사용자 컨텍스트와 도메인별 순위 요소를 통합하여 입력 시 빠르고 관련성 높은 제안을 애플리케이션에 추가합니다.
산업: 소매
제품: MongoDB Atlas, MongoDB Atlas Vector Search
솔루션 개요
자동 완성, 자동 제안 또는 예측 검색 이라고도 하는 입력 시 기능은 특별히 구축된 포괄적인 솔루션이 아닌 낮은 수준의 문자 매칭을 의미하는 경우가 많습니다. 이 기능을 사용하면 원하는 관련 콘텐츠로 빠르게 이동할 수 있습니다. 검색 창에 'matr'을 입력하여 영화 '매트릭스'를 조회하는 것은 입력 시 즉시 표시되는 기능의 예시 입니다.
벡터 검색과 전체 텍스트 검색 완전한 쿼리 있거나 단어가 매우 일치하는 경우 의미적으로 콘텐츠를 일치시키는 데 유용합니다. 그러나 통합된 as-you-type 기능은 텍스트 입력과 대상 키워드 사이의 문자 수를 줄이고 거리를 늘려 관련 결과를 반환할 수 있습니다. 이 어휘 기반 솔루션은 부분 일치를 용이하게 하고 상황에 맞는 관련 결과를 제공합니다.
참조 아키텍처
as-you-type 제안 솔루션은 아키텍처적으로 간단합니다. 입력과 동시에 요청이 Atlas Search 로 전송되어 관련 결과를 반환합니다. 아키텍처는 특수 entities 컬렉션 과 해당 쿼리를 중심으로 구성됩니다.

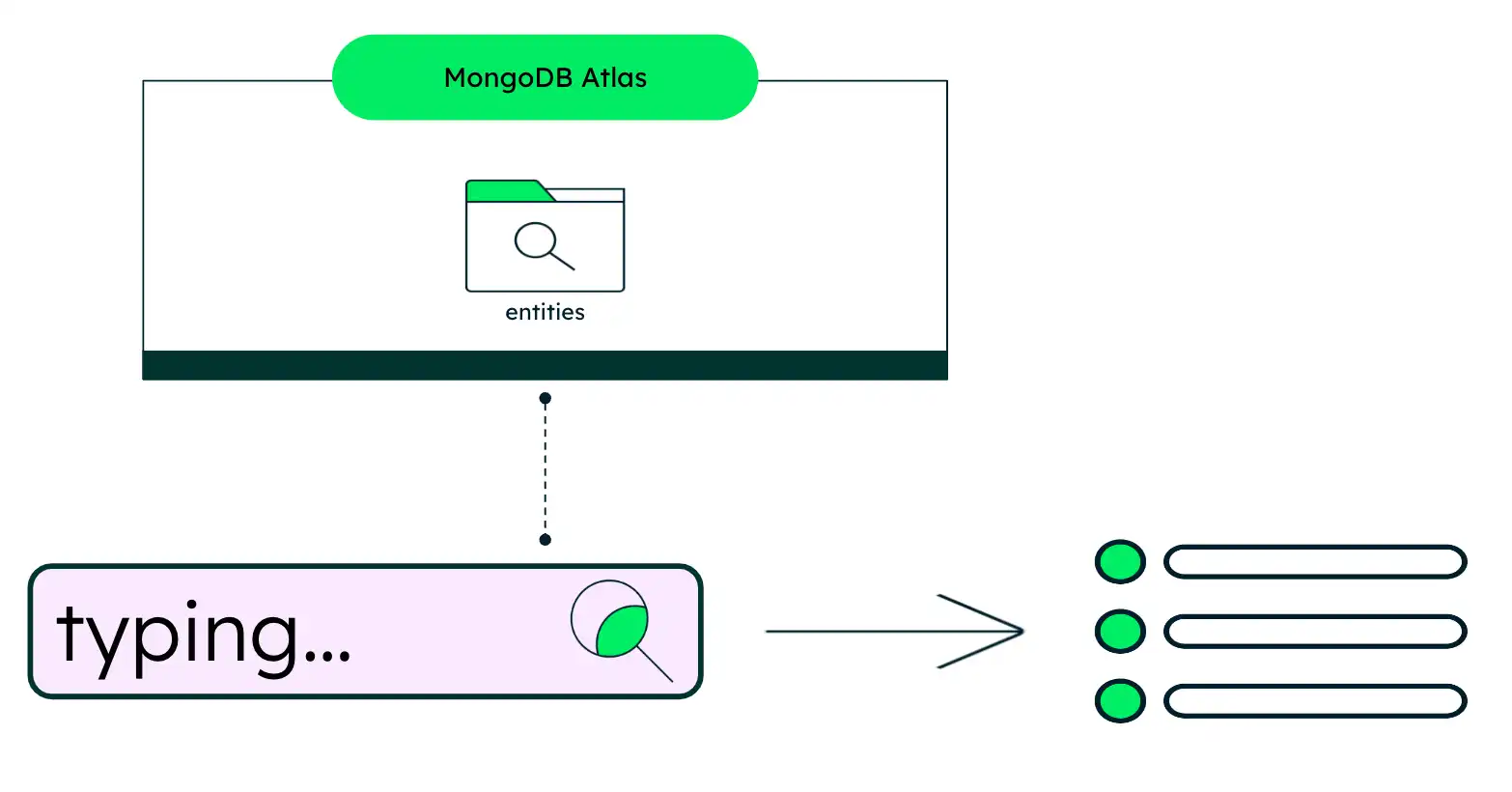
그림 1. 입력 시 제안 솔루션 아키텍처
데이터 모델 접근 방식
사용자에게 제시된 각 제안은 도메인의 고유한 엔티티를 나타냅니다. 엔터티는 입력 시 추천 가능성에 맞게 조정된 특수 컬렉션 의 개별 문서로 모델링되어야 합니다.
기본 컬렉션 일반적으로 한 가지 유형의 엔터티를 문서로 나타내고 다른 도메인 엔터티를 메타데이터 필드 또는 내장된 문서로 나타냅니다. 예시 를 들어, Atlas 에서 제공되는 샘플 영화 데이터를 사용하는 것이 좋습니다. 입력하는 동안 검색 에서 영화 이름이 제안됩니다. 그러나 출연진 이름을 검색 할 수도 있습니다. 예시 를 들어, 'kea'만 입력하면 키아누 리브스가 출연한 영화를 찾을 수 있습니다.
데이터 모델 에는 다음과 같은 스키마 있습니다.
_id:<type>-<natural id>형식의 이 컬렉션 의 고유 ID입니다.type: 엔티티/ 객체 유형, 예: 영화, 브랜드, 인물 제품 및 카테고리.name: 엔터티의 이름 또는 제목으로, 일반적으로 유형별로 고유합니다.
엔터티는 기본 컬렉션 에서 정기적으로 새로 고쳐지므로 엔터티 문서에는 안정적이고 고유한 식별자가 있어야 합니다. 각 엔터티에 type 를 할당하면 필터링(배우별 조회에서 출연진만 추천), 그룹화(유형별로 제안 정리) 또는 유형별 부스트(배우 이름보다 영화에 가중치 부여)가 가능합니다.
엔티티를 개별 문서로 직접 모델링하면 각 문서가 순위 지정, 표시, 필터링 또는 그룹화에 도움이 되는 선택적 메타데이터 필드를 가질 수 있습니다.
문서 모델 여러 가지 방법으로 쿼리하는 데 적합한 여러 가지 방법으로 값을 나누는 정교한 인덱스 구성을 통해 name 필드 피드를 제공합니다. 이 솔루션의 힘은 여러 인덱싱 및 쿼리 전략의 결합에서 비롯됩니다.
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
솔루션 빌드
먼저 데이터에서 제안 가능한 엔터티를 식별합니다. 영화 시나리오에서는 영화 제목, 출연진 이름, 장르 및 감독 이름도 포함됩니다.
이 as-you-type 제안 시스템의 기본은 다음과 같습니다.
entities컬렉션 만들고 위에서 모델링된 스키마 사용하여 채웁니다. 보장되는 한 자주entities컬렉션 새로 고칩니다.아래에 설명된 대로 인덱스 구성을 사용하여 Atlas Search
entities_index를 만듭니다.$search를 사용하는 집계 파이프라인 내에서 관련 부스팅 요인과 함께 강력한 쿼리 절 설정하다 작성합니다.
엔터티 가져오기
entities 컬렉션 채우는 방법에는 여러 가지가 있지만, 컬렉션을 채우는 간단한 방법 중 하나는 메인 컬렉션에서 집계 파이프라인 실행하여 모든 영화에서 고유한 제목을 가져오는 것입니다.
[ { $group: { _id: "$title", }, }, { $project: { _id: {$concat: [ "title", "-", "$_id" ]}, type: "title", name: "$_id" } }, { $merge: { into: "entities" } } ]
$project 단계에서는 각 고유 영화 제목을 필요한 entities 스키마 로 변환합니다. 이 컬렉션 각 문서 유형 지정하기 때문에 type 가 생성된 _id 의 접두사로 인코딩되고 실제 영화 제목이 추가되어 각 고유 제목에 대한 재현 가능한 식별자를 생성합니다. 엔터티 식별자에 type 를 포함하면 같은 이름을 가진 여러 유형의 entities 를 서로 독립적으로 사용할 수 있습니다('Adventure'라는 이름의 영화와 'Adventure' 장르가 있을 수 있음).
마지막으로 $merge 단계에서는 모든 새 제목을 추가하고 기존 제목은 그대로 둡니다.
'The Matrix'의 제목 필드가 적용된 문서는 다음과 같이 간단히 생성됩니다.
{ "_id":"title-The Matrix", "name":"The Matrix", "type":"title" }
각 엔터티 유형에는 $unwind를 사용하여 중첩 배열에서 해제해야 하는 "장르" 및 "캐스트" 엔터티의 경우와 같이 entities 컬렉션 에 병합하기 위한 고유한 기술이 잠재적으로 필요합니다.
이 캐스트 전용 엔티티 가져오기는 'Keanu Reeves'를 다음과 같이 가져옵니다.
{ "_id":"cast-Keanu Reeves", "name":"Keanu Reeves", "type":"cast", "weight": 6.637 }
엔터티 인덱싱
name 필드는 여러 방식으로 인덱싱되어 쿼리 시 부분 일치 및 순위 지정을 용이하게 합니다.


그림 2. 다양한 인덱싱 전략
이 기능 다중 분석기는 Atlas Search 인덱스 구성을 사용하여 단일 문서 필드 다양한 방법으로 인덱싱 활성화 .
type 필드는 equals 또는 in 필터링을 위한 token 필드와 각 엔터티 유형의 결과별 개수를 확인할 수 있도록 하는 stringFacet 필드 두 가지 형태로 모두 인덱싱됩니다.
인덱스 정의는 동적 매핑 또는 사용자가 제공하는 정적 정의를 통해 _id, type, name 외에 추가된 다른 필드를 처리합니다. 이 예시 에서 weight 은 사용자 지정이며 숫자 유형으로 동적으로 처리됩니다.
제안 검색
그 결과로 생성된 특수 검색 인덱스 실시간 쿼리(as-you-type) 쿼리의 기반을 제공합니다. name 필드 여러 가지 방법으로 인덱싱되며 다양한 조정 가능한 쿼리 연산자를 사용하여 입력하는 사용자와 일치합니다. 아이디어는 쿼리 연산자를 다르게 분석된 매핑과 비교하여 일치하는 항목을 확인하는 것입니다. 일치하는 항목이 많을수록 추천 순위가 높아집니다. 각 쿼리 절을 독립적으로 늘리고 합산하여 일치하는 엔터티에 대한 관련성 점수를 제공할 수 있습니다. 이러한 점수는 선택적 엔터티 weight 필드 와 같은 다른 요인에 의해 더 증가할 수 있습니다.


그림 3 예시 쿼리 및 관련성 점수 계산
일반적으로 사용자가 추천 항목을 선택한 다음 선택한 항목에 대해 대상 기존 검색 수행합니다. 그런 다음 검색 일치하는 모든 항목을 반환합니다.
이 솔루션을 보려면Github 리포지토리 를 방문하세요.
주요 학습 사항
특수 인덱스 구성을 사용하여 제안 가능한 엔터티를 문서로 모델링합니다: 위의 단계에 따라 모든 소스의 모든 엔터티를 포함하는 별도의 컬렉션 만듭니다.
다음 구성으로 인덱스 만들기: 기본 컬렉션 이 모든 제안 가능한 엔터티를 최상위 문서로 모델링하는 경우 이 인덱스 설정을 사용합니다.
인덱스 구조를 사용하여 영리한 쿼리 작성: 인덱스 사용하여 엔터티를 일치시키고 원하는 대로 추천 순위를 지정합니다.
작성자
Erik Hatcher, MongoDB