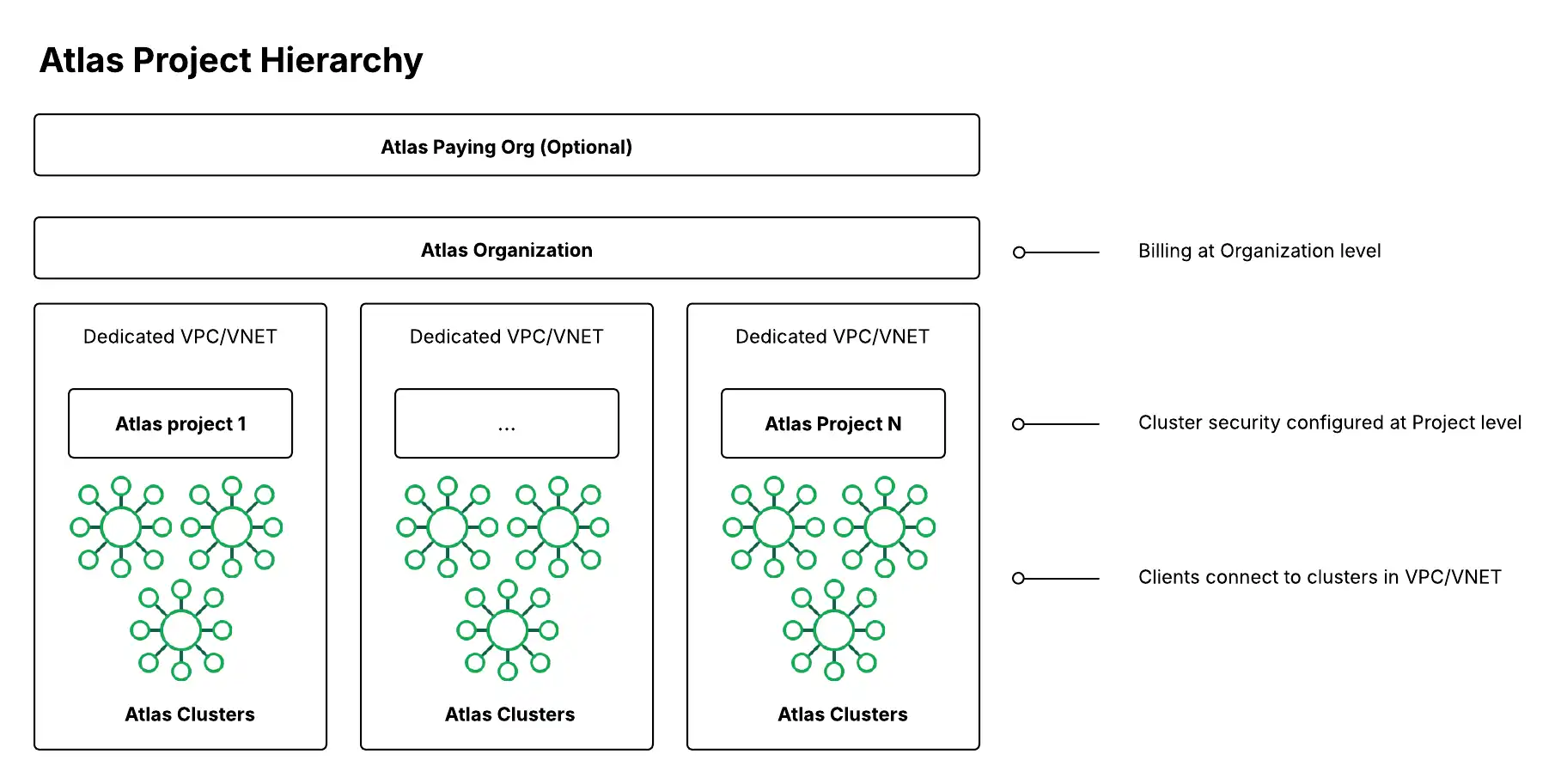
Organizações, projetos e clusters são os componentes fundamentais do seu patrimônio empresarial Atlas:
No nível da organização , você pode implementar controles de segurança e criar usuários que trabalham em um ou mais projetos.
Os projetos oferecem um isolamento de segurança e uma fronteira de autorização mais refinada.
Os clusters são seus bancos de dados na nuvem no Atlas.
Utilize a orientação fundamental desta página para projetar o layout de suas organizações, projetos e clusters com base na hierarquia da sua empresa e no número esperado de clusters e projetos. Esta orientação, além de ajudar você a otimizar sua segurança e seu desempenho desde o início, está alinhada às necessidades de faturamento e acesso da sua empresa.
Recursos para organizações, projetos e clusters do Atlas
Você pode utilizar os seguintes níveis de hierarquia para definir configurações de segurança e administração para sua propriedade do Atlas :
Nível de hierarquia do Atlas | Descrição |
|---|---|
(Opcional) Organização Pagadora | Uma organização pode ser uma organização pagadora para outras organizações. Organizações pagadoras permitem configurar o faturamento entre organizações para compartilhar uma assinatura de faturamento entre múltiplas organizações. Para aprender mais sobre como configurar sua organização pagadora ao fazer a assinatura do Atlas, consulte Gerenciar faturamento. Para habilitar o faturamento entre organizações, o usuário que realiza a ação deve possuir a função de Proprietário da organização ou Administrador de Faturamento em ambas as organizações que deseja vincular. Para saber mais, consulte Funções de usuário. Uma organização pagadora é comum para grandes empresas com muitos BUou departamentos que operam de forma independente, mas cujo contrato ou fatura é de propriedade de uma autoridade central. |
Uma organização pode conter diversos projetos e fornece um contêiner para aplicar configurações compartilhadas de integração e segurança entre esses projetos e os clusters neles contidos.Se você gerencia várias organizações do Atlas, o Federation Management Console do Atlas permite que usuários com a função de Proprietário da organização gerenciem IdPs para SSO e, em seguida, os vinculem a várias organizações. Uma organização frequentemente se correlaciona a uma UN ou departamento dentro de uma empresa. O Atlas Cost Explorer integrado agrega os gastos com a nuvem da organização e detalha os itens de linha do projeto e do cluster abaixo dele. Você pode personalizar ainda mais utilizando a API de faturamento. | |
A configuração de segurança para o plano de dados (incluindo clusters de banco de dados, segurança de rede e outros serviços de dados) é realizada no nível do projeto. Um projeto frequentemente se correlaciona a um aplicativo e um ambiente (por exemplo: aplicativo Portal do Cliente - ambiente de Produção). Para cada projeto, com base no provedor de nuvem selecionado, existe uma VPC ou VNet dedicada por região na AWS e no Azure. | |

Recomendações para organizações, projetos e clusters do Atlas
Recomendações de implantação multirregional e multinuvem
Para implantações multirregionais e multinuvem, considere as seguintes recomendações adicionais para otimizar o desempenho, a segurança e o compliance além das fronteiras geográficas:
Arquitetura de Rede e Latência
Implante clusters nas regiões mais próximas dos usuários do seu aplicativo para minimizar a latência.
Use VPCs/VNets dedicadas por região em cada projeto para manter o isolamento da rede.
Configure pontos de extremidade privados em cada região em que você implantar clusters para garantir conexões seguras e de baixa latência.
Localidade e conformidade dos dados
Crie projetos separados para diferentes jurisdições regulatórias (por exemplo, projeto compatível com o GDPR da UE, projeto compatível com o SOX dos EUA) para garantir que os requisitos de residência de dados sejam atendidos.
Use Clusters Globais com fragmentação por zona para rotear automaticamente leituras e gravar para a região geográfica apropriada com base nos valores da chave de fragmento.
Marque projetos e clusters com classificação de dados e requisitos de compliance regional para fins de auditoria e governança.
Recuperação de desastres entre regiões
Implante clusters com réplicas de leitura em várias regiões para habilitar funcionalidades de failover.
Mantenha agendamentos de backup consistentes em todas as regiões dentro do mesmo ambiente de aplicativo.
Teste regularmente os procedimentos de recuperação de desastres em todas as regiões para assegurar a continuidade dos negócios.
Considerações sobre implantações multinuvem
Adote convenções de nomenclatura consistentes entre os provedores de nuvem para facilitar o gerenciamento e o monitoramento.
Padronize as configurações de segurança em todos os ambientes de nuvem no mesmo projeto.
Considere as características e limitações específicas dos provedores de nuvem ao planejar a replicação de dados entre nuvens e a conectividade de rede.
Todas as Recomendações de Paradigmas de Implantação
As seguintes recomendações se aplicam a todos os paradigmas de implantação.
Ambientes de desenvolvimento, teste, preparação e produção
Recomendamos que você use os quatro ambientes a seguir para isolar sua sandbox e testar projetos e clusters dos seus projetos e clusters de aplicativos:
ambiente | Descrição |
|---|---|
Desenvolvimento (Dev) | Permita que os desenvolvedores testem livremente novas ideias em um ambiente seguro de sandbox. |
Teste (Teste) | Teste componentes ou funções específicas criadas no ambiente de desenvolvimento. |
Encenação | Prepare todos os componentes e funções juntos para garantir que todo o aplicação funcione conforme o esperado antes de ser implementado na produção. A preparação é semelhante ao ambiente de teste, mas garante que os novos componentes funcionem bem com os componentes existentes. |
Produção (Prod) | O back-end do seu aplicativo que está em operação para os seus usuários finais. |
Sistemas locais do Atlas
Para fins de desenvolvimento e teste, os desenvolvedores podem usar a Atlas CLI para criar uma implantação local do Atlas. Ao trabalhar localmente em suas máquinas, os desenvolvedores podem reduzir os custos com ambientes externos de desenvolvimento e teste.
Os programadores também podem executar comandos do Atlas CLI com o Docker para construir, executar e gerenciar sistemas locais do Atlas utilizando containers. Os contêineres são unidades padronizadas que contêm todo o software necessário para executar um aplicação. A containerização permite que os desenvolvedores criem implantações locais do Atlas em ambientes de teste seguros, confiáveis e portáteis. Para saber mais, consulte Criar uma implantação de Atlas local com Docker.
Hierarquias da organização e do projeto
Geralmente, recomendamos uma organização pagadora gerida centralmente e uma organização para cada UN ou departamento vinculado à organização pagadora. Em seguida, crie um projeto com um cluster para seu ambientes inferior (desenvolvimento ou teste) e para seu ambiente superior; você pode criar clusters nesses projetos. Para saber mais, veja as informações a seguir para Hierarquia recomendada.
Se você atingir facilmente o limite de projeto 250 por organização, recomendamos a criação de uma organização por ambiente, como uma para ambientes inferiores e superiores, ou uma para desenvolvimento, teste, preparação e produção. Essa configuração tem o benefício de isolamento adicional. Você também pode aumentar os limites. Para saber mais, consulte Limites de Serviço do Atlas.
As configurações de rede e segurança, como IPs permitidos e chaves de API, são compartilhadas no nível do projeto. Portanto, se você precisar de controles de acesso detalhados para equipes que trabalham em diferentes aplicativos, recomendamos que crie projetos separados para cada aplicativo.
Hierarquia recomendada
Considere a seguinte hierarquia, que cria menos organizações Atlas, se você tiver equipes e permissões comuns em todo o BU e menor que o limite de aumento de 250 projetos por organização.

Hierarquia recomendada 2: unidades de negócios descentralizadas/departamentos
Considere a seguinte hierarquia se sua organização for altamente descentralizada e não houver uma função centralizada para servir como responsável pelo contrato e pela cobrança. Nesta hierarquia, cada UN, departamento ou equipe tem sua própria organização do Atlas. Esta hierarquia é útil se cada uma de suas equipes for bastante independente, não compartilhar pessoas ou permissões dentro da empresa ou quiser comprar créditos por meio do marketplace do provedor de nuvem ou diretamente com o próprio contrato. Não há organização pagante nesta hierarquia.

Cluster Hierarchy
Para manter o isolamento entre ambientes, recomendamos que você implante cada cluster dentro de seu próprio projeto, como ilustrado no diagrama a seguir. Isso permite que os administradores mantenham diferentes configurações de projeto entre ambientes e respeitem o princípio do privilégio mínimo, que estabelece que os usuários devem receber apenas o nível mínimo de acesso necessário para suas funções.
Sobretudo em ambientes de produção, recomendamos que você crie projetos separados para cada par de aplicativo e ambiente. Como essas configurações são gerenciadas no nível do projeto, essa abordagem reduz a potencial necessidade de transferir dados manualmente entre clusters de ambiente de produção caso esses requisitos mudem para um determinado aplicativo.
Você pode compartilhar configurações gerais do projeto, como pontos de extremidade privados e CMKs, entre clusters usando ferramentas de automação, como o Terraform, durante a criação do cluster. Além disso, automatizar a criação de clusters pode resultar em economia de custos ao padronizar a criação de ambientes paralelos superiores para produção e inferiores para desenvolvimento, respectivamente.
Para aprender mais, consulte Quando considerar vários clusters por projeto.

Quando considerar vários clusters por projeto
O diagrama seguinte mostra uma organização cujos projetos cada um contém múltiplos Atlas clusters, agrupados por ambiente. A implantação de vários clusters no mesmo projeto simplifica a administração quando um aplicação usa vários clusters de apoio ou a mesma equipe é responsável por vários aplicativos em ambientes. Isso reduz o custo de configuração de recursos como endpoints privados e chaves gerenciadas pelo cliente, pois todos os clusters no mesmo projeto compartilham a mesma configuração de projeto .
No entanto, essa hierarquia de cluster pode violar o princípio do privilégio mínimo.
Implante vários clusters no mesmo projeto somente se ambos os itens a seguir forem verdadeiros:
Cada membro da equipe com acesso ao projeto está trabalhando em todos os outros aplicativos e clusters no projeto.
Você está criando clusters para ambientes de desenvolvimento e teste. Em ambientes de preparo e produção, recomendamos que os clusters no mesmo projeto pertençam ao mesmo aplicação e sejam administrativos pela mesma equipe.

Marcação de recursos
Recomendamos que você marque clusters ou projetos com as seguintes informações para facilitar a análise de relatórios e integrações:
BU ou departamento
teamName
Nome do aplicativo
ambiente
Versão
Contato por e-mail
Criticidade (indica o nível de dados armazenados no cluster, incluindo quaisquer classificações sensíveis, como PII ou PHI)
Para aprender mais sobre a análise de dados de faturamento usando tags, consulte Recursos para dados de faturamento do Atlas.
Guia de Tamanho do Atlas Cluster
Em uma implantação dedicada (cluster maior que M10), o Atlas aloca recursos de forma exclusiva. Recomendamos implantações dedicadas para casos de uso em produção, pois oferecem maior segurança e desempenho em comparação com clusters compartilhados.
O guia de tamanho de cluster a seguir usa o "dimensionamento de t-camiseta", uma comparação comum usada no desenvolvimento de software e na infraestrutura para descrever o planejamento de capacidade de maneira simplificada. Use as recomendações de tamanho de roupas de times apenas como pontos de partida aproximados em sua análise de dimensionamento. O dimensionamento de um cluster é um processo iterativo baseado na alteração das necessidades de recursos, nos requisitos de desempenho, nas características do volume de trabalho e nas expectativas de crescimento.
Importante
Essa orientação exclui aplicativos de função crítica, volumes de trabalho de alta memória e volumes de trabalho de alta CPU. Para esses casos de uso, entre em contato com o suporte do MongoDB para obter orientação personalizada.
Você pode estimar os recursos de cluster que seu sistema exige usando o tamanho aproximado dos dados e o volume de trabalho da organização:
Armazenamento Total Necessário: 50% do tamanho total dos dados brutos
Total de RAM Necessária: 10% do tamanho total dos dados brutos
Total de núcleos de CPU necessários: operações de banco de dados de leitura/escrita de pico esperadas por segundo sta 4000
Total de IOPS de armazenamento necessário: operações de banco de dados de leitura/escrita de pico esperadas por segundo (IOPS mínima = 5%, IOPS máxima = 95%)
Use o guia de tamanho de cluster a seguir para selecionar uma camada do cluster que garanta o desempenho sem provisionamento excessivo. Esta tabela exibe os recursos padrão de armazenamento e desempenho para cada camada do cluster, bem como se a camada do cluster é adequada ou não para ambientes de preparação e produção.
O guia de tamanho do cluster também inclui valores esperados para o tamanho total de dados de um cluster e IOPS padrão, que podem ser aumentados com configurações adicionais. Observe que as recomendações de armazenamento a seguir são por fragmento, não para todo o cluster. Para aprender mais, consulte Orientações para escalabilidade do Atlas.
Tamanho da coleção | Camada do cluster | Faixa de armazenamento: AWS, Google Cloud e Azure | CPUs (#) | RAM padrão | IOPS padrão | Tamanho médio esperado dos dados | Leituras/gravações de pico esperadas | Ideal para |
|---|---|---|---|---|---|---|---|---|
Pequena |
| 2 GB a 128 GB | 2 | 2 GB | 1000 | 1 GB a 10 GB | 200 | Somente para desenvolvimento/teste |
Med |
| 8 GB a 512 GB | 2 | 8 GB | 3000 | 20 GB a 50 GB | 3000 | Prod |
grande |
| 8 GB a 4 TB | 16 | 32 GB | 3000 | 360 GB a 420 GB | 11000 | Prod |
X-Large |
| 8 GB a 4 TB | 32 | 128 GB | 3000 | 1200 GB a 1750 GB | 39000 | Prod |
| [1] | M10 é uma camada de CPU compartilhada. Para setores altamente regulamentados ou dados confidenciais, seu nível inicial mínimo e menor deve ser M30. |
Por exemplo, considere uma fintech fictícia, a MongoFinance, que precisa armazenar um total de 400 GB de dados processados. Durante o pico de atividade, os funcionários e clientes da MongoFinance realizam até 3000 operações de leitura ou gravação nos bancos de dados da MongoFinance por segundo. Os requisitos de armazenamento e desempenho da MongoFinance são melhor atendidos por uma camada do cluster grande, ou M50.
Para aprender mais sobre as camadas de cluster e as regiões com suporte, consulte a documentação do Atlas para cada provedor de nuvem:
Exemplos de Automação: Organizações, Projetos e Clusters do Atlas
Dica
Para exemplos de Terraform que impõem nossas recomendações em todos os colunas, consulte um dos seguintes exemplos no Github:
Os exemplos seguintes criam organizações, projetos e clusters utilizando ferramentas Atlas para automação.
Esses exemplos também incluem outras configurações recomendadas, tais como:
Camada do cluster definida como
M10para um ambiente de desenvolvimento/teste. Use o guia de tamanho de cluster para saber mais sobre a camada do cluster recomendada para o tamanho do seu aplicação.Região única, 3-Conjunto de réplicas de nós/Topologia de implantação de fragmento.
Nossos exemplos utilizam AWS, Azure e Google Cloud de maneira intercambiável. Você pode usar qualquer um desses três provedores de nuvem, mas deve alterar o nome da região para corresponder à do provedor de nuvem. Para aprender mais sobre os provedores de nuvem e as respectivas regiões, consulte Provedores de nuvem.
Camada do cluster definida como
M30para um aplicativo de porte médio. Use o guia de tamanho do cluster para saber qual a camada do cluster recomendada para o tamanho do seu aplicativo.Região única, 3-Conjunto de réplicas de nós/Topologia de implantação de fragmento.
Nossos exemplos utilizam AWS, Azure e Google Cloud de maneira intercambiável. Você pode usar qualquer um desses três provedores de nuvem, mas deve alterar o nome da região para corresponder à do provedor de nuvem. Para aprender mais sobre os provedores de nuvem e as respectivas regiões, consulte Provedores de nuvem.
Observação
Antes de criar recursos com o Atlas CLI, você deve:
Crie sua organização pagadora e crie uma chave de API para a organização pagadora.
Conecte-se pelo Atlas CLI seguindo as instruções para Programmatic Use.
Criar as organizações
Execute o seguinte comando para cada BU. Altere os IDs e nomes para usar seus valores reais:
atlas organizations create ConsumerProducts --ownerId 508bb8f5f11b8e3488a0e99e --apiKeyRole ORG_OWNER --apiKeyDescription consumer-products-key
Para mais opções de configuração e informações sobre este exemplo, consulte Criar organizações no Atlas.
Você pode criar uma organização e vinculá-la à sua organização pagadora, programaticamente, usando a Atlas Administration API. Para isso, envie uma solicitação POST para o ponto de extremidade https://cloud.mongodb.com/api/atlas/v2/orgs e especifique o ID da organização pagadora no campo federationSettingsId. A conta de serviço ou a chave de API solicitante deve ter a função "Proprietário da organização", e a organização solicitante deve ser uma organização pagante.
O exemplo a seguir usa cURL para enviar a solicitação:
curl --location '/api/atlas/v2/orgs?envelope=false&pretty=false' \ --header 'Content-Type: application/vnd.atlas.2023-01-01+json' \ --header 'Accept: application/vnd.atlas.2023-01-01+json' \ --data '{ "name": "<organization name>", "apiKey": { "desc": "<organization description>", "roles": [ "ORG_MEMBER" ] }, "federationSettingsId": "<ID of org to link to>", "orgOwnerId": "<organization owners ID>", "skipDefaultAlertsSettings": false }'
Para aprender mais sobre a chamada de API precedente, consulte a documentação da API atlas organizations create.
Para obter os IDs de usuário e os IDs da organização, consulte os seguintes comandos:
Criar os projetos
Execute o comando a seguir para cada par de aplicação e ambientes. Altere os IDs e nomes para usar seus valores:
atlas projects create "Customer Portal - Prod" --tag environment=production --orgId 32b6e34b3d91647abb20e7b8
Para mais opções de configuração e informações sobre este exemplo, consulte criar projetos do atlas.
Para obter os IDs do projeto, consulte o seguinte comando:
Configurar criptografia com o gerenciamento de chaves do cliente
Para ambientes de staging e produção, recomendamos que habilite a criptografia com gerenciamento de chaves do cliente ao provisionar seus clusters. Para desenvolvimento e teste, considere omitir a criptografia com gerenciamento de chaves do cliente para reduzir custos, a menos que você esteja em um setor altamente regulamentado ou armazene dados sensíveis. Para aprender mais, consulte Recomendações para organizações, projetos e clusters do Atlas.
Você não pode usar a Atlas CLI para gerenciar a criptografia com o gerenciamento de chaves do cliente . Em vez disso, use os seguintes métodos:
Criar um cluster por projeto
Para criar um cluster de região única para seus ambientes de desenvolvimento e teste, execute o seguinte comando para cada projeto criado. Altere os IDs e nomes para usar seus valores:
Observação
Você também pode usar a API de Administração de Clusters do Atlas para criar um cluster.
Esse exemplo não permite o dimensionamento automático para controlar os custos em ambientes de desenvolvimento e teste. Para ambientes de teste e produção, deve ser ativado o dimensionamento automático.
atlas clusters create CustomerPortalDev \ --projectId 56fd11f25f23b33ef4c2a331 \ --region EASTERN_US \ --members 3 \ --tier M10 \ --provider GCP \ --mdbVersion 8.0 \ --diskSizeGB 30 \ --tag bu=ConsumerProducts \ --tag teamName=TeamA \ --tag appName=ProductManagementApp \ --tag env=Production \ --tag version=8.0 \ --tag email=marissa@example.com \ --watch
Para configurar um cluster multirregional, crie o seguinte arquivo cluster.json para cada projeto criado. Altere os IDs e nomes para usar os seus valores.
{ "name": "CustomerPortalDev", "projectId": "56fd11f25f23b33ef4c2a331", "clusterType": "REPLICASET", "diskSizeGB": 30, "mongoDBMajorVersion": "8.0", "backupEnabled": true, "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "providerName": "GCP", "regionName": "EASTERN_US", "members": 3, "priority": 7, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } }, { "providerName": "GCP", "regionName": "CENTRAL_US", "members": 2, "priority": 5, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } }, { "providerName": "GCP", "regionName": "WESTERN_US", "members": 2, "priority": 4, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } } } ] } ], "tags": [ { "key": "bu", "value": "ConsumerProducts" }, { "key": "teamName", "value": "TeamA" }, { "key": "appName", "value": "ProductManagementApp" }, { "key": "env", "value": "Production" }, { "key": "version", "value": "8.0" }, { "key": "email", "value": "marissa@example.com" } ] }
Depois de criar o arquivo de configuração anterior, execute o seguinte comando para criar o cluster:
atlas clusters create --file <path to your configuration file>
Para criar um cluster de região única para seus ambientes de preparação e produção, crie o seguinte arquivo cluster.json para cada projeto criado. Altere os IDs e nomes para usar seus valores:
{ "clusterType": "REPLICASET", "links": [], "name": "CustomerPortalProd", "mongoDBMajorVersion": "8.0", "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], "tag" : [{ "bu": "ConsumerProducts", "teamName": "TeamA", "appName": "ProductManagementApp", "env": "Production", "version": "8.0", "email": "marissa@example.com" }] }
Após criar o arquivo cluster.json, execute o seguinte comando para cada projeto criado. O comando utiliza o arquivo cluster.json para criar um cluster.
atlas cluster create --projectId 5e2211c17a3e5a48f5497de3 --file cluster.json
Para configurar um cluster multirregional, modifique o array replicationSpecs no arquivo cluster.json anterior para especificar várias regiões, conforme mostrado no exemplo a seguir:
{ … "replicationSpecs": [ { "numShards": 1, "regionConfigs": [ { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 7, "providerName": "GCP", "regionName": "EASTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } }, { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 5, "providerName": "GCP", "regionName": "CENTRAL_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } }, { "electableSpecs": { "instanceSize": "M30", "nodeCount": 3 }, "priority": 6, "providerName": "GCP", "regionName": "WESTERN_US", "analyticsSpecs": { "nodeCount": 0, "instanceSize": "M30" }, "autoScaling": { "compute": { "enabled": true, "scaleDownEnabled": true }, "diskGB": { "enabled": true } }, "readOnlySpecs": { "nodeCount": 0, "instanceSize": "M30" } } ], "zoneName": "Zone 1" } ], … }
Depois de criar o arquivo de configuração anterior, execute o seguinte comando para criar o cluster:
atlas clusters create --file <path to your configuration file>
Para mais opções de configuração e informações sobre estes exemplos, consulte Criar clusters do Atlas.
Observação
Antes de criar recursos com o Terraform, você deve:
Crie sua organização pagadora e uma chave de API para a organização pagadora. Armazene sua chave de API como variáveis de ambiente ao executar o seguinte comando no terminal:
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
Importante
Os exemplos a seguir usam o provedor Terraform do MongoDB Atlas versão 2.x (~> 2.2). Ao migrar para a versão 1.x do provedor, consulte o Guia de Upgrade 2.0.0 para alterações interruptivas e etapas de migração. Os exemplos usam o recurso mongodbatlas_advanced_cluster com sintaxe v2.x.
Criar os projetos e as implantações
Para seus ambientes de desenvolvimento e teste, crie os seguintes arquivos para cada par de aplicação e ambientes. Coloque os arquivos para cada par de aplicação e ambiente em seu próprio diretório. Altere os IDs e nomes para usar seus valores:
main.tf
# Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalDev" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version # MongoDB recommends enabling auto-scaling # When auto-scaling is enabled, Atlas may change the instance size, and this use_effective_fields # block prevents Terraform from reverting Atlas auto-scaling changes use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Test" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.0.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Observação
Para criar um cluster multirregional, especifique cada região em seu próprio objeto region_configs e aninhe-os no objeto replication_specs. Os campos priority devem ser definidos em ordem decrescente e devem consistir em valores entre 7 e 1, como mostrado no exemplo a seguir:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } auto_scaling = { compute_enabled = true compute_scale_down_enabled = true compute_max_instance_size = "M60" compute_min_instance_size = "M10" } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Dev" environment = "dev" cluster_instance_size_name = "M10" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Para seus ambientes de preparação e produção, crie os seguintes arquivos para cada par de aplicativo e ambiente. Coloque os arquivos de cada par de aplicativo e ambiente em seus respectivos diretórios. Altere os IDs e nomes para usar os seus valores:
main.tf
# Create a Group to Assign to Project resource "mongodbatlas_team" "project_group" { org_id = var.atlas_org_id name = var.atlas_group_name usernames = [ "user1@example.com", "user2@example.com" ] } # Create a Project resource "mongodbatlas_project" "atlas-project" { org_id = var.atlas_org_id name = var.atlas_project_name } # Assign the team to project with specific roles resource "mongodbatlas_team_project_assignment" "project_team" { project_id = mongodbatlas_project.atlas-project.id team_id = mongodbatlas_team.project_group.team_id role_names = ["GROUP_READ_ONLY", "GROUP_CLUSTER_MANAGER"] } # Create an Atlas Advanced Cluster resource "mongodbatlas_advanced_cluster" "atlas-cluster" { project_id = mongodbatlas_project.atlas-project.id name = "ClusterPortalProd" cluster_type = "REPLICASET" mongo_db_major_version = var.mongodb_version use_effective_fields = true replication_specs = [ { region_configs = [ { electable_specs = { instance_size = var.cluster_instance_size_name node_count = 3 disk_size_gb = var.disk_size_gb } auto_scaling = { disk_gb_enabled = var.auto_scaling_disk_gb_enabled compute_enabled = var.auto_scaling_compute_enabled compute_max_instance_size = var.compute_max_instance_size } priority = 7 provider_name = var.cloud_provider region_name = var.atlas_region } ] } ] tags = { BU = "ConsumerProducts" TeamName = "TeamA" AppName = "ProductManagementApp" Env = "Production" Version = "8.0" Email = "marissa@example.com" } } # Outputs to Display output "atlas_cluster_connection_string" { value = mongodbatlas_advanced_cluster.atlas-cluster.connection_strings.standard_srv } output "project_name" { value = mongodbatlas_project.atlas-project.name }
Observação
Para criar um cluster multirregional, especifique cada região em seu próprio objeto region_configs e aninhe-as no objeto replication_specs, como mostrado no exemplo a seguir:
replication_specs = [ { region_configs = [ { electable_specs = { instance_size = "M10" node_count = 2 } provider_name = "GCP" priority = 7 region_name = "NORTH_AMERICA_NORTHEAST_1" }, { electable_specs = { instance_size = "M10" node_count = 3 } provider_name = "GCP" priority = 6 region_name = "WESTERN_US" } ] } ]
variables.tf
# MongoDB Atlas Provider Authentication Variables # Legacy API key authentication (backward compatibility) variable "mongodbatlas_public_key" { type = string description = "MongoDB Atlas API public key" sensitive = true } variable "mongodbatlas_private_key" { type = string description = "MongoDB Atlas API private key" sensitive = true } # Recommended: Service account authentication variable "mongodb_service_account_id" { type = string description = "MongoDB service account ID for authentication" sensitive = true default = null } variable "mongodb_service_account_key_file" { type = string description = "Path to MongoDB service account private key file" sensitive = true default = null } # Atlas Organization ID variable "atlas_org_id" { type = string description = "Atlas Organization ID" } # Atlas Project Name variable "atlas_project_name" { type = string description = "Atlas Project Name" } # Atlas Project Environment variable "environment" { type = string description = "The environment to be built" } # Cluster Instance Size Name variable "cluster_instance_size_name" { type = string description = "Cluster instance size name" } # Cloud Provider to Host Atlas Cluster variable "cloud_provider" { type = string description = "AWS or GCP or Azure" } # Atlas Region variable "atlas_region" { type = string description = "Atlas region where resources will be created" } # MongoDB Version variable "mongodb_version" { type = string description = "MongoDB Version" } # Atlas Group Name variable "atlas_group_name" { type = string description = "Atlas Group Name" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" environment = "prod" cluster_instance_size_name = "M30" cloud_provider = "AWS" atlas_region = "US_WEST_2" mongodb_version = "8.0" atlas_group_name = "Atlas Group"
provider.tf
# Define the MongoDB Atlas Provider terraform { required_providers { mongodbatlas = { source = "mongodb/mongodbatlas" version = "~> 2.2" } } required_version = ">= 1.0" } # Configure the MongoDB Atlas Provider provider "mongodbatlas" { # Legacy API key authentication (backward compatibility) public_key = var.mongodbatlas_public_key private_key = var.mongodbatlas_private_key # Recommended: Service account authentication # Uncomment and configure the following for service account auth: # service_account_id = var.mongodb_service_account_id # private_key_file = var.mongodb_service_account_key_file }
Para mais opções de configuração e informações sobre este exemplo, consulte MongoDB & HashiCorp Terraform e a publicação no blog do MongoDB Terraform.
Após criar os arquivos, acesse o diretório correspondente a cada par de aplicativo e ambiente e execute o seguinte comando para inicializar o Terraform:
terraform init
Execute o seguinte comando para visualizar o Terraform plan:
terraform plan
Execute o seguinte comando para criar um projeto e uma implantação para o par de aplicativo e ambiente. O comando utiliza os arquivos e o MongoDB & HashiCorp Terraform para criar os projetos e clusters:
terraform apply
Quando solicitado, digite yes e pressione Enter para aplicar a configuração.
Próximos passos
Depois de planejar a hierarquia e o tamanho de suas organizações, projetos e clusters, consulte os recursos sugeridos a seguir ou use a navegação à esquerda para encontrar funcionalidades e melhores práticas para cada pilar do Well-Architected Framework.