Qu’est-ce qu’une base de données documentaire ?
Une base de données documentaire (également appelée base de données orientée documents ou magasin de documents) est une base de données qui stocke des informations dans des documents.

Les bases de données orientées documents offrent divers avantages, notamment :
- Un modèle de données intuitif, rapide et facile à manipuler pour les développeurs
- Un schéma flexible permettant au modèle de données d’évoluer selon les besoins changeants des applications
- La possibilité d’effectuer un scaling horizontal
Grâce à ces avantages, les bases de données orientées documents sont des bases de données polyvalentes pouvant être utilisées dans divers cas d’utilisation et secteurs.
Les bases de données orientées documents sont considérées comme des bases de données (ou NoSQL) non relationnelles. Au lieu de stocker les données dans des lignes et colonnes fixes, les bases de données orientées documents utilisent des documents flexibles. Les bases de données orientées documents sont l’alternative la plus populaire aux relational databases tabulaires. En savoir plus sur les bases de données NoSQL
Qu’est-ce que des documents ?
Un document est un enregistrement dans une base de données de documents. Un document stocke généralement des informations sur un objet et ses métadonnées associées.
Les documents stockent les données sous forme de paires clé-valeur. Les valeurs peuvent être de divers types et structures, y compris des chaînes de caractères, des nombres, des dates, des tableaux ou des objets. Les documents peuvent être stockés dans des formats tels que JSON, BSON, et XML.
Voici un document JSON qui stocke des informations sur un utilisateur nommé Tom.
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Collections
Une collection est un groupe de documents. Les collections stockent généralement des documents ayant un contenu similaire.
Tous les documents d’une collection ne doivent pas nécessairement contenir les mêmes champs, car les bases de données orientées documents ont des schémas flexibles. Notez que certaines bases de données orientées documents offrent une validation de schéma. Le schéma peut ainsi être verrouillé de manière optionnelle lorsque cela est nécessaire.
En continuant avec l’exemple ci-dessus, le document contenant des informations sur Tom pourrait être stocké dans une collection nommée users. D’autres documents pourraient être ajoutés à la collection users pour stocker des informations sur d’autres utilisateurs. Par exemple, le document ci-dessous qui stocke des informations sur Donna pourrait être ajouté à la collection users.
{
"_id": 2,
"first_name": "Donna",
"email": "donna@example.com",
"spouse": "Joe",
"likes": [
"spas",
"shopping",
"live tweeting"
],
"businesses": [
{
"name": "Castle Realty",
"status": "Thriving",
"date_founded": {
"$date": "2013-11-21T04:00:00Z"
}
}
]
}Notez que le document pour Donna ne contient pas les mêmes champs que le document pour Tom. La collection users utilise un schéma flexible pour stocker les informations disponibles pour chaque utilisateur.
Opérations CRUD
Les bases de données orientées documents disposent généralement d’une API ou d’un langage de requête qui permet aux développeurs d’exécuter les opérations CRUD (Create, Read, Update et Delete).
- Create : les documents peuvent être créés dans la base de données. Chaque document a un identifiant unique.
- Read : les documents peuvent être lus à partir de la base de données. L’API ou le langage de requête permet aux développeurs d’interroger des documents en utilisant leurs identifiants uniques ou leurs valeurs de champs. Des index peuvent être ajoutés à la base de données pour améliorer les performances de lecture.
- Update : les documents existants peuvent être mis à jour, en totalité ou en partie.
- Delete : les documents peuvent être supprimés de la base de données.
Quelles sont les principales caractéristiques des bases de données orientées documents ?
Les bases de données orientées documents possèdent les caractéristiques principales suivantes :
- Modèle de document : les données sont stockées dans des documents (contrairement à d’autres bases de données qui stockent les données dans des structures telles que des tables ou des graphes). Les documents sont mappés aux objets dans la plupart des langages de programmation populaires, ce qui permet aux développeurs de développer rapidement leurs applications.
- Schéma flexible : les bases de données orientées documents possèdent des schémas flexibles, ce qui signifie que tous les documents d’une collection n’ont pas besoin de contenir les mêmes champs. Notez que certaines bases de données orientées documents prennent en charge la validation du schéma. Le schéma peut ainsi être verrouillé de façon optionnelle.
- Distribuées et résilientes : les bases de données orientées documents sont distribuées, ce qui permet un scaling horizontal (généralement moins coûteux qu’un scaling vertical) et la distribution des données. Les bases de données orientées document offrent une résilience grâce à la réplication.
- Interrogation via une API ou un langage de requête : les bases de données orientées documents disposent d’une API ou d’un langage de requête qui permet aux développeurs d’effectuer les opérations CRUD sur la base de données. Les développeurs ont la possibilité de lancer une requête sur des documents en fonction d’identificateurs uniques ou de valeurs de champ.
Qu’est-ce qui différencie les bases de données orientées documents des relational databases ?
Trois facteurs clés différencient les bases de données orientées documents des relational databases :
1. L’intuitivité du modèle de données : les documents correspondent aux objets dans le code, il est donc beaucoup plus naturel de travailler avec eux. Il n’est pas nécessaire de décomposer les données entre les tables, d’effectuer des jointures coûteuses ni d’intégrer une couche distincte de mappage relationnel-objet (ORM). Les données auxquelles on accède ensemble sont stockées ensemble, ce qui permet aux développeurs d’écrire moins de code et aux utilisateurs finaux de bénéficier de meilleures performances.
2. L’omniprésence des documents JSON : JSON est devenu une norme établie pour les échanges et le stockage de données. Les documents JSON sont légers, indépendants du langage et lisibles par l’homme. Les documents sont un sur-ensemble de tous les autres modèles de données, permettant aux développeurs de structurer les données selon les besoins de leurs applications : objets riches, paires clé-valeur, tables, données géospatiales et de time-series, ou les nœuds et arêtes d’un graphe.
3. La flexibilité du schéma : le schéma d’un document est dynamique et auto-descriptif, de sorte que les développeurs n’ont pas besoin de le prédéfinir dans la base de données. Les champs peuvent varier d’un document à l’autre. Les développeurs peuvent modifier la structure à tout moment, évitant ainsi des migrations de schéma perturbatrices. Certaines bases de données orientées documents offrent une validation de schéma afin que vous puissiez appliquer des règles régissant les structures des documents.
Dans quelle mesure les documents sont-ils plus faciles à manipuler que les tables ?
Les développeurs trouvent généralement que travailler avec des données dans des documents est plus facile et plus intuitif qu’avec des données dans des tableaux. Les documents se mettent en correspondance avec les structures de données dans la plupart des langages de programmation populaires. Les développeurs n’ont pas à se préoccuper de fractionner manuellement les données connexes sur plusieurs tables lors de leur stockage ou de les rassembler lors de leur récupération. Ils n’ont pas non plus besoin d’utiliser un ORM pour gérer la manipulation des données automatiquement. Au lieu de cela, ils peuvent facilement travailler directement avec les données dans leurs applications.
Examinons à nouveau un document pour un utilisateur nommé Tom.
Users
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Toutes les informations concernant Tom sont stockées dans un seul document.
Voyons maintenant comment nous pouvons stocker ces mêmes informations dans une relational database. Nous allons commencer par créer une table qui stocke les informations de base sur l’utilisateur.
Users
| ID | first_name | cell | |
|---|---|---|---|
| 1 | Tom | tom@example.com | 765-555-5555 |
Un utilisateur peut aimer beaucoup de choses (ce qui signifie qu’il existe une relation un-à-plusieurs entre un utilisateur et les mentions « J’aime »). Nous allons donc créer une nouvelle table nommée « Likes » pour stocker les mentions « J’aime » d’un utilisateur. La table Likes disposera d’une clé étrangère qui fait référence à la colonne ID dans la table Users.
Likes
| ID | user_id | like |
|---|---|---|
| 10 | 1 | fashion |
| 11 | 1 | spas |
| 12 | 1 | shopping |
De même, un utilisateur pouvant gérer plusieurs entreprises, nous allons créer une nouvelle table nommée « Entreprises » pour stocker les informations commerciales. La table Businesses table aura une clé étrangère qui fera référence à la colonne ID dans la table Users.
Businesses
| ID | user_id | name | partner | status | date_founded |
|---|---|---|---|---|---|
| 20 | 1 | Entertainment 1080 | Jean | Bankrupt | 2011-05-19 |
| 21 | 1 | Swag for Tweens | NULL | NULL | 2012-11-01 |
Dans cet exemple simple, nous voyons que les données concernant un utilisateur peuvent être stockées dans un seul document dans une base de données orientée documents ou dans trois tables dans une relational database. Lorsqu’un développeur souhaite récupérer ou mettre à jour des informations sur un utilisateur dans la base de données orientée documents, il peut écrire une requête sans jointure. L’interaction avec la base de données est simple, et la modélisation des données dans la base de données est intuitive.
Consultez Correspondance des termes et concepts entre SQL et MongoDB pour en savoir plus.
Quelles sont les relations entre les bases de données orientées documents et les autres types de bases de données ?
Le document model est un sur-ensemble d’autres modèles de données, y compris de paires les clé-valeur, relationnel, objets, graphes et données géospatiales.
- Les paires clé-valeur peuvent être modélisées avec des champs et des valeurs dans un document. N’importe quel champ d’un document peut être indexé, offrant ainsi aux développeurs une flexibilité supplémentaire dans l’interrogation des données.
- Les données relationnelles peuvent être modélisées différemment (et certains diraient de manière plus intuitive) en regroupant les données associées dans un seul document à l’aide de sous-documents et de tableaux intégrés. Les données connexes peuvent également être stockées dans des documents distincts, et des références de base de données peuvent être utilisées pour relier les données connexes. Les documents correspondent à des *objets dans la plupart des langages de programmation populaires. Les nœuds et/ou les arêtes *graphiques peuvent être modélisés comme des documents. Les arêtes peuvent aussi être modélisées à l’aide de références de base de données. Les requêtes graphiques peuvent être exécutées à l’aide d’opérations telles que $graphLookup. Les données *géospatiales peuvent être modélisées sous forme de tableaux dans des documents.
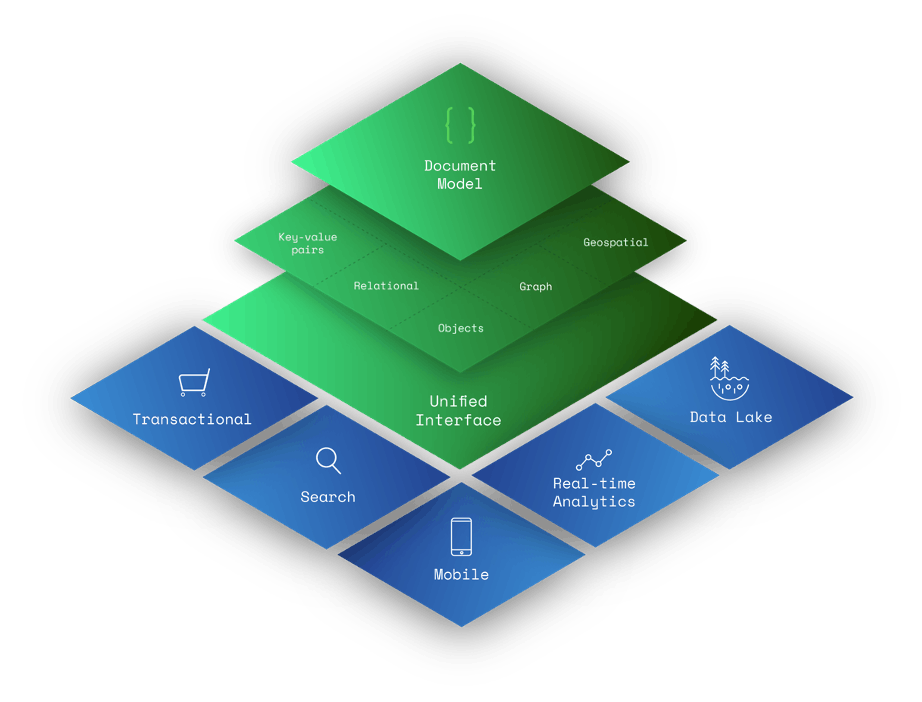 Le document model est un sur-ensemble d’autres modèles de données
Le document model est un sur-ensemble d’autres modèles de données
En raison de leurs fonctionnalités étendues de modélisation des données, les bases de données orientées documents sont des bases de données polyvalentes qui peuvent stocker des données pour une variété de cas d’utilisation.
Pourquoi ne pas simplement utiliser JSON dans une relational database ?
Avec les bases de données orientées documents qui permettent aux développeurs de créer plus rapidement, la plupart des relational databases ont ajouté la prise en charge de JSON. Cependant, le simple ajout d’un type de données JSON n’apporte pas les avantages d’une base de données avec prise en charge native de JSON. Pourquoi ? Parce que l’approche relationnelle abaisse la productivité des développeurs, au lieu de l’améliorer. Voici quelques-uns des aspects avec lesquels les développeurs doivent composer.
Extensions propriétaires
Travailler avec des documents signifie utiliser des fonctions SQL personnalisées, spécifiques aux fournisseurs, qui ne sont pas familières à la plupart des développeurs et qui ne fonctionnent pas avec vos outils SQL préférés. Ajoutez des pilotes JDBC/ODBC de bas niveau et des ORM et vous vous retrouvez confronté à des processus de développement complexes qui abaissent la productivité.
Gestion primitive des données
Présenter les données JSON sous forme de simples chaînes et nombres plutôt que sous forme de types de données riches pris en charge par des bases de données orientées documents natives telles que MongoDB rend le calcul, la comparaison et le tri des données complexes et sujets aux erreurs.
Mauvaise qualité des données et tableaux rigides
Les relational database offrent peu de possibilités de valider le schéma des documents ; vous n’avez donc aucun moyen d’appliquer des contrôles de qualité à vos données JSON. Et vous devez encore définir un schéma pour vos données tabulaires régulières, avec toutes les complications supplémentaires que cela implique lorsque vous devez modifier vos tableaux à mesure que les fonctionnalités de votre application évoluent.
Faibles performances
La plupart des relational databases ne maintiennent pas de statistiques sur les données JSON, ce qui empêche le planificateur de requêtes d’optimiser les requêtes par rapport aux documents et vous empêche d’ajuster vos requêtes.
Absence de scalabilité horizontale native
Les relational databases traditionnelles ne permettent pas de partitionner (shard) la base de données sur plusieurs instances pour évoluer à mesure que les charges de travail augmentent. Vous devez au contraire implémenter vous-même le sharding dans la couche applicative, ou vous fier à des systèmes de scaling coûteux.
Quels sont les points forts et les faiblesses des bases de données orientées documents ?
Les bases de données orientées documents ont de nombreux atouts :
- Le document model est omniprésent, intuitif et permet un développement logiciel rapide.
- Le schéma flexible permet au modèle de données d’évoluer à mesure que les exigences de l’application changent.
- Les bases de données orientées documents comportent des API riches et des langages de requête qui permettent aux développeurs d’interagir facilement avec leurs données.
- Les bases de données orientées documents sont distribuées (permettant une scalabilité horizontale ainsi qu’une distribution globale des données) et résilientes.
Ces atouts font des bases de données orientées documents un excellent choix pour un usage général.
Une faiblesse couramment citée à propos des bases de données orientées documents est que beaucoup d’entre elles ne prennent pas en charge les transactions ACID multidocuments. Nous estimons que 80%-90% des applications qui exploitent le document model n’auront pas besoin d’utiliser des transactions multidocuments.
Notez que certaines bases de données orientées documents comme MongoDB prennent en charge les transactions ACID multidocuments.
Consultez la page Qu’est-ce qu’une transaction ACID ? pour en savoir plus sur la façon dont le document model élimine en grande partie le besoin de transactions multidocuments et sur la manière dont MongoDB prend en charge les transactions dans les rares cas où elles sont nécessaires.
Quels sont les cas d’utilisation pour les bases de données orientées documents ?
Les bases de données orientées documents sont des bases de données polyvalentes qui répondent à une variété de cas d’utilisation pour des applications transactionnelles et analytiques :
- Vue unique ou hub de données
- Gestion et personnalisation des données clients
- Internet of Things (IoT) et données de time-series
- Catalogues de produits et gestion de contenu
- Traitement des paiements
- Applications mobiles
- Déchargement du mainframe
- Analyses opérationnelles
- Analyses en temps réel
Consultez notre livre blanc Use Case Guidance: Where to Use MongoDB pour en savoir plus sur chacune des applications mentionnées ci-dessus.
Résumé
Les bases de données orientées documents utilisent un modèle de données documentaire intuitif et flexible pour stocker les données. Les bases de données orientées document sont des bases de données à usage général qui peuvent être utilisées pour une variété de cas d’utilisation dans divers secteurs d’activité.
Commencez à utiliser les bases de données orientées documents en créant une base de données dans MongoDB Atlas, la plateforme de données pour développeurs de MongoDB. MongoDB Atlas propose une version généreuse et gratuite à vie que vous pouvez utiliser pour expérimenter et explorer le document model.
FAQ
À quoi servent les bases de données documentaires ?
MongoDB est-elle une base de données de documents ?
Quel est un exemple de base de données orientée documents ?
Comment fonctionnent les bases de données de documents ?
Comment les documents sont-ils stockés dans une base de données ?
Quel champ est toujours le premier champ dans un document ?
Dans MongoDB, le premier champ de chaque document est nommé _id. Le champ _id sert d’identifiant unique pour le document. Consultez la documentation officielle de MongoDB pour plus d’informations.
Notez que chaque système de gestion de base de données orientée documents possède ses propres exigences de champ.
Comment les données de MongoDB sont-elles stockées ?
MongoDB stocke les données dans des documents BSON (Binary JSON).
MongoDB est-il gratuit à utiliser ?
Oui, MongoDB propose deux niveaux gratuits :
- MongoDB Atlas, la plateforme de données pour les développeurs de MongoDB, offre une option généreuse et gratuite à vie, idéale pour expérimenter et apprendre à utiliser MongoDB.
- Si vous préférez héberger vous-même MongoDB, optez pour la version MongoDB Community Server conformément à la Server Side Public License (SSPL).
Base de données orientée documents vs relational database
La différence la plus évidente entre une base de données orientée documents et une relational database est la façon dont les données sont modélisées. Les bases de données orientées documents modélisent généralement les données à l’aide de documents flexibles de type JSON avec des paires champ-valeur. Les relational databases modélisent généralement les données en utilisant des tables rigides avec des lignes et des colonnes fixes.