照片出處:CHUTTERSNAP 於 Unsplash 所發佈的
AI 人工智慧為生成式人工智慧所起到的作用
任何 AI 系統(包括生成式人工智慧系統)的有效性和多功能性都取決於訓練該模型時所使用的資料,這些資料的品質、數量和多樣性決定了 AI 系統的有效性和多功能性高低。讓我們看一下資料與生成式人工智慧模型之間的一些關鍵項目。
訓練資料
生成式人工智慧模型會是透過海量資料集來進行訓練的。著重文本相關目的的模型可能會採用數十億篇文章來進行訓練,而著重圖片設計目的的模型則可能會採用數百萬張圖片來進行訓練。大型語言模型會需要各位提供大量的機器學習訓練資料,才能生成呼應情境且合乎情理的內容。資料的多樣化和全面性程度越高,模型理解並產出各式內容的能力也會有所提升。一般來說,資料量越大,模型的產出內容品質也就越高。有了更大量的資料集作為訓練基底,生成式人工智慧模型即可辯別更微妙的模式,從而產出更準確且細緻的成果。但是,資料本身的品質也是極為重要。通常而言,以量小但品質高的資料集所訓練出來的模型通常會比量大但關聯性低的資料集所訓練出來的模型來的優異。
### 原始資料和複雜資料
原始資料,尤其是複雜與尚非結構化的資料,在將這些資料用來訓練模型之前,可能會需要相關人員在資料管道的早期階段進行預先處理。這也是大家可以驗證資料品質的時刻,以確保這些資料合適且沒有存在偏差。此一驗證步驟能夠有效幫各位預先免除偏差或偏差產出。
標記資料與未標記的資料
標記資料可提供各位有關每筆資料的特定資訊(舉凡:圖片附帶的文字說明),而未標記的資料則不會有此類的註記。大多數而言,生成式模型可以搭配未標記資料,這是因為生成式模型仍可透過理解既有的結構和模式來學習該如何產出內容。
專有資料
有些資料是特定企業組織所特有的。舉凡公司的客戶訂單歷史記錄、員工績效指標與任務流程等。許多企業組織會收集這些資料,然後先將這些資料匿名以防止敏感的 PII 或 PHI 資料外洩給下游廠商,然後再進行傳統的資料分析。這些資料中會有大量的資訊,如果用在訓練生成式模型的話,可以更有效深入地發掘這些資料中的細節。產出的成果會根據該企業組織的特別需求來進行調整。
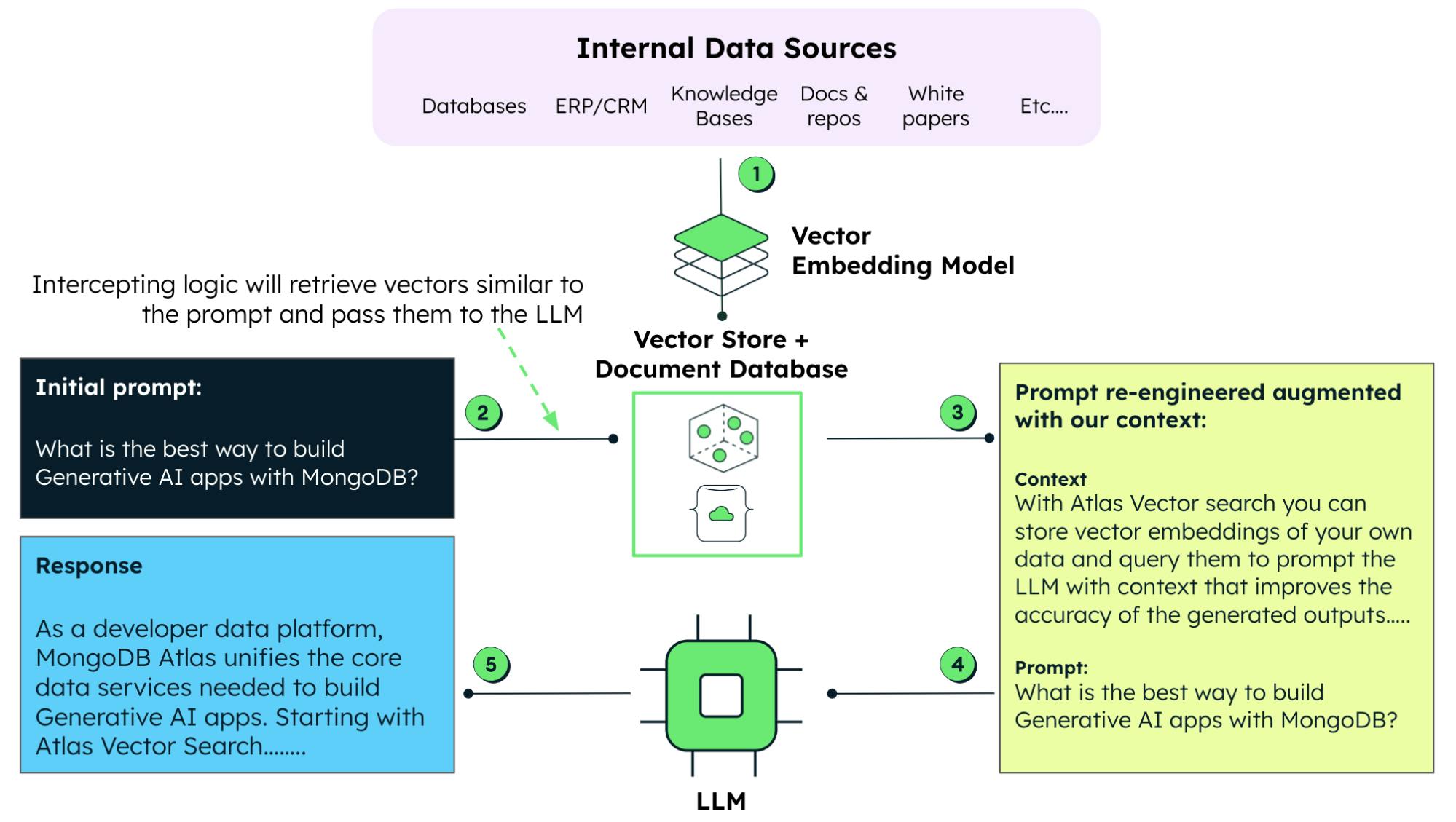
資料在檢索增強生成中所扮演的角色
如上所述,檢索增強生成能將大型語言模型的強大功能與即時資料檢索的機能相結合。有了檢索增強生成,您便不必再仰賴預先訓練時所使用的資料。現在,您可以自外部資料庫即時擷取相關資訊。這樣即可保障生成的內容乃是最新且準確的資料。
如何使用專有資料來強化生成式人工智慧模型?
在使用生成模型時,指令工程指的是透過精心設計特定輸入查詢語言或是指令來指導模型,以期能夠打造更優良的產出內容與回應的技術。有了檢索增強生成,我們可以透過專有資料來強化提示,使 AI 人工智慧模型能夠在將企業資料納入考量的情況下產出相關聯且準確的回覆。與重新使用這筆資料訓練或微調大型語言模型這種耗時耗資源的方法相比,這種方法可取了許多。
挑戰與注意事項
當然,使用生成式人工智慧也是有其挑戰的。如果您的企業組織希望能夠應用 GenAI 的潛力,建議您可以牢記以下幾個關鍵問題。
資料專業知識的需求和強大的電腦運算機能
生成模型會需要大量的資源。首先,您會需要訓練有素的資料科學家和工程師所能帶來的專業知識。除資料組織外,大多數企業都缺乏具有訓練或微調大型語言模型所需的專業技能團隊
在電腦運算資源方面,即使您使用的是強大的 GPU 或 TPU,透過全面資料訓練模型仍可能會需要數周或數月的時間。儘管微調大型語言模型可能不會需要用到像從頭開始訓練大型語言模型那樣多的電腦運算機能,但訓練過程仍會需要使用到大量的資源。耗費資源的大型語言模型訓練與微調任務讓檢索增強生成的功能變成了一種極具吸引力的替代技術,好結合當前(和專有)資料與預先訓練大型語言模型的既有資料。
道德考量
生成式人工智慧的興起也就相關開發和應用所帶來的倫理考量激起了熱烈討論。隨著生成式人工智慧應用程式逐漸變成主流並為公眾所接受,相關對話主要集中在以下幾個主題:
- 如何確保模型公正且無偏差
- 如何防止模型中毒或模型篡改等攻擊事件
- 如何防止假消息的傳播
- 如何防止生成式人工智慧的濫用行為(舉凡深度偽造或產出誤導性資訊)
- 如何定奪保留歸屬
- 如何提高終端使用者的資訊透明度,以便大家知道曉何時是在與生成式人工智慧聊天機器人聊天,而不是在與人類進行交流
與其他AI 人工智慧工具/系統的相比較
生成式人工智慧工具的熱潮和新穎性已然讓其他更多的 AI 人工智慧工具/系統領域相形見絀。許多人會錯誤地認為生成式人工智慧是能夠解決他們一切問題的人工智慧工具。其實不然,生成式人工智慧固然擅長創作全新的內容,但其他的 AI 人工智慧工具可能會比生成式人工智慧更適合肩負特定的任務。與堆棧中的工具一樣,探討生成式人工智慧的優勢時,應與其他工具的優勢進行權衡。
檢索增強生成特有的挑戰
利用檢索增強生成機能來強化大型語言模型的方法固然強大,但各位也會面臨一系列的挑戰。
- 選擇向量資料庫與搜尋的技術:歸根究底,檢索增強生成的效率取決於其快速檢索相關資料的能力。這使得向量資料庫和搜尋技術的選擇成為影響檢索增強生成效能的關鍵決策。
- 資料的一致性:由於檢索增強生成會即時擷取資料,因此,確保向量資料庫是最新且一致與否可說是至關重要。
- 整合複雜性:將檢索增強生成與大型語言模型整合能為您的系統增添一層複雜度。實裝具備檢索增強生成機能的生成式人工智慧可能會需要相對應的專業知識。儘管我們會面臨這些挑戰,檢索增強生成仍為企業組織提供了一種簡單而強大的選項來有效利用其營運和應用程式資料來收集豐富的見解,並為關鍵的任務決策提供了相關資訊。
支援由 GenAI 所驅動之應用程式的 MongoDB Atlas
我們已經揭開了生成式人工智慧的變革潛力,並看到了檢索增強生成所帶來之即時資料的有效強化。將這些技術結合在一起需要一個靈活的資料平臺,該平臺要能提供一套為由 GenAI 驅動之應用程式特別訂定的功能。對於有涉及生成式人工智慧和檢索增強生成領域的企業組織,MongoDB Atlas 將成會是改變世界的領導者。
MongoDB Atlas 的核心功能包含:
- 內建的向量搜尋功能:MongoDB Atlas 內建的原生向量儲存和搜尋功能,確保各位能夠快速且有效地搜尋檢索增強生成的資料,而無需額外的資料庫來處理向量資料。
- 統一的 API 和靈活的文檔模型:MongoDB Atlas 的統一 API 讓開發人員能夠將向量搜尋與其他查詢功能(舉凡結構化搜尋或文字搜尋的功能)相結合。除了這個功能,再結合 MongoDB 的文檔資料模型,將能為您的安排帶來了超乎想像的靈活性。
- 可擴展性、可靠性與安全性:MongoDB Atlas 可提供水平擴展性,好隨著您(和您資料)的增長而輕鬆擴展系統規模。憑藉容錯能力和簡單的水平和垂直擴展機能,無論您的工作負載需求高低,MongoDB Atlas 都能夠確保服務不間斷。當然,MongoDB 也展示了該如何透過啟用領先業界的可查詢資料加密技術來著重安全性的考量。