É fundamental que as empresas planejem a recuperação de desastres. É altamente recomendável que você prepare um plano abrangente de recuperação de desastres (DR) que inclua elementos como:
Seu objetivo de ponto de recuperação (RPO) designado
Seu objetivo de tempo de recuperação (RTO) designado
Processos automatizados que facilitam o alinhamento com esses objetivos
Utilize as recomendações desta página para se preparar e responder a desastres.
Para aprender mais sobre configurações proativas de alta disponibilidade que podem ajudar na recuperação de desastres, consulte Recomendações para Alta Disponibilidade do Atlas.
Recursos para Recuperação de desastres do Atlas
Para aprender sobre os recursos do Atlas que oferecem suporte à recuperação de desastres, consulte as seguintes páginas no Centro de Arquitetura Atlas:
Recomendações para Recuperação de desastres do Atlas
Use as seguintes recomendações de recuperação de desastres para criar um plano de recuperação de desastres para sua organização. Estas recomendações fornecem informações sobre as medidas a serem tomadas no evento de um desastre.
É fundamental que você teste os planos nesta seção regularmente (idealmente trimestralmente, mas pelo menos semestralmente). Os testes geralmente ajudam a preparar a equipe de gerenciamento de banco de dados empresarial (EDM) para responder a desastres e, ao mesmo tempo, ajudar a manter as instruções atualizadas.
Alguns testes de recuperação de desastres podem exigir ações que não podem ser executadas por usuários do EDM. Nesses casos, abra um caso de suporte com o objetivo de realizar interrupções sintéticas pelo menos uma semana antes de quando você planeja executar um exercício de teste.
O diagrama a seguir compara diferentes cenários de recuperação de desastres e configurações de implantação. A tabela mostra os benefícios relativos do objetivo de tempo de recuperação (RTO) e do objetivo de ponto de recuperação (RPO) em relação à complexidade de implantação e ao custo para cada configuração. Observe que as eleições de conjuntos de réplicas (failover automático) não resultam em perda de dados, enquanto a recuperação de backups pode envolver alguma perda de dados, dependendo da frequência do backup. "Falha do plano de controle" refere-se a problemas com a infraestrutura de gerenciamento do Atlas em vez de com seus nós de dados.

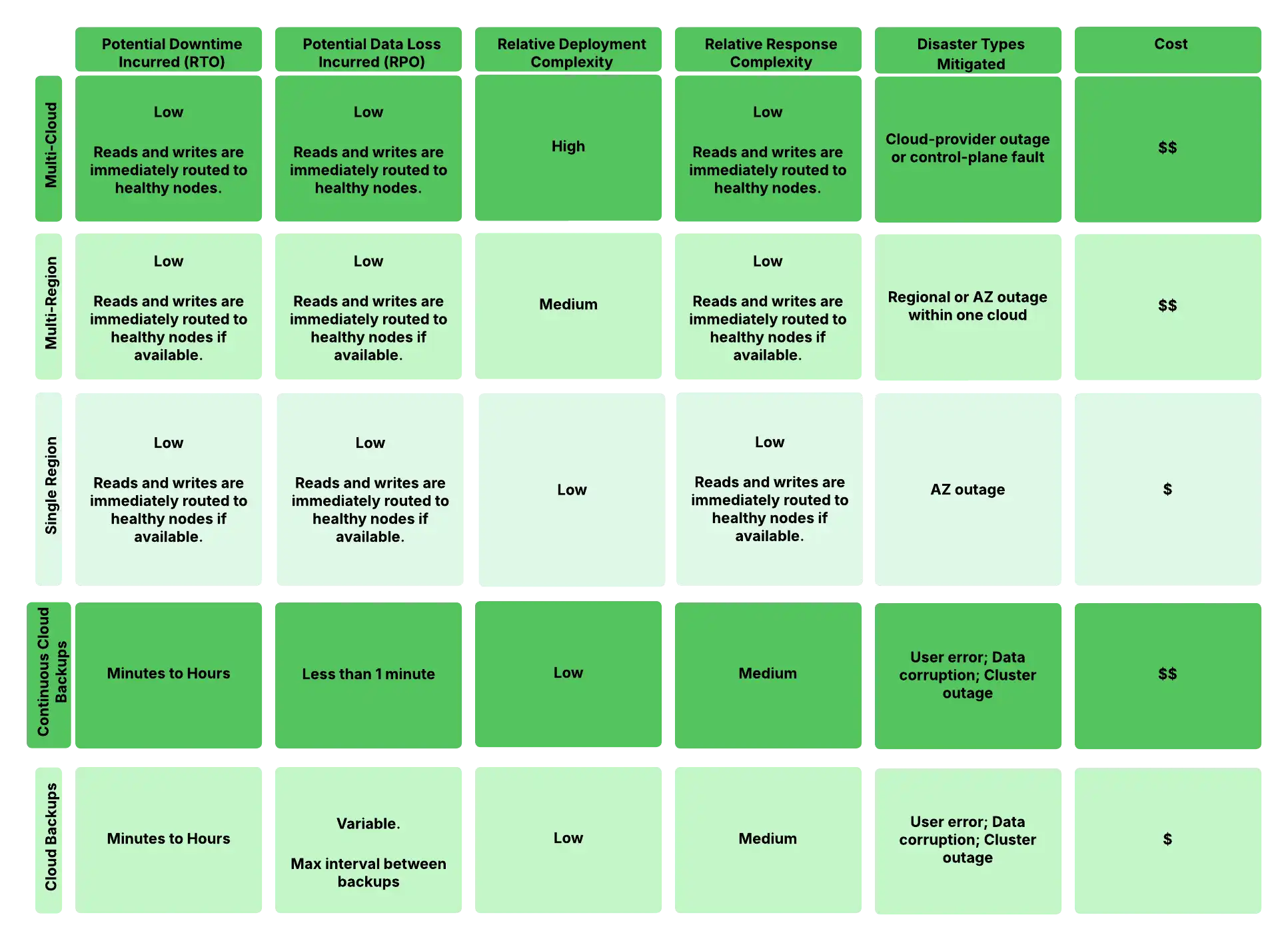
figura 1. complexidade da configuração de recuperação de desastres e compensações RTO/RPO.
Cada provedor de nuvem no qual você pode implantar clusters do Atlas oferece redundância de dados padrão que ajuda a mitigar interrupções:
O AWS armazena objetos em vários dispositivos em um mínimo de três zonas de disponibilidade em uma região do AWS.
O Microsoft Azure usa o armazenamento redundante localmente (LRS) que replica seus dados três vezes em um único data center na região selecionada.
O Google Cloud dispersa seus dados em várias zonas na região de backup.
Para aprimorar sua recuperação de desastre, você pode configurar o Atlas para criar automaticamente cópias de seus snapshots e oplogs em outras regiões. Isso garante que, mesmo que a região primária enfrente uma interrupção, você possa restaurar seu cluster usando cópias de snapshot armazenadas em outras regiões.
O Atlas otimiza as velocidades de restauração selecionando a opção mais eficiente com base na disponibilidade da região, usando snapshots copiados se estiver restaurando em uma região onde essas cópias existem. Além disso, se o snapshot original estiver inacessível devido a uma interrupção regional, o Atlas restaurará usando a cópia de snapshot disponível mais próxima, minimizando o tempo de inatividade e melhorando a resiliência da recuperação. Para saber mais, consulte Exportar Snapshot de Backups em Nuvem.
As implantações multirregionais e multinuvem fornecem funcionalidades aprimoradas de recuperação de desastre, distribuindo nós de cluster em diferentes localizações geográficas ou provedores de nuvem. Essa distribuição ajuda a garantir que, se uma região ou provedor de nuvem sofrer uma interrupção, seu aplicativo possa continuar operando usando nós em localizações não afetadas.
Ao configurar implantações multirregionais ou multinuvem, certifique-se de que sua estratégia de backup considere a natureza distribuída de sua implantação, incluindo a definição de períodos de retenção de backup apropriados com base em seus requisitos específicos de recuperação.
Todas as Recomendações de Paradigmas de Implantação
As seguintes recomendações se aplicam a todos os paradigmas de implantação.
Esta seção aborda os seguintes procedimentos de recuperação de desastres:
Interrupção de nó único
Se um único nó no seu conjunto de réplicas falhar devido a uma interrupção regional, sua implantação ainda deverá estar disponível, desde que você tenha seguido as melhores práticas. Se estiver lendo de secundários, poderá experimentar um desempenho degradado ou possíveis interrupções caso um nó secundário falhe, devido ao aumento da carga no cluster que então estará subprovisionado.
Você pode testar uma interrupção de nó primary no Atlas usando a funcionalidade Testar Failover Primário da UI do Atlas ou o endpoint da API de Administração do Atlas de Failover de Teste.
Interrupção regional
Os clusters multirregionais, em caso de uma interrupção regional, realizarão automaticamente uma eleição e identificarão um novo nó primário, se necessário. Essa mudança de topologia será comunicada automaticamente ao aplicativo, permitindo que ele tome as ações corretivas necessárias. Para garantir o tempo de atividade do aplicativo em caso de uma interrupção regional, seu aplicativo deve ser implantado com uma topologia multirregional. Este requisito se estende para incluir qualquer serviço de terceiros com o qual seu aplicativo possa estar integrado. Para aprender mais, consulte Paradigma de Implantação Multirregional.
Se uma única interrupção de região ou interrupção de multirregional degradar o estado do seu cluster, siga estas etapas:
Determine quais regiões provavelmente não serão afetadas pela interrupção atual
Dependendo da causa da interrupção, pode haver outras regiões em um futuro próximo que também sofrerão interrupções não programadas. Por exemplo, se as interrupções foram causadas por um desastre natural na costa leste dos Estados Unidos, você deverá evitar regiões na costa leste dos Estados Unidos caso haja problemas adicionais.
Adicione nós às regiões identificadas
Adicione o número necessário de nós para um estado normal em regiões que provavelmente não serão afetadas pela causa da interrupção.
Para reconfigurar um conjunto de réplicas durante uma interrupção adicionando regiões ou nós, consulte Reconfiguração de um conjunto de réplicas durante uma interrupção regional.
Você pode testar uma interrupção de região no Atlas usando o recurso Simular Interrupção da UI do Atlas ou o ponto de extremidade da API de Administração do Atlas de Simulação de Interrupção.
Interrupção do provedor de nuvem
Com clusters multinuvem, é possível selecionar nós elegíveis entre provedores de nuvem para manter a alta disponibilidade. Caso o provedor no qual seu nó primário está implantado fique indisponível, o Atlas elege automaticamente novos nós primários para garantir a operação contínua. Por exemplo, é possível criar nós elegíveis na AWS, Google Cloud e Microsoft Azure para garantir que, se um provedor de nuvem sofrer uma interrupção, um nó elegível em um provedor separado possa assumir automaticamente como nó primário do cluster. Para saber mais, veja Paradigma de Implantação multinuvem.
A maioria dos clusters multirregionais do Atlas se recuperará automaticamente de uma interrupção em uma única região. Para aprender mais, consulte a seção alta disponibilidade e a página Implantação multirregional. No caso de interrupções regionais terem derrubado a maioria dos nós, você deve determinar quantos nós adicionais precisa adicionar para que a maioria dos nós esteja íntegra.
No caso altamente improvável de um provedor de nuvem inteiro ficar indisponível, siga estas instruções para restaurar sua implantação online:
Identifique o provedor de nuvem alternativo no qual você gostaria de implantar seu novo cluster
Para obter uma lista de fornecedores de nuvem e informações, consulte Fornecedores de nuvem.
Se armazenar backups em vários provedores de nuvem, a interrupção de um provedor de nuvem implica que os backups armazenados no provedor de nuvem primário estarão necessariamente indisponíveis. Encontre o snapshot mais recente disponível do cluster antes do início da interrupção.
Para saber como visualizar seus snapshots de backup, consulte Visualizar snapshots de backup M10+.
Restaure o snapshot mais recente da etapa anterior no novo cluster
Para saber como restaurar seu snapshot, consulte Restaurar seu cluster.
Alterne todos os aplicativos que se conectam ao cluster antigo para o cluster recém-criado
Para encontrar a nova string de conexão, consulte Conectar via bibliotecas de clientes. Revise sua pilha de aplicativo, pois você provavelmente precisará redistribuí-la no novo provedor de nuvem.
Interrupção do Atlas
No caso altamente improvável de o Plano de Controle do Atlas e a IU do Atlas não estarem disponíveis, seu cluster ainda estará disponível e acessível. Para saber mais, veja Reliability da plataforma. Abra um ticket de suporte com prioridade alta para investigar o problema mais a fundo.
Problemas de Capacidade de Recursos
Problemas de capacidade de recursos computacionais (como espaço em disco, RAM ou CPU) podem resultar de planejamento inadequado ou tráfego inesperado no banco de dados. Esse comportamento pode não ser resultado de um desastre.
Se um recurso computacional atingir o limite alocado e causar um desastre, siga estas instruções:
Identifique qual recurso computacional está esgotando usando o Painel de Desempenho em Tempo Real ou as métricas do Atlas
Para visualizar sua utilização de recursos na UI do Atlas, consulte Monitorar o desempenho em tempo real.
Para visualizar métricas com a API de administração do Atlas, consulte Monitoramento e registros.
Alocar os recursos necessários
Observe que o Atlas executará essa alteração de forma contínua, portanto, ela não deve ter nenhum impacto grande em seus aplicativos.
Para saber como alocar mais recursos, consulte Editar um cluster.
Falha de recurso
Importante
Esta é uma solução temporária destinada a reduzir o tempo de inatividade geral do sistema. Quando o problema subjacente for resolvido, mescle os dados do cluster recém-criado ao cluster original e ponto todos os aplicativos de volta para o cluster original.
Se um recurso computacional falhar e tornar seu cluster indisponível, siga estas instruções:
Abra um ticket de suportede alta prioridade
Restaure o backup mais recente no cluster recém-criado
Para saber como restaurar seu snapshot, consulte Restaurar seu cluster.
Exclusão de dados de produção
Os dados de produção podem ser excluídos acidentalmente devido a erro humano ou a um bug no aplicativo criado sobre o banco de dados. Se o próprio cluster foi excluído acidentalmente, o Atlas pode reter o volume temporariamente.
Se o conteúdo de uma coleção ou de um banco de dados foi excluído, siga estas instruções para restaurar seus dados:
Criar uma cópia do estado atual da collection ou banco de dados, se ela contiver quaisquer dados
Você pode usar o mongoexport para criar uma cópia.
Restaurar seus dados
Se a exclusão ocorreu nas últimas 72 horas, e você configurou o backup contínuo, use a restauração de ponto no tempo (PIT) para restaurar a partir do ponto no tempo imediatamente anterior à exclusão.
Se a exclusão não ocorreu nas últimas 72 horas, restaure o backup mais recente de antes da ocorrência da exclusão no cluster.
Para saber mais, consulte Restaurar Seu Cluster.
Se você criou uma cópia dos seus dados, importe os novos dados que você exportou
Você pode usar o mongoimport com o modo upsert para importar seus dados e garantir que quaisquer dados que tenham sido modificados ou adicionados estejam corretamente replicados na coleção ou no banco de dados.
Falha do driver
Se um driver falhar, siga estas instruções:
Identifique a versão apropriada do driver para resolver o problema
Se você estiver usando um driver desatualizado, verifique se fazer upgrade para uma versão mais recente resolve o problema. A maioria dos problemas de driver é corrigida em versões mais recentes.
Se você atualizou recentemente seu driver e suspeita que a nova versão introduziu o problema, considere reverter para a versão de trabalho anterior.
Avalie se outras alterações são necessárias para migrar para a versão do driver de destino
Isso pode incluir código do aplicativo ou alterações de query. Por exemplo, pode haver alterações interruptivas se você estiver alternando entre as versões principais, ou novos recursos disponíveis se você estiver fazendo upgrade.
Corrupção de dados
Importante
Esta é uma solução temporária destinada a reduzir o tempo de inatividade geral do sistema. Quando o problema subjacente for resolvido, mescle os dados do cluster recém-criado ao cluster original e ponto todos os aplicativos de volta para o cluster original.
Se os seus dados subjacentes forem corrompidos, siga estas instruções:
Abra um ticket de suportede alta prioridade
Restaure o backup mais recente no cluster recém-criado
Para saber como restaurar seu snapshot, consulte Restaurar seu cluster.