代替データ、人工知能、生成系 AI の融合が、信用スコアリングの基盤を再構築している仕組みを学びます。
ユースケース: Gen AI
製品およびツール: MongoDB Atlas、 Spark Streaming Connector、 MongoDB Atlas Vector Search
パートナー: LgChuin、Fireworks.AI
ソリューション概要
このソリューションは、代替データの人工知能と生成系AI のコンフィギュレーションがクレジットリングの基盤を再構築する方法を示しています。代替のクレジットクレジットリング メソッドは、クレジット可能性のより包括的でニュアンスのある評価を提供し、従来のモデルの問題を解決することもできます。
このソリューションでは、オンラインクレジットカードアプリケーションのサンプルプロセスについて説明し、 MongoDB がクレジットスコアリングをサポートする方法を示しています。また、個人保証、モーダル、組織任意のクレジット、構造体のクレジットラインなどの他のクレジット商品に対しても同様のアプローチを使用できます。
従来のクレジットスコアリングの課題
以下に、従来のクレジットスコアリング モデルの問題点と制限事項をいくつか示します。
クレジット履歴の不足:多くの人々は、クレジット履歴が限られている、または存在しないという障害に直面し、過去のデータがないため、信用力を証明することが困難です。
一貫性のない収入: パートタイムの仕事やフリーランスによく見られる不規則な収入によって、個人をよりリスクが高いと分類する従来の信用評価モデルにおいて懸念事項となり、申請の却下や与信限度額の制限につながります。
既存のクレジットの利用率が高い : 既存のクレジットに依存しているため、クレジット使用率の上昇につながり、条件が満たされない拒否または承認が適用される可能性があるため、クレジットアプリケーションの障害となります。
却下理由の不明確さ:却下理由の透明性が欠如しているため、顧客は根本的な原因に対処し、今後のアプリケーションにおける信用力を高めることが困難です。
ソリューションのビルド
次のソリューションは、 MongoDB がプロセスの次のアスペクトでクレジットアプリケーションをどのように変換するかを示しています。
データのキャプチャとプロセシングを簡素化します。
AI でクレジットスコアリングを強化する。
クレジットアプリケーションの却下について説明する。
代替クレジット商品を提案する。
データの取得とプロセシングの簡素化
クレジット製品への適用は、次の理由で困難なプロセスが多いことが多いです。
アプリケーションプロセスの複雑さ:クレジットカードのアプリケーションプロセスには、次のような時間のかかる手順が含まれます。
カードの選択:まず、ニーズに合ったクレジットカードを選択します。さまざまなカードを検索し、機能を比較し、その用語と条件を理解します。
適格性チェック: 次に、金融機関が設定した適格性基準を満たしているかどうかを確認します。これらの基準では通常、クレジット評価、年数、給与、オプションなどの要素が考慮されます。
ドキュメント送信: 本人証明書( ソーシャル スペースID、パスワード、ドライバーのライセンスなど)、住所証明書(レンター契約、ユーティリティ 請求書)、インバウンド 証明書(電信送金、給与明細、フォーム 16)などのドキュメントを提供します。
アプリケーションフォーム:クレジットカードのアプリケーションフォームに入力します。これは、金融機関のウェブサイト、ネットワーキングポイント、または店舗にアクセスすることで、オンラインで行うことができます。一部の行では物理的なドキュメントが必要ですが、デジタル プロセスがより一般的になっています。
検証と参考資料:銀行はドキュメントの信憑性を検証し、提供された情報を照合します。このステップでは、AI/機械学習アルゴリズムを使用して滞納確率を計算することも含まれます。
冗長な情報収集:銀行は多くの場合、次のような冗長なデータ収集を行います。
KYCの詳細情報:こうした機関はカスタマーのKYC(顧客確認)情報にアクセスできるにもかかわらず、繰り返しその提出を求めます。
収入の確認:顧客の給与、銀行取引履歴、公共料金、家賃、携帯電話料金、買い物支出などの情報がある場合でも、銀行はこれらの詳細を確認するために追加の証明書類をリクエストすることがあります。
冗長なリクエストを排除し、既存のデータを活用することでこのプロセスを効率化し、ユーザーエクスペリエンスを向上させることができます。
これらのアプリケーション形式は、オートメーション、モーダル、等価トランザクションなどの他のクレジット商品との複雑度が高まります。アプリケーションフォーム内には、入力する必要がある表形式や階層情報がある場合があります。MongoDB の柔軟な開発者データ プラットフォームは、JSONデータをネイティブでサポートしており、ドキュメントが同じスキーマを持つ必要がないため、さまざまなタイプのデータを処理する能力が向上します。
データ取得プロセスを簡素化し、申請のパフォーマンスを向上させるために、オンラインクレジット申請フォームに JSON を使用することができます。JSON には構造化されたデータ表現があり、保存する必要があるさまざまな詳細を整理できます。柔軟なデータモデルは、クレジットカード申請要件の動的な性質にうまく適応し、データの形状が完全に一致しなくても関連データを一緒に保存することができます。JSON は他の開発者にも一般的に理解されているため、コラボレーションが可能になり、データが一目で簡単に理解できるようになります。
MongoDB はJSONのようなBSON形式をネイティブにサポートしているため、クレジットアプリケーションでJSONドキュメントを正常に処理します。
AI でクレジットスコアリングを強化する
MongoDB の開発者データプラットフォームである Atlas を活用して、関連するデータポイントを組み合わせて包括的なユーザーログプロファイルを作成します。
これは、延滞の可能性とクレジットスコアリングを予測するためのデータ処理パイプラインのアーキテクチャ図です。

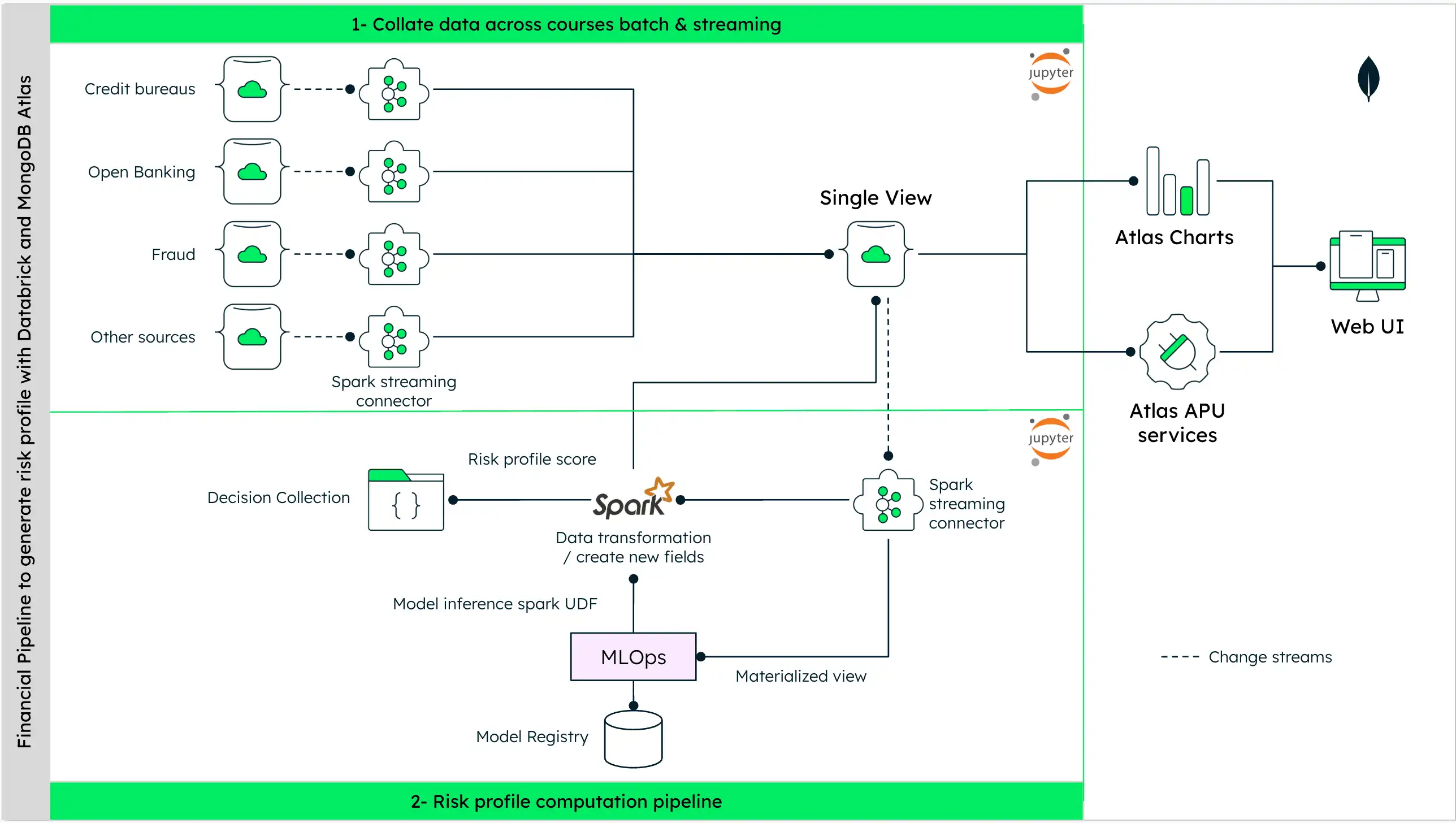
図1。クレジットスコアリング用データ処理パイプラインの図
顧客のクレジットスコアリングのためのデータパイプラインには、次のステップが含まれます。
データ収集:まず、このプロセスでは、クレジット調査機関、オープンバンキング、不正検出システム、その他の関連情報源など、さまざまな情報源からデータを収集します。
データ処理:収集されたデータは、Spark Streaming Connectors などのツールを使用して処理され、カスタマーの財務プロファイルの統合ビューが作成されます。同じデータが MongoDB Atlas に単一ビューとして保存されます。
リスクプロファイルの生成: この統一ビューから、リスクプロファイルや製品提案が生成されます。これには、統計メソッドを使用して記述的分析を実行する方法と、リスク傾向スコアリングを実行するにあたりデータ内のパターンを識別するための人工知能(AI)または機械学習(ML)の技術を使用することが含まれます。
モデル開発:クレジットのスコアリングと決定に使用されるさまざまな機械学習アルゴリズム。論理的な回帰、決定ツリー、サポートベクトルマシン、およびネストされたネットワークについて考えてみましょう。
このチュートリアルでは、予測パフォーマンスに一般的に使用される機械学習アルゴリズムである XGBoost(Extreme Gradient Boosted Tres) モデルを使用します。アルゴリズムは、 関数近似 に基づいて監視される学習メソッドです。このアルゴリズムには次の機能があります。
特定の損失関数を最適化してください。
いくつかの正規化手法を適用する。
高次元データを処理します。
分類と回帰のために複雑なパターンをキャプチャする。
モデルはその推論結果をサポートしており、この予測モデルの結果を説明するのに役立ちます。
データ変換:リスクプロファイルのスコアリングが実行される前に、未加工のユーザーデータはSpark(または同様のマネージド分析フレームワーク)を使用して変換されます。データは複数のソースから集約され、単一のマテリアライズドビューが作成されます。このビューは MongoDB Atlas コレクションから直接取得され、モデル開発やさまざまな記述分析タスクに使用できます。このステップには、モデル推論が含まれることもあります。
意思決定コレクション:最終的に変換されたデータは、意思決定コレクションに格納されます。これは、銀行や金融機関が財務上の意思決定と監査の目的をサポートするのに役立ちます。
目的は、カスタマーの信用度を正確に評価し、情報に基づいた融資の決定や金融商品の推奨を行うことです。このパイプラインは、組織が維持している既存のリスクスコアリングパイプラインのデモンストレーションです。
クレジットアプリケーションの却下について説明する
クレジット申請の却下の理由を理解することは、申請の重要な部分です。MongoDB と大規模言語モデル (LLM) が XGBoost モデルの予測 (このチュートリアルで使用されるモデル) を説明する方法を学びます。
以下は、LLM を使用したクレジット スコアリングを説明するアーキテクチャ図です。

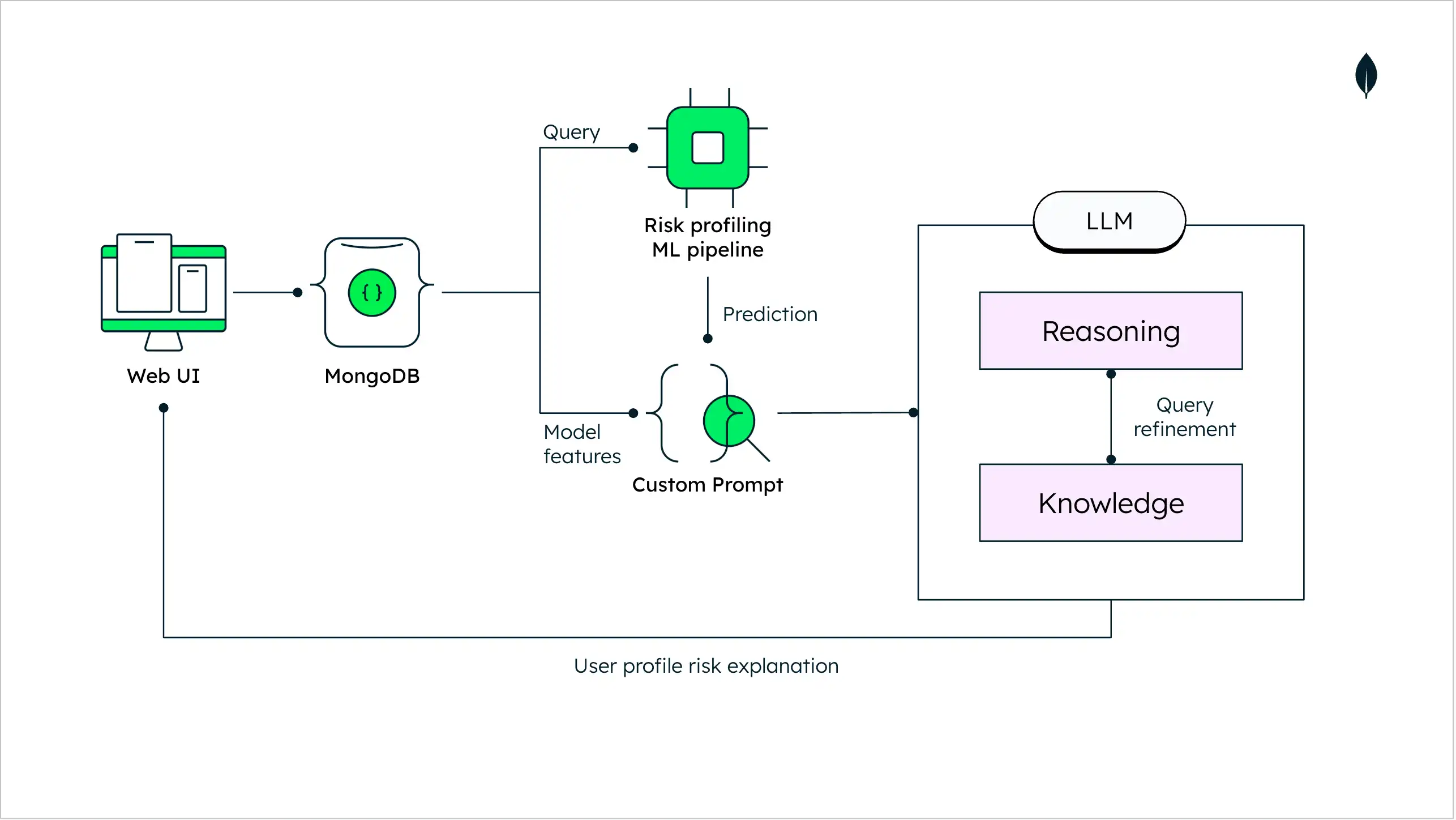
図2。LLMを使用したクレジットスコアリングアーキテクチャ図
採用されているリスクプロファイリング機械学習パイプラインは、商品推奨のプロファイルに関連するリスクを定義する確率スコアを提供します。このメッセージは標準化された方法でユーザーに返され、申請の最終ステータスのみがエンドユーザーに伝えられます。LLM を含む提案されたアーキテクチャでは、プロンプトエンジニアリングを使用して、最終的に承認された商品のステータスの理由をエンドカスタマーに正当な理由と共に説明することができます。
ここで、コードと応答例を閲覧できます。同様のメッセージを生成するコードは、Jupyter Notebook で Python を使って実行できます。MongoDB Atlas の設定と接続文字列の取得の詳細については、このリンクをご覧ください。
以下は、却下の説明の一例です。


図 3. 却下理由の説明例
カスタマーへのこのメッセージは、説明可能な AI の形式であり、リスクプロファイリングを実行するためにモデルで使用される機能がランク付けされ、LLM へのカスタムプロンプトの一部として使用されます。これにより、上記のように、エンドカスタマーがユーザープロファイルを説明する際に、より具体的な理由を示すことができます。LLM は、説明理由のリストを要約し、説明の簡略化されたビューを提供するのにも役立ちます。
このデモでは、クレジット申請をスコアリングするために2つのアプローチが使用されています。クレジット申請のステータスは、前のセクションで説明したように、20以上のクレジット関連の機能を使用した機械学習アプローチによって決定されます。最も重要な上位15の機能の一部を以下にご紹介します。

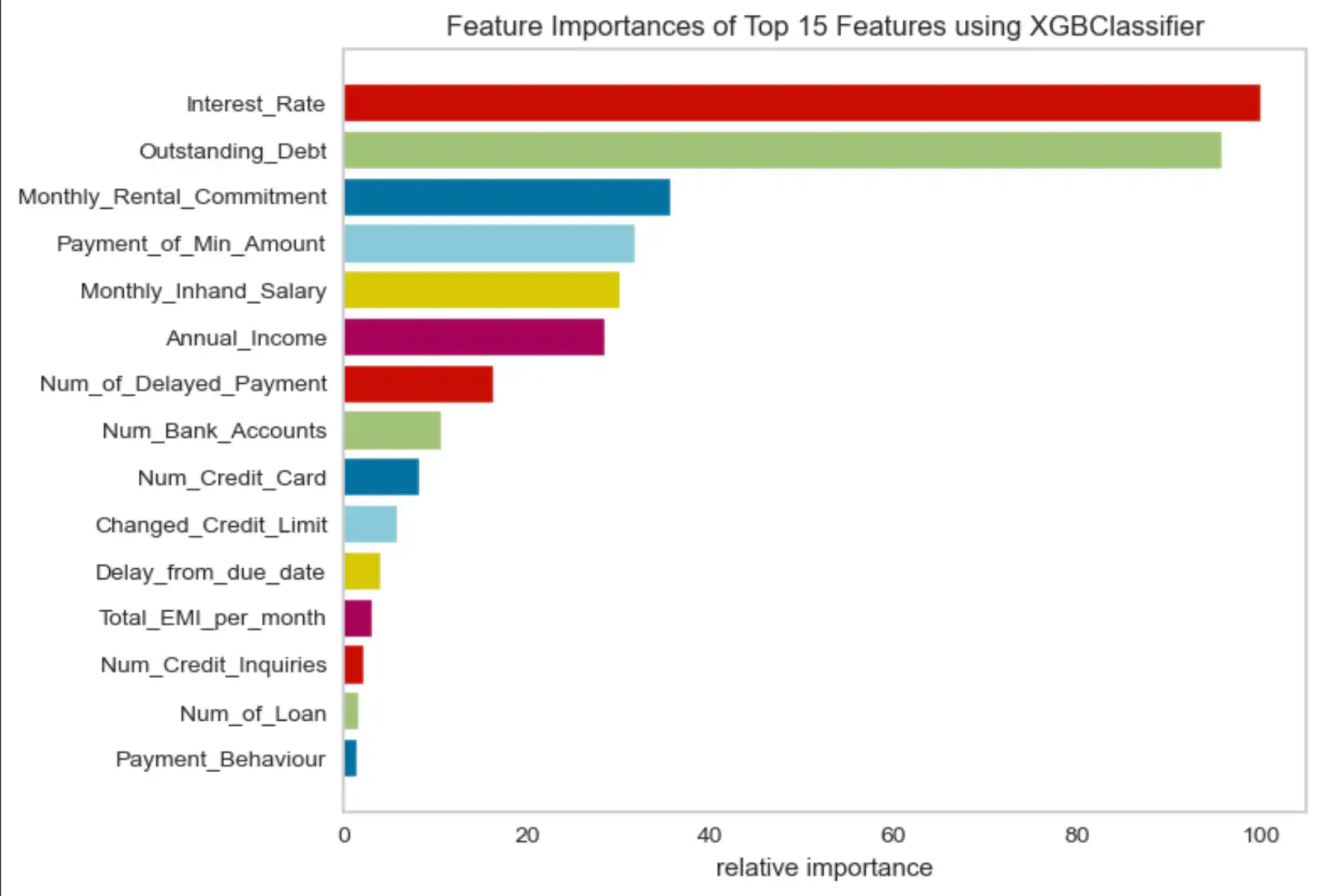
図 4. 機能重要度チャート
このデモで使用されている機能の詳細については、クレジットスコア GitHub リポジトリで提供されているソースコードをご覧ください。
ML と従来のクレジットスコアリング アプローチの違いを示すには、一般的な従来のクレジットリング メソッドが、同じクレジットアプリケーションをスコアリングする方法を検討してくださいが、通常は 少数の次元しか使用しません。このデモでは、主要クレジットスコア プロバイダーによって通常使用されるいくつかの機能を使用します。
クレジット申請者の返済履歴
クレジット使用
クレジット履歴
クレジット照会の未処理件数と回数
代替クレジット製品を提案
信用機関は、顧客がすでに手続きやアプリケーションポータルを利用している状況において、顧客のニーズに合った関連商品をクロスセルするよう常に努めるべきです。
金融機関は、新しい推奨の理由を人間が判読できるようにする製品推奨システムを実装できます。これにより、現在のレガシーシステムでは提供されていない新しい収益の機会が開かれます。理由を提供すると、クライアントとのパーソナライズされた関係が作成され、推奨製品の受け入れが増加します。これを実現するために使用されるデータ アーキテクチャの例を示します。

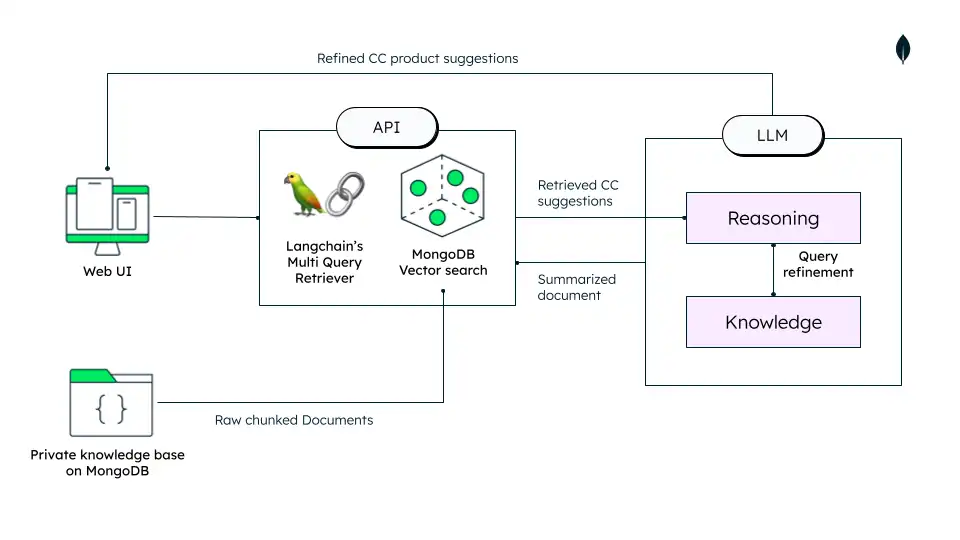
図 5. レコメンデーションシステム アーキテクチャ
Atlas ベクトル検索 は、あらゆるタイプのデータに対してセマンティック検索と生成系AI を実行できる機能です。これにより、運用データベースとベクトル検索が単一のフルマネージドプラットフォームにMongoDBネイティブ インターフェースで統合されます。機械学習モデルでベクトル埋め込みを作成し、 MongoDB Atlasに保存してインデックスを作成すると、検索拡張生成 (RAG)、セマンティック検索、推奨エンジン、動的パーソナライズ、およびその他のユースケースで使用できます。
RAG は、入力クエリに基づいて関連するドキュメントをベクトル検索で検索するパラダイムです。次に、検索されたドキュメントをコンテキストとして LLM に提供し、より情報に基づいた正確な応答の生成に役立てます。
上記のチュートリアルでは、クレジットカード商品の推奨のユースケースを解決するために使用できるテクノロジーについて説明しています。プロセスに含まれる手順を以下に説明します。
個人データを読み込む:クレジットカード商品ごとに提供内容は異なります。これらの商品は随時変更されます。また、映画チケットやコンシェルジュサービスなどのさまざまなライフスタイル特典の料金も変更されます。商品データを MongoDB にオペレーショナルデータストア(ODS)として保存することで、変更を維持しながらベクトルインデックスを同時に構築することができます。
大規模なデータポイントは、ニーズに応じて適切に更新、削除、挿入、または置換することができます。
クレジットカード商品の説明は非常に長いため、小さなチャンクに分割すると、それに応じて関連情報を検索するのに役立ちます。
LLM を活用すると、製品の説明を短縮し、製品の主要な機能とコストをすべて含む要約を作成することができます。この変更により、関連する商品をすばやく検索して提案することが可能になります。
LLM を活用したレコメンデーション: このユースケースでは、LLM をレコメンダー システムとして使用し、前の段階で生成されたユーザープロファイルを入力として使用し、MongoDB Atlas に保存されている製品ベクトルに対してセマンティックな類似性検索を実行するためのサブクエリを生成できます。
パーソナライズされたメッセージングによる製品推奨: 推奨製品は、エンド ユーザー向けに関連する製品推奨のサマリーを生成するために、LDM へのカスタム プロンプトで使用されます。
これにより、金融機関は推奨をパーソナライズし、カスタマーに関連する推奨を提供できるため、コンバージョン率が向上します。
商品の推奨は、提供する商品の「推奨する可能性が高い」スコアを向上させることで、顧客エンゲージメントを高め、ユーザーエクスペリエンスを向上させます。
ここでは、代替製品の推奨事項のコードと例を見つけることができます.以下に例を示します。Pythonを使用して、製品推奨を生成し、製品推奨の説明をカスタマイズするコードを作成できます。

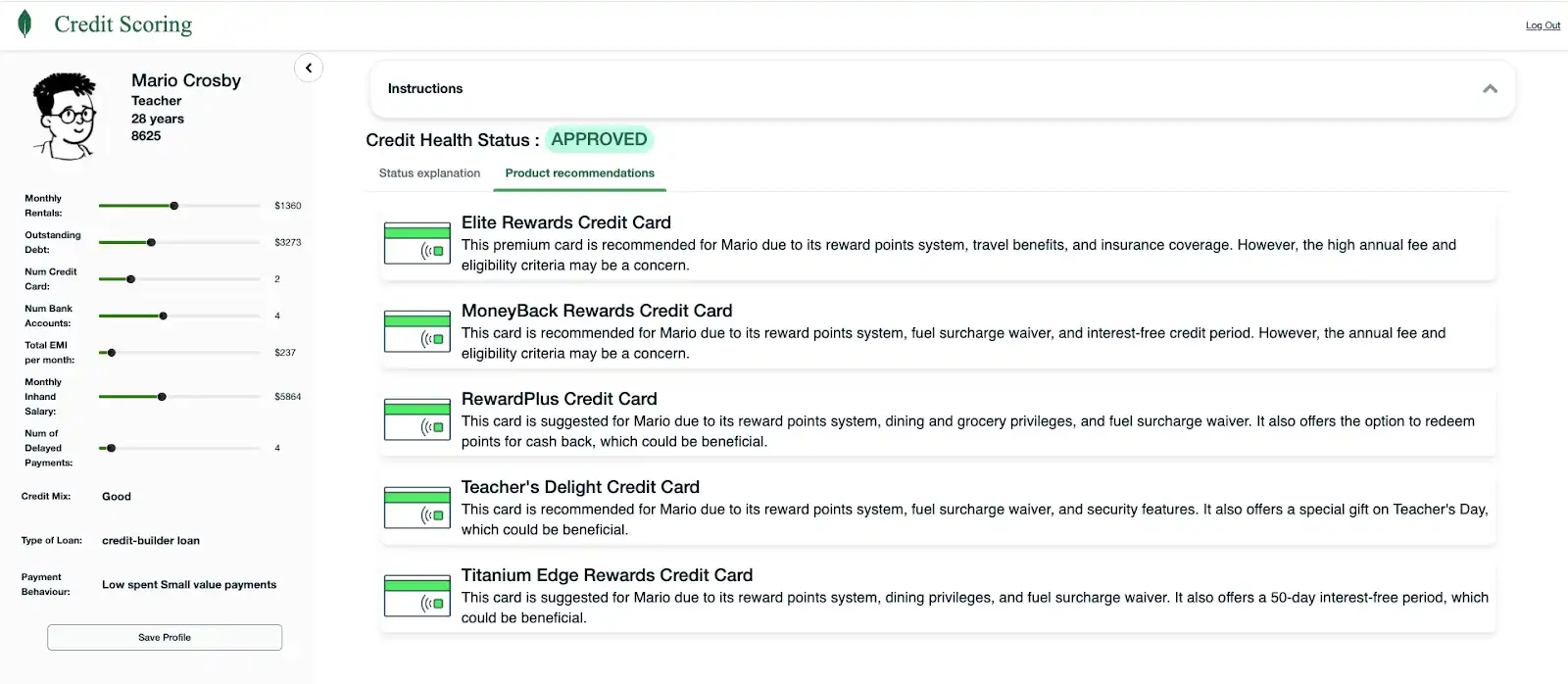
図 6. 承認済み申請の例
結論として、クレジットスコアリングは、生成系AIの統合により、変革の段階にあります。テクノロジーと金融の相乗効果により、クレジット判断が正確であるだけでなく、借り手にも力を与える未来が形作られています。
このようなソリューションを構築するためのMongoDBのすべての機能を表示するコードは、 Githubリポジトリで利用できます。起動します。 MongoDBの主要AI提携するであるAIは、生成系AIによるイノベーションをより速く、効率的に、安全にします。
キーポイント
生成AI の機能の理解: さまざまなデータセットを同期して、従来のクレジットクレジットリング モデルの重要な制限に対処します。
説明可能なクレジットステータスの提供: LM を通じてプロンプト エンジニアリング を使用して、有効な理由でクレジットカスタマーの理由を説明します。
従来のクレジットスコアリング モデルの課題: 変化する金融サービスに適応し、非トランザクションのデータソースを処理し、クレジット可能性のより包括的で正確な評価を提供する代替のクレジットスコアリング モデルの必要性を認識します。
代替データの使用: より正確なクレジットリングのために代替データの利点を理解します。このクレジットスコアリング モデルは、ユーティリティ 請求、携帯電話請求、教育履歴などの代替データ ポイントを使用してさらに改善できます。
ドキュメントの認証メカニズムに対処する: RG を活用して現在のソースからの実際の情報でモデルの応答を基礎にし、モデルの応答が最新の正確な情報を反映するようにすることで、ハートビートのリスクを軽減します。
作成者
Ashwin Gangadhar、提携ソリューション部門、MongoDB
Wei You Pan、業界ソリューション部門、MongoDB
Julian Boronat、業界ソリューション、MongoDB