Overview
このガイドでは、GridFSを使用してMongoDBに大容量ファイルを保存、検索する方法を学びます。GridFSとは、保存時にファイルをチャンクに分裂、検索時にそれらのファイルを再アセンブルする方法を記述した仕様です。RubyドライバーのGridFSの実装は、ファイルストレージの操作と組織を管理する抽象化です。
ファイルのサイズがBSONドキュメントサイズ制限の16 MB を超える場合は、 GridFSを使用します。 GridFSがユースケースに適しているかどうかの詳細については、 MongoDB Serverマニュアルの GridFSを参照してください。
次のセクションでは、GridFS 操作とその実行方法について説明します。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイルのチャンクとそれを説明する情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには、GridFS の仕様に定義されている規則を使用して名前付けされた、以下のコレクションが含まれています。
chunksコレクションには、バイナリ ファイルのチャンクがストアされます。filesコレクションには、ファイルのメタデータがストアされます。
新しいGridFSバケットを作成すると、Mongo::Database#fs メソッド オプションで別の名前を指定しない限り、ドライバーは fs.chunks コレクションと fs.files コレクションを作成します。また、ファイルや関連メタデータを効率的に取得できるように、各コレクションにインデックスも作成します。ドライバーは、 GridFSバケットが存在しない場合、最初の書込み操作が実行されたときにのみ作成します。ドライバーはインデックスが存在しない場合と、バケットが空の場合にのみインデックスを作成します。GridFSインデックスの詳細については、 MongoDB Serverマニュアルの「 GridFSインデックス 」を参照してください。
GridFSを使用してファイルを保存する場合、ドライバーはファイルを小さなチャンクに分割し、各ファイルは chunksコレクションに個別のドキュメントとして表されます。また、ファイルID、ファイル名、およびその他のファイルメタデータを含むドキュメントを filesコレクションに作成します。ファイルをメモリからアップロードすることも、ストリームからアップロードすることもできます。次の図は、バケットにアップロードされるときにGridFS がファイルを分割する方法を示しています。

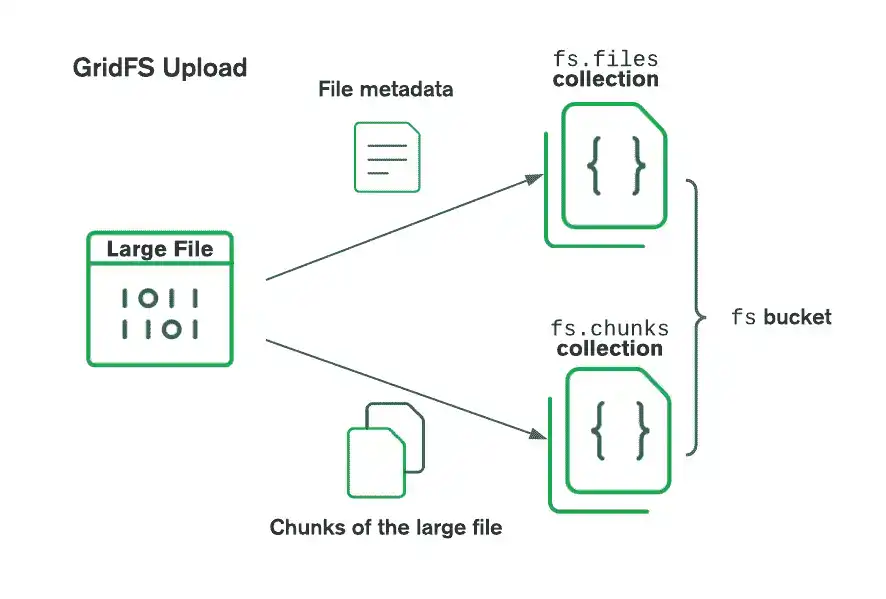
ファイルを検索する際、GridFS は指定されたバケット内の files コレクションからメタデータを取得し、その情報を使用して chunks コレクション内のドキュメントからファイルを再構築します。ファイルをメモリに読み込んだり、ストリームに出力したりすることもできます。
GridFS バケットの作成
GridFSからファイルを保存または検索するには、Mongo::Databaseインスタンスで fs メソッドを呼び出してGridFSバケットを作成します。FSBucketインスタンスを使用して、バケット内のファイルの読み取り操作および書込み操作を実行できます。
bucket = database.fs
デフォルト名 fs 以外の名前のバケットを作成または参照には、次の例に示すように、バケット名を任意のパラメータとして fs メソッドに渡します。
custom_bucket = database.fs(database, bucket_name: 'files')
ファイルのアップロード
upload_from_stream メソッドはアップロード ストリームの内容を読み取り、GridFSBucketインスタンスに保存します。
オプションのパラメータとして Hash を渡すと、チャンク サイズを構成したり、追加のメタデータを含めたりできます。
次の例では、ファイルを FSBucket にアップロードし、アップロードされたファイルのメタデータを 指定しています。
metadata = { uploaded_by: 'username' } File.open('/path/to/file', 'rb') do |file| file_id = bucket.upload_from_stream('test.txt', file, metadata: metadata) puts "Uploaded file with ID: #{file_id}" end
ファイル情報の検索
このセクションでは、GridFS バケットの files コレクションにストアされているファイル メタデータを検索する方法を学びます。メタデータには、参照先のファイルに関する次のような情報が含まれます。
ファイルの
_idファイルの名前
ファイルのサイズ
アップロード日時
その他の情報をストアできる
metadataドキュメント
filesコレクションから取得できるフィールドの詳細については、 MongoDB ServerマニュアルのGridFSファイル コレクション のドキュメントを参照してください。
GridFSバケットからファイルを検索するには、FSBucketインスタンスで find メソッドを呼び出します。 次のコード例では、 GridFSバケット内のすべてのファイルからファイルメタデータを検索して出力します。
bucket.find.each do |file| puts "Filename: #{file.filename}" end
MongoDB のクエリの詳細については、ドキュメントの検索を参照してください。
ファイルのダウンロード
download_to_stream メソッドは、ファイルの内容をダウンロードします。
ファイルをファイル_id ごとにダウンロードするには、_id を メソッドに渡します。download_to_stream メソッドは、ファイルの内容を指定されたオブジェクトに書込みます。次の例では、ファイルをファイル_id ごとにダウンロードします。
file_id = BSON::ObjectId('your_file_id') File.open('/path/to/downloaded_file', 'wb') do |file| bucket.download_to_stream(file_id, file) end
ファイル名を指定して、その _id でない場合は、download_to_stream_by_name メソッドを使用できます。次の例では、mongodb-tutorial という名前のファイルをダウンロードします。
File.open('/path/to/downloaded_file', 'wb') do |file| bucket.download_to_stream_by_name('mongodb-tutorial', file) end
注意
同じ filename 値を持つドキュメントが複数ある場合、 GridFS は指定された名前( uploadDateフィールドによって決定)を持つ最新のファイルを取得します。
ファイルの削除
delete メソッドを使用して、ファイルのコレクションドキュメントと関連するチャンクをバケットから削除します。 削除するファイルは、ファイル名ではなく、_idフィールドで指定する必要があります。
次の例では、 _id でファイルを削除しています。
file_id = BSON::ObjectId('your_file_id') bucket.delete(file_id)
注意
deleteメソッドでサポートされているファイルの削除は、一度に 1 件のみです。 複数のファイルを削除するには、バケットからファイルを検索し、削除するファイルから_idフィールドを抽出し、 deleteメソッドを個別に呼び出して各値を渡します。
API ドキュメント
GridFS を使用して大容量のファイルを保存および検索する方法の詳細については、次のAPIドキュメントを参照してください。