Alta disponibilidade é a capacidade do seu aplicativo de assegurar a operação contínua e reduzir o tempo de inatividade durante falhas de infraestrutura, manutenção do sistema e outras interrupções. A arquitetura de implantação padrão do MongoDB é projetada para alta disponibilidade, com funcionalidades integradas para redundância de dados e failover automático. Esta página descreve opções adicionais de configuração e aprimoramentos na arquitetura de implantação, que você pode escolher para prevenir interrupções e oferecer suporte a mecanismos robustos de failover para falhas de zona, região e de provedor de nuvem.
Recursos do Atlas para Alta Disponibilidade
Replicação de banco de dados
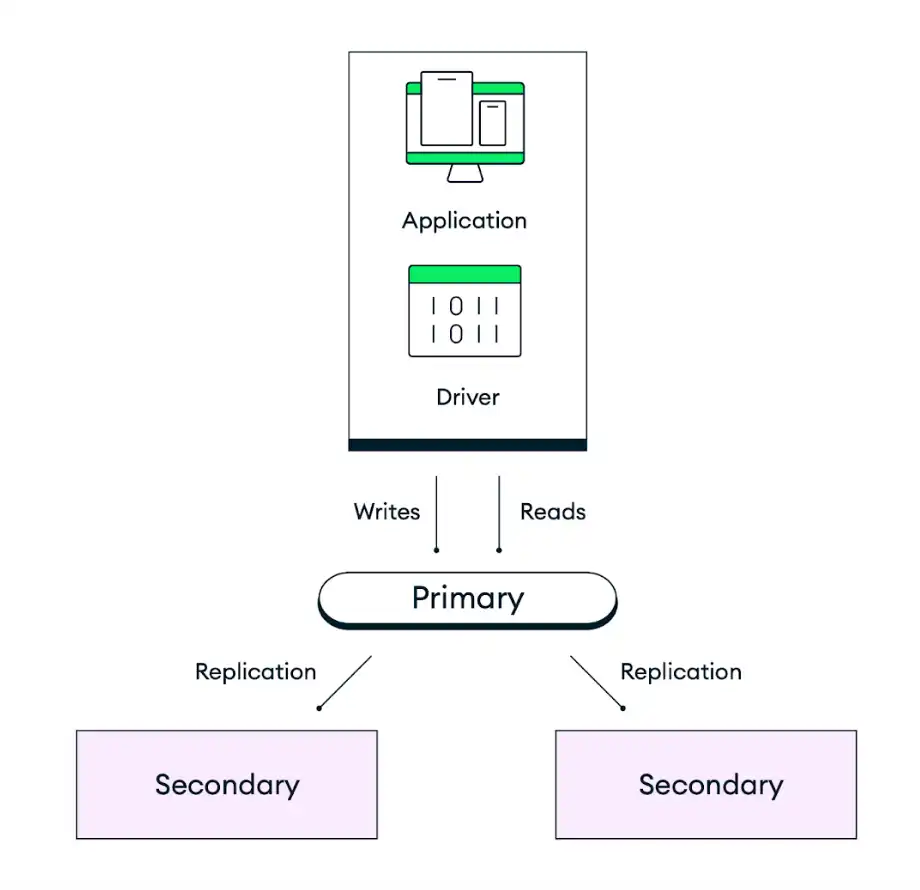
A arquitetura padrão de implantação do MongoDB é projetada para redundância. O Atlas implanta cada cluster como um conjunto de réplicas, com um mínimo de três instâncias de banco de dados (também chamadas de nós ou membros do conjunto de réplicas), distribuídas em zonas de disponibilidade separadas dentro das regiões selecionadas do provedor de nuvem. Os aplicativos gravam dados no nó primário do conjunto de réplicas e, em seguida, o Atlas replica e armazena esses dados em todos os nós do seu cluster. Para controlar a durabilidade do seu armazenamento de dados, você pode ajustar a preocupação de gravação do seu código de aplicativo para concluir a gravação somente depois que um determinado número de secundários tiver confirmado a gravação. O comportamento padrão é que os dados sejam persistidos na maioria dos nós elegíveis antes de confirmar a ação.
O diagrama a seguir ilustra como a replicação opera em um conjunto de réplicas padrão de três nós:

Failover automático
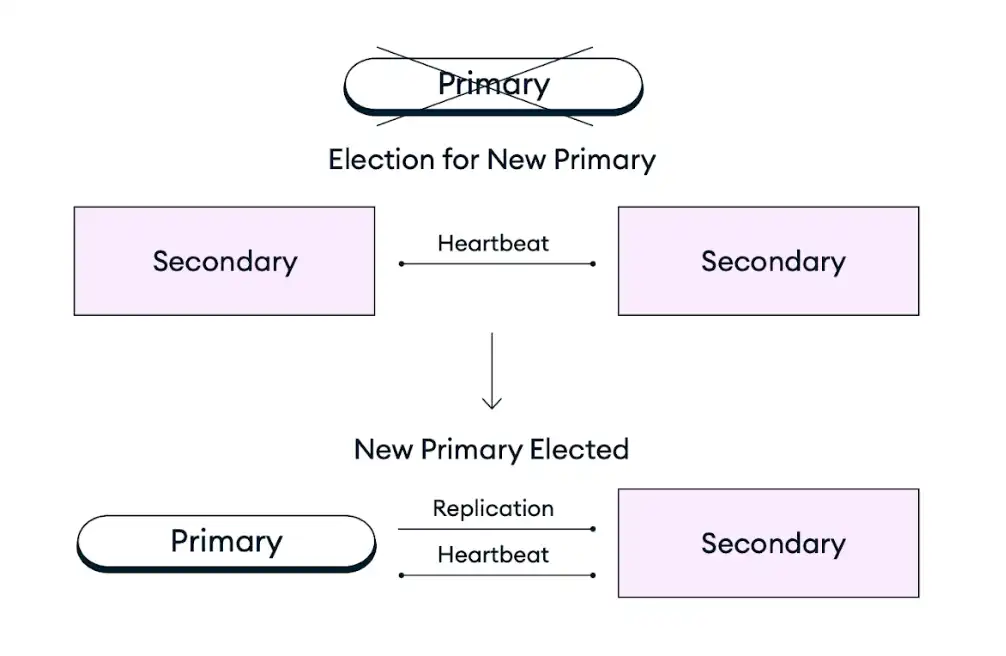
Caso um nó primário em um conjunto de réplicas fique indisponível devido a uma interrupção de infraestrutura, manutenção programada ou qualquer outra interrupção, os clusters Atlas se recuperam automaticamente promovendo um nó secundário existente à função de nó primário em uma eleição de conjunto de réplicas. Este processo de failover é totalmente automático e é concluído em segundos sem qualquer perda de dados, incluindo operações que estavam em andamento no momento da falha, que passarão por uma nova tentativa de execução após a falha se as gravações repetíveis estiverem habilitadas. Após uma eleição do conjunto de réplicas, o Atlas restaura ou substitui o nó com falha para garantir que o cluster retorne à configuração desejada o mais rápido possível. O driver do cliente MongoDB também alterna automaticamente todas as conexões de cliente durante e após a falha.
O diagrama a seguir representa o processo de eleição do conjunto de réplicas:

Para aumentar a disponibilidade dos aplicativos mais críticos, você pode dimensionar sua implantação adicionando nós, regiões ou provedores de nuvem para resistir a interrupções de zona, região ou provedor, respectivamente. Para aprender mais, veja a recomendação Dimensionar seu Paradigma de Implantação para Tolerância a Falhas abaixo.
Recomendações para Alta Disponibilidade do Atlas
As recomendações a seguir descrevem opções adicionais de configuração e aprimoramentos na arquitetura de implantação que você pode fazer para aumentar a disponibilidade da sua implantação.
Escolha uma camada do cluster que atenda às metas de implantação
Ao criar um novo cluster, você pode escolher entre uma faixa de camadas do cluster disponíveis nos tipos de implantação Dedicated, Flex ou Free. A camada do cluster no MongoDB Atlas especifica os recursos (memória, armazenamento, vCPUs e IOPS) disponíveis para cada nó no seu cluster. O dimensionamento para um nível superior melhora a capacidade do cluster de lidar com picos de tráfego e aumenta a confiabilidade do sistema por meio de uma resposta mais rápida a altas cargas de trabalho. Para determinar a camada do cluster recomendada para o tamanho do seu aplicativo, consulte o Guia de Tamanhos de Cluster do Atlas.
O Atlas também oferece suporte ao dimensionamento automático para permitir que o cluster se ajuste automaticamente aos picos de demanda. A automatização desta ação reduz o risco de uma interrupção devido a restrições de recursos. Para aprender mais, veja Orientação para o Provisionamento Automatizado de Infraestrutura do Atlas.
Dimensionar o Paradigma de Implantação para Tolerância a Falhas
A tolerância a falhas para uma implantação do Atlas pode ser medida pelo número de membros do conjunto de réplicas que podem ficar indisponíveis enquanto a implantação ainda permanece operacional. No evento de uma interrupção de zona de disponibilidade, região ou provedor de nuvem, os clusters do Atlas se autorreparam promovendo um nó secundário existente à função de nó primário em uma eleição de conjunto de réplicas. A maioria dos nós de votação em um conjunto de réplicas deve estar operacional para executar uma eleição de conjunto de réplicas quando um nó primário vivencia uma interrupção.
Para garantir que um conjunto de réplicas possa eleger um primário em caso de interrupção parcial de região, você deve implantar clusters em regiões com no mínimo três zonas de disponibilidade. As zonas de disponibilidade são grupos separados de datacenters dentro de uma única região de provedor de nuvem, cada um com sua própria infraestrutura de energia, refrigeração e rede. O Atlas distribui automaticamente seu cluster pelas zonas de disponibilidade quando elas são suportadas pela região do seu provedor de nuvem selecionado, de modo que, se uma zona sofrer uma interrupção, os nós restantes no seu cluster ainda oferecerão suporte a serviços regionais. A maioria das regiões de provedores de nuvem com suporte do Atlas possui pelo menos três zonas de disponibilidade. Essas regiões são marcadas com um ícone de estrela na IU do Atlas. Para obter mais informações sobre as regiões recomendadas, consulte Provedores de nuvem e regiões.
Para aprimorar ainda mais a tolerância a falhas dos seus aplicativos mais críticos, você pode dimensionar sua implantação adicionando nós, regiões ou provedores de nuvem para resistir a interrupções em zonas de disponibilidade, regiões ou provedores, respectivamente. Você pode aumentar a contagem de nós para qualquer número ímpar de nós, com um máximo de 7 nós elegíveis e 50 nós no total. Você também pode implantar um cluster em várias regiões para aumentar a disponibilidade em uma geografia maior e permitir o failover automático no caso de uma interrupção completa da região que desativa todas as zonas de disponibilidade na sua região primária. O mesmo padrão se aplica à implantação do seu cluster em vários provedores de nuvem para resistir a uma interrupção completa de um provedor de nuvem.
Para obter orientação sobre como escolher uma implantação que equilibre suas necessidades de alta disponibilidade, baixa latência, compliance e custo, consulte a documentação Paradigmas de implantação do Atlas.
Evitar Exclusão Acidental do Cluster
Você pode habilitar a proteção contra encerramento para garantir que um cluster não seja encerrado acidentalmente e que não exija tempo de inatividade para ser restaurado a partir de um backup. Para excluir um cluster que tenha a proteção contra encerramento habilitada, primeiro você deve desabilitar essa proteção. Por padrão, o Atlas desativa a proteção contra encerramento para todos os clusters.
Habilitar a proteção contra encerramento é especialmente importante ao utilizar ferramentas de IaC, como Terraform, para garantir que uma reimplantação não faça o provisionamento de nova infraestrutura.
Testar failovers automáticos
Antes de implantar um aplicativo em produção, recomendamos fortemente que você simule vários cenários que exijam failovers automáticos de nós para avaliar sua preparação para tais eventos. Com o Atlas, você pode testar o failover do nó primário para um conjunto de réplicas e simular interrupções regionais para uma implantação multirregional.
Use o majority preocupação de gravação
O MongoDB permite que você especifique o nível de reconhecimento solicitado para operações de gravação usando a preocupação de gravação. O Atlas tem uma preocupação de gravação padrão de majority, o que significa que os dados devem ser replicados em mais da metade dos nós do seu cluster antes que o Atlas dispare um aviso de sucesso. O uso de majority em vez de um valor numérico definido como 2 permite que o Atlas ajuste automaticamente a necessidade de replicação em menos nós caso ocorra uma interrupção temporária de um nó, permitindo que as gravações continuem após o failover automático. Isso também oferece uma configuração consistente em todos os ambientes, garantindo que sua string de conexão permaneça a mesma, seja em um ambiente de teste com três nós ou de produção, com um número maior de nós.
Configurar Leituras e Gravações de Banco de Dados Repetíveis
O Atlas oferece suporte a operações de leituras repetíveis e gravações repetíveis. Quando habilitadas, o Atlas repete as operações de leitura e gravação uma vez como uma proteção contra interrupções de rede intermitentes e eleições de conjunto de réplicas nas quais o aplicativo não consegue encontrar temporariamente um nó primário íntegro. As gravações repetíveis exigem uma preocupação de gravação reconhecida, o que significa que sua preocupação de gravação não pode ser {w:
0}.
Monitorar e Planejar o Uso de Recursos
Para evitar problemas de capacidade dos recursos, recomendamos que você monitore a utilização dos recursos e realize sessões regulares de planejamento de capacidade. Os Professional Services do MongoDB oferecem essas sessões. Consulte nosso Plano de recuperação de desastre de capacidade de recurso para obter nossas recomendações sobre como se recuperar de problemas de capacidade de recurso.
Para conhecer as melhores práticas de alertas e monitoramento da utilização de recursos, consulte Orientações para monitoramento e alertas do Atlas.
Planejar as alterações da versão do MongoDB
Recomendamos que você execute a versão mais recente do MongoDB para aproveitar os novos recursos e as garantias de segurança aprimoradas. Você deve sempre fazer o upgrade para a versão principal mais recente do MongoDB antes que sua versão atual atinja o fim da vida útil.
Você não pode fazer o downgrade da sua versão do MongoDB usando a IU do Atlas. Por isso, recomendamos que trabalhar diretamente com os Professional Services ou Serviços Técnicos do MongoDB ao planejar e executar um upgrade de versão principal para ajudar a evitar eventuais problemas que possam ocorrer durante o processo de upgrade.
Configurar janelas de manutenção
O Atlas mantém a disponibilidade durante a manutenção programada aplicando atualizações de forma contínua a um nó por vez. Sempre que o primário atual é colocado offline para manutenção durante esse processo, o Atlas elege um novo primário por meio de uma eleição automática do conjunto de réplicas. Este é o mesmo processo que ocorre durante o failover automático em resposta a uma interrupção não planejada do nó primário.
Recomendamos que você configure um período de manutenção personalizado para o seu projeto, para evitar eleições de conjunto de réplicas relacionadas à manutenção durante os horários críticos para os negócios. Você também pode definir horas protegidas nas configurações do período de manutenção para definir um período diário, no qual as atualizações padrão não podem começar. Atualizações padrão não envolvem reinicializações ou ressincronizações de clusters.
Exemplos de Automação: Alta Disponibilidade do Atlas
Os exemplos a seguir configuram a topologia de implantação de região única, 3 conjunto de réplicas de nó / shard usando as ferramentas do Atlas para automação.
Esses exemplos também incluem outras configurações recomendadas, tais como:
Camada do cluster configurada para
M10em um ambiente de desenvolvimento/teste. Use o guia de tamanho do cluster para saber qual a camada do cluster recomendada para o tamanho do seu aplicativo.Região única, 3-Conjunto de réplicas de nós/Topologia de implantação de fragmento.
Nossos exemplos utilizam AWS, Azure e Google Cloud indistintamente. Você pode usar qualquer um desses três provedores de nuvem, mas deve alterar o nome da região para corresponder à do provedor de nuvem. Para saber mais sobre os provedores de nuvem e as respectivas regiões, consulte Provedores de nuvem.
Camada do cluster definida como
M30para um aplicativo de porte médio. Use o guia de tamanho do cluster para saber qual a camada do cluster recomendada para o tamanho do seu aplicativo.Região única, 3-Conjunto de réplicas de nós/Topologia de implantação de fragmento.
Nossos exemplos utilizam AWS, Azure e Google Cloud indistintamente. Você pode usar qualquer um desses três provedores de nuvem, mas deve alterar o nome da região para corresponder à do provedor de nuvem. Para saber mais sobre os provedores de nuvem e as respectivas regiões, consulte Provedores de nuvem.
Observação
Antes de criar recursos com o Atlas CLI, você deve:
Crie sua organização pagadora e crie uma chave de API para a organização pagadora.
Conecte-se pelo Atlas CLI seguindo as instruções para Programmatic Use.
Criar uma implantação por projeto
Para seus ambientes de desenvolvimento e teste, execute o seguinte comando para cada projeto. No exemplo a seguir, altere os IDs e nomes para usar seus valores.
Observação
O exemplo a seguir não permite o dimensionamento automático para controlar os custos em ambientes de desenvolvimento e teste. Para ambientes de teste e produção, o dimensionamento automático deve ser ativado. Consulte a aba "Ambientes de estágio e produção" para exemplos que permitem o dimensionamento automático.
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=dev \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
Para os seus ambientes de preparação e produção, crie o seguinte arquivo cluster.json para cada projeto. Altere os IDs e nomes para usar os seus valores:
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
Após criar o arquivo cluster.json, execute o seguinte comando para cada projeto. O comando utiliza o arquivo cluster.json para criar um cluster.
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
Para mais opções de configuração e informações sobre este exemplo, veja o comando atlas clusters create.
Observação
Antes de criar recursos com o Terraform, você deve:
Crie sua organização pagadora e uma chave de API para a organização pagadora. Armazene sua chave de API como variáveis de ambiente ao executar o seguinte comando no terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Importante
Os exemplos a seguir usam o provedor Terraform do MongoDB Atlas versão 2.x (~> 2.2). Ao migrar para a versão 1.x do provedor, consulte o Guia de Upgrade 2.0.0 para alterações interruptivas e etapas de migração. Os exemplos usam o recurso mongodbatlas_advanced_cluster com sintaxe v2.x.
Criar os projetos e as implantações
Para seus ambientes de desenvolvimento e teste, crie os seguintes arquivos para cada par de aplicação e ambientes. Coloque os arquivos para cada par de aplicação e ambiente em seu próprio diretório. Altere os IDs e nomes para usar seus valores:
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Observação
Para criar um cluster multirregional, especifique cada região em seu próprio objeto region_configs e aninhe-os no objeto replication_specs. Os campos priority devem ser definidos em ordem decrescente e devem consistir em valores entre 7 e 1, como mostrado no exemplo a seguir:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Após criar os arquivos, acesse o diretório correspondente a cada par de aplicativo e ambiente e execute o seguinte comando para inicializar o Terraform:
terraform init
Execute o seguinte comando para visualizar o Terraform plan:
terraform plan
Execute o seguinte comando para criar um projeto e uma implantação para o par de aplicativo e ambiente. O comando utiliza os arquivos e o MongoDB & HashiCorp Terraform para criar os projetos e clusters:
terraform apply
Quando solicitado, digite yes e pressione Enter para aplicar a configuração.
Para seus ambientes de preparação e produção, crie os seguintes arquivos para cada par de aplicativo e ambiente. Coloque os arquivos de cada par de aplicativo e ambiente em seus respectivos diretórios. Altere os IDs e nomes para usar os seus valores:
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Observação
Para criar um cluster multirregional, especifique cada região em seu próprio objeto region_configs e aninhe-as no objeto replication_specs, como mostrado no exemplo a seguir:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Após criar os arquivos, acesse o diretório correspondente a cada par de aplicativo e ambiente e execute o seguinte comando para inicializar o Terraform:
terraform init
Execute o seguinte comando para visualizar o Terraform plan:
terraform plan
Execute o seguinte comando para criar um projeto e uma implantação para o par de aplicativo e ambiente. O comando utiliza os arquivos e o MongoDB & HashiCorp Terraform para criar os projetos e clusters:
terraform apply
Quando solicitado, digite yes e pressione Enter para aplicar a configuração.
Para mais opções de configuração e informações sobre este exemplo, consulte MongoDB & HashiCorp Terraform e a publicação no blog do MongoDB Terraform.