マルチリージョン Atlas 配置とは、複数のリージョンにまたがって設定されるクラスターです。マルチリージョン配置では、同じ地理的条件内に複数のリージョン(大陸や国のような大きな面積)内に複数のリージョンが存在する場合、または複数の地理的領域にある複数のリージョンが存在する場合があります。マルチリージョン配置:
リージョン停止時が発生した場合に、トラフィックを自動的に別のリージョンにルーティングして保護を強化し、継続的な可用性とスムーズなユーザー エクスペリエンスを実現します。
データがユーザーの近くに配置されるため、一部のアプリケーションでパフォーマンスと可用性が向上します。
マルチリージョン配置の適否を検討する際は、アプリケーションの重要性を評価するだけでなく、そうした評価と RTO/RPO 要件との対応関係も評価する必要があります。回復力を達成する手段は、マルチリージョン配置でダウンタイムをゼロにする方法から、単一リージョン配置でバックアップ予定を複数用意する方法にまで及び、可用性とコストには二率相反関係があります。
マルチリージョン配置がワークロードに適しているかどうかに関する詳細なガイダンスについては、「信頼性」セクションを参照してください。
注意
マルチリージョン配置は、M10 以上の専用クラスターでのみ使用できます。
マルチリージョン配置戦略
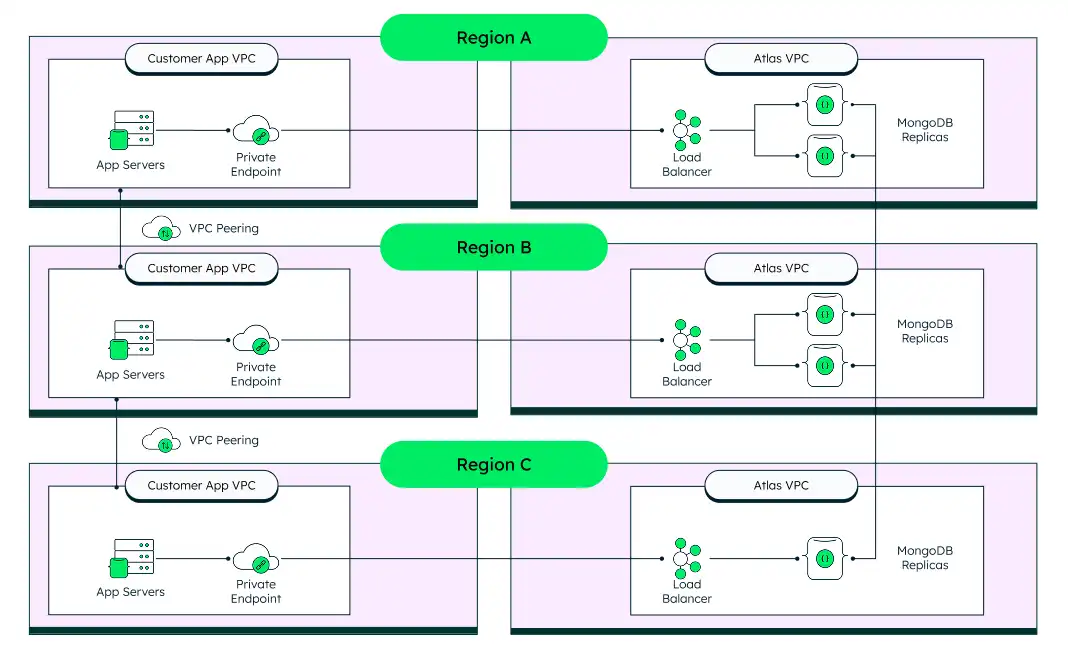
次の図には、2+2+1トポロジーの 2 の例が示されています。これについて詳しくは、以下で詳しく説明します。[5]5 3の異なるリージョンに ノードを含む単一クラスターが表示されます。2 US12US2の ノード、1 の ノード、 のUS3 ノード。


5-ノード、3-リージョン アーキテクチャ(2+2+1)
当社は、リージョンの停止時にほぼ瞬時に復旧するために、3 つのリージョンに 5 つ以上のノードを分散させる構成のアーキテクチャを推奨しています。このアーキテクチャにすると、第 2 リージョンへのフェイルオーバーを強制することなく定期的なメンテナンス操作を実行可能であるうえ、リージョン全域で機能が停止したときには自動フェイルオーバーが確実に実行されて、データ消失を防ぐこともできます。
次の図は、このアーキテクチャの詳細を示しています。

メモと考慮事項
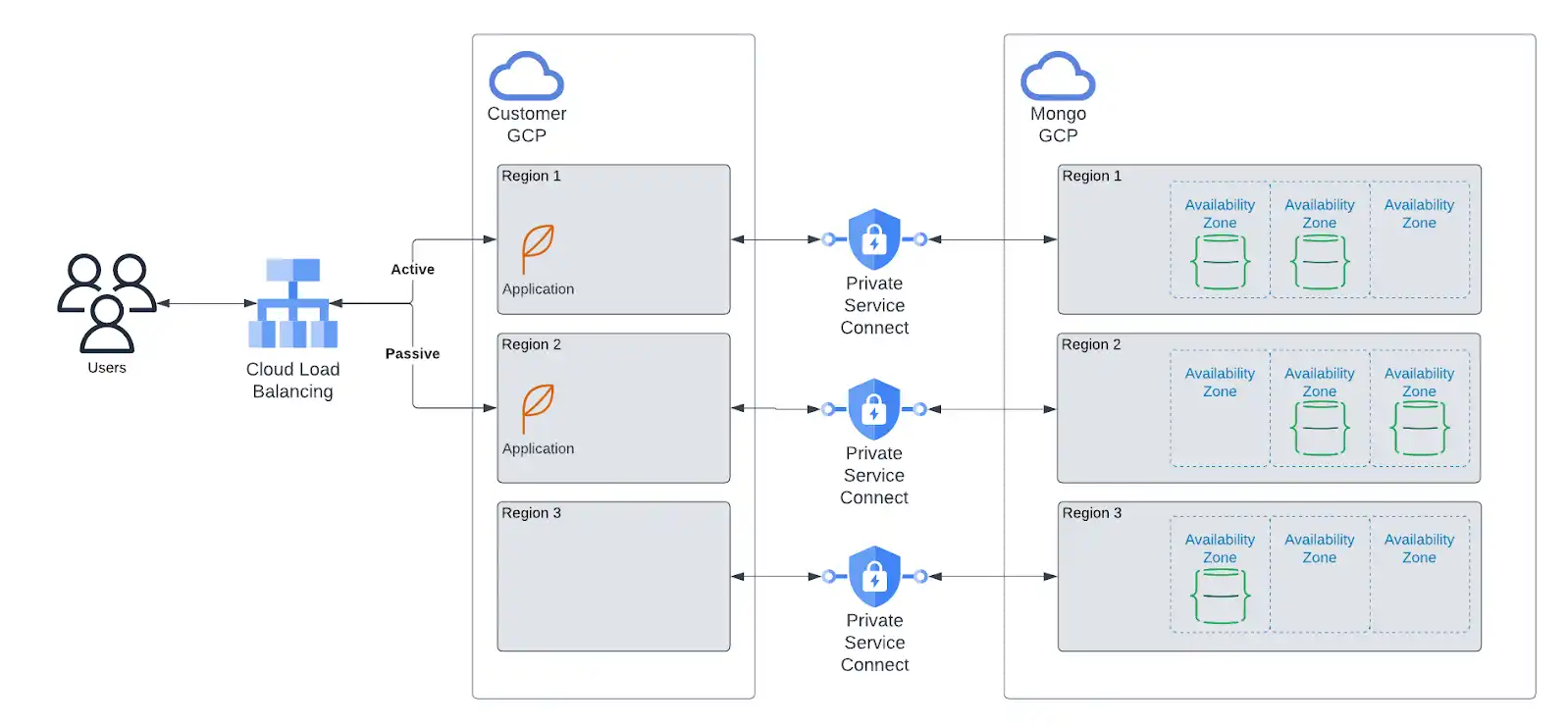
プライベートエンドポイント を使用してクラスターと、アプリケーションサーバーVPC 間のVPCピアリングに接続します。VPCピアリングにより、ネットワーク接続が中断された場合でも、そのリージョンの Atlas がダウンした場合でも、アプリケーション層は引き続き プライマリノードにルーティングでき、最初はVPCピアリング、次にプライベートエンドポイントを経由します。
このアーキテクチャでは、リージョン間のネットワーク トラフィックと 5 以上のデータを保持するノードがあるため、コストが最も高くなります。
このアーキテクチャは、最高の回復力を提供します。Atlas の操作中に中断されることはありません(自動アップグレードなど)。アプリケーションは、中断や手動介入を必要とせずに、完全なリージョン障害を維持できます。
このアーキテクチャでは、リージョン間のネットワーク トラフィックと 5 以上のデータを保持するノードがあるため、コストが最も高くなります。
5-ノード、2-リージョン アーキテクチャ(2+3)
リージョン数が 2 つのみに制限される場合、5 ノード、3 リージョンのアーキテクチャでバリエーションを使用できます。このアーキテクチャでは、5 ノードが2つのリージョンに分散されます。プライマリ リージョンには 2 個の選挙可能なノードがあり、セカンダリ リージョンには 1 個の選挙可能なノードと 2 個の読み取り専用(非投票)ノードがあります。
過半数のリージョンが失敗した場合にオペレーターがフェイルオーバーオーバーを手動で中断する必要があるため、3 リージョンを使用できる場合は通常推奨されません。ただし、承認されたリージョンが 2 のみのカスタマーのオプションです。

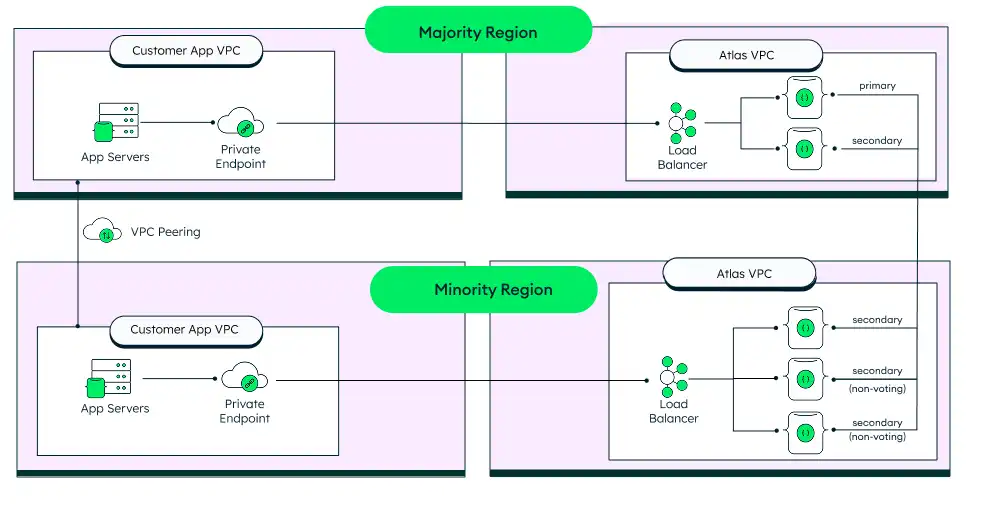
メモと考慮事項
このアーキテクチャにすると、データの消失保護が強化されます。プライマリ リージョンで障害が発生した場合は、セカンダリ リージョンでクラスターが完全に機能し続けるため、対応する必要はありません。プライマリ リージョンでは、障害が発生した場合でも、ノードの大半が選挙可能な状態になるまで、システムは読み取り専用モードで稼働し続けます。ただし、障害発生後に一部のデータがセカンダリ ノードに複製されていない場合、データ消失から完全に保護されない可能性があります。この場合、そのデータはプライマリ リージョンが復旧するまで利用できません。
このアーキテクチャには次のとおり注意点がいくつかあります。
過半数リージョンが失われると、少数リージョンは完全に機能するクラスターではなくなります。プライマリがないため、読み取りのみを受け入れることができますが、書込みはできません。
投票権のあるノードの過半数が存在しないため、プライマリはなく、読み取りのみを受け入れることができます(書込みはしない)。
機能クラスターを復元するには、管理者が 2 つの読み取り専用ノードを選挙可能なノードに再構成する必要があります。ただし、データ消失のリスクがあります。機能停止中、セカンダリへの新規の書き込みはすべて、手動復旧用の特別なコレクションに保存されます。ただし、プライマリに書き込まれたデータがその停止前にいずれかのセカンダリに複製されなかった場合、そのデータは消失します。詳細については、「リージョン停止時のレプリカセットの再構成」をご覧いただくか、API パラメーター「acceptDataRisksAndForceReplicaSetReconfig」を使用してください。
シャーディングされたクラスターでは、MongoDB プロセスでチャンクの移行が複製されなかった場合、データが整合しなくなり孤立したドキュメントが発生する可能性があります。
低コストのバリエーション
さらにコストを節約するには、2 読み取り専用ノードを使用せずにこのアーキテクチャを設計できます。上記に記載された警告に加えて、クラスターに新しいノードを追加するたびにデータをセカンダリに同期する必要があるため、データサイズは決定に大きな影響を与えます。例、1 TB のデータは平均 1 時間の復元と同期時間になります。少数リージョンに 2 の読み取り専用ノードを用意することをお勧めします。これらはすでに完全に同期されており、完全に機能するクラスターへの回復には 秒から 分しかないためです。
3-ノード、3-リージョン アーキテクチャ(1+1+1)
中断を許容できるクリティカルではないワークロードの場合は、各 3 リージョンで 1ノードを使用することで、より低コストのアーキテクチャを活用できます。各リージョンに選挙可能な ノードがあるため、プライマリノードが使用できない場合は、クラスターは新しいリージョンにフェイルオーバーして、継続的な可用性を確保します。ただし、元のプライマリ リージョンのアプリ階層が引き続きユーザーのリクエストを処理している場合は、リクエストが複数のリージョンにルーティングされるため、レイテンシが増加します。さらに、ノードを再構築する 場合には、最適化された最初の同期を実行する能力はありません。
注意
Atlas ノードの定期的かつ計画的なメンテナンスにより一時的なレイテンシの急増が発生するため、通常この構成は推奨されません。
マルチリージョン配置に関する推奨事項
マルチリージョン配置の設定方法、および追加可能な各種ノードについては、Atlas ドキュメント「高可用性とワークロード分離の設定」を参照してください。
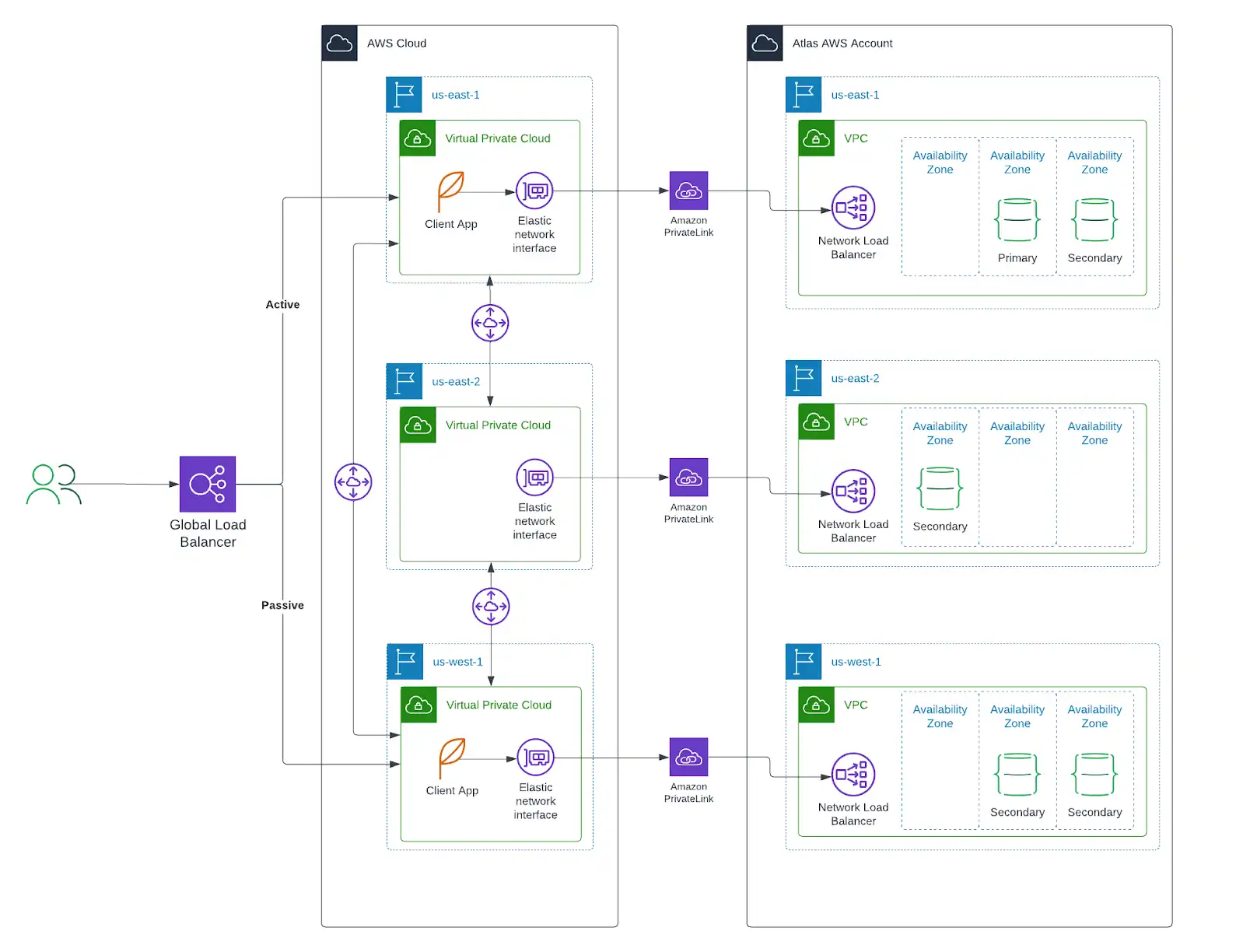
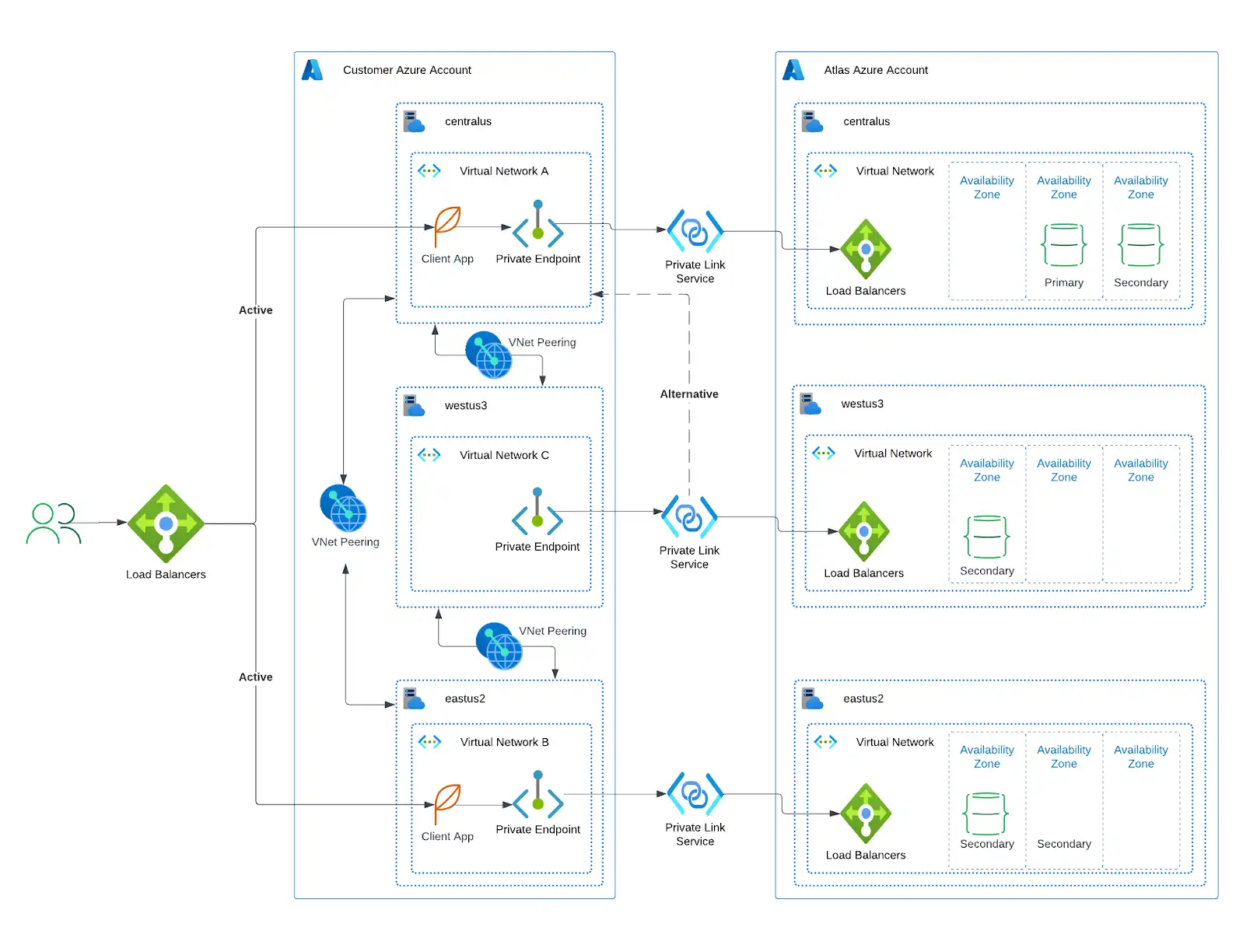
アプリケーションが次のいずれかのクラウドプロバイダーに配置されている場合、MongoDB は Atlas リソースを同じプロバイダーおよびリージョンに配置することを強く推奨します。さらに、以下に示すように、アプリケーションリソースのリージョン間の配置を Atlas リソースの配置に対応付けることを推奨します。
Atlas リソースと併せたアプリケーションリソースの配置:
アプリケーションによって実行されるデータベース操作のレイテンシを削減します。
自己管理型クラウドリソースを Atlas リソースに接続するプライベートエンドポイントにより、セキュリティを強化できます。プライベートエンドポイントは最高レベルのネットワークセキュリティを提供し、トラフィックがユーザーのアカウントからのみ開始されることを保証します。
リージョン固有のデータストレージに対して、よりきめ細かな制御が可能です。
他のリージョンで障害が発生した場合に、正常なリージョンへトラフィックを再ルーティングできます。
アプリケーションおよび Atlas の配置推奨事項の詳細については、以下を参照してください。


Atlas クラウド配置の推奨事項については、次のリソースを参照してください。
運用効率
セキュリティ
Reliability
パフォーマンス
コスト最適化