목차
CRUD 작업의 기본 정의
사용자가 웹 사이트나 웹 애플리케이션과 같은 디지털 플랫폼에서 수행하는 대부분의 트랜잭션 상호 작용에는 다음과 같은 네 가지 기본 작업에 대한 요청이 포함됩니다.
- 새로 생성(예: 고객 프로필)
- 읽기(예: 사용자의 주문 세부 정보 가져오기)
- 정보 업데이트(예: 사용자의 휴대폰 번호나 이메일 주소)
- 삭제(예: 업무용 휴대폰 번호)
CRUD는 데이터 지향적이며 HTTP 동작 동사에 따라 표준화되었습니다. 애플리케이션의 프론트엔드는 정보를 캡처하여 HTTP 요청으로 미들웨어에 전송합니다. 미들웨어는 적절한 데이터베이스 기능을 호출하여 작업을 완료합니다. 이 네 가지 기본 기능을 통칭하여 CRUD(Create, Read, Update, Delete의 약어)라고 합니다.
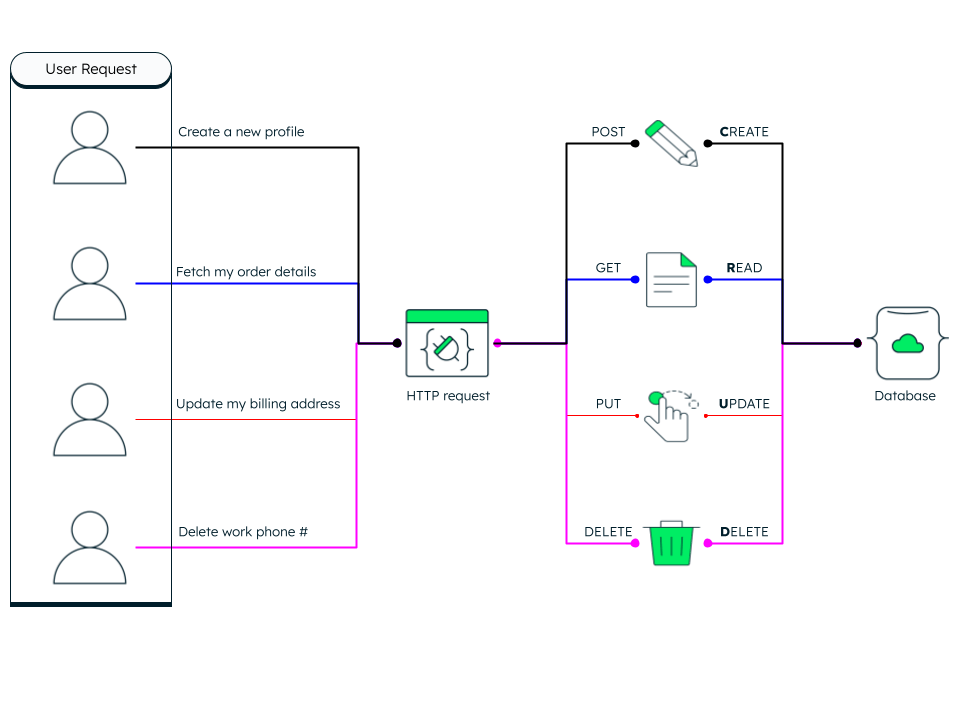
기본 작업의 예
CRUD는 데이터베이스의 데이터를 관리하는 기본적인 방법입니다. 대량 작업이든 개별 작업이든, CRUD 작업은 모든 애플리케이션에 필수적입니다.
생성 작업의 몇 가지 예로는 데이터베이스에 새 사용자 프로필 만들기, 사용자를 위한 장바구니 만들기, 새 도서 카탈로그 만들기(대량 삽입) 등을 들 수 있습니다.
읽기 작업의 몇 가지 예로는 사용자가 특정 검색 조건에 맞는 제품 세부 정보 가져오기(예: 사용자가 'apple' 브랜드의 휴대폰을 검색하는 경우), iPhone의 모든 모델 표시, 사용자의 제품 장바구니 정보 표시, 포털에서 직원 세부 정보 보기 등을 들 수 있습니다.
업데이트 작업의 예로는 사용자의 개인 정보, 장바구니 정보, 청구 주소, 타임스탬프의 업데이트 또는 특정 범위에 해당하는 제품 일련 번호의 업데이트(일괄 업데이트)를 들 수 있습니다.
삭제 작업의 몇 가지 예로는 사용자의 장바구니에서 제품 삭제, 즐겨찾기에서 책 삭제, 특정 기간보다 오래된 모든 기록 삭제(일괄 삭제) 등을 들 수 있습니다.
CRUD의 정의에 대해 자세히 알아보고 MQL(MongoDB Query Language)을 사용하여 MongoDB CRUD 작업을 실행하는 방법에 대해 살펴보겠습니다.
MongoDB에서 CRUD란 무엇인가요?
CRUD 작업은 사용자가 데이터베이스의 일부를 보고, 검색하고, 수정할 수 있도록 하는 사용자 인터페이스의 규칙을 설명합니다. MongoDB는 드라이버를 통해 원하는 프로그래밍 언어로 CRUD 작업을 수행하는 세련된 방법을 제공합니다.
MongoDB 문서는 서버에 연결하여 적절한 문서를 쿼리한 다음 업데이트할 데이터베이스로 데이터를 다시 보내기 전에 설정 속성을 변경하여 수정됩니다.
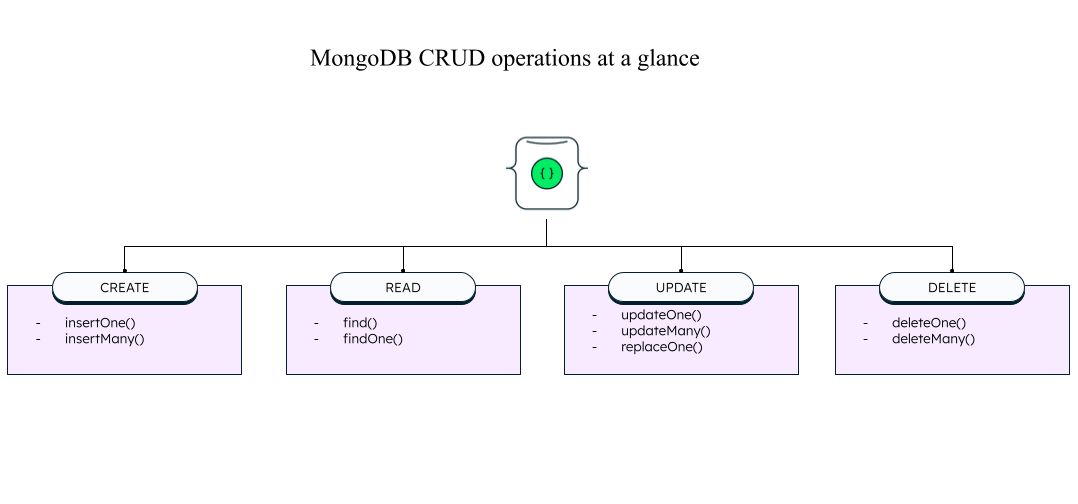
개별 CRUD 작업의 경우 다음과 같습니다.
- 생성 작업은 MongoDB 데이터베이스에 새로운 문서를 삽입하는 데 사용됩니다.
- 읽기 작업은 데이터베이스의 문서를 쿼리하는 데 사용됩니다.
- 업데이트 작업은 데이터베이스의 기존 문서를 수정하는 데 사용됩니다.
- 삭제 작업은 데이터베이스에서 문서를 제거하는 데 사용됩니다.
CRUD 작업 수행 방법
이제 MongoDB CRUD 작업의 정의를 알아보았으므로 MongoDB 데이터베이스에서 개별 작업을 수행하고 문서를 조작하는 방법을 살펴보겠습니다. 문서를 만들고, 읽고, 업데이트하고, 삭제하는 프로세스를 각 작업별로 차례로 살펴보겠습니다.
insertOne()
이름에서 알 수 있듯이 insertOne()을 사용하면 하나의 문서를 컬렉션에 삽입할 수 있습니다. 이 예시에서는 RecordsDB라는 컬렉션을 사용해 보겠습니다. RecordsDB에서 insertOne() 메서드를 호출하여 컬렉션에 단일 항목을 삽입할 수 있습니다. 그런 다음 키-값 쌍의 형태로 삽입하려는 정보를 제공하여 스키마를 설정합니다.
db.RecordsDB.insertOne({
name: "Marsh",
age: "6 years",
species: "Dog",
ownerAddress: "380 W. Fir Ave",
chipped: true
})생성 작업이 성공하면 새 문서가 만들어집니다. 이 함수는 'acknowledged'가 'true'이고 'insertID'가 새로 생성된 'ObjectId'인 객체를 반환합니다.
> db.RecordsDB.insertOne({
... name: "Marsh",
... age: "6 years",
... species: "Dog",
... ownerAddress: "380 W. Fir Ave",
... chipped: true
... })
{
"acknowledged" : true,
"insertedId" : ObjectId("5fd989674e6b9ceb8665c57d")
}insertMany()
원하는 컬렉션에서 insertMany() 메서드를 호출하여 한 번에 여러 항목을 삽입할 수 있습니다. 이 경우 선택한 컬렉션(RecordsDB)에 여러 항목을 전달하고 쉼표로 구분합니다. 괄호 안에는 여러 항목의 목록을 전달한다는 것을 나타내기 위해 대괄호를 사용합니다. 이를 일반적으로 중첩 메서드라고 합니다.
db.RecordsDB.insertMany([{
name: "Marsh",
age: "6 years",
species: "Dog",
ownerAddress: "380 W. Fir Ave",
chipped: true},
{name: "Kitana",
age: "4 years",
species: "Cat",
ownerAddress: "521 E. Cortland",
chipped: true}])db.RecordsDB.insertMany([{ name: "Marsh", age: "6 years", species: "Dog",
ownerAddress: "380 W. Fir Ave", chipped: true}, {name: "Kitana", age: "4 years",
species: "Cat", ownerAddress: "521 E. Cortland", chipped: true}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5fd98ea9ce6e8850d88270b4"),
ObjectId("5fd98ea9ce6e8850d88270b5")
]
}읽기 작업
읽기 작업을 통해 원하는 문서를 지정할 수 있는 특수 쿼리 필터 및 기준을 제공할 수 있습니다. MongoDB 설명서에서 사용 가능한 쿼리 필터에 대해 자세히 알아볼 수 있습니다. 쿼리 수정자를 사용하여 반환되는 결과 수를 변경할 수도 있습니다.
MongoDB는 컬렉션에서 문서를 읽는 두 가지 메서드를 제공합니다.
find()
컬렉션의 모든 문서를 가져오려면 선택한 컬렉션에서 find() 메서드를 사용하면 됩니다. 인수 없이 find() 메서드만 실행하면 현재 컬렉션에 있는 모든 기록이 반환됩니다.
db.RecordsDB.find(){ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }
{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "6 years", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd993f3ce6e8850d88270b8"), "name" : "Loo", "age" : "3 years", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd994efce6e8850d88270ba"), "name" : "Kevin", "age" : "8 years", "species" : "Dog", "ownerAddress" : "900 W. Wood Way", "chipped" : true }결과에서 컬렉션에 있는 모든 기록을 볼 수 있습니다. 각 기록에는 '_id' 키에 매핑된 'ObjectId'가 할당되어 있습니다.
읽기 작업을 보다 구체적으로 수행하여 기록의 원하는 하위 섹션을 찾으려면 앞서 언급한 필터링 기준을 사용하여 반환될 결과를 선택할 수 있습니다. 결과를 필터링하는 가장 일반적인 방법 중 하나는 값으로 검색하는 것입니다.
db.RecordsDB.find({"species":"Cat"}){ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }findOne()
검색 기준을 충족하는 하나의 문서를 확인하려면 선택한 컬렉션에서 findOne() 메서드를 사용하면 됩니다. 여러 문서가 쿼리를 충족하는 경우 이 메서드는 디스크의 문서 순서를 반영하는 기본 순서에 따라 첫 번째 문서를 반환합니다. 검색 기준을 충족하는 문서가 없는 경우 함수는 null을 반환합니다. 함수는 다음과 같은 구문 형식을 사용합니다.
db.{collection}.findOne({query}, {projection})다음 컬렉션(RecordsDB)을 예시로 들어 보겠습니다.
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "8 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }
{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "6 years", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd993f3ce6e8850d88270b8"), "name" : "Loo", "age" : "3 years", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd994efce6e8850d88270ba"), "name" : "Kevin", "age" : "8 years", "species" : "Dog", "ownerAddress" : "900 W. Wood Way", "chipped" : true }그리고 다음 코드 줄을 실행합니다.
db.RecordsDB.find({"age":"8 years"})다음과 같은 결과를 얻을 수 있습니다.
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "8 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }두 문서가 검색 기준에 맞더라도 검색 조건과 일치하는 첫 번째 문서만 반환된다는 점에 유의하세요.
업데이트 작업
생성 작업과 마찬가지로 업데이트 작업은 단일 컬렉션에서 작동하며 단일 문서 수준에서 원자적입니다. 업데이트 작업은 필터와 기준을 사용하여 업데이트하려는 문서를 선택합니다.
업데이트는 영구적이며 롤백할 수 없으므로 문서를 업데이트할 때는 주의해야 합니다. 이는 삭제 작업에도 적용됩니다.
MongoDB CRUD에는 문서를 업데이트하는 세 가지 메서드가 있습니다.
updateOne()
업데이트 작업을 통해 현재 존재하는 기록을 업데이트하고 단일 문서를 변경할 수 있습니다. 이를 위해 선택한 컬렉션(여기서는 'RecordsDB')에서 updateOne() 메서드를 사용합니다. 문서를 업데이트하기 위해 메서드에 업데이트 필터와 업데이트 작업이라는 두 개의 인수를 제공합니다.
업데이트 필터는 업데이트하려는 항목을 정의하고 업데이트 작업은 해당 항목을 업데이트하는 방법을 정의합니다. 먼저 업데이트 필터를 전달합니다. 그런 다음 '$set' 키를 사용하여 업데이트하려는 필드를 값으로 제공합니다. 이 메서드는 제공된 필터와 일치하는 첫 번째 기록을 업데이트합니다.
db.RecordsDB.updateOne({name: "Marsh"}, {$set:{ownerAddress: "451 W. Coffee St. A204"}}){ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "6 years", "species" : "Dog", "ownerAddress" : "451 W. Coffee St. A204", "chipped" : true }updateMany()
updateMany()를 사용하면 여러 항목을 삽입할 때와 마찬가지로 항목 목록을 전달하여 여러 항목을 업데이트할 수 있습니다. 이 업데이트 작업은 단일 문서를 업데이트하는 데 동일한 구문을 사용합니다.
db.RecordsDB.updateMany({species:"Dog"}, {$set: {age: "5"}}){ "acknowledged" : true, "matchedCount" : 3, "modifiedCount" : 3 }> db.RecordsDB.find()
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }
{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "5", "species" : "Dog", "ownerAddress" : "451 W. Coffee St. A204", "chipped" : true }
{ "_id" : ObjectId("5fd993f3ce6e8850d88270b8"), "name" : "Loo", "age" : "5", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd994efce6e8850d88270ba"), "name" : "Kevin", "age" : "5", "species" : "Dog", "ownerAddress" : "900 W. Wood Way", "chipped" : true }replaceOne()
replaceOne() 메서드는 지정된 컬렉션의 단일 문서를 대체합니다. replaceOne()은 전체 문서를 대체합니다. 즉, 새 문서에 포함되지 않은 이전 문서의 필드는 손실됩니다.
db.RecordsDB.replaceOne({name: "Kevin"}, {name: "Maki"}){ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }> db.RecordsDB.find()
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }
{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "5", "species" : "Dog", "ownerAddress" : "451 W. Coffee St. A204", "chipped" : true }
{ "_id" : ObjectId("5fd993f3ce6e8850d88270b8"), "name" : "Loo", "age" : "5", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }
{ "_id" : ObjectId("5fd994efce6e8850d88270ba"), "name" : "Maki" }삭제 작업
삭제 작업은 업데이트 및 생성 작업과 같이 단일 컬렉션에서 작동합니다. 삭제 작업도 단일 문서에 대해 원자적입니다. 컬렉션에서 삭제하려는 문서를 지정하는 필터 및 기준과 함께 삭제 작업을 제공할 수 있습니다. 필터 옵션은 읽기 작업에서 사용하는 것과 동일한 구문을 사용합니다.
MongoDB는 컬렉션에서 기록을 삭제하는 두 가지 메서드를 제공합니다.
deleteOne()
deleteOne()은 MongoDB Server의 지정된 컬렉션에서 문서를 제거합니다. 필터 기준은 삭제할 항목을 지정하는 데 사용됩니다. 제공된 필터와 일치하는 첫 번째 기록이 삭제됩니다.
db.RecordsDB.deleteOne({name:"Maki"}){ "acknowledged" : true, "deletedCount" : 1 }> db.RecordsDB.find()
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }
{ "_id" : ObjectId("5fd993a2ce6e8850d88270b7"), "name" : "Marsh", "age" : "5", "species" : "Dog", "ownerAddress" : "451 W. Coffee St. A204", "chipped" : true }
{ "_id" : ObjectId("5fd993f3ce6e8850d88270b8"), "name" : "Loo", "age" : "5", "species" : "Dog", "ownerAddress" : "380 W. Fir Ave", "chipped" : true }deleteMany()
deleteMany()는 단일 삭제 작업으로 원하는 컬렉션에서 여러 문서를 삭제하는 데 사용되는 메서드입니다. 메서드에 목록이 전달되고 개별 항목은 deleteOne()에서와 같이 필터 조건으로 정의됩니다.
db.RecordsDB.deleteMany({species:"Dog"}){ "acknowledged" : true, "deletedCount" : 2 }> db.RecordsDB.find()
{ "_id" : ObjectId("5fd98ea9ce6e8850d88270b5"), "name" : "Kitana", "age" : "4 years", "species" : "Cat", "ownerAddress" : "521 E. Cortland", "chipped" : true }관계형과 비관계형에서의 CRUD 성능 비교
NoSQL 데이터베이스는 생성 및 읽기 작업에 더 최적화되어 있으며 더 큰 확장성을 제공합니다. 따라서 보다 높은 부하에 적합합니다(더 많은 CRUD 작업 처리). 또한 정보 저장 측면에서도 유연합니다.
ResearchGate가 다양한 유형의 NoSQL 및 SQL 데이터베이스를 사용하여 수행한 CRUD 작업에 대해 실시한 세부 실험에서 특히 작업 수가 많을 때 모든 CRUD 작업에서 NoSQL 데이터베이스가 SQL 데이터베이스보다 훨씬 더 나은 성능을 보인다는 결론을 얻었습니다. 예를 들어 MongoDB는 데이터 가져오기(읽기 작업)에서 탁월한 성능을 보였는데, 100,000번의 읽기(찾기/선택) 작업에서 평균 43.5ms의 성능을 기록했습니다. MongoDB는 또한 다른 문서 중심 데이터베이스에서는 시간이 많이 걸리는 원자적 업데이트(필드 수준 업데이트)를 제공하는 데에도 유리합니다.
요약
이 문서에서는 MongoDB에서 CRUD 작업을 수행하는 방법에 대한 몇 가지 예시와 함께 CRUD에 대한 기본 정보를 다루었습니다. MongoDB Atlas에서 UI를 사용하여 CRUD 작업을 수행하는 간단한 방법을 확인할 수 있습니다. MongoDB 매뉴얼에서 핵심 MongoDB CRUD 개념에 대해 자세히 알아보면 성능이 뛰어나고 확장 가능한 애플리케이션을 개발하는 데 도움을 얻을 수 있습니다.
FAQ
CRUD 원칙이란 무엇인가요?
약어인 CRUD는 모든 애플리케이션이 수행할 수 있어야 하는 네 가지 기본 작업, 즉 생성, 읽기, 업데이트, 삭제 작업을 의미합니다. 즉, 애플리케이션은 필요에 따라 데이터베이스에 데이터를 삽입하고, 데이터베이스에서 데이터를 읽고, 데이터베이스 세부 정보를 업데이트하고, 데이터베이스에서 데이터를 삭제할 수 있어야 합니다.
CRUD 앱이란 무엇인가요?
CRUD 앱은 모든 트랜잭션 및 작업에 CRUD 작업을 사용합니다. CRUD 앱에는 사용자 인터페이스(프론트엔드), 컨트롤러 또는 API, CRUD 작업을 처리하는 데이터베이스가 있습니다.
CRUD 작업이란 무엇인가요?
CRUD 작업은 모든 애플리케이션이 웹 사용자와 데이터를 교환하기 위해 수행해야 하는 기본 기능을 말합니다. 새 사용자 프로필 생성(Create), 데이터베이스에서 제품 세부 정보 가져오기(Read), 직원 포털의 직원 정보 업데이트(Update), 카탈로그에서 특정 제품 제거(Delete)와 같은 작업을 예로 들 수 있습니다.