Che cos'è un database di documenti?
Un database di documenti (noto anche come database orientato ai documenti o archivio di documenti) è un database che memorizza le informazioni nei documenti.

I database di documenti offrono una serie di diversi vantaggi, tra cui:
- Un modello di dati intuitivo, veloce e di facile utilizzo per gli sviluppatori
- Uno schema flessibile, che consente al modello di dati di evolversi con il cambiamento delle esigenze dell'applicazione
- La capacità di scalare orizzontalmente
Grazie a questi vantaggi, i database di documenti sono database generici che possono essere utilizzati in una serie di diversi casi di utilizzo e settori.
I database di documenti sono considerati database non relazionali (o NoSQL). Invece di archiviare i dati in righe e colonne fisse, i database di documenti utilizzano documenti flessibili. I database di documenti sono l'alternativa più popolare ai relational database tabellari. Scopri di più sui database NoSQL.
Che cosa sono i documenti?
Un documento è un record in un database di documenti. Un documento in genere archivia informazioni su un oggetto e su eventuali metadati a esso correlati.
I documenti archiviano i dati in coppie campo-valore. I valori possono essere di diversi tipi e strutture, inclusi stringhe, numeri, date, array o oggetti. I documenti possono essere archiviati in formati come JSON, BSON, e XML.
Di seguito è riportato un documento JSON che archivia informazioni su un utente di nome Tom.
{
"ID": 1,
"nome": "Tom",
"e-mail": "tom@example.com",
"cellulare": "765-555-5555",
"preferenze": [
"moda",
"centri benessere",
"shopping"
],
"aziende": [
{
"nome": "Entertainment 1080",
"partner": "Jean",
"stato": "Fallita",
"data_fondazione": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"nome": "Swag for Tweens",
"data_fondazione": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Raccolte
Una raccolta è un gruppo di documenti. Normalmente le raccolte archiviano documenti con contenuti simili.
Non è necessario che tutti i documenti di una raccolta abbiano gli stessi campi, poiché i database di documenti hanno schemi flessibili. Si ricorda che alcuni database di documenti offrono la convalida dello schema, pertanto, lo schema può essere bloccato facoltativamente quando necessario.
Continuando con l'esempio riportato in precedenza, il documento con le informazioni su Tom potrebbe essere archiviato in una raccolta di nome "utenti". Ulteriori documenti potrebbero essere aggiunti alla collezione "utenti" per archiviare informazioni su altri utenti. Ad esempio, il documento seguente che archivia le informazioni su Donna potrebbe essere aggiunto alla raccolta "utenti"
{
"ID": 2,
"nome": "Donna",
"e-mail": "donna@example.com",
"coniuge": "Joe",
"preferenze": [
"centri benessere",
"shopping",
"twittare in diretta"
],
"aziende": [
{
"nome": "Castle Realty",
"stato": "Fiorente",
"data_fondazione": {
"$date": "2013-11-21T04:00:00Z"
}
}
]
}Si noti che il documento per Donna non contiene gli stessi campi del documento per Tom. La raccolta "utenti" utilizza uno schema flessibile per archiviare le informazioni disponibili per ogni utente.
Operazioni CRUD
I database di documenti in genere dispongono di un'API o di un linguaggio di query che consente agli sviluppatori di eseguire le operazioni CRUD (creazione, lettura, aggiornamento ed eliminazione).
- Create: nel database si possono creare documenti. Ciascun documento ha un identificatore univoco.
- Read: nel database si possono leggere documenti. L'API o il linguaggio di query consente agli sviluppatori di interrogare i documenti utilizzando i loro identificatori univoci o i valori dei campi. Al database si possono aggiungere indici per migliorare le prestazioni di lettura.
- Update: i documenti già presenti si possono aggiornare, completamente e parzialmente.
- Delete: i documenti si possono eliminare dal database.
Quali sono le caratteristiche principali dei database di documenti?
I database di documenti presentano le seguenti caratteristiche principali:
- Document model: i dati sono archiviati nei documenti (a differenza di altri database che archiviano i dati in strutture come tabelle o grafici). I documenti si mappano agli oggetti nella maggior parte dei linguaggi di programmazione più popolari: questo consente agli sviluppatori di sviluppare rapidamente le applicazioni.
- Schema flessibile: i database di documenti presentano schemi flessibili, perciò non tutti i documenti in una raccolta devono avere gli stessi campi. Si ricorda che alcuni database di documenti supportano la convalida dello schema, quindi lo schema può essere bloccato facoltativamente.
- Distributed e resilienti: i database di documenti sono distributed e questo consente la scalabilità orizzontale (in genere più economica della scalabilità verticale) e la distribuzione dei dati. I database basati su documenti consentono resilienza tramite la replica.
- Interrogazione tramite un'API o un linguaggio di query: i database di documenti dispongono di un'API o di un linguaggio di query che consente agli sviluppatori di eseguire operazioni CRUD sul database. Gli sviluppatori possono eseguire query sui documenti in base a identificatori o valori di campo univoci.
Che cosa differenzia i database di documenti dai relational database?
I database di documenti si differenziano dai relational database per tre fattori chiave differenziano:
1. L'intuitività del modello di dati: i documenti si mappano agli oggetti nel codice, quindi è molto più naturale lavorarci. Non è necessario scomporre i dati tra le tabelle, eseguire join costosi o integrare un livello distinto di Object Relational Mapping (ORM). I dati a cui si accede insieme vengono archiviati insieme, quindi gli sviluppatori devono scrivere meno codice e gli utenti finali possono contare su prestazioni più elevate.
2. L'ubiquità dei documenti JSON: JSON è diventato uno standard consolidato per lo scambio e l'archiviazione dei dati. I documenti JSON sono leggeri, indipendenti dalla lingua e leggibili dall'uomo. I documenti sono una superserie di tutti gli altri modelli di dati. Questo consente agli sviluppatori di strutturare i dati in base alle esigenze delle applicazioni: oggetti avanzati, coppie chiave-valore, tabelle, dati geospaziali e serie temporali o i nodi e i bordi di un grafico.
3. La flessibilità dello schema: lo schema di un documento è dinamico e autodescrittivo, quindi gli sviluppatori non devono predefinirlo nel database. I campi possono variare da un documento all'altro. Gli sviluppatori possono modificare la struttura in qualsiasi momento, evitando migrazioni di schemi dirompenti. Alcuni database di documenti offrono la convalida dello schema in modo da poter applicare facoltativamente regole che governano le strutture dei documenti.
Scopri di più su database NoSQL a confronto con relational database.
In che misura è più facile lavorare con i documenti rispetto alle tabelle?
Generalmente gli sviluppatori ritengono che lavorare con i dati nei documenti sia più facile e intuitivo rispetto al lavoro con i dati nelle tabelle. I documenti si mappano alle strutture dati nei linguaggi di programmazione più popolari. Gli sviluppatori non devono preoccuparsi di suddividere manualmente i dati correlati in più tabelle durante l'archiviazione o di unirli nuovamente durante il recupero. Inoltre, non è necessario utilizzare un ORM per gestire la manipolazione dei dati. Gli sviluppatori, invece, possono lavorare in modo agevole direttamente con i dati nelle applicazioni.
Esaminiamo nuovamente un documento per un utente di nome Tom.
Utenti
{
"_id": 1,
"nome": "Tom",
"e-mail": "tom@example.com",
"cellulare": "765-555-5555",
"preferenze": [
"moda",
"centri benessere",
"shopping"
],
"aziende": [
{
"nome": "Entertainment 1080",
"partner": "Jean",
"stato": "Fallita",
"data-fondazione": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"nome": "Swag for Tweens",
"data_fondazione": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Tutte le informazioni su Tom sono archiviate in un unico documento.
Ora valutiamo come possiamo archiviare le stesse informazioni in un relational database. Inizieremo creando una tabella che archivia le informazioni di base sull'utente.
Utenti
| ID | nome | cellulare | |
|---|---|---|---|
| 1 | Tom | tom@example.com | 765-555-5555 |
A un utente possono piacere molte cose (dunque esiste una relazione uno-a-molti tra un utente e le preferenze), quindi creeremo una nuova tabella denominata "Preferenze" per archiviare le preferenze di un utente. La tabella Preferenze avrà una chiave esterna che fa riferimento alla colonna ID della tabella Utenti.
Preferenze
| ID | id_utente | preferenze |
|---|---|---|
| 10 | 1 | moda |
| 11 | 1 | centri benessere |
| 12 | 1 | shopping |
Analogamente, un utente può gestire molte aziende, quindi creeremo una nuova tabella denominata "Aziende" per archiviare le informazioni sulle aziende. La tabella Aziende avrà una chiave esterna che fa riferimento alla colonna "ID" della tabella "Utenti".
Aziende
| ID | id_utente | nome | partner | stato | data_fondazione |
|---|---|---|---|---|---|
| 20 | 1 | Entertainment 1080 | Jean | Fallita | 19-05-2011 |
| 21 | 1 | Swag for Tweens | NULL | NULL | 2012-11-01 |
In questo semplice esempio, vediamo che i dati su un utente potrebbero essere archiviati in un singolo documento in un database di documenti o in tre tabelle in un relational database. Quando uno sviluppatore desidera recuperare o aggiornare le informazioni su un utente nel database dei documenti, può scrivere una query senza join. L'interazione con il database è semplice e la modellazione dei dati nel database è intuitiva.
Visita Termini e concetti sulla mappatura da SQL a MongoDB per scoprire di più.
Che relazioni ci sono tra i database di documenti e altri database?
Il modello di documento è una superserie di altri modelli di dati, inclusi coppie chiave-valore, relazionali, oggetti, grafici e geospaziali.
- Le coppie chiave-valore possono essere modellate con campi e valori in un documento. Qualsiasi campo in un documento può essere indicizzato offrendo agli sviluppatori una maggiore flessibilità nell'interrogazione dei dati.
- I dati relazionali possono essere modellati in modo diverso (e, secondo alcuni, in modo più intuitivo) mantenendo i dati correlati insieme in un unico documento tramite documenti incorporati e matrici. I dati correlati si possono anche archiviare in documenti distinti e i riferimenti al database si possono utilizzare per connettere i dati correlati.
- I documenti vengono mappati a oggetti nei linguaggi di programmazione più diffusi.
- Nodi e/o bordi del grafico possono essere modellati come documenti. I bordi si possono modellare anche tramite riferimenti al database. Le interrogazioni del grafico si possono eseguire tramite operazioni come $graphLookup.
- I dati geospaziali si possono modellare come array nei documenti.
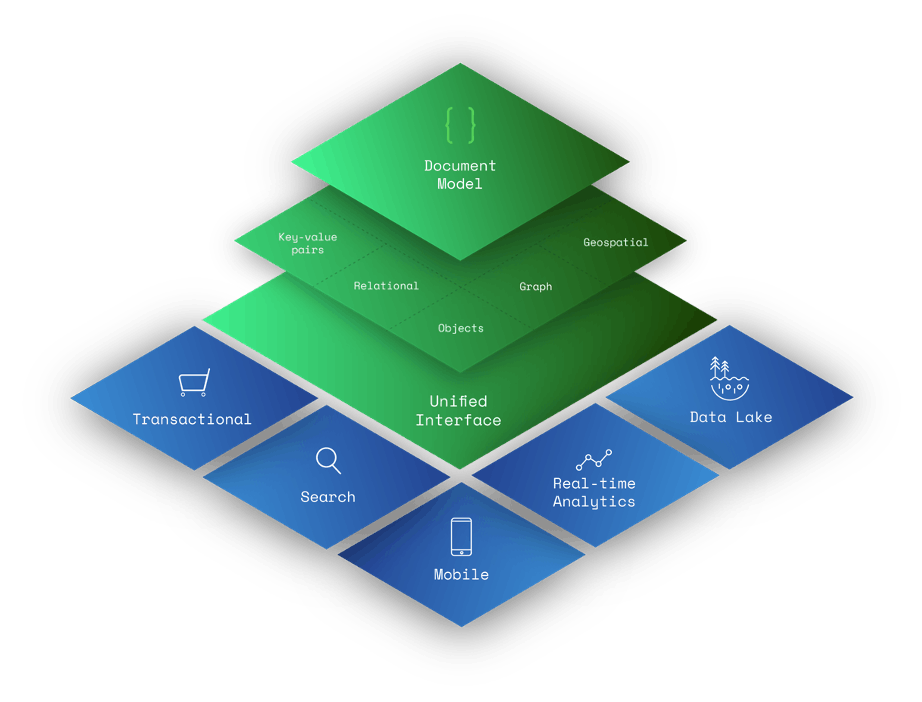 Il Document Model è una superserie di altri modelli di dati
Il Document Model è una superserie di altri modelli di dati
Grazie alle loro ricche capacità di modellazione dei dati, i database di documenti sono database generici in grado di archiviare dati per un'ampia serie di casi di utilizzo.
Perché non usare semplicemente JSON in un relational database?
Dal momento che i database di documenti permettono agli sviluppatori di sviluppare più velocemente, la maggior parte dei relational database ha aggiunto il supporto per JSON. Tuttavia, la semplice aggiunta di un tipo di dati JSON non apporta i vantaggi di un database con supporto native per JSON. Perché? Perché l'approccio relazionale riduce la produttività degli sviluppatori, invece di migliorarla. Ecco alcuni problemi che gli sviluppatori devono affrontare.
Estensioni proprietarie
Lavorare con i documenti significa usare funzioni SQL personalizzate e specifiche del fornitore, che la maggior parte degli sviluppatori non conoscono e che non funzionano con i tuoi strumenti SQL preferiti. Aggiungendo driver JDBC/ODBC e ORM di basso livello, ci si trova di fronte a processi di sviluppo complessi che portano a una bassa produttività.
Gestione di dati primitivi
La presentazione dei dati JSON come semplici stringhe e numeri, anziché come tipi di rich data supportati dai database di documenti native come MongoDB, rende l'elaborazione, il confronto e l'ordinamento dei dati complessi e passibili di errori.
Scarsa qualità dei dati e tabelle rigide
I relational database offrono pochi strumenti per convalidare lo schema dei documenti, quindi non si potranno applicare controlli di qualità sui dati JSON. E si deve comunque definire uno schema per i dati tabellari regolari, con tutti i costi generali aggiuntivi che comporta la necessità di modificare le tabelle man mano che le funzionalità dell'applicazione si evolvono.
Prestazioni di scarsa qualità
La maggior parte dei relational database non mantiene statistiche sui dati JSON, impedendo al pianificatore di query di ottimizzare le query sui documenti e a te di ottimizzare le query.
Nessuna scalabilità native
I relational database tradizionali non offrono alcun modo per partizionare (shard) il database su più istanze allo scopo di scalare con la crescita dei carichi di lavoro. In alternativa, si deve implementare lo sharding autonomamente nel layer applicativo oppure affidarsi a costosi sistemi di scalabilità.
Quali sono i punti di forza e i punti deboli dei database di documenti?
I database di documenti hanno molti punti di forza:
- Il document model è onnipresente, intuitivo e consente uno sviluppo rapido del software.
- Lo schema flessibile consente al modello di dati di cambiare man mano che cambiano i requisiti di un'applicazione.
- I database di documenti hanno API e linguaggi di query ricchi che consentono agli sviluppatori di interagire facilmente con i propri dati.
- I database di documenti sono distributed (consentendo la scalabilità orizzontale e la distribuzione globale dei dati) e resilienti.
Questi punti di forza rendono i database di documenti un'ottima scelta per un database a uso generale.
Il punto debole più noto dei database di documenti è che molti non supportano le transazioni ACID multi-documento. Stimiamo che l'80%%-90% delle applicazioni che sfruttano il modello di documento non necessiteranno di utilizzare transazioni su più documenti.
Si ricorda che alcuni database di documenti come MongoDB supportano transazioni ACID multi-documento.
Visita Che cosa sono le transazioni ACID? per scoprire di più su come il document model consente nella maggior parte dei casi di non dover usare transazioni con più documenti e su come MongoDB supporta le transazioni nei rari casi in cui sono necessarie.
Quali sono i casi di utilizzo dei database di documenti?
I database di documenti sono database a scopo generale utili a una varietà di casi di utilizzo per applicazioni transazionali e analitiche:
- Visualizzazione singola o hub di dati
- Gestione e personalizzazione dei dati dei clienti
- Internet delle cose (IoT) e dati di time-series
- Cataloghi di prodotti e gestione dei contenuti
- Elaborazione dei pagamenti
- App mobili
- Offload del mainframe
- Analytics operativa
- Analytics in tempo reale
Visita Indicazioni per i casi di utilizzo: dove usare MongoDB per scoprire di più su ciascuna delle applicazioni elencate in precedenza.
Riepilogo
I database di documenti utilizzano il data model doc intuitivo e flessibile per archiviare i dati. I database di documenti sono database per uso generico che si possono utilizzare in una varietà di casi di utilizzo in diversi settori.
Inizia con i database di documenti creando un database in MongoDB Atlas, la piattaforma dati per sviluppatori di MongoDB. Atlas offre un generoso livello gratuito per sempre, utilizzabile per sperimentare ed esplorare il document model.
Domande frequenti
A cosa servono i database di documenti?
MongoDB è un database di documenti?
Potete fare un esempio di un database di documenti?
Come funzionano i database di documenti?
Come vengono memorizzati i documenti in un database?
Qual è sempre il primo campo in un documento?
In MongoDB, il primo campo di ogni documento è denominato "id". Il campo "id" funge da identificatore univoco per il documento. Vedi la documentazione ufficiale di MongoDB per maggiori informazioni.
Si ricorda che ogni sistema di gestione di database di documenti ha requisiti di campo specifici.
Come vengono archiviati i dati in MongoDB?
MongoDB archivia i dati in BSON (Documenti JSON) binari.
L'uso di MongoDB è gratuito?
Sì, MongoDB ha due opzioni gratuite:
- MongoDB Atlas, la piattaforma dati per sviluppatori di MongoDB, offre un'opzione generosa e gratuita per sempre, ideale per sperimentare e imparare a usare MongoDB.
- Se preferisci ospitare autonomamente MongoDB, puoi utilizzare MongoDB Community Server in conformità con la Server Side Public License (SSPL).
Database di documenti a confronto con relational database
La differenza più evidente tra un database di documenti e un relational database è il modo in cui i dati sono modellati. I database di documenti generalmente modellano i dati utilizzando documenti flessibili simili a JSON con coppie di campi e valori. I relational database generalmente modellano i dati utilizzando tabelle rigide con righe e colonne fisse.