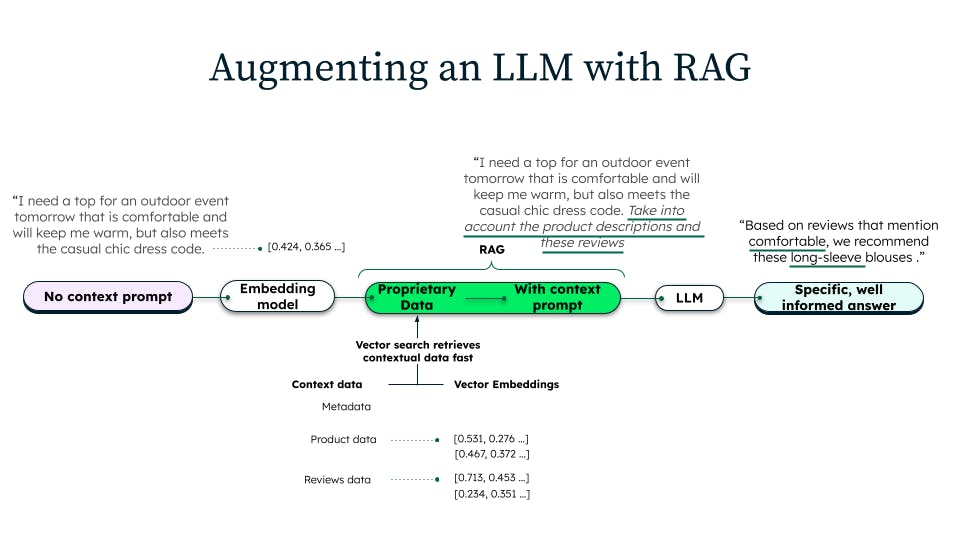
Como solución a esta falta de contexto específico del dominio, la generación aumentada de recuperación se realiza de la siguiente manera:
- Obtenemos las descripciones de producto más relevantes de una base de datos (a menudo una base de datos con búsqueda vectorial) que contiene el catálogo de productos más reciente
- A continuación, insertamos (aumentamos) estas descripciones en la consulta del LLM
- Por último, ordenamos al LLM que "haga referencia" a esta información de producto actualizada al responder a la pregunta
Tres cosas a tener en cuenta de lo anterior:
- La generación aumentada por recuperación es una técnica puramente de tiempo de inferencia (no requiere reentrenamiento). Los pasos 1-3 anteriores se realizan en tiempo de inferencia. No se requieren cambios en el modelo (p. ej. modificar los pesos del modelo).
- La generación aumentada de recuperación es muy adecuada para personalizaciones en tiempo real de generaciones de LLM. Como no hay que reentrenar y todo se hace mediante aprendizaje en contexto, la inferencia basada en RAG es rápida (latencia inferior a 100 m) y muy adecuada para su uso en aplicaciones operativas en tiempo real.
- La generación aumentada de recuperación hace que las generaciones LLM sean más precisas y útiles. Cada vez que cambie el contexto, el LLM generará una respuesta diferente. Por lo tanto, RAG hace que las generaciones LLM dependan de cualquier contexto que se haya recuperado.
Hacer que RAG sea simple con una complejidad mínima, pero sofisticada para funcionar de manera confiable a escala.
Para lograr una arquitectura RAG eficaz pero mínimamente compleja, hay que empezar por elegir los sistemas adecuados. A la hora de elegir los sistemas, o tecnologías, para la implantación de una RAG, es importante elegir sistemas, o un sistema, que pueda lograr lo siguiente:
- soportar los nuevos requisitos de datos vectoriales sin añadir una enorme expansión, costo y complejidad a sus operaciones de TI.
- Asegúrese de que las experiencias de IA generativa creadas tengan acceso a datos en vivo con una latencia mínima.
- Tener la flexibilidad para adaptarse a nuevos requisitos de datos y aplicaciones y permitir que los equipos de desarrollo se mantengan ágiles mientras lo hacen.
- Equipar mejor a los equipos de desarrollo para llevar todo el ecosistema de IA a sus datos, no al revés.
Las opciones van desde bases de datos vectoriales de un solo propósito hasta bases de datos documentales y relacionales con capacidades vectoriales nativas, y almacenes de datos y lakehouses. Sin embargo, las bases de datos vectoriales de propósito único añadirán dispersión y complejidad de inmediato. Los almacenes de datos y los lakehouses están diseñados inherentemente para consultas de tipo analítico de larga duración sobre datos históricos, a diferencia de los requisitos de alto volumen, baja latencia y datos frescos de las aplicaciones de IA generativa que impulsa RAG. Además, las bases de datos relacionales aportan esquemas rígidos que limitan la flexibilidad de agregar nuevos datos y requisitos de aplicaciones fácilmente. Quedan las bases de datos de documentos con funciones vectoriales nativas o integradas. En particular, MongoDB se basa en el modelo de documento flexible y tiene búsqueda vectorial nativa, lo que la convierte en una base de datos vectorial para RAG, además de la base de datos líder en la industria para cualquier aplicación moderna.
Cómo llevar la potencia de las LLM al siguiente nivel con capacidades adicionales en su implementación de RAG.
Además de los componentes centrales, hay varias capacidades adicionales que se pueden agregar a una implementación RAG para llevar el poder de LLM al siguiente nivel. Algunas de estas capacidades adicionales son:
- Multimodalidad: los modelos RAG multimodales pueden generar texto basado en datos textuales y no textuales, como imágenes, vídeos y audio. Estos datos multimodales almacenados junto a los datos operativos en tiempo real facilitan el diseño y el manejo de la implementation de RAG.
- Definición de filtros adicionales en la consulta de búsqueda vectorial: la capacidad de agregar búsqueda de palabras clave, búsqueda geoespacial y filtros de punto y rango en la misma consulta vectorial puede aportar precisión y velocidad al contexto proporcionado al LLM.
- Especificidad de dominio: los modelos RAG específicos de un dominio pueden entrenarse con datos de un dominio concreto, como la salud o las finanzas. Esto permite que el modelo RAG genere texto más preciso y relevante para ese dominio.
Cómo garantizar que su aplicación basada en IA generativa sea segura, eficiente, fiable y escalable cuando se globalice.
Hay una serie de cosas que se pueden hacer para garantizar que una aplicación impulsada por GenAI y construida con una RAG sea segura, eficiente, fiable y escalable cuando se globalice. Algunas de estas cosas son:
- Utilizar una plataforma que sea segura y tenga las capacidades adecuadas de manejo de datos: el manejo de datos es un término amplio que abarca todo lo que se hace para garantizar que los datos sean seguros, privados, precisos, disponibles y utilizables. Incluye los procesos, las políticas, las medidas, la tecnología, las herramientas y los controles en torno al ciclo de vida de los datos. Así pues, la plataforma debe ser segura por defecto, disponer de cifrado de extremo a extremo y haber alcanzado los niveles más altos de cumplimiento.
- Utilizar una plataforma basada en la cloud: además de las características de seguridad y escalabilidad que ofrecen las plataformas basadas en la cloud, los principales proveedores de cloud son algunos de los principales innovadores para la infraestructura de IA. La elección de una plataforma que sea independiente de la cloud permite a los equipos aprovechar las innovaciones de IA dondequiera que lleguen.
- Utilizar una plataforma que pueda aislar la infraestructura de la carga de trabajo vectorial de otra infraestructura de base de datos: es importante que las cargas de trabajo OLTP normales y las cargas de trabajo vectoriales no compartan infraestructura para que las dos cargas de trabajo puedan ejecutarse en hardware optimizado para cada una y para que no compitan por los recursos sin dejar de aprovechar los mismos datos.
- Utilizar una plataforma que haya demostrado su eficacia a gran escala: una cosa es que un proveedor diga que puede escalar, pero ¿tiene un historial y una trayectoria con clientes empresariales globales? ¿Tiene tolerancia a fallas críticas y capacidad de escalar horizontalmente, y puede demostrarlo con ejemplos de clientes?
Siguiendo estos consejos, es posible crear aplicaciones impulsadas por IA generativa con arquitecturas RAG que sean seguras, eficientes, confiables y escalables.
Con la introducción de Atlas Vector Search, La plataforma de datos para desarrolladores líder de MongoDB proporciona a los equipos una base de datos vectorial que permite crear arquitecturas RAG sofisticadas y de alto rendimiento que pueden funcionar a escala. Todo ello manteniendo los más altos niveles de seguridad y agnosticismo de la cloud y, lo que es más importante, sin agregar complejidad ni costos innecesarios.