Puede implementar MongoDB Search y Vector Search en su clúster de Kubernetes para crear potentes experiencias de búsqueda directamente en sus aplicaciones. Con MongoDB Search y Vector Search, puede crear funciones de búsqueda de texto tradicionales y de búsqueda vectorial con IA que se sincronizan automáticamente con una base de datos MongoDB local. Esto elimina la necesidad de mantener sincronizados sistemas separados y, al mismo tiempo, ofrece funciones de búsqueda avanzadas. Para obtener más información, consulte:
Para habilitar las capacidades de búsqueda, como la búsqueda de texto completo y semántica, en implementaciones locales, debe implementar el proceso de búsqueda MongoDB y búsqueda vectorial (mongot) y conéctelo a su implementación de base de datos MongoDB (mongod). La implementación de mongot es opcional y solo es necesaria si planea aprovechar las funciones de búsqueda que ofrece.
La base de datos MongoDB procesa (mongod) y actúa como proxy para todas las consultas de búsqueda de mongot. mongod reenvía la consulta a mongot, que la procesa. mongot devuelve los resultados de la consulta a mongod, que a su vez los reenvía a usted. Nunca interactúa directamente con mongot.
Cada proceso mongot tiene su propio volumen persistente, que no se comparte con la base de datos ni con otros nodos de búsqueda. El almacenamiento se utiliza para mantener los índices generados a partir de los datos que se obtienen continuamente de la base de datos. Las definiciones de índice (metadatos) se almacenan en la propia base de datos.
El mongot realiza las siguientes acciones:
Gestiona el índice.
El
mongotes responsable de actualizar las definiciones de índice en la base de datos.Obtiene los datos de la base de datos.
Los nodos
mongotestablecen conexiones permanentes a la base de datos para actualizar los índices de la base de datos en tiempo real.Procesa consultas de búsqueda.
Cuando
mongodrecibe$searchuna consulta, o, la dirige$searchMetaa uno de los$vectorSearchmongotnodos. Elmongotnodo que recibe la consulta la procesa, agrega los datos y devuelve los resultadosmongoda, que los reenvía al usuario.
Los componentes mongot están estrechamente vinculados a un único conjunto de réplicas de MongoDB y no se pueden compartir entre varias bases de datos o conjuntos de réplicas. Esto significa que la implementación de un conjunto de réplicas tiene sus propios nodos de búsqueda dedicados.
La conectividad de red entre mongot y mongod va en ambas direcciones:
mongotEstablece una conexión con el conjunto de réplicas para obtener los datos utilizados para crear índices y ejecutar consultas.mongodse conecta amongotpara reenviar operaciones relacionadas con la búsqueda, como la gestión de índices y la consulta de datos.
Implementación de búsqueda vectorial y de búsqueda en MongoDB
No hay muchas diferencias entre la arquitectura de implementación de búsqueda con o sin el Operador de Kubernetes. El Operador de Kubernetes simplifica los pasos necesarios para implementar nodos de búsqueda totalmente funcionales, especialmente cuando la base de datos también es gestionada por el Operador de Kubernetes.
Para implementar, se aplica el recurso personalizado (CR) MongoDBSearch, que el operador de Kubernetes selecciona y comienza a implementar los pods mongot y solicita el almacenamiento persistente especificado en spec. Las búsquedas de MongoDB y de vectores implementadas con el operador de Kubernetes pueden tener como destino el conjunto de réplicas de MongoDB implementado por el operador de Kubernetes dentro del mismo clúster de Kubernetes o una base de datos externa de MongoDB completamente independiente. Para aprender a implementar y configurar mongot para su uso:
Un conjunto de réplicas de MongoDB en Kubernetes, consulte Instalar y usar la búsqueda con MongoDB Enterprise Edition
Un set de réplicas de MongoDB externo, consulta Instala y usa MongoDB Search y búsqueda vectorial con MongoDB Enterprise Edition.
Prerrequisitos
Para aprovechar MongoDB Search y Vector Search en su implementación de MongoDB Enterprise, debe tener lo siguiente:
Conjunto de réplicas MongoDB 8.0.14+ completamente funcional implementado de una de las siguientes maneras:
Dentro de un clúster de Kubernetes usando el operador de Kubernetes
Fuera de un clúster de Kubernetes
Instancia de Cloud Manager o Ops Manager
Antes de comenzar, considere lo siguiente:
Debe tener un
StorageClassactivo para crear volúmenes persistentes en el clúster |k8s|. Sin él, suPersistentVolumeClaimspodría quedar pendiente y MongoDB podría no tener almacenamiento duradero.Debe tener una red de clúster correctamente configurada. Servicios como ClusterIP, NodePort o LoadBalancer deben poder enrutar el tráfico. Si los clientes externos necesitan acceso, configure un balanceador de entrada o de carga.
Tu base de datos y los nodos de búsqueda deben tener suficiente CPU, memoria y espacio en disco asignados, ya que las cargas de trabajo de la base de datos MongoDB, así como de MongoDB Search y Vector Search, consumen muchos recursos. Recomendamos usar solicitudes y límites en las especificaciones de tu pod para evitar expulsiones o limitaciones.
Su versión de Kubernetes debe ser compatible con el operador de MongoDB o el diagrama de Helm que desee utilizar. Algunos CRD o API difieren entre versiones. Para obtener más información, consulte Controladores de MongoDB para la compatibilidad de operadores de Kubernetes.
Debes crear cualquier requerido RolesRBAC y enlaces de roles para que el operador de Kubernetes y los procesos que se ejecutan dentro de los pods puedan administrar recursos.
Tareas de configuración
La siguiente tabla muestra las tareas de configuración que el operador de Kubernetes realiza automáticamente y las acciones que debe realizar para implementar con éxito MongoDB Search y Vector Search en Kubernetes y conectarse a un conjunto de réplicas de MongoDB en Kubernetes o a un conjunto de réplicas de MongoDB externo.
Tarea | (Inside Kubernetes) Performed by | (External MongoDB) Performed by |
|---|---|---|
Implementar Ops Manager dentro de Kubernetes | Operador de Kubernetes | Operador de Kubernetes |
Implementar Cloud Manager u Ops Manager fuera de Kubernetes | Le | Le |
Implementar un conjunto de réplicas de MongoDB | Operador de Kubernetes | Le |
Crear | Le | Le |
Proporcionar una cadena de conexión al conjunto de réplicas de MongoDB | Operador de Kubernetes | Le |
Crear | Operador de Kubernetes | Operador de Kubernetes |
Establezca los parámetros del conjunto de réplicas necesarios en cada proceso | Operador de Kubernetes | Le |
Rol Polyfill | Operador de Kubernetes | Le |
Crear usuario para | Operador de Kubernetes y usted mediante la aplicación del recurso MongoDBUser | Le |
Configurar el conjunto de réplicas de MongoDB con un usuario que tenga los permisos necesarios para realizar consultas de búsqueda | Le | Le |
Crear índices de búsqueda de MongoDB y de búsqueda vectorial | Le | Le |
Exponer pods de búsqueda externamente para conectarse desde cada nodo | No es necesario | Le |
Exponer pods mongod externamente para conectarse desde | No es necesario | Le |
El siguiente diagrama muestra la arquitectura de implementación de una sola instancia de MongoDB Search y Vector Search con un conjunto de réplicas de MongoDB Enterprise en un clúster de Kubernetes.

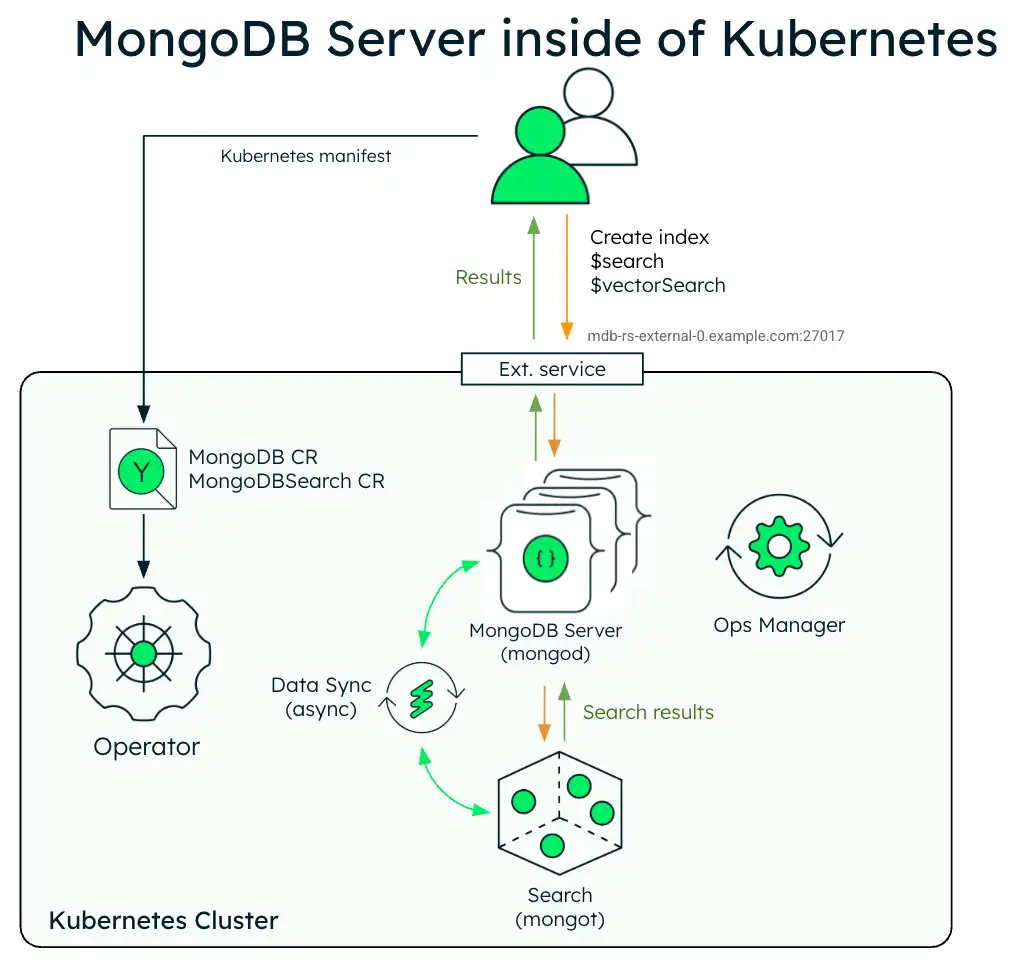
El siguiente diagrama muestra los componentes que el operador de Kubernetes implementa en un clúster de Kubernetes para MongoDB Search y Vector Search con un conjunto de réplicas de MongoDB Enterprise Edition.

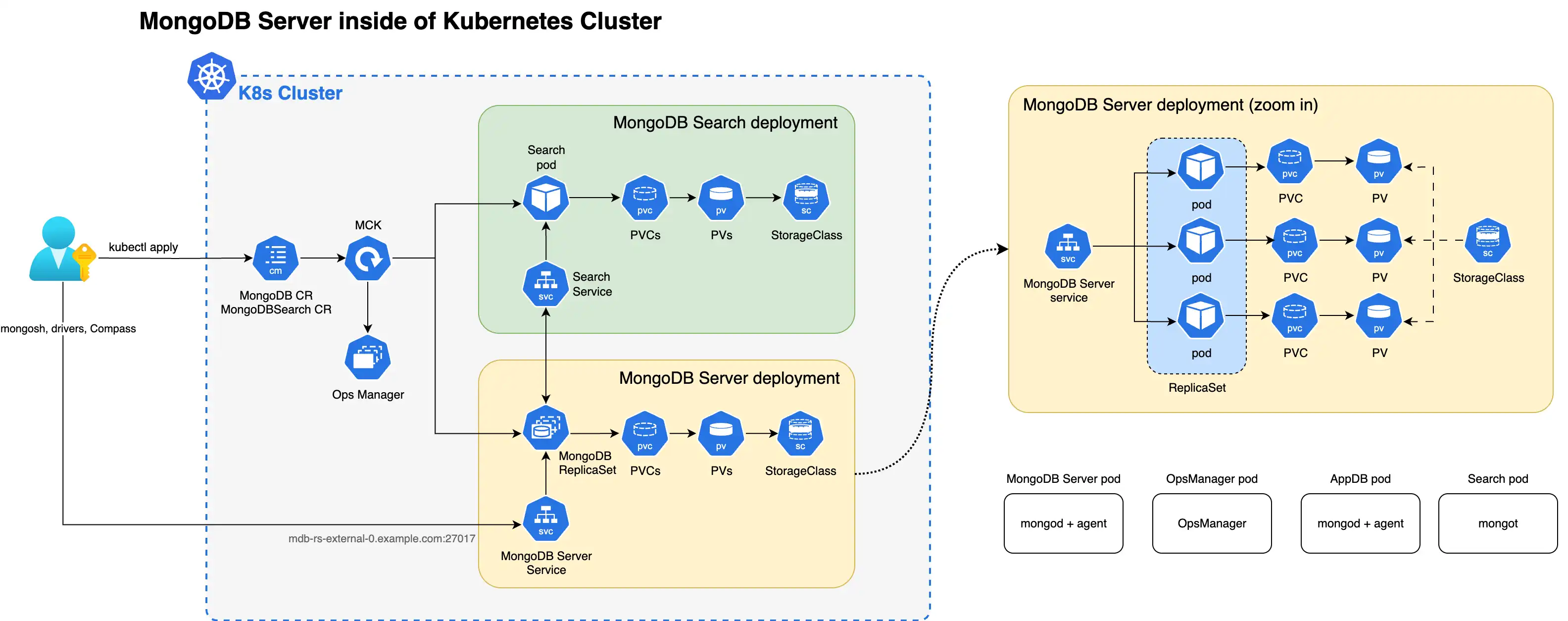
Cuando los procesos mongot y mongod se implementan dentro del clúster de Kubernetes, el operador de Kubernetes configura ambos procesos automáticamente. En concreto, realiza las siguientes operaciones:
Encuentra el CR de MongoDB al
MongoDBSearchquespec.source.mongodbResourceRefhace referencia utilizando, o mediante una convención de nomenclatura buscando un CR de MongoDB con el mismo nombreMongoDBSearchque.Genera
mongotla configuración en un archivo YAML y la guarda en un mapa de configuración<MongoDBSearch.metadata.name>-search-configllamado.Los pods de búsqueda montan el mapa de configuración y el proceso de utiliza la configuración YAML al
mongotiniciarse. El YAML generado contiene toda la información sobre cómo conectarse al conjunto de réplicas, la configuración de TLS, etc.Implementa el conjunto con estado de MongoDB Search y Vector Search denominado
<MongoDBSearch.metadata.name>-searchcon requisitos de almacenamiento y recursos configurados de acuerdo con las configuraciones yspec.persistencespec.resourceRequirementsen la CR.Actualiza la configuración de cada proceso
mongodagregando las opcionessetParameternecesarias, incluidos los nombres de host y los números de puerto de los hosts de mongot. opcionessetParameternecesarias, incluidos los nombres de host y los números de puerto de los miembros del conjunto de réplicas de MongoDB.Para versiones de MongoDB anteriores a la v8.2, crea el rol personalizado
searchCoordinatorcon todos los permisos necesarios para el procesomongot. A partir de MongoDB 8.2, el rolsearchCoordinatores integrado.
Debes realizar las siguientes acciones:
Cree un usuario en el conjunto de réplicas usando un recurso personalizado
MongoDBUser.mongotusa las credenciales de este usuario para conectarse al conjunto de réplicas y obtener los datos:El nombre de usuario es arbitrario (en los ejemplos, usamos
search-sync-source-user), pero debe tener el rolsearchCoordinatorasignado.El nombre de usuario y la contraseña de este usuario se pasan en
MongoDBSearch.spec.source.usernameyMongoDBSearch.spec.source.passwordSecretRefrespectivamente.La contraseña secreta puede referirse al mismo secreto que contiene la contraseña de usuario que se utilizó para crear la especificación
MongoDBUser(enMongoDBUser.spec.source.passwordSecretKeyRef).
Configurar y aplicar el recurso personalizado
MongoDBSearch.
Para obtener más información sobre la configuración de CR para el mongot proceso, consulte Configuración de búsqueda de MongoDB y búsqueda vectorial.
El siguiente diagrama muestra la arquitectura de implementación de MongoDB Search y Vector Search en un clúster de Kubernetes utilizando un conjunto de réplicas externas de MongoDB Enterprise Edition.

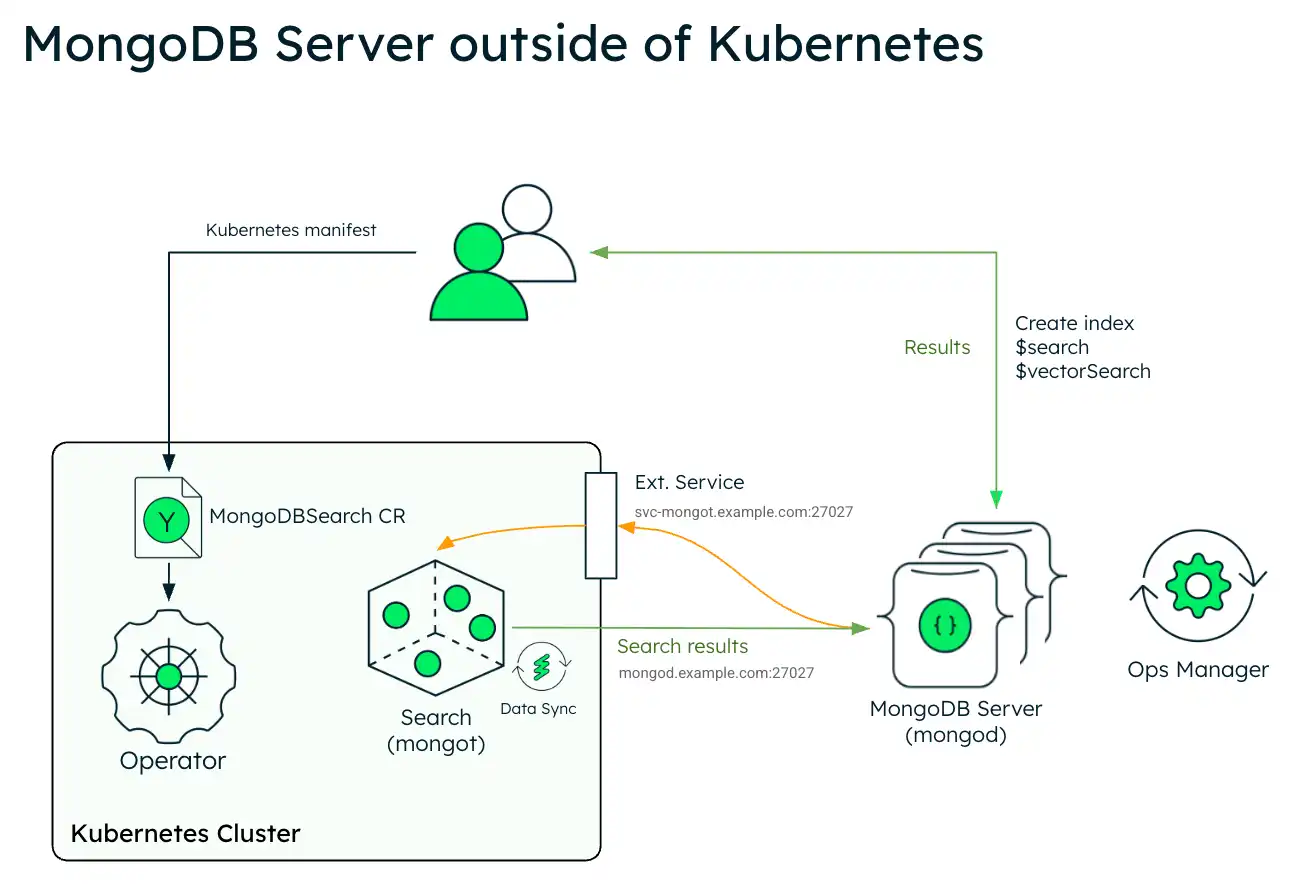
El siguiente diagrama muestra los componentes que el operador de Kubernetes implementa en un clúster de Kubernetes para MongoDB Search y Vector Search.

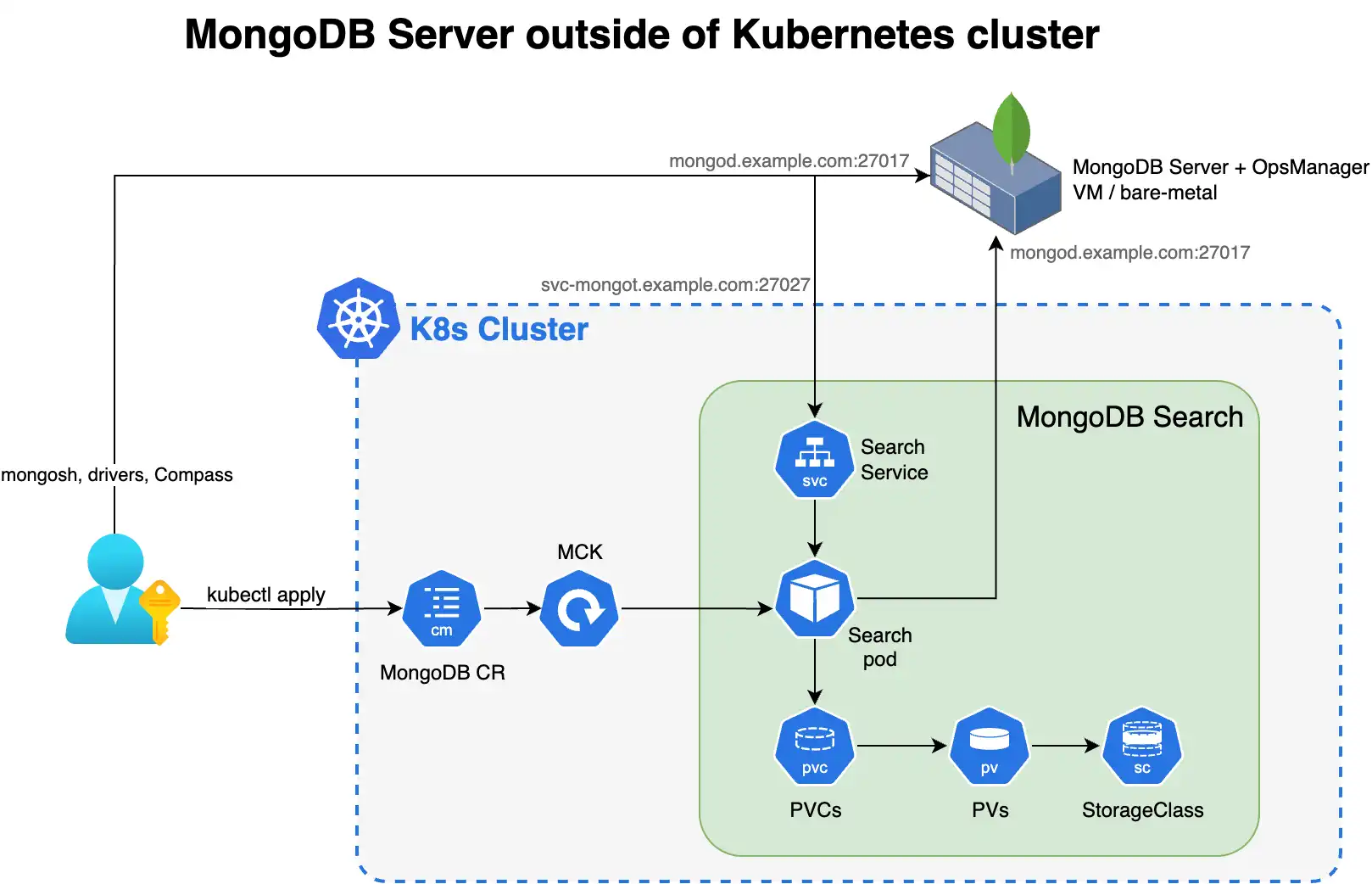
Para aprovechar MongoDB Search y Vector Search cuando su implementación de MongoDB está fuera de Kubernetes, implemente mongot mediante el operador de Kubernetes y deberá realizar algunos pasos manualmente. El operador de Kubernetes gestiona la configuración de los pods de búsqueda. Sin embargo, cuando el conjunto de réplicas de MongoDB está fuera de Kubernetes, deberá reconfigurar sus nodos de MongoDB y la red.
Usted es responsable de las siguientes configuraciones manuales:
Configuración externa de MongoDB
Configure el siguiente parámetro usando
setParameteren cada procesomongodde su conjunto de réplicas externas. Al configurarlo, reemplace<search-service-hostname>:27027con el nombre de host y el puerto resolubles reales de su servicioMongoDBSearch.setParameter: mongotHost: "<search-service-hostname>:27027" searchIndexManagementHostAndPort: "<search-service-hostname>:27027" skipAuthenticationToSearchIndexManagementServer: false searchTLSMode: "disabled" # or "requireTLS" for TLS deployments (Solo para la versión de MongoDB anterior a
<()) 8.2 Cree elsearchCoordinatorrol personalizado con todos los permisos necesarios.Desde MongoDB 8.2+,
searchCoordinatores una función integrada y, por lo tanto, puedes omitir este paso.Cree un usuario en el conjunto de réplicas externas para el proceso de sincronización de búsqueda. Este usuario debe tener el rol
searchCoordinator.- userName: "search-sync-source" password: "<your-search-sync-password>" database: "admin" roles: - role: "searchCoordinator" db: "admin"
Configuración de Kubernetes
Configure y aplique el
MongoDBSearchCR conspec.source.externalapuntando a sus hosts MongoDB externos.Cree un secreto de Kubernetes para la contraseña del usuario de sincronización de búsqueda.
apiVersion: v1 kind: Secret metadata: name: search-sync-source-password stringData: password: "your-search-sync-password" Cree un archivo de claves secreto que contenga las mismas claves especificadas en el archivo de claves utilizado por su conjunto de réplicas externas de MongoDB.
Configure la red y el DNS para garantizar la conectividad bidireccional entre su MongoDB externo y los pods de búsqueda. Su entorno externo de MongoDB debe poder resolver el nombre de host de su servicio de búsqueda (
<search-service-hostname>).
Para obtener más información sobre la configuración de CR para que el mongot proceso se conecte a un mongod proceso externo, consulte Configuración de búsqueda de MongoDB y búsqueda vectorial.
Seguridad
La siguiente imagen ilustra la configuración de seguridad del mongot proceso. Si el servidor MongoDB está dentro del clúster de Kubernetes, el operador de Kubernetes configura automáticamente la autenticación mediante archivo de claves para MongoDB Search y Vector Search. Si el servidor MongoDB es externo, debe crear un secreto de Kubernetes que contenga la credencial del archivo de claves del conjunto de réplicas y referenciarlo en el MongoDBSearch CR.

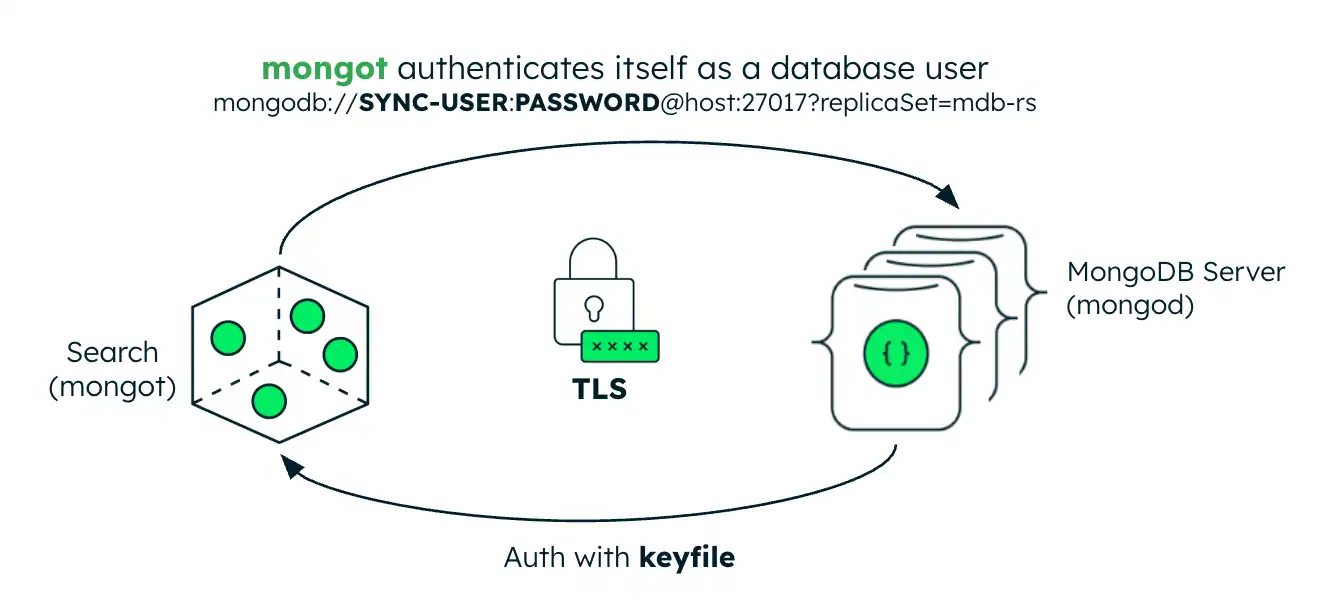
Autenticación
Al conectarse a mongod, mongot se autentica como un usuario de base de datos. Al implementar MongoDB Search y búsqueda vectorial, debe crear el usuario de base de datos. Debes pasar las credenciales de usuario almacenadas en un secreto de Kubernetes a mongot rellenando los campos spec.source.username y spec.source.passwordSecretRef en el MongoDBSearch CR.
Al aceptar una conexión de mongod, mongot autentica la solicitud remota mediante autenticación interna con archivos de claves, similar a la autenticación interna de los miembros del conjunto de réplicas de MongoDB. Al configurarse para indexar un recurso de MongoDB en el mismo clúster de Kubernetes, el operador de Kubernetes configura automáticamente la autenticación con archivos de claves para MongoDBSearch. Si el conjunto de réplicas de MongoDB se implementa fuera de Kubernetes, debe crear un secreto de Kubernetes que contenga la credencial del archivo de claves del conjunto de réplicas y referenciarlo en el campo MongoDBSearch.spec.source.external.keyfileSecretRef.
Seguridad de capa de transporte (TLS)
MongoDBSearch puede proteger los datos y las credenciales en tránsito utilizando TLS. Para los comandos de gestión de índices y consultas de búsqueda, especifica (incluso un objeto vacío, {}) el campo spec.security.tls y proporciona un certificado TLS en un secreto de Kubernetes en el campo spec.security.tls.certificateKeySecretRef. Este certificado TLS debe ser emitido y firmado por la misma CA que emitió el certificado CA que utiliza el set de réplicas de MongoDB.
Cuando el operador de Kubernetes implementa MongoDBSearch y MongoDB, la configuración subyacente de mongot y mongod la gestiona en gran medida el propio operador de Kubernetes. Cuando el conjunto de réplicas de MongoDB se implementa fuera de Kubernetes, el campo .spec.source.external.tls debe rellenarse con un secreto de Kubernetes que contenga el mismo certificado de CA con el que está configurado mongod, y la configuración de mongod debe tener el parámetro searchTLSMode establecido en requireTLS.