MongoDB Atlas には、組み込みのメトリクス、テレメトリ、ログの堅牢なセットがあり、Atlas から利用するか、またはサードパーティのオブザーバビリティおよびアラート スタックに統合できます。これにより、Atlas の配置を監視および管理し、インシデントに対して能動的にリアルタイムで対応できるようになります。
配置をモニタリングすると、次のことが可能になります。
クラスターの健全性と状態を把握する
クラスターで実行中の操作がデータベースにどのように影響するかを見る
ハードウェアのリソースが制約されているかどうかを学ぶ
ワークロードとクエリの最適化の実行
アプリケーション スタックを改善するために、リアルタイムの問題を検出し、対応する
Atlas は、モニタリングおよびアラートのためにいくつかのメトリクスを提供しています。配置の健全性、可用性、消費量、パフォーマンスをビジュアル ダッシュボードや API で追跡できます。また、さまざまなクラスター メトリクスを表示し、データベースのパフォーマンスを監視し、アラートとアラート通知を設定し、アクティビティ ログをダウンロードすることもできます。
Atlas の監視とアラートに関する機能
メトリクス | 配置メトリクスは、ハードウェアのパフォーマンスとデータベース操作の効率に関するインサイトを提供します。Atlas はサーバー、データベース、 MongoDBプロセスのメトリクスを収集し、のさまざまな粒度レベルでメトリクス データを保存します。Atlas は各粒度レベルごとに、次の細かい粒度レベルで報告されたメトリクスの平均としてメトリクスを計算します。多くのメトリクスにはバースト レポート作成と同等があります。 Atlas UI では、メトリクスビュー、リアルタイム パフォーマンス パネル、クエリプロファイラー、Performance Advisor、および名前空間インサイトページを使用してメトリクスを監視できます。Atlas CLI または Atlas Administration API を使用して、メトリクスを任意のツールに集約することもできます。 次の Atlas UI メトリクスビューには、サンプルの 3 ノードレプリカセットを監視するために利用できるさまざまなメトリクスが表示されています。 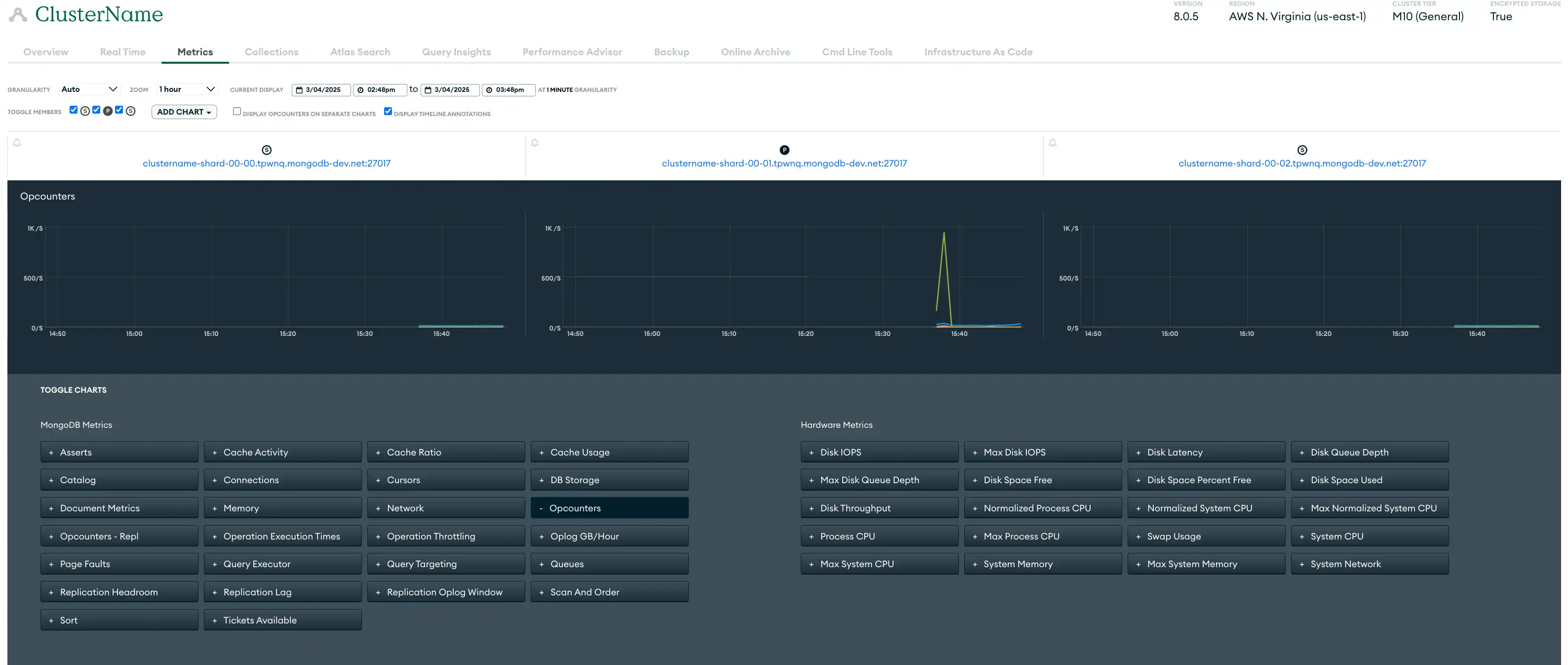 クリックして拡大します |
アラート | Atlas は 200 を超えるイベント タイプのアラートを提供し、正確なモニタリングを行うためにアラートをカスタマイズできます。Atlas は、アラート設定で設定したデータベースとサーバーの条件に対してアラートを発報します。条件によってアラートがトリガーされると、Atlas はクラスターに警告シンボルを表示し、アラート通知を送信します。 Atlas UI、 Atlas Administration API、Atlas CLI、統合 Terraformリソースを使用して、アラートとアラート通知を構成できます。 |
モニタリング | Atlas のモニタリング可視化により、ハードウェアのパフォーマンスやデータベース操作効率など、さまざまな重要なメトリクスに関するインサイトが提供されます。ネットワークや操作の可視性のためのリアルタイムパフォーマンス パネル、効率の傾向を追跡するためのクエリプロファイラー、自動インデックス提案などのツールを使用すると、問題をより効果的に監視およびトラブルシューティングできるため、 運用効率が向上します。例、これらのチャートは、サーバーの再起動と選挙がデータベースのパフォーマンスに影響を理解するのに役立ちます。 |
ログ | Atlas は、クラスター内の各プロセスのログを提供します。各プロセスは、独自のログファイルにアクティビティの記録を保持します。 Atlas UI、Atlas CLI、および Atlas Administration API を使用してログをダウンロードできます。詳細については、Atlas の監査とロギングに関するガイダンスを参照してください。 |

Atlasの監視とアラートに関する推奨事項
単一リージョンの配置では、DataDog や Prometheus などのサードパーティのアラート ツールとの統合に関して特に考慮すべき点はありません。詳細については、「すべての配置パラダイムの推奨事項」をご覧ください。
マルチリージョンクラスターでは、リージョン間でログやメトリクスを送信する際に発生する可能性のあるデータ転送コストを考慮する必要があります。生成されたリージョンにログを保持するなどの方法により、データ転送が最小限になるようにログ記録と監査システムを構成することをお勧めします。
すべての配置パラダイムに共通する推奨事項
以下の推奨事項は、すべての配置パラダイムに適用されます。
メトリクスを使用して監視する
クラスターまたはデータベースのパフォーマンスを監視するには、履歴スループット、パフォーマンス、使用率メトリクスなどのクラスター メトリクスを確認できます。次の表には、メトリクスのカテゴリのうち監視すべき重要なものがいくつか(全部でなく)示されています。
Atlas クラスターの操作と接続メトリクス |
|
ハードウェア メトリクス |
|
レプリケーション メトリクス |
|
Atlas クラスター メトリクスを表示するには、 Atlas UI、 Atlas Administration API、および Atlas CLI を使用できます。さらに、Atlas は Datadog や Prometheus などのサードパーティ ツールとの組み込み統合を提供しており、Atlas Administration API を活用して他のカスタム メトリクス ツールと統合することもできます。
詳しくは、「 クラスター メトリクスを確認する 」を参照してください。
アラートを設定して監視する
Atlas は既存のオブザーバビリティ スタックに統合されるため、現在のツールを置き換えたりワークフローを変更したりせずにアラートを受け取り、データに基づいた意思決定を行うことができます。また、Microsoft Teams、PagerDuty、DataDog、Opsgenie、Splunk On-Call、その他のサードパーティ ツールを使用してアラート通知を送信し、データベースとフルスタックの両方のパフォーマンスを一か所で可視化できます。
セキュリティ イベント(ログイン試行の失敗、異常なアクセス パターン、データ侵害まど)に対してアラートと通知を設定します。開発およびテスト環境で 7 日以上アクティブでない状態が続いているクラスターにアラートを構成することをお勧めします。シャットダウンの可能性のあるクラスターが特定しやすくなるため、コストを節約できるためです。
Atlas UIでアラートを表示するときは、利用可能な フィルター を使用して、ホスト、レプリカセット、クラスター、シャードなどで結果を制限し、最も重要なアラートに焦点を当てることをお勧めします。
推奨される Atlas アラート設定
少なくとも、次のアラートを構成することをお勧めします。これらのアラートの推奨事項はベースラインを提供しますが、ワークロードの特性に基づいて調整する必要があります。次の表で「高優先順位」条件が指定されている場合は、同じ条件に対して複数のアラートを構成することをお勧めします。1 つは優先順位度の低いアラートで、1 つの重大度の高い優先順位を構成します。これにより、それぞれのアラート通知設定を個別に構成できます。
Atlas は、一部のアラートをデフォルトで構成します。デフォルトアラートの設定については、「デフォルトのアラート設定」を参照してください。
条件 | 推奨アラートしきい値: 低優先順位 | 推奨アラートしきい値: 高優先順位 | 重要なインサイト |
|---|---|---|---|
oplog window | 24 時間以内に 5 分間 | 1 時間以内に 10 分間 | レプリケーション oplog window とレプリケーションのヘッドルームをモニターして、セカンダリがすぐに完全再同期を必要とするかどうかを判断する。レプリケーション oplog window は、計画停止および予期しない停止に対するセカンダリの回復力を事前に判断するのに役立つことが多い。 |
選挙 イベント | >5 分間は 3 | >5 分間は 30 | プライマリノードが降格し、セカンダリノードが新しいプライマリとして選出されたときに発生する選挙イベントを監視します。頻繁に選挙イベントが発生すると、オペレーションが中断され、可用性に影響を与え、一時的に書き込みができなくなり、データのロールバックが発生する可能性があります。選挙イベントを最小限に抑えることで、一貫した書き込み操作と安定したクラスターのパフォーマンスを確保できます。 |
IOPS を読む | >2 分間は 4000 | >5 分間は 9000 | ディスク IOPS が最大プロビジョニングされた IOPS に近づくかどうかを監視します。 クラスターが将来のワークロードを処理できるかどうかを判断してください。 |
書込み IOPS | >2 分間は 4000 | >5 分間は 9000 | ディスク IOPS が最大プロビジョニングされた IOPS に近づくかどうかを監視します。 クラスターが将来のワークロードを処理できるかどうかを判断してください。 |
読み取りレイテンシ | 5 分間で 20 ミリ秒超 | > 50 秒(5 分) | ディスクのレイテンシを監視して、ディスクからの読み取りとディスクへの書き込みの効率性を追跡します。 |
書き込みレイテンシ | 5 分間で 20 ミリ秒超 | 50ミリ秒を超えて5分以上 | ディスクのレイテンシを監視して、ディスクからの読み取りとディスクへの書き込みの効率性を追跡します。 |
スワップの使用 | > 2 GBで 15 分 | > 2 GBで 15 分 | メモリを監視して、より高いクラスター階層にアップグレードするかどうかを判断します。このメトリクスは、メトリクスの粒度によって指定された期間における平均値を表します。 |
ホストがダウンしています | 15 分 | 24 時間 | ホストを監視して、ダウンタイムを迅速に検出します。15 分を超えてホストがダウンすると可用性に影響可能性があり、ダウンタイムが 24 時間を超えると重要で、データアクセスとアプリケーションのパフォーマンスにリスクが生じます。 |
プライマリなし | 5 分 | 5 分 | レプリカセットのステータスを監視して、 プライマリノードがないインスタンスを特定します。5 分以上プライマリが存在しない場合は、書込み操作が停止し、アプリケーションの機能に影響可能性があります。 |
アクティブでない | 15 分 | 15 分 | アクティブな |
ページ フォールト | 5分間で 50 回/秒を超える | 5分間で 100 回/秒を超える | ページフォールトをモニターして、メモリを増やす必要があるかどうかを判断。このメトリクスは、選択したサンプル期間中におけるこのプロセスのページフォールトの 1 秒あたりの平均レートを表示。Windows 以外の環境では、ハードページフォルトにのみ適用。 |
レプリケーションラグ | >5 分は 240 秒 | 1 時間で 5 分超 | レプリケーション ラグを監視して、セカンダリが oplog から削除される可能性があるかどうかを判断します。 |
バックアップの失敗 | で発生した | なし | バックアップ操作を追跡して、データの整合性を確保します。バックアップに失敗すると、データの可用性が損なわれる可能性があります。 |
復元されたバックアップ | で発生した | なし | 復元されたバックアップを検証して、データの整合性とシステム機能を確保します。 |
フォールバック スナップショットが失敗 | で発生した | なし | フォールバック スナップショット操作を監視し、データの冗長性と回復機能を確保します。 |
バックアップ スケジュールが遅延しています | > 12 時間 | > 12 時間 | バックアップスケジュールが追跡していることを確認します。が遅れると、データが失われるリスクがあり、リカバリプランに影響が出る可能性があります。 |
キューされた読み取り | > 0-10 | > 10+ | キューで読み取りを監視して、効率的なデータ取得を確保します。キューに入れられた読み取りのレベルが高い場合は、リソースの制約やパフォーマンスのボトルネックが発生している可能性があり、システムの応答性を維持するために最適化が必要です。 |
キューされた書き込み | > 0-10 | > 10+ | 効率的なデータ処理を維持するために、キューされた書き込み (write)を監視します。キューされた書き込み (write) のレベルが高い場合、リソースの制約やパフォーマンスのボトルネックを示す可能性があり、システムの応答性を維持するために最適化が必要です。 |
過去 1 時間の再起動 | > 2 | > 2 | 過去 1 時間の再起動数を追跡して、不安定や構成の問題を検出します。頻繁に再起動する場合は、システムの信頼性とアップタイムを維持するために即座の調査が必要な基礎となる問題を示している可能性があります。 |
で発生した | なし | プライマリ選挙を監視して、安定したクラスター操作を確保します。頻繁に選択される場合は、ネットワークの問題やリソースの制約を示している可能性があり、データベースの可用性とパフォーマンスに影響を与える可能性があります。 | |
メンテナンスが不要になりました | で発生した | なし | 不要なメンテナンス タスクを検討して、リソースを最適化し、中断を最小限に抑えます。 |
メンテナンスが開始されました | で発生した | なし | メンテナンス タスクの開始を追跡し、計画されたアクティビティが円滑に進むことを確認します。適切な監視は、システムのパフォーマンスを維持し、メンテナンス中のダウンタイムを最小限に抑える上で役立ちます。 |
メンテナンスが予定されています | で発生した | なし | スケジュールされたメンテナンスを監視し、潜在的なシステムへの影響に備えましょう。 |
>5 分間は 5% | >5 分間は 20% | Burstable Performance で AWS EC2 クラスターの CPU steal を監視して、共有コアが原因で CPU 使用率が保証されたベースラインを超えたタイミングを特定します。steal 率が高いということは、CPU クレジット バランスが枯渇しており、パフォーマンスに影響を与えていることを示しています。 | |
CPU | >5 分間は 75% | >5 分間は 75% | CPU 使用率を監視して、データがメモリではなくディスクから取得されているかどうかを判断します。 |
ディスクパーティションの使用状況 | 90% 超 | >5 分間は 95% | ディスク パーティションの使用状況を監視して、十分なストレージの可用性を確保します。使用レベルが高いと、パフォーマンスの低下やシステム停止の可能性があります。 |
詳細については、「 アラートの設定と解決 」を参照してください。
Atlas の組み込みツールを使用して監視する
Atlas は、データベースのパフォーマンスを積極的に監視し改善するためのいくつかのツールを提供します。
リアルタイムのパフォーマンスパネル
Atlas UIの リアルタイム パフォーマンス パネル(RTPP)は、現在のネットワーク トラフィック、データベース操作、およびホストに関するハードウェア統計に関するインUIを 1 秒単位で提供します。 RTPP を使用して、次の操作を行うことをお勧めします。
関連するデータベース操作を視覚的に識別する
クエリの実行時間を評価する
スキャンされたドキュメントと返されたドキュメントの比率を評価する
ネットワークの負荷とスループットを監視する
レプリカ セットのセカンダリ メンバーで発生する可能性のあるレプリケーションラグを検出する
操作が完了する前に強制終了して価値のあるリソースを解放する
RTPP は Atlas Administration APIからの監視には使用できませんが、Update One Project Settings を使用して Atlas Administration APIから RTPP を有効および無効にすることができます。
詳細については、「リアルタイム パフォーマンスの監視」を参照してください。
Query Profiler
クエリプロファイラーは、遅いクエリやボトルネックを特定し、データベースのパフォーマンスを向上させるためにインデックスの最適化やクエリの再構築を提案します。これにより、Atlas UI で 24 時間のウィンドウにおいて最も遅い操作が可視化され、クエリ効率の傾向や外れ値を特定しやすくなります。このデータを用いて、パフォーマンスの低いクエリを特定し、トラブルシューティングを行うことで、パフォーマンスのオーバーヘッドを削減することを推奨します。
低速クエリを返す を使用すると、クエリプロファイラーが Atlas Administration APIから識別する低速クエリのログ行を返すことができます。
詳細については、「Query Profiler によるクエリパフォーマンスの監視」を参照してください。
Performance Advisor
Performance Advisor は、実行速度が遅いクエリのログを自動的に分析し、インデックスの作成および削除を推奨します。遅いクエリを分析し、計算された影響スコアでランク付けされ、ワークロードに合わせた個々のコレクションについてインデックスを推奨します。これにより、影響の大きいパフォーマンスを簡単かつ瞬時に改善できます。オーバーヘッドを最小限に抑えるために、定期的に監視し、遅いクエリに焦点を当て、プロファイラーを選択的に有効にすることを推奨します。
Atlas UI、Atlas CLI、および Atlas 管理APIを使用して、 Performance Advisor からクエリのパフォーマンスを向上させるための低速クエリと提案を表示できます。
低速クエリを返す と、Atlas Administration APIから Performance Advisor が識別する低速クエリのログ行を返すことができます。Atlas Administration APIで推奨インデックスなどを返すには、Performance Advisor を参照してください。
詳細については「Performance Advisor による遅いクエリの監視と改善」を参照してください。
名前空間のインサイト
Atlas UI の「名前空間インサイト」ページでは、コレクションレベルのパフォーマンスと使用状況のメトリクスを監視できます。モニタリング用に固定したコレクションの特定のホストや操作タイプに関するメトリクス(コレクションの CRUD 操作の数など)と統計情報(平均クエリ実行時間など)が表示されます。これにより、コレクションレベルのパフォーマンスをより詳細に可視化できるため、データベースのパフォーマンスを最適化し、問題を解決し、スケーリング、インデックス作成、クエリ調整に関する決定を行うことができます。
詳細については、「Namespace Insights を使用したコレクションレベルのクエリレイテンシのモニター」をご覧ください。
アクティビティ フィード
Atlas UI の組織アクティビティフィードとプロジェクト アクティビティフィードには、それぞれ特定の Atlas 組織またはプロジェクトで発生するすべてのイベントが一覧表示されます。各アクティビティフィードをイベント タイプと時間範囲でフィルタリングして、API アクセスの更新やアラート構成の変更などのイベントをモニターできます。これにより、組織またはプロジェクトのアクティビティ レコードを必要な粒度で確認できます。
Atlas UI、Atlas CLI、Atlas 管理API を使用して、各アクティビティフィードからイベントを取得します。詳細については、「アクティビティ フィードを表示」をご覧ください。
ログを使用して監視する
Atlas は、過去 30 日間のログ メッセージとシステム イベント監査メッセージを保持します。Atlas ログは、Atlas UI、Atlas Administration API、および Atlas CLI を使用して、保持期間が終了するまでいつでもダウンロードできます。
詳しくは、「MongoDB ログの表示とダウンロード」を参照してください。
AWS S3 バケットにログをエクスポートすることもできます。この機能を構成すると、Atlas はmongod 、mongos 、および監査するログからAWS S3 バケットに 1 分ごとにエクスポートします。
オートメーションの例: Atlas の監視とロギング
次の例では、Atlas のオートメーションツールを使用してモニタリングを有効にする方法を示しています。
クラスター メトリクスの表示
次のコマンドを実行して、指定したディスクの使用済みスペースと空きスペースの量を検索します。このメトリクスは、システムの空きスペースが不足しているかどうかを判断するために使用できます。
atlas metrics disks describe atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 data \ --granularity P1D \ --period P1D \ --type DISK_PARTITION_SPACE_FREE,DISK_PARTITION_SPACE_USED \ --projectId 6698000acf48197e089e4085 \
アラートの構成
配置にプライマリがない場合に、メールアドレスにアラート通知を作成するには、次のコマンドを実行します。
atlas alerts settings create \ --enabled \ --event "NO_PRIMARY" \ --matcherFieldName CLUSTER_NAME \ --matcherOperator EQUALS \ --matcherValue ftsTest \ --notificationType EMAIL \ --notificationEmailEnabled \ --notificationEmailAddress "myName@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
データベースパフォーマンスの監視
次のコマンドを実行して、プロジェクトで Atlas が管理する低速操作のしきい値を有効にします。
atlas performanceAdvisor slowOperationThreshold enable --projectId 56fd11f25f23b33ef4c2a331
ログのダウンロード
次のコマンドを実行して、プロジェクト内の指定されたホストのMongoDBログを含む圧縮ファイルをダウンロードします。
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Atlas Go SDK を使用して例のスクリプトを認証・実行する前に、次の手順を実行する必要があります。
Atlas サービス アカウントを作成します。ターミナルで次のコマンドを実行して、クライアント ID とシークレットを環境変数として保存します。
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Go プロジェクトで次の構成変数を設定します。
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
クラスター メトリクスの表示
次の例のスクリプトには、指定されたディスク上の使用済み領域と空き領域の量の検索方法が示されています。このメトリクスを使ってシステムの空き領域が十分かどうかを判断できます。
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.development" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch disk metrics with the provided parameters p := &admin.GetDiskMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, PartitionName: "data", M: &[]string{"DISK_PARTITION_SPACE_FREE", "DISK_PARTITION_SPACE_USED"}, Granularity: admin.PtrString("P1D"), Period: admin.PtrString("P1D"), } view, err := metrics.FetchDiskMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch disk metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
ログのダウンロード
次の例のスクリプトには、Atlas プロジェクトの指定ホスト用 MongoDB ログを含む圧縮ファイルをダウンロードして解凍する方法が示されています。
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Tip
すべてのピリオドにわたって推奨事項を強制する Terraform の例については、 Githubの次のいずれかの例を参照してください。
Terraform でリソースを作成する前に、次の手順を実行する必要があります。
支払い組織を作成し、その支払い組織の API キーを作成します。ターミナルで次のコマンドを実行して、API キーを環境変数として保存します。
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
アラートの構成
次の例は、アラートとアラート通知の構成方法を示しています。の例ごとに次のファイルを作成する必要があります。各例のファイルを 独自のディレクトリに配置します。ID と名前を変更して、 値を使用します。
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster"
例: 次の を使用して、レプリケーションラグが発生し、データの不整合が発生する可能性がある場合に、GROUP_CLUSTER_MANAGER ロールを持つユーザーにメールでアラート通知を送信します。
main.tf
resource "mongodbatlas_alert_configuration" "test" { project_id = var.atlas_project_id event_type = "REPLICATION_OPLOG_WINDOW_RUNNING_OUT" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } threshold_config { operator = "LESS_THAN" threshold = 1 units = "HOURS" } }
クラスター メトリクスの表示
次のメトリクスを取得するには、サンプルコマンドを実行します。
OPCOUNTERS - ピーク負荷時に発生するクエリ、更新、挿入、削除の量をモニターし、負荷が想定範囲を超えて増加しないようにします。
CONNECTIONS - メンバー間のハートビートとレプリケーションに使用されるソケット数が、所定の制限値を超えないようにします。
QUERY TARGETING - スキャンされたキーとドキュメントの数と、返されるドキュメント数の比率(平均秒数)が過大にならないようにします。
システム CPU - CPU 使用率が安定していることを確認してください。
GLOBAL LOCK QUEUE - 現在キューで読み取りと書込みのロックを待機している読み取りと書き込み操作の数をモニターし、負荷が想定範囲を超えて増加しないようにします。
atlas metrics processes atlas-lnmtkm-shard-00-00.ajlj3.mongodb.net:27017 \ --projectId 56fd11f25f23b33ef4c2a331 \ --granularity PT1H \ --period P7D \ --type OPCOUNTER_DELETE,OPCOUNTER_INSERT,OPCOUNTER_QUERY,OPCOUNTER_UPDATE,CONNECTIONS,QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED,QUERY_TARGETING_SCANNED_PER_RETURNED,SYSTEM_CPU_GUEST,SYSTEM_CPU_IOWAIT,SYSTEM_CPU_IRQ,SYSTEM_CPU_KERNEL,SYSTEM_CPU_NICE,SYSTEM_CPU_SOFTIRQ,SYSTEM_CPU_STEAL,SYSTEM_CPU_USER,GLOBAL_LOCK_CURRENT_QUEUE_TOTAL,GLOBAL_LOCK_CURRENT_QUEUE_READERS,GLOBAL_LOCK_CURRENT_QUEUE_WRITERS \ --output json
アラートの構成
プロジェクト内の接続数に基づいて接続ストームが発生する可能性がある場合は、次のコマンドを実行して、グループにメールでアラートを送信します。
atlas alerts settings create \ --enabled \ --event "OUTSIDE_METRIC_THRESHOLD" \ --metricName CONNECTIONS \ --metricOperator LESS_THAN \ --metricThreshold 1 \ --metricUnits RAW \ --notificationType GROUP \ --notificationRole "GROUP_DATA_ACCESS_READ_ONLY","GROUP_CLUSTER_MANAGER","GROUP_DATA_ACCESS_ADMIN" \ --notificationEmailEnabled \ --notificationEmailAddress "user@example.com" \ --notificationIntervalMin 5 \ --projectId 6698000acf48197e089e4085
データベースパフォーマンスの監視
次のコマンドを実行して、低速クエリが発生しているコレクションの推奨インデックスを取得します。
atlas performanceAdvisor suggestedIndexes list \ --projectId 56fd11f25f23b33ef4c2a331 \ --processName atlas-zqva9t-shard-00-02.2rnul.mongodb.net:27017
ログのダウンロード
次のコマンドを実行して、プロジェクト内の指定されたホストのMongoDBログを含む圧縮ファイルをダウンロードします。
atlas logs download cluster0-shard-00-00.a1b2c.mongodb.net mongodb.gz
Atlas Go Infrastructure SDK Githubリポジトリの、1 つのプロジェクトでの Atlas Administration Go SDK の例をすべて参照してください。
Atlas Go SDK を使用して例のスクリプトを認証・実行する前に、次の手順を実行する必要があります。
Atlas サービス アカウントを作成します。ターミナルで次のコマンドを実行して、クライアント ID とシークレットを環境変数として保存します。
export MONGODB_ATLAS_SERVICE_ACCOUNT_ID="<insert your client ID here>" export MONGODB_ATLAS_SERVICE_ACCOUNT_SECRET="<insert your client secret here>" Go プロジェクトで次の構成変数を設定します。
configs/config.json{ "MONGODB_ATLAS_BASE_URL": "https://cloud.mongodb.com", "ATLAS_ORG_ID": "32b6e34b3d91647abb20e7b8", "ATLAS_PROJECT_ID": "67212db237c5766221eb6ad9", "ATLAS_CLUSTER_NAME": "myCluster", "ATLAS_PROCESS_ID": "myCluster-shard-00-00.ajlj3.mongodb.net:27017" }
クライアント の認証と作成の詳細については、 Githubの完全な Atlas SDK for Go例プロジェクトを参照してください。
クラスター メトリクスの表示
次の例のスクリプトには、以下のメトリクスの検索方法が示されています。
OPCOUNTERS - ピーク負荷時に発生するクエリ、更新、挿入、削除の量をモニターし、負荷が想定範囲を超えて増加しないようにします。
CONNECTIONS - メンバー間のハートビートとレプリケーションに使用されるソケット数が、所定の制限値を超えないようにします。
QUERY TARGETING - スキャンされたキーとドキュメントの数と、返されるドキュメント数の比率(平均秒数)が過大にならないようにします。
システム CPU - CPU 使用率が安定していることを確認してください。
GLOBAL LOCK QUEUE - 現在キューで読み取りと書込みのロックを待機している読み取りと書き込み操作の数をモニターし、負荷が想定範囲を超えて増加しないようにします。
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "encoding/json" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/metrics" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch process metrics with the provided parameters p := &admin.GetHostMeasurementsApiParams{ GroupId: cfg.ProjectID, ProcessId: cfg.ProcessID, M: &[]string{ "OPCOUNTER_INSERT", "OPCOUNTER_QUERY", "OPCOUNTER_UPDATE", "TICKETS_AVAILABLE_READS", "TICKETS_AVAILABLE_WRITE", "CONNECTIONS", "QUERY_TARGETING_SCANNED_OBJECTS_PER_RETURNED", "QUERY_TARGETING_SCANNED_PER_RETURNED", "SYSTEM_CPU_GUEST", "SYSTEM_CPU_IOWAIT", "SYSTEM_CPU_IRQ", "SYSTEM_CPU_KERNEL", "SYSTEM_CPU_NICE", "SYSTEM_CPU_SOFTIRQ", "SYSTEM_CPU_STEAL", "SYSTEM_CPU_USER", }, Granularity: admin.PtrString("PT1H"), Period: admin.PtrString("P7D"), } view, err := metrics.FetchProcessMetrics(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch process metrics: %v", err) } // Output metrics out, err := json.MarshalIndent(view, "", " ") if err != nil { log.Fatalf("Failed to format metrics data: %v", err) } fmt.Println(string(out)) }
ログのダウンロード
次の例のスクリプトには、Atlas プロジェクトの指定ホスト用 MongoDB ログを含む圧縮ファイルをダウンロードして解凍する方法が示されています。
// See entire project at https://github.com/mongodb/atlas-architecture-go-sdk package main import ( "context" "fmt" "log" "atlas-sdk-examples/internal/auth" "atlas-sdk-examples/internal/config" "atlas-sdk-examples/internal/fileutils" "atlas-sdk-examples/internal/logs" "github.com/joho/godotenv" "go.mongodb.org/atlas-sdk/v20250219001/admin" ) func main() { envFile := ".env.production" if err := godotenv.Load(envFile); err != nil { log.Printf("Warning: could not load %s file: %v", envFile, err) } secrets, cfg, err := config.LoadAllFromEnv() if err != nil { log.Fatalf("Failed to load configuration %v", err) } ctx := context.Background() client, err := auth.NewClient(ctx, cfg, secrets) if err != nil { log.Fatalf("Failed to initialize authentication client: %v", err) } // Fetch logs with the provided parameters p := &admin.GetHostLogsApiParams{ GroupId: cfg.ProjectID, HostName: cfg.HostName, LogName: "mongodb", } fmt.Printf("Request parameters: GroupID=%s, HostName=%s, LogName=%s\n", cfg.ProjectID, cfg.HostName, p.LogName) rc, err := logs.FetchHostLogs(ctx, client.MonitoringAndLogsApi, p) if err != nil { log.Fatalf("Failed to fetch logs: %v", err) } defer fileutils.SafeClose(rc) // Prepare output paths // If the ATLAS_DOWNLOADS_DIR env variable is set, it will be used as the base directory for output files outDir := "logs" prefix := fmt.Sprintf("%s_%s", p.HostName, p.LogName) gzPath, err := fileutils.GenerateOutputPath(outDir, prefix, "gz") if err != nil { log.Fatalf("Failed to generate GZ output path: %v", err) } txtPath, err := fileutils.GenerateOutputPath(outDir, prefix, "txt") if err != nil { log.Fatalf("Failed to generate TXT output path: %v", err) } // Save compressed logs if err := fileutils.WriteToFile(rc, gzPath); err != nil { log.Fatalf("Failed to save compressed logs: %v", err) } fmt.Println("Saved compressed log to", gzPath) // Decompress logs if err := fileutils.DecompressGzip(gzPath, txtPath); err != nil { log.Fatalf("Failed to decompress logs: %v", err) } fmt.Println("Uncompressed log to", txtPath) }
Tip
すべてのピリオドにわたって推奨事項を強制する Terraform の例については、 Githubの次のいずれかの例を参照してください。
Terraform でリソースを作成する前に、次の手順を実行する必要があります。
支払い組織を作成し、その支払い組織の API キーを作成します。ターミナルで次のコマンドを実行して、API キーを環境変数として保存します。
export MONGODB_ATLAS_PUBLIC_KEY="<insert your public key here>" export MONGODB_ATLAS_PRIVATE_KEY="<insert your private key here>"
アラートの構成
次の例は、アラートとアラート通知の構成方法を示しています。の例ごとに次のファイルを作成する必要があります。各例のこれらのファイルは独自のディレクトリに配置し、main.tfファイルのみを置き換えます。ID と名前を変更して、 値を使用します。
variables.tf
variable "atlas_org_id" { type = string description = "MongoDB Atlas Organization ID" } variable "atlas_project_name" { type = string description = "The MongoDB Atlas Project Name" } variable "atlas_project_id" { description = "MongoDB Atlas project id" type = string } variable "atlas_cluster_name" { description = "MongoDB Atlas Cluster Name" default = "datadog-test-cluster" type = string } variable "datadog_api_key" { description = "Datadog api key" type = string } variable "datadog_region" { description = "Datadog region" default = "US5" type = string } variable "prometheus_user_name" { type = string description = "The Prometheus User Name" default = "puser" } variable "prometheus_password" { type = string description = "The Prometheus Password" default = "ppassword" }
terraform.tfvars
atlas_org_id = "32b6e34b3d91647abb20e7b8" atlas_project_name = "Customer Portal - Prod" atlas_project_id = "67212db237c5766221eb6ad9" atlas_cluster_name = "myCluster" datadog_api_key = "1234567890abcdef1234567890abcdef" datadog_region = "US5" prometheus_user_name = "prometheus_user" prometheus_password = "secure_prometheus_password"
1 の例: 次の手順を使用して、アラート通知のために Datadog や Prometheus などのサードパーティ サービスと統合します。
main.tf
resource "mongodbatlas_third_party_integration" "test_datadog" { project_id = var.atlas_project_id type = "DATADOG" api_key = var.datadog_api_key region = var.datadog_region } resource "mongodbatlas_third_party_integration" "test_prometheus" { project_id = var.atlas_project_id type = "PROMETHEUS" user_name = var.prometheus_user_name password = var.prometheus_password service_discovery = "http" enabled = true } output "datadog.id" { value = mongodbatlas_third_party_integration.test_datadog.id } output "prometheus.id" { value = mongodbatlas_third_party_integration.test_prometheus.id }
2 の例: 次の を使用して、レプリカセットにプライマリが 5 分以上存在しない場合に、Datadog や Prometheus などのサードパーティ サービスにアラート通知を送信します。
main.tf
resource "mongodbatlas_alert_configuration" "test_alert_notification" { project_id = var.atlas_project_id event_type = "NO_PRIMARY" enabled = true notification { type_name = "PROMETHEUS" integration_id = mongodbatlas_third_party_integration.test_datadog.id # ID of the Atlas Prometheus integration } notification { type_name = "DATADOG" integration_id = mongodbatlas_third_party_integration.test_prometheus.id # ID of the Atlas Datadog integration } matcher { field_name = "REPLICA_SET_NAME" operator = "EQUALS" value = "myReplSet" } threshold_config { operator = "GREATER_THAN" threshold = 5 units = "MINUTES" } }
3 の例: 次の を使用して、レプリケーションラグが発生し、データの不整合が発生する可能性がある場合に、GROUP_CLUSTER_MANAGER ロールを持つユーザーにメールでアラート通知を送信します。
main.tf
resource "mongodbatlas_alert_configuration" "test_replication_lag_alert" { project_id = var.atlas_project_id event_type = "OUTSIDE_METRIC_THRESHOLD" enabled = true notification { type_name = "GROUP" interval_min = 10 delay_min = 0 sms_enabled = false email_enabled = true roles = ["GROUP_CLUSTER_MANAGER"] } matcher { field_name = "CLUSTER_NAME" operator = "EQUALS" value = "myCluster" } metric_threshold_config { metric_name = "OPLOG_SLAVE_LAG_MASTER_TIME" operator = "GREATER_THAN" threshold = 1 units = "HOURS" } }