do seu banco de dados. Ele fornece visibilidade das operações mais lentas em uma janela de 24 horas na IU do Atlas, facilitando a identificação de tendências e pontos fora da curva na eficiência da consulta. Recomendamos que você use esses dados para identificar e solucionar consultas com baixo desempenho, reduzindo a sobrecarga de desempenho.
Você pode retornar linhas de log para queries lentas que o Analisador de query identifica na API de administração do Atlas com Retornar queries lentas.
Para saber mais, consulte Monitorar o desempenho da query com o Query Profiler.
Assistente de desempenho
O Performance Advisor analisa automaticamente os logs em busca de queries de execução lenta e recomenda índices para criar e descartar. Ele analisa consultas lentas e fornece sugestões de índices para coleções individuais, classificadas por uma pontuação de impacto calculada, e adaptadas à sua carga de trabalho. É uma maneira fácil e imediata de implementar melhorias de alto impacto no desempenho. Recomendamos que você monitore regularmente, concentre-se em consultas lentas e ative o analisador de consultas seletivamente para minimizar a sobrecarga.
Você pode usar a UI do Atlas , o Atlas CLI e a API de administração do Atlas para visualizar queries lentas e sugestões para melhorar o desempenho de suas queries a partir do Performance Advisor.
Você pode retornar linhas de log para queries lentas que o Performance Advisor identifica na API de administração do Atlas com Retornar queries lentas. Para retornar índices sugeridos e mais com a API de Administração do Atlas, consulte Performance Advisor.
Para saber mais, consulte Monitorar e melhorar consultas lentas com o Performance Advisor.
Insights de namespace
A página namespace Insights na IU do Atlas permite que você monitore o desempenho e as métricas de uso da coleção. Ela exibe métricas (como o número de operações CRUD na coleção) e estatísticas (como o tempo médio de execução de consultas) para determinados hosts e tipos de operação para as coleções que você fixar para monitoramento. Isso proporciona uma visibilidade mais detalhada do desempenho da coleção, que pode ser utilizada para otimizar o desempenho do banco de dados, resolver problemas e tomar decisões sobre dimensionamento, indexação e ajuste de consultas.
Para saber mais, consulte Monitorar a latência de consulta no nível de coleção com o Namespace Insights.
Feed de atividade
O Feed de Atividades da Organização e o Feed de Atividades do Projeto na IU do Atlas listam todos os eventos que ocorrem para uma determinada organização ou projeto do Atlas, respectivamente. Você pode filtrar cada feed de atividades por tipo de evento e faixa de tempo para monitorar eventos como atualizações de acesso à API, alterações de configuração de alerta e muito mais. Isso permite revisar os registros de atividades da sua organização ou projeto no nível de granularidade desejado.
Você usa a IU do Atlas, o Atlas CLI e a Administration API do Atlas para recuperar eventos de cada feed de atividades. Para saber mais, consulte Visualizar feed de atividades.
Monitorar usando logs
O Atlas retém os últimos 30 dias de mensagens de log e mensagens de auditoria de eventos do sistema. Você pode baixar os logs do Atlas a qualquer momento até o final de seus períodos de retenção usando a IU do Atlas, a API de administração do Atlas e o Atlas CLI.
Para saber mais, consulte Exibir e baixar registros do MongoDB.
Você também pode exportar registros para um3 bucket do AWS S. Quando você configura este recurso, o Atlas exporta mongod mongosde, e logs de auditar para um bucket AWS S3 a cada minuto.
Exemplos de automação: monitoramento e registro do Atlas
Os exemplos seguintes demonstram como permitir o monitoramento usando as ferramentas do Atlas para automação.
Exibir métricas do cluster
Execute o seguinte comando para recuperar a quantidade de espaço usado e livre no disco especificado. Essa métrica pode ser utilizada para verificar se o sistema está ficando sem espaço disponível.
atlas metrics disks describe atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 data \ --granularity P1D \ --period P1D \ --type DISK_PARTITION_SPACE_FREE,DISK_PARTITION_SPACE_USED \ --projectId 6698000acf48197e089e4085 \
Configurar alertas
Execute o comando a seguir para criar uma notificação de alerta para um endereço de e-mail quando seu sistema não tiver um primary.
atlas alerts settings create \ --enabled \ --event "NO_PRIMARY" \ --matcherFieldName CLUSTER_NAME \ --matcherOperator EQUALS \ --matcherValue ftsTest \ --notificationType EMAIL \ --notificationEmailEnabled \ --notificationEmailAddress "myName@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
Monitore o desempenho do banco de dados
Execute o seguinte comando para habilitar o limite de operação lenta gerenciado pelo Atlas para o seu projeto.
atlas performanceAdvisor slowOperationThreshold enable --projectId 56fd11f25f23b33ef4c2a331
Baixar registros
Execute o seguinte comando para baixar um arquivo compactado que contém os registros MongoDB para o host especificado em seu projeto.
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Veja todos os exemplos do Atlas Architecture Go SDK em um único projeto no repositório do Atlas Architecture Go SDK no Github.
Antes de autenticar e executar os scripts de exemplo usando o Atlas Go SDK, você deve:
Criar uma conta de serviço do Atlas. Armazene seu ID de cliente e segredo como variáveis de ambiente executando o seguinte comando no terminal:
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Defina as seguintes variáveis de configuração no seu projeto Go:
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
Exibir métricas do cluster
O seguinte script de exemplo demonstra como recuperar a quantidade de espaço usado e livre no disco especificado. Essa métrica pode ser utilizada para verificar se o sistema está ficando sem espaço disponível.
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.development" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch disk metrics with the provided parameters p := &admin.GetDiskMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, PartitionName: "data", M: &[]string{"DISK_PARTITION_SPACE_FREE", "DISK_PARTITION_SPACE_USED"}, Granularity: admin.PtrString("P1D"), Period: admin.PtrString("P1D"), } view, err := metrics.FetchDiskMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch disk metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
Baixar registros
O script de exemplo a seguir demonstra como baixar e descompactar um arquivo comprimido que contém os logs do MongoDB para o host especificado no seu projeto do Atlas:
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Dica
Para exemplos de Terraform que impõem nossas recomendações em todos os colunas, consulte um dos seguintes exemplos no Github:
Antes de criar recursos com o Terraform, você deve:
Crie sua organização pagadora e uma chave de API para a organização pagadora. Armazene sua chave de API como variáveis de ambiente ao executar o seguinte comando no terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Também recomendamos criar um espaço de trabalho para seu ambiente.
Configurar alertas
Os exemplos a seguir demonstram como configurar alertas e notificações de alerta . Você deve criar os seguintes arquivos para cada exemplo. Coloque os arquivos de cada exemplo em seu próprio diretório. Altere os IDs e nomes para usar seus valores:
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster"
Exemplo: Use o seguinte para enviar uma notificação de alerta por e-mail para usuários com a função GROUP_CLUSTER_MANAGER quando houver um atraso de replicação, o que pode resultar em inconsistências de dados.
main.tf
resource "mongodbatlas_alert_configuration" "test" { project_id = var.atlas_project_id event_type = "REPLICATION_OPLOG_WINDOW_RUNNING_OUT" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } threshold_config { operator = "LESS_THAN" threshold = 1 units = "HOURS" } }
Exibir métricas do cluster
Execute o comando de amostra para recuperar as seguintes métricas:
OPCOUNTERS – Monitore a quantidade de consultas, atualizações, inserções e exclusões que ocorrem no pico de carga e garanta que a carga não aumente inesperadamente.
CONEXÕES – Certifique‑se de que o número de conexões usadas para heartbeats e replicação entre membros não ultrapasse o limite estabelecido.
DIRECIONAMENTO DE CONSULTAS – Certifique‑se de que o número de chaves e documentos digitalizados em relação ao número de documentos retornados, em média por segundo, não seja muito alto.
CPU do SISTEMA – Assegure‑se de que o uso da CPU permaneça estável.
FILA DE BLOQUEIO GLOBAL – Monitore o número de operações de leitura e gravação que estão atualmente na fila e aguardando o bloqueio de leitura e gravação, e garanta que a carga não aumente inesperadamente.
atlas metrics processes atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 \ --projectId 56fd11f25f23b33ef4c2a331 \ --granularity PT1H \ --period P7D \ --type OPCOUNTER_DELETE,OPCOUNTER_INSERT,OPCOUNTER_QUERY,OPCOUNTER_UPDATE,CONNECTIONS,QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED,QUERY_TARGETING_SCANNED_PER_RETURNED,SYSTEM_CPU_GUEST,SYSTEM_CPU_IOWAIT,SYSTEM_CPU_IRQ,SYSTEM_CPU_KERNEL,SYSTEM_CPU_NICE,SYSTEM_CPU_SOFTIRQ,SYSTEM_CPU_STEAL,SYSTEM_CPU_USER,GLOBAL_LOCK_CURRENT_QUEUE_TOTAL,GLOBAL_LOCK_CURRENT_QUEUE_READERS,GLOBAL_LOCK_CURRENT_QUEUE_WRITERS \ --output json
Configurar alertas
Execute o seguinte comando para enviar alertas a um grupo por e-mail quando houver possíveis tempestades de conexão com base no número de conexões no seu projeto.
atlas alerts settings create \ --enabled \ --event "OUTSIDE_METRIC_THRESHOLD" \ --metricName CONNECTIONS \ --metricOperator LESS_THAN \ --metricThreshold 1 \ --metricUnits RAW \ --notificationType GROUP \ --notificationRole "GROUP_DATA_ACCESS_READ_ONLY","GROUP_CLUSTER_MANAGER","GROUP_DATA_ACCESS_ADMIN" \ --notificationEmailEnabled \ --notificationEmailAddress "user@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
Monitore o desempenho do banco de dados
Execute o comando a seguir para recuperar os índices sugeridos para collections com queries lentas.
atlas performanceAdvisor suggestedIndexes list \ --projectId 56fd11f25f23b33ef4c2a331 \ --processName atlas-zqva9t-shard-00-02.2rnul.mongodb.net:27017
Baixar registros
Execute o seguinte comando para baixar um arquivo compactado que contém os registros MongoDB para o host especificado em seu projeto.
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Veja todos os exemplos do Atlas Architecture Go SDK em um único projeto no repositório do Atlas Architecture Go SDK no Github.
Antes de autenticar e executar os scripts de exemplo usando o Atlas Go SDK, você deve:
Criar uma conta de serviço do Atlas. Armazene seu ID de cliente e segredo como variáveis de ambiente executando o seguinte comando no terminal:
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Defina as seguintes variáveis de configuração no seu projeto Go:
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
Para obter mais informações sobre como autenticar e criar um cliente, consulte o exemplo de projeto completo do Atlas SDK for Go no Github.
Exibir métricas do cluster
O script de exemplo a seguir demonstra como recuperar as seguintes métricas:
OPCOUNTERS – Monitore a quantidade de consultas, atualizações, inserções e exclusões que ocorrem no pico de carga e garanta que a carga não aumente inesperadamente.
CONEXÕES – Certifique‑se de que o número de conexões usadas para heartbeats e replicação entre membros não ultrapasse o limite estabelecido.
DIRECIONAMENTO DE CONSULTAS – Certifique‑se de que o número de chaves e documentos digitalizados em relação ao número de documentos retornados, em média por segundo, não seja muito alto.
CPU do SISTEMA – Assegure‑se de que o uso da CPU permaneça estável.
FILA DE BLOQUEIO GLOBAL – Monitore o número de operações de leitura e gravação que estão atualmente na fila e aguardando o bloqueio de leitura e gravação, e garanta que a carga não aumente inesperadamente.
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch process metrics with the provided parameters p := &admin.GetHostMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, M: &[]string{ "OPCOUNTER_INSERT", "OPCOUNTER_QUERY", "OPCOUNTER_UPDATE", "TICKETS_AVAILABLE_READS", "TICKETS_AVAILABLE_WRITE", "CONNECTIONS", "QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED", "QUERY_TARGETING_SCANNED_PER_RETURNED", "SYSTEM_CPU_GUEST", "SYSTEM_CPU_IOWAIT", "SYSTEM_CPU_IRQ", "SYSTEM_CPU_KERNEL", "SYSTEM_CPU_NICE", "SYSTEM_CPU_SOFTIRQ", "SYSTEM_CPU_STEAL", "SYSTEM_CPU_USER", }, Granularity: admin.PtrString("PT1H"), Period: admin.PtrString("P7D"), } view, err := metrics.FetchProcessMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch process metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
Baixar registros
O script de exemplo a seguir demonstra como baixar e descompactar um arquivo comprimido que contém os logs do MongoDB para o host especificado no seu projeto do Atlas:
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Dica
Para exemplos de Terraform que impõem nossas recomendações em todos os colunas, consulte um dos seguintes exemplos no Github:
Antes de criar recursos com o Terraform, você deve:
Crie sua organização pagadora e uma chave de API para a organização pagadora. Armazene sua chave de API como variáveis de ambiente ao executar o seguinte comando no terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Também recomendamos criar um espaço de trabalho para seu ambiente.
Configurar alertas
Os exemplos a seguir demonstram como configurar alertas e notificações de alerta . Você deve criar os seguintes arquivos para cada exemplo. Coloque esses arquivos para cada exemplo em seu próprio diretório e substitua apenas o arquivo main.tf . Altere os IDs e nomes para usar seus valores:
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string } variable "datadog_api_key" { description = "Datadog api key" type = string } variable "datadog_region" { description = "Datadog region" default = "US5" type = string } variable "prometheus_user_name" { type = string description = "The Prometheus User Name" default = "puser" } variable "prometheus_password" { type = string description = "The Prometheus Password" default = "ppassword" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster" datadog_api_key = "1234567890abcdef1234567890abcdef" datadog_region = "US5" prometheus_user_name = "prometheus_user" prometheus_password = "secure_prometheus_password"
Exemplo 1: use o seguinte para integrar-se a serviços de terceiros, como Datadog e Prometheus, para notificações de alerta.
main.tf
resource "mongodbatlas_third_party_integration" "test_datadog" { project_id = var.atlas_project_id type = "DATADOG" api_key = var.datadog_api_key region = var.datadog_region } resource "mongodbatlas_third_party_integration" "test_prometheus" { project_id = var.atlas_project_id type = "PROMETHEUS" user_name = var.prometheus_user_name password = var.prometheus_password service_discovery = "http" enabled = true } output "datadog.id" { value = mongodbatlas_third_party_integration.test_datadog.id } output "prometheus.id" { value = mongodbatlas_third_party_integration.test_prometheus.id }
Exemplo 2: use o seguinte para enviar uma notificação de alerta para serviços de terceiros, como Datadog e Prometheus, quando não houver nenhum primary no conjunto de réplicas por mais de 5 minutos.
main.tf
resource "mongodbatlas_alert_configuration" "test_alert_notification" { project_id = var.atlas_project_id event_type = "NO_PRIMARY" enabled = true notification { type_name = "PROMETHEUS" integration_id = mongodbatlas_third_party_integration.test_datadog.id # ID of the Atlas Prometheus integration } notification { type_name = "DATADOG" integration_id = mongodbatlas_third_party_integration.test_prometheus.id # ID of the Atlas Datadog integration } matcher { field_name = "REPLICA_SET_NAME" operator = "EQUALS" value = "myReplSet" } threshold_config { operator = "GREATER_THAN" threshold = 5 units = "MINUTES" } }
Exemplo 3: Use o seguinte para enviar uma notificação de alerta por e-mail para usuários com a função GROUP_CLUSTER_MANAGER quando houver um atraso de replicação, o que pode resultar em inconsistências de dados.
main.tf
resource "mongodbatlas_alert_configuration" "test_replication_lag_alert" { project_id = var.atlas_project_id event_type = "OUTSIDE_METRIC_THRESHOLD" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } metric_threshold_config { metric_name = "OPLOG_SLAVE_LAG_MASTER_TIME" operator = "GREATER_THAN" threshold = 1 units = "HOURS" } }