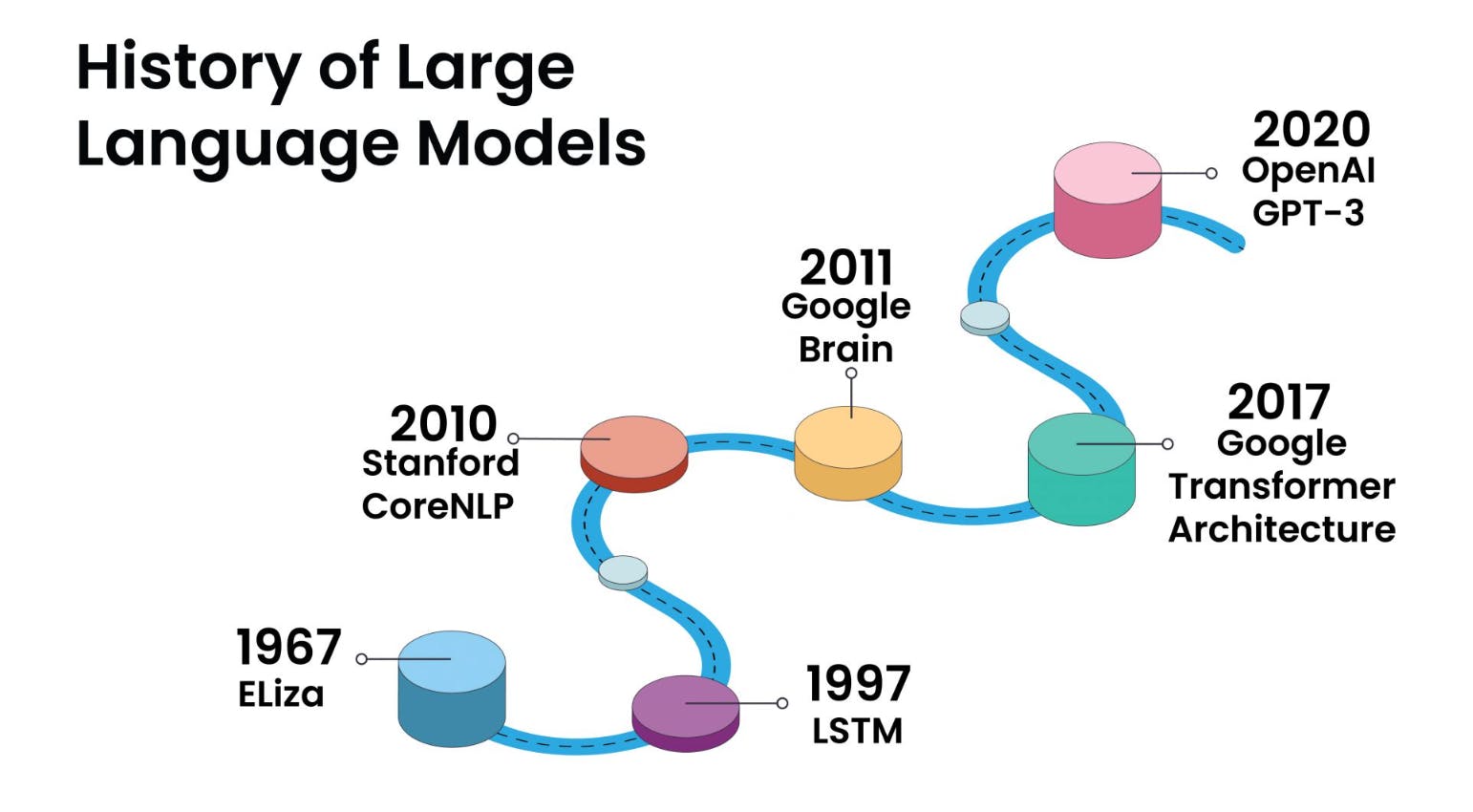
Un modelo Transformer es un avance fundamental en el mundo de la inteligencia artificial y el procesamiento del lenguaje natural. Representa un tipo de modelo de aprendizaje profundo que desempeñó un papel transformador en diversas tareas relacionadas con el lenguaje. Los Transformer están diseñados para comprender y generar lenguaje humano centrándose en las relaciones entre las palabras dentro de las oraciones.
Una de las características determinantes de los modelos Transformer es la utilización de una técnica llamada "autoatención". Esta técnica permite que estos modelos procesen cada palabra en una oración mientras consideran el contexto proporcionado por otras palabras en la misma oración. Este conocimiento del contexto supone un cambio significativo con respecto a los modelos lingüísticos anteriores y es una de las principales razones del éxito de los Transformer.
Los modelos Transformer se convirtieron en la columna vertebral de muchos LLM modernos. Al emplear modelos de Transformer, desarrolladores e investigadores han podido crear sistemas de IA más sofisticados y contextualmente conscientes que interactúan con el lenguaje natural de maneras cada vez más humanas, lo que lleva a mejoras significativas en las experiencias de usuario y aplicaciones de IA.
¿Cómo funcionan los modelos de lenguaje grandes?
Los modelos de lenguaje grandes funcionan utilizando técnicas de deep learning o aprendizaje profundo para procesar y generar lenguaje humano.
- Recopilación de datos: el primer paso en el entrenamiento de los LLM implica recopilar un conjunto masivo de datos de texto y código de Internet. Este conjunto de datos comprende una amplia gama de contenidos escritos por humanos, lo que proporciona a los LLM una base de lenguaje variada.
- Datos previos al entrenamiento: durante la fase previa al entrenamiento, los LLM están expuestos a este amplio conjunto de datos. Aprenden a predecir la siguiente palabra en una oración, lo que les ayuda a comprender las relaciones estadísticas entre palabras y frases. Este proceso les permite comprender la gramática, la sintaxis e incluso alguna comprensión contextual.
- Ajuste de datos: después de la capacitación previa, los LLM pasan por un ajuste fino para tareas específicas. Esto implica exponerlos a un conjunto de datos más limitado relacionado con la aplicación deseada, como la traducción, el análisis de sentimientos o la generación de textos. El fine-tuning o ajuste fino refina su capacidad para realizar estas tareas de manera efectiva.
- Comprensión contextual: los LLM consideran las palabras antes y después de una palabra dada en una oración, lo que les permite generar un texto coherente y contextualmente relevante. Este conocimiento del contexto es lo que diferencia a los LLM de los modelos de lenguaje anteriores.
- Adaptación a las tareas: gracias al ajuste fino, los LLM pueden adaptarse a una amplia gama de tareas. Pueden responder preguntas, generar texto similar al humano, traducir idiomas, resumir documentos y más. Esta adaptabilidad es una de las fortalezas clave de los LLM.
- Despliegue: una vez entrenados, los LLM se pueden implementar en varias aplicaciones y sistemas. Impulsan chatbots, motores de generación de contenido, motores de búsqueda y otras aplicaciones de IA, y así mejoran las experiencias de los usuarios.
En resumen, las LLM trabajan primero aprendiendo las complejidades del lenguaje humano a través de la capacitación previa en conjuntos de datos masivos. Luego afinan sus habilidades para tareas específicas, aprovechando la comprensión contextual. Esta adaptabilidad los convierte en herramientas versátiles para una amplia gama de aplicaciones de procesamiento de lenguaje natural.
Además, es importante tener en cuenta que la selección de un LLM específico para su caso de uso, así como los procesos de preentrenamiento del modelo, ajuste fino y otras personalizaciones, se producen independientemente de Atlas (y, por tanto, fuera de Atlas Vector Search).
¿Cuál es la diferencia entre un modelo de lenguaje grande (LLM) y el procesamiento del lenguaje natural (NLP)?
El procesamiento del lenguaje natural (NLP) es un dominio dentro de la informática dedicado a facilitar las interacciones entre las computadoras y los lenguajes humanos, abarcando tanto la comunicación hablada como la escrita. Su alcance abarca dotar a los ordenadores de la capacidad de comprender, interpretar y manipular el lenguaje humano, por lo que abarca aplicaciones como la traducción automática, el reconocimiento de voz, el resumen de textos y la respuesta a preguntas.
Por otro lado, los modelos de lenguaje grandes (LLM) emergen como una categoría específica de modelos de NLP. Estos modelos se someten a un riguroso entrenamiento con vastos repositorios de texto y código, lo que les permite discernir intrincadas relaciones estadísticas entre palabras y frases. En consecuencia, los LLM muestran la capacidad de generar textos coherentes y contextualmente relevantes. Los LLM se pueden usar para una variedad de tareas, incluida la generación de texto, la traducción y la respuesta a preguntas.
Ejemplos de modelos de lenguaje grandes en aplicaciones reales
Mejora del servicio de atención al cliente
Imagine una empresa que quiere mejorar su servicio de atención al cliente. Aprovechan las capacidades de un modelo de lenguaje grande para crear un chatbot capaz de abordar las consultas de los clientes sobre sus productos y servicios. Este chatbot se somete a un proceso de entrenamiento utilizando amplios conjuntos de datos compuestos por preguntas de los clientes, sus correspondientes respuestas y documentación detallada de los productos. Lo que distingue a este chatbot es su comprensión profunda de la intención del cliente, lo que le permite proporcionar respuestas precisas e informativas.
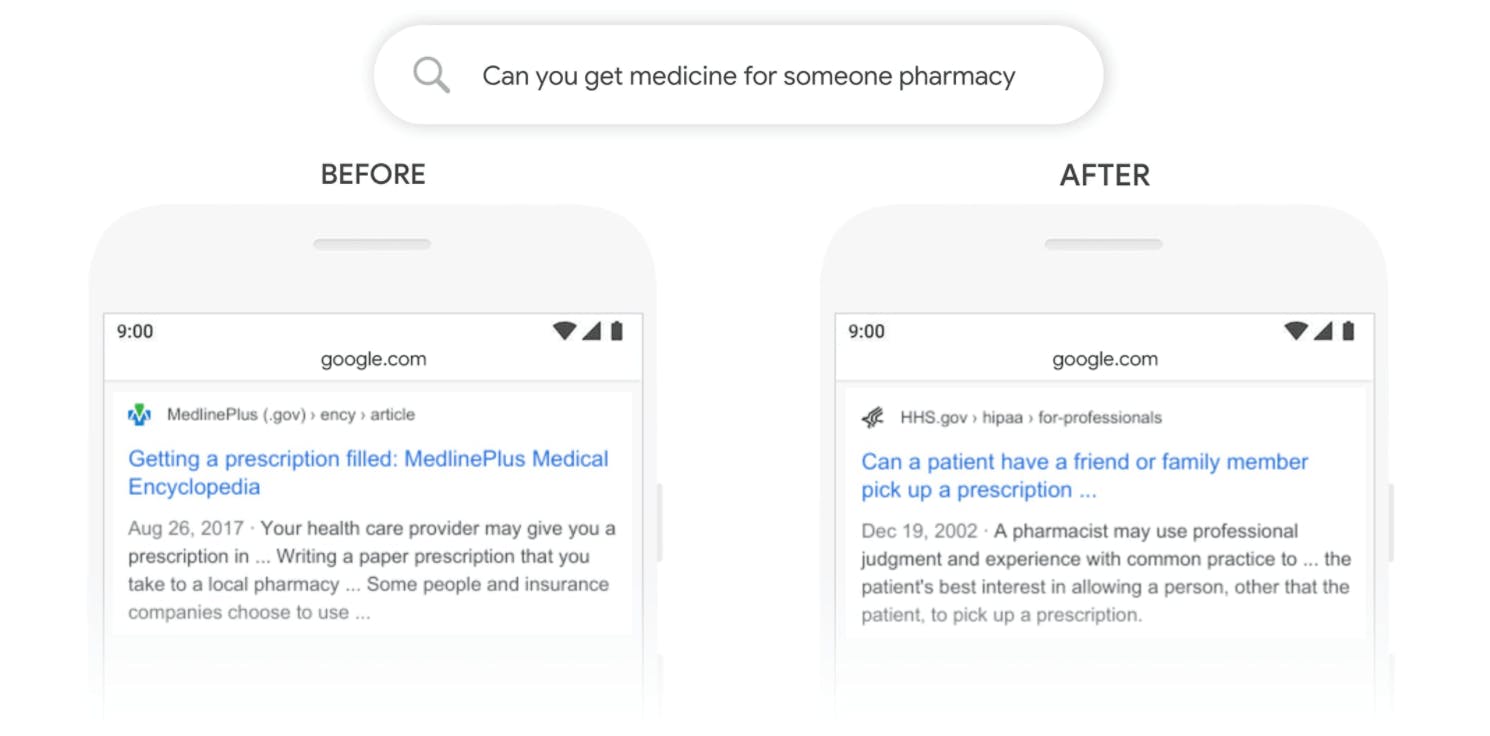
Mejores motores de búsqueda
Los motores de búsqueda forman parte de nuestra vida cotidiana, y los LLM potencian estos motores haciéndolos más intuitivos. Estos modelos pueden entender lo que estás buscando, incluso si no lo expresas perfectamente, y recuperar los resultados más relevantes de vastas bases de datos, mejorando tu experiencia de búsqueda en línea.
Recomendaciones personalizadas
Cuando compras en Internet o ves vídeos en plataformas de streaming, a menudo ves recomendaciones de productos o contenidos que podrían gustarte. Los LLM impulsan estas recomendaciones inteligentes, ya que analizan su comportamiento pasado para sugerir cosas que coincidan con sus gustos, haciendo que sus experiencias en línea sean más personalizadas.
Los LLM de generación
de contenido creativo no son solo procesadores de datos; también son mentes creativas. Tienen algoritmos de aprendizaje profundo que pueden generar contenido desde publicaciones de blog hasta descripciones de productos e incluso poesía. Esto no solo ahorra tiempo, sino que también ayuda a las empresas a crear contenido atractivo para sus audiencias.
Al incorporar los LLM, las empresas están mejorando sus interacciones con los clientes, las funciones de búsqueda, las recomendaciones de productos y la creación de contenidos, transformando en última instancia el panorama tecnológico.
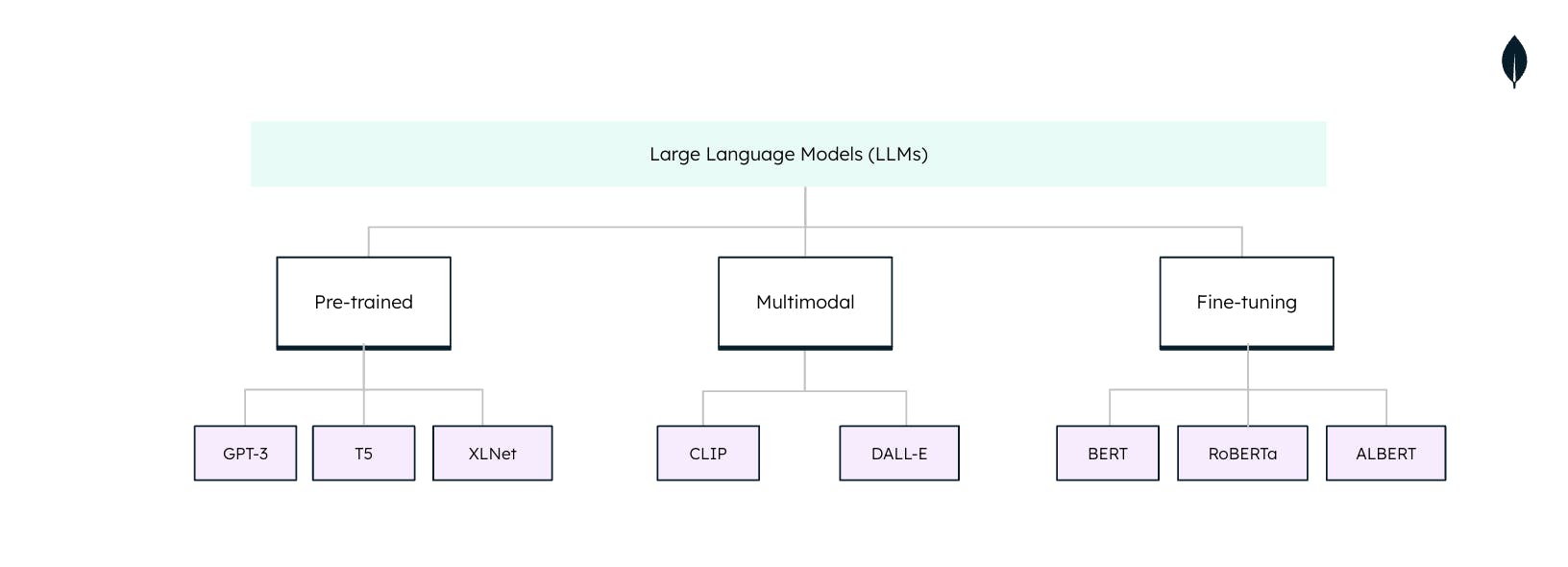
Tipos de modelos de lenguaje grandes
Los modelos de lenguaje grandes (LLM) no son universales cuando se utilizan en tareas de procesamiento del lenguaje natural (NLP). Cada LLM se adapta a tareas y aplicaciones específicas. Comprender estos tipos es esencial para aprovechar todo el potencial de los LLM: