Puedes implementar MongoDB Search y búsqueda vectorial en tu clúster de Kubernetes para construir potentes experiencias de búsqueda directamente en tus aplicaciones. Utilizando MongoDB Search y Vector Search, puedes crear tanto funciones tradicionales de búsqueda de texto como funciones de búsqueda vectorial impulsadas por IA que se sincronizan automáticamente con una base de datos MongoDB on-premises. Esto elimina la necesidad de mantener sistemas separados sincronizados, al tiempo que se ofrece funcionalidades avanzadas de búsqueda. Para obtener más información, consulte:
Para habilitar las capacidades de búsqueda, como búsqueda full-text y búsqueda semántica en implementaciones on-prem, debe desplegar el proceso MongoDB Search y búsqueda vectorial (mongot) y conéctalo con tu despliegue de base de datos MongoDB (mongod). El despliegue de mongot es opcional y solo es necesario si planeas usar las funciones de búsqueda que ofrece.
Los procesos de la base de datos MongoDB (mongod) actúan como el proxy para todas las consultas de búsqueda para mongot. El mongod reenvía la query al mongot, que procesa la query. El mongot devuelve los resultados de la query al mongod, que luego te envía los resultados a ti. Nunca interactúas directamente con el mongot.
Cada proceso mongot tiene su propio volumen persistente que no se comparte ni con la base de datos ni con otros nodos de búsqueda. El almacenamiento se utiliza para mantener índices que se compilan a partir de los datos obtenidos continuamente de la base de datos. Las definiciones del índice (metadatos) se almacenan en la propia base de datos.
El mongot realiza las siguientes acciones:
Gestiona el índice.
El
mongotes responsable de actualizar las definiciones de índices en la base de datos.Obtiene los datos de la base de datos.
Los nodos
mongotestablecen conexiones permanentes con la base de datos para actualizar los índices en tiempo real.Procesa consultas de búsqueda.
Cuando
mongodrecibe una consulta$search,$searchMeta, o$vectorSearch, dirige la consulta a uno de los nodosmongot. Elmongotque recibe la query la procesa, agrega los datos y envía los resultados amongod, que los reenvía al usuario.
Los componentes mongot están estrechamente vinculados a un único conjunto de réplicas de MongoDB y no se pueden compartir entre varias bases de datos o conjuntos de réplicas. En una implementación de conjunto de réplicas, un grupo de nodos de búsqueda dedicados presta servicio al conjunto de réplicas. En un clúster fragmentado, cada fragmento mantiene su propio grupo independiente de nodos mongot. Los fragmentos no comparten instancias mongot.
La conectividad de red entre mongot y mongod va en ambas direcciones:
mongotestablece la conexión con el set de réplicas para obtener los datos que se utilizarán en la creación de índices y la ejecución de queries.mongodse conecta amongotpara reenviar operaciones relacionadas con la búsqueda, como la gestión de índices y la consulta de datos.
El spec.replicas campo controla cuántas mongot instancias implementa el operador de Kubernetes. Para una fuente despec.replicas conjunto de réplicas, establece el número total de mongot pods. Para una fuente de clúster fragmentado, spec.replicas establece el número de mongot pods por fragmento.
Si establece spec.replicas en un valor mayor que 1, debe colocar un balanceador de carga L7 entre mongod y los pods mongot. El proceso mongod abre una única conexión TCP de larga duración a mongot, por lo que un balanceador de carga L4 no puede distribuir consultas entre varias instancias mongot; todo el tráfico fluye a través de esa única conexión. Un balanceador de carga L7 entiende HTTP/2 y gRPC, lo que le permite distribuir flujos gRPC individuales entre pods mongot mientras fija cada flujo a un único mongot durante la duración del cursor de consulta.
Implementación de búsqueda vectorial y de búsqueda en MongoDB
No hay muchas diferencias entre la arquitectura de implementación de búsqueda con o sin el Operador de Kubernetes. El Operador de Kubernetes simplifica los pasos necesarios para implementar nodos de búsqueda totalmente funcionales, especialmente cuando la base de datos también es gestionada por el Operador de Kubernetes.
Para implementar, se aplica el recurso personalizado (CR) MongoDBSearch, que el operador de Kubernetes detecta y comienza a implementar pods mongot y solicita el almacenamiento persistente especificado en spec. MongoDB Search y Vector Search implementados a través del operador de Kubernetes pueden apuntar a un conjunto de réplicas de MongoDB o a un clúster fragmentado implementado por el operador de Kubernetes dentro del mismo clúster de Kubernetes, o a una implementación externa de MongoDB completamente independiente (conjunto de réplicas o clúster fragmentado). Para aprender cómo implementar y configurar mongot para usar:
Un set de réplicas de MongoDB en Kubernetes, consulte Instalar y usar con MongoDB Community Edition o Instalar y usar Buscar con MongoDB Enterprise Edition
Un set de réplicas de MongoDB externo, consulta Instala y usa MongoDB Search y búsqueda vectorial con MongoDB Enterprise Edition.
Requisitos previos
Para utilizar MongoDB Search y Vector Search en su:
Para el despliegue de MongoDB Community, debe tener un conjunto de réplicas o clúster fragmentado de MongoDB 8.2 o posterior completamente funcional desplegado dentro de un clúster de Kubernetes utilizando el operador de Kubernetes.
Para la implementación de MongoDB Enterprise, debe tener un conjunto de réplicas o un clúster fragmentado de MongoDB 8.2 o posterior completamente funcional implementado de una de las siguientes maneras:
Dentro de un clúster de Kubernetes usando el operador de Kubernetes
Fuera de un clúster de Kubernetes
Instancia de Cloud Manager u Ops Manager
Antes de comenzar, tenga en cuenta lo siguiente:
Debes tener un
StorageClassen funcionamiento para la creación de volúmenes persistentes en el clúster de Kubernetes. Sin esto, tuPersistentVolumeClaimspodría quedar pendiente y MongoDB podría no tener almacenamiento duradero.Debe tener una red de clúster correctamente configurada. Servicios como ClusterIP, NodePort o LoadBalancer deben poder enrutar el tráfico. Si los clientes externos necesitan acceso, configure un balanceador de entrada o de carga.
Tus nodos de base de datos y de búsqueda deben tener suficiente CPU, memoria y espacio en disco asignados porque la base de datos de MongoDB y las cargas de trabajo de MongoDB Search y búsqueda vectorial requieren muchos recursos. Recomendamos utilizar solicitudes y límites en tus especificaciones de Pod para evitar la expulsión o la limitación.
Su versión de Kubernetes debe ser compatible con el operador de MongoDB o el Helm gráfica que desee utilizar. Algunos CRD o API difieren según la versión. Para obtener más información, consulta Controladores de MongoDB para compatibilidad con operadores de Kubernetes.
Debes crear cualquier requerido RolesRBAC y enlaces de roles para que el operador de Kubernetes y los procesos que se ejecutan dentro de los pods puedan administrar recursos.
Si desea varias instancias
mongot(spec.replicasmayor que1), necesita un balanceador de carga. El operador de Kubernetes puede implementar y administrar un proxy Envoy automáticamente (spec.loadBalancer.managed: {}), o puede proporcionar su propio balanceador de carga L7 (spec.loadBalancer.unmanaged).Si desea un clúster fragmentado con múltiples
mongotinstancias, asegúrese de contar con recursos suficientes para el número total de pods en todos los fragmentos. Cada fragmento obtiene su propio grupo independiente demongotpods. El balanceador de carga distribuye el tráfico almongotgrupo correcto. Lee el campo TLS SNI del tráfico entrante para identificar el fragmento de origen y lo enruta a losmongotpods que pertenecen a ese fragmento. Por lo tanto,debe configurar cada fragmento con un nombre de host de búsqueda distinto.
Tareas de configuración
La siguiente tabla muestra las tareas de configuración que el Operador de Kubernetes realiza automáticamente y las acciones que debe llevar a cabo para implementar correctamente MongoDB Search y Vector Search en Kubernetes y conectarse a un conjunto de réplicas de MongoDB o a un clúster fragmentado en Kubernetes o a una implementación externa de MongoDB.
Tarea | (Inside Kubernetes) Performed by | (External MongoDB) Performed by |
|---|---|---|
Implementa Ops Manager dentro de Kubernetes | Operador de Kubernetes | Operador de Kubernetes |
Implementa Cloud Manager u Ops Manager fuera de Kubernetes | Le | Le |
Implementar un conjunto de réplicas de MongoDB o un clúster fragmentado. | Operador de Kubernetes | Le |
Crea un recurso personalizado MongoDBSearch | Le | Le |
Proporcione la cadena de conexión para la implementación de MongoDB. | Operador de Kubernetes | Le |
Crea configuración de | Operador de Kubernetes | Operador de Kubernetes |
Configura los parámetros necesarios del set de réplicas en cada proceso | Operador de Kubernetes | Le |
Crea un usuario para | Kubernetes operador y usted aplicando el recurso MongoDBUser | Le |
Configura el set de réplicas de MongoDB con un usuario que tenga los permisos necesarios para consultar query | Le | Le |
Crea índices de búsqueda de MongoDB y Vector Search | Le | Le |
Exponer externamente los pods de búsqueda o el balanceador de carga para conectarse desde cada nodo | No es necesario | Le |
Exponer | No es necesario | Le |
Configurar el balanceador de carga administrado (cuando | Operador de Kubernetes | Operador de Kubernetes |
Configurar balanceador de carga no administrado (cuando | Le | Le |
Proporcionar certificados TLS por fragmento (clústeres fragmentados con TLS) | Le | Le |
Exponer el balanceador de carga externamente (MongoDB externo + Balanceador de carga administrado) | No es necesario | Le |
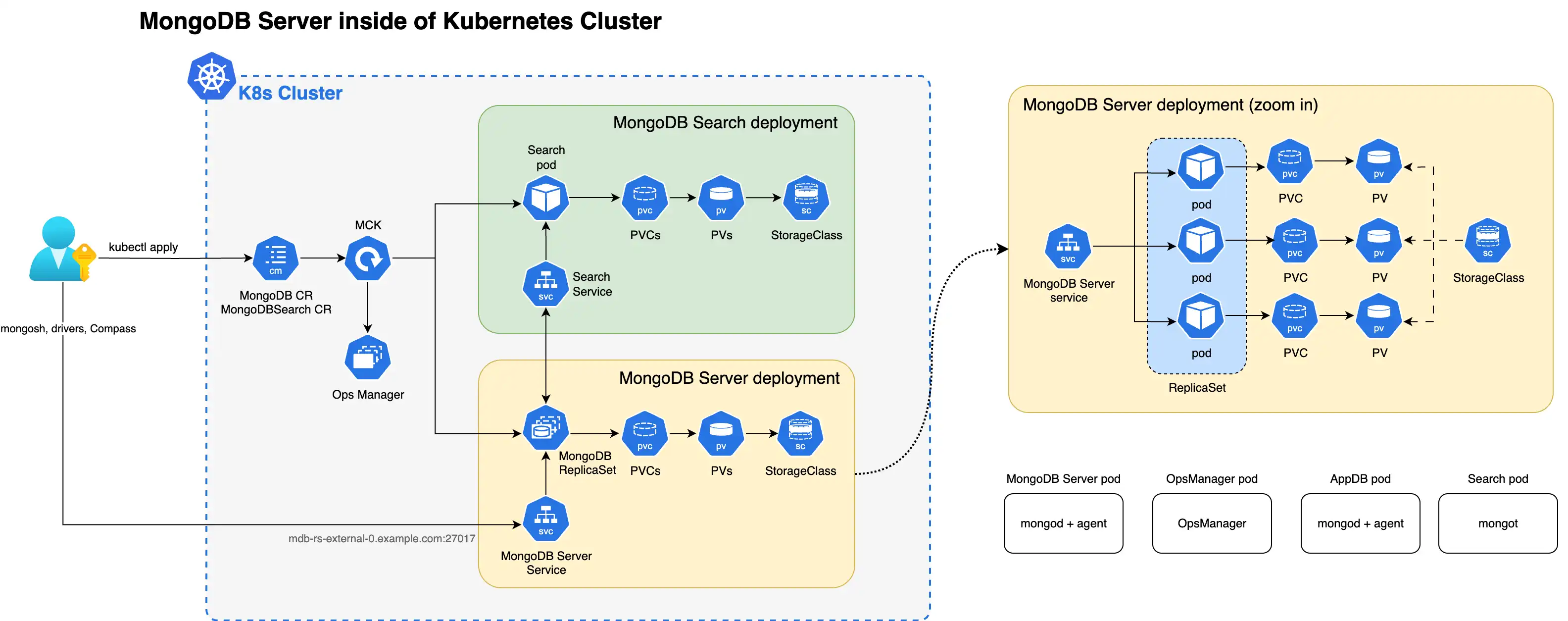
El siguiente diagrama muestra la arquitectura de implementación de una instancia única de MongoDB Search y búsqueda vectorial con un set de réplicas de MongoDB Enterprise en un clúster de Kubernetes.

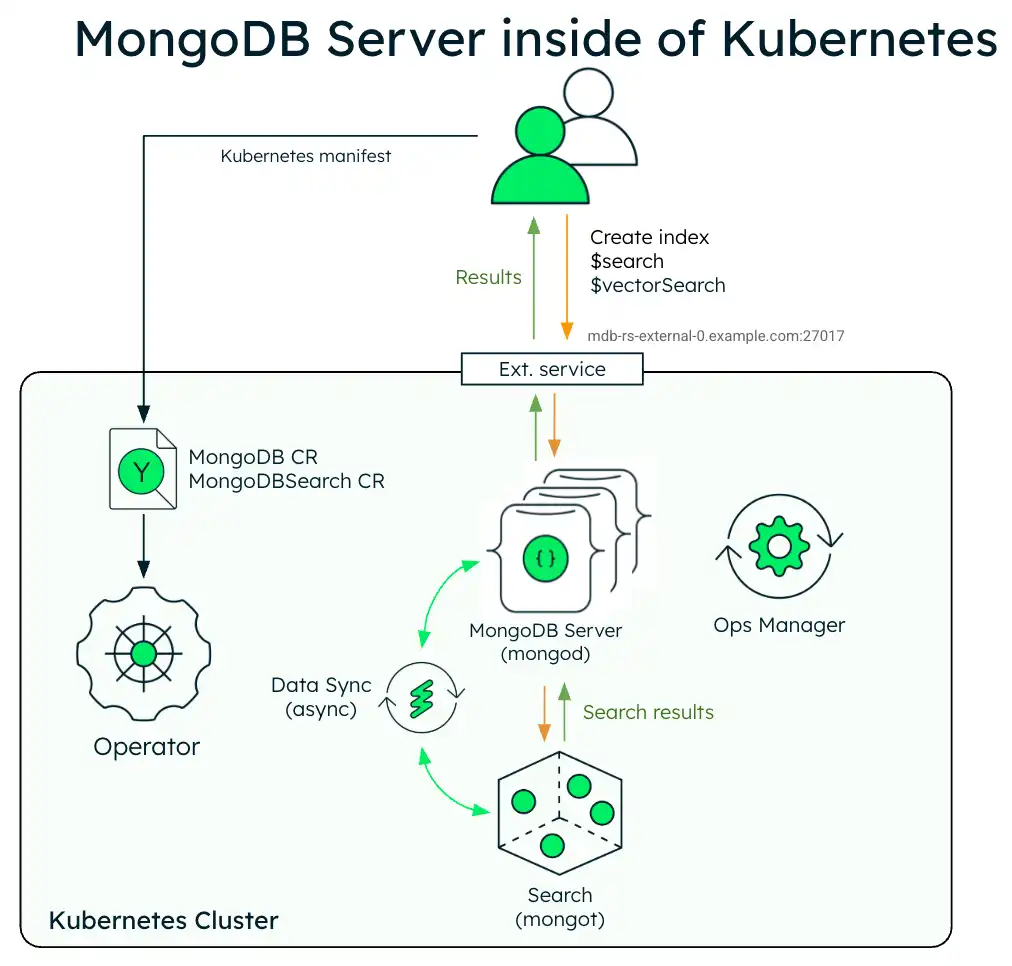
El siguiente diagrama muestra los componentes que el operador de Kubernetes implementa en un clúster de Kubernetes para MongoDB Search y Vector Search con un conjunto de réplicas de MongoDB Enterprise Edition.

Cuando los procesos mongot y mongod se implementan dentro del clúster de Kubernetes, el operador de Kubernetes configura ambos procesos automáticamente. En concreto, realiza las siguientes operaciones:
Encuentra el CR de MongoDB al que hace referencia MongoDBSearch
spec.source.mongodbResourceRefusando, o mediante una convención de nomenclatura buscando un CR de MongoDB con el mismo nombre que MongoDBSearch. Para clústeres fragmentados, el operador de Kubernetes descubre automáticamente la topología de fragmentación (nombres de fragmentación, miembros del conjunto de réplicas y enrutadores mongos) a partir delMongoDBrecurso referenciado.Genera la configuración
mongoten un archivo YAML y la guarda en un config map llamado<MongoDBSearch.metadata.name>-search-config.Los pods de búsqueda montan el mapa de configuración y el proceso de utiliza la configuración YAML al
mongotiniciarse. El YAML generado contiene toda la información sobre cómo conectarse al conjunto de réplicas, la configuración de TLS, etc.Implementa un conjunto con estado de MongoDB Search y Vector Search denominado
<MongoDBSearch.metadata.name>-searchcon requisitos de almacenamiento y recursos configurados según las configuracionesspec.persistenceyspec.resourceRequirementsdel CR. Para fuentes de clúster fragmentadas, el operador de Kubernetes crea un StatefulSet por cada fragmento. Cada StatefulSet utiliza el patrón de nomenclatura<name>-search-0-<shardName>y contienespec.replicaspods, cuyo valor predeterminado1es. El0en el patrón de nomenclatura reserva un índice de clúster para compatibilidad futura con múltiples clústeres.Implementa un único proxy Envoy para el clúster de MongoDB si necesitas un balanceador de carga (
spec.loadBalancer.managed). El proxy Envoy gestiona el enrutamiento L7, la terminación mTLS y la fijación de flujo gRPC entre los podsmongodymongot.Actualiza la configuración de cada proceso
mongodagregando las opcionessetParameternecesarias, incluyendo los nombres de host y los números de puerto de los hostsmongot. Al configurar un balanceador de carga,mongotHostysearchIndexManagementHostAndPortapuntan al punto final del balanceador de carga en lugar de a los podsmongot. Para clústeres fragmentados, los procesosmongodde cada fragmento reciben el punto final del balanceador de carga para ese fragmento.
Debes realizar las siguientes acciones:
Crea un usuario en el set de réplicas utilizando un recurso personalizado
MongoDBUser. Elmongotutiliza las credenciales de este usuario para conectarse al set de réplicas y obtener los datos:El nombre de usuario es arbitrario (en los ejemplos, usamos
search-sync-source-user), pero debe tener el rolsearchCoordinatorasignado.El nombre de usuario y la contraseña de este usuario se pasan en
MongoDBSearch.spec.source.usernameyMongoDBSearch.spec.source.passwordSecretRefrespectivamente.El secreto de la password puede referirse al mismo secreto que contiene la password del usuario que se utilizó para crear la especificación
MongoDBUser(enMongoDBUser.spec.source.passwordSecretKeyRef).
Configura y aplica el recurso personalizado MongoDBSearch.
Para obtener más información sobre la configuración de CR para el proceso mongot, consulta Configuraciones de MongoDB Search y búsqueda vectorial.
El siguiente diagrama muestra la arquitectura de implementación de MongoDB Search y Vector Search en un clúster de Kubernetes utilizando un conjunto de réplicas externas de MongoDB Enterprise Edition.

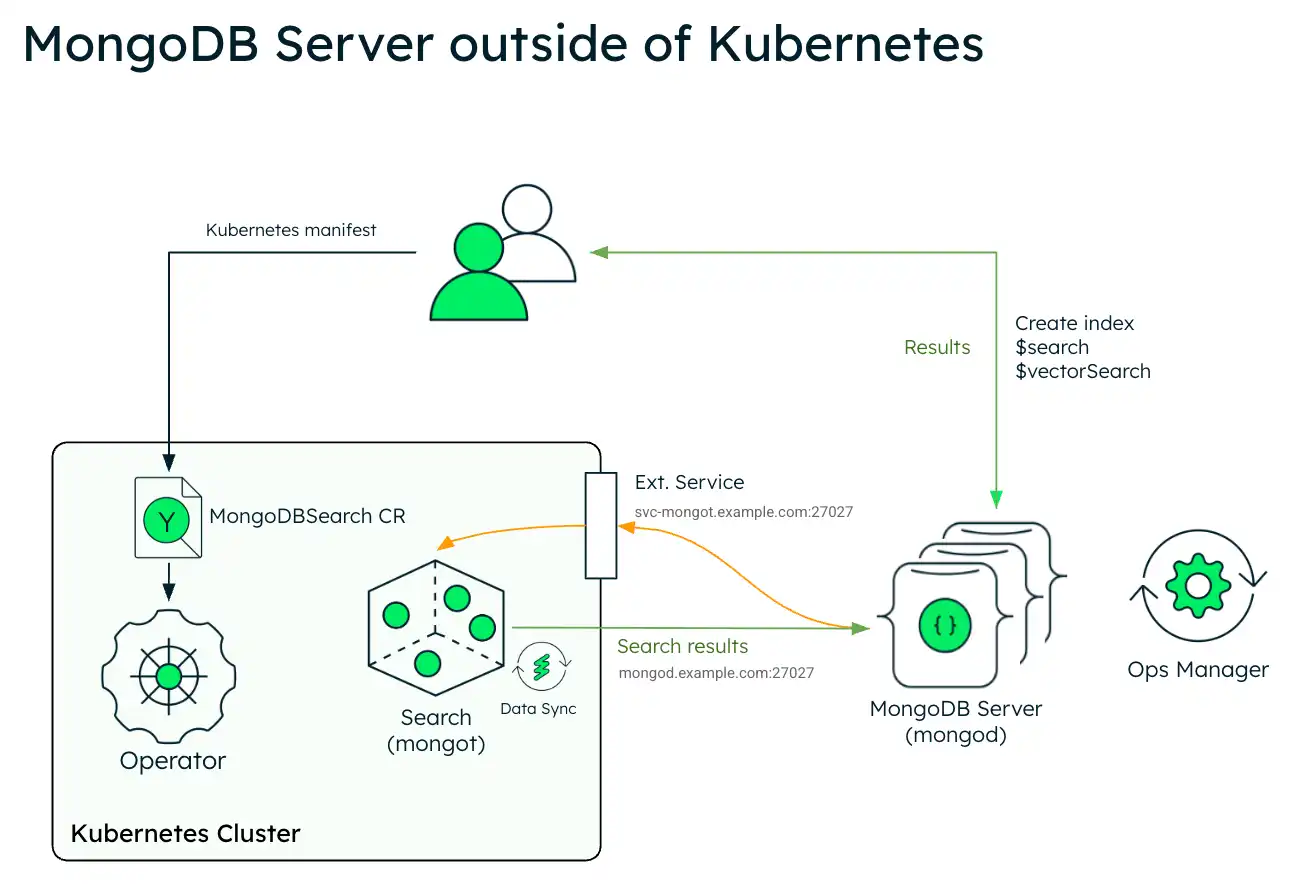
El siguiente diagrama muestra los componentes que el operador de Kubernetes implementa en un clúster de Kubernetes para MongoDB Search y búsqueda vectorial.

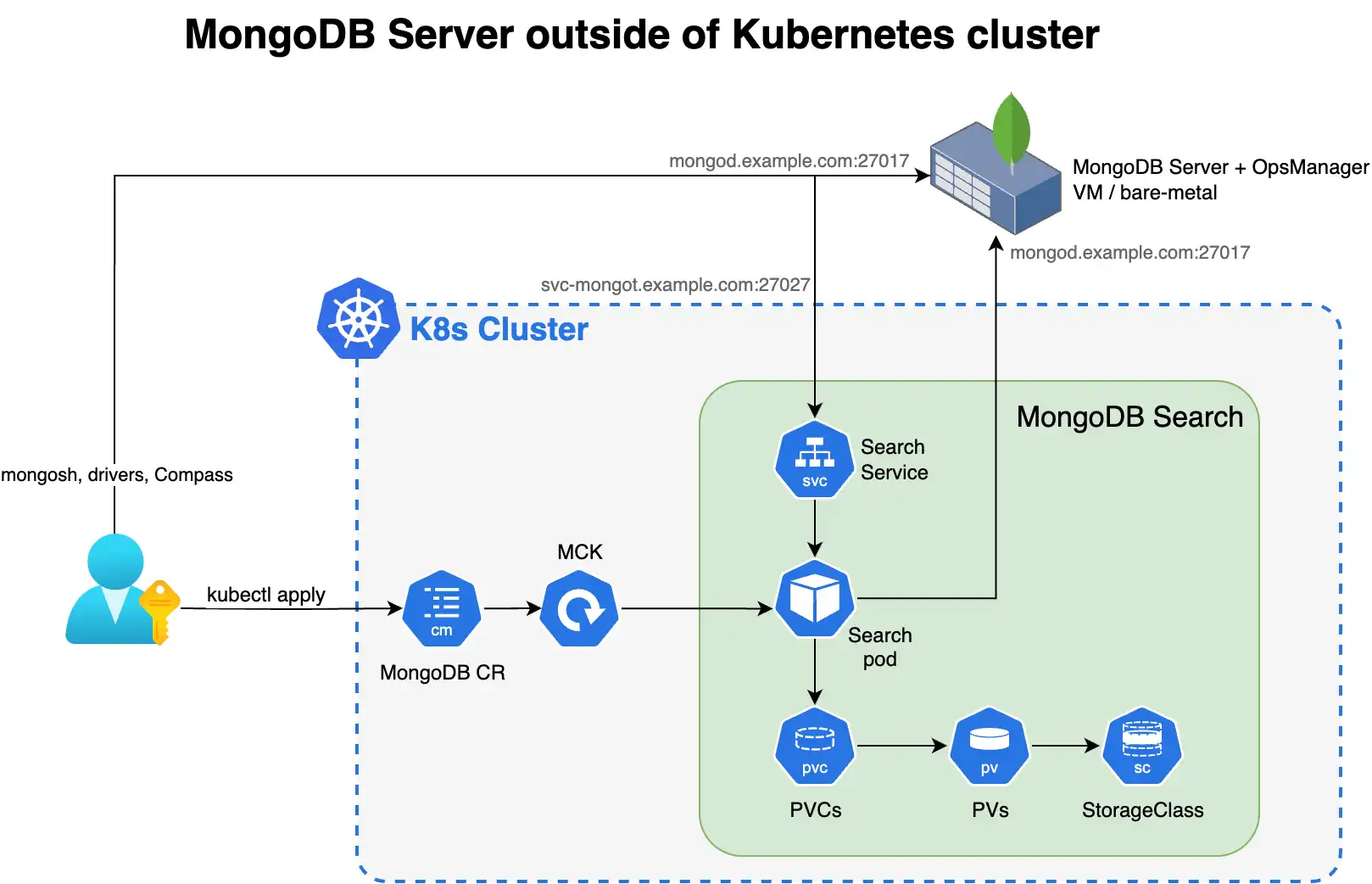
Para usar MongoDB Search y Vector Search cuando su implementación de MongoDB se encuentra fuera de Kubernetes, implemente mongot usando el Operador de Kubernetes y realice algunos pasos manualmente. El Operador de Kubernetes se encarga de la configuración de los pods de búsqueda. Sin embargo, cuando la implementación de MongoDB está fuera de Kubernetes, debe reconfigurar sus nodos de MongoDB y la red.
Usted es responsable de las siguientes configuraciones manuales:
Configuración del conjunto de réplicas externas
Configura el siguiente parámetro mediante
setParameteren cada procesomongoddel set de réplicas externo. Al configurar, reemplaza<search-service-hostname>:27028con el nombre de dominio resolvible y el puerto reales de tu servicio MongoDBSearch.setParameter: mongotHost: "<search-service-hostname>:27028" searchIndexManagementHostAndPort: "<search-service-hostname>:27028" skipAuthenticationToSearchIndexManagementServer: false searchTLSMode: "disabled" # or "requireTLS" for TLS deployments useGrpcForSearch: true Para una única instancia
mongot(sin balanceador de carga),mongotHostapunta directamente al nombre de host del serviciomongot(<name>-search-svc:27028).Para múltiples instancias
mongotcon un balanceador de carga,mongotHostapunta al punto final del balanceador de carga en su lugar.Para los balanceadores de carga administrados, el operador de Kubernetes configura automáticamente el
mongotHostusandospec.source.mongodbResourceRef.Para implementaciones externas de MongoDB, debe establecer
mongotHosten el punto final del balanceador de carga que especificó enspec.loadBalancer.managed.externalHostnameospec.loadBalancer.unmanaged.endpoint.
Cree un usuario en el conjunto de réplicas externas para el proceso de sincronización de búsqueda. Este usuario debe tener el rol
searchCoordinator.- userName: "search-sync-source" password: "<your-search-sync-password>" database: "admin" roles: - role: "searchCoordinator" db: "admin"
Configuración de clúster fragmentado externo
Importante
En una implementación estándar de clúster fragmentado de MongoDB, los clientes se conectan solo a los mongos enrutadores y nunca directamente a los conjuntos de réplicas de fragmentos. Sin embargo, al mongot implementar, los mongot procesos de cada grupo de fragmentos se conectan tanto a los mongos enrutadores como a todos los mongod procesos de ese fragmento. Por lo tanto,debe exponer el conjunto de réplicas de cada fragmento directamente a los mongot procesos. Asegúrese de que las reglas de red y del firewall permitan la conectividad directa desde el clúster de Kubernetes a las instancias de cada mongod fragmento, y no solo a los mongos enrutadores.
Los valores shardName que especifique en spec.source.external.shardedCluster.shards deben seguir las reglas de nomenclatura de Kubernetes:
Contiene únicamente caracteres alfanuméricos en minúscula,
-o..Comience con un carácter alfabético y termine con un carácter alfanumérico.
No deben contener guiones bajos. Si los nombres de tus particiones de MongoDB usan guiones bajos, reemplázalos por guiones.
La longitud combinada de
MongoDBSearch.metadata.nameyshardNamedebe ser menor que 50 caracteres.
El shardName no tiene por qué coincidir exactamente con el nombre del fragmento en MongoDB. El operador de Kubernetes lo utiliza únicamente para nombrar los recursos de Kubernetes.
Cuando conectas MongoDBSearch a un clúster sharded externo, debes:
Configure
spec.source.external.shardedClusteren el CR MongoDBSearch con losmongoshosts del enrutador y los hosts del conjunto de réplicas por fragmento.Establezca los parámetros
mongotHostysearchIndexManagementHostAndPorten los procesosmongodde cada fragmento. Apunte cada fragmento a su propio grupomongot(o a su propio punto final de balanceador de carga si utiliza varias instanciasmongot).Garantizar la conectividad de red bidireccional entre:
Los nodos
mongodde cada fragmento y los podsmongotcorrespondientes (o balanceador de carga).Los pods
mongoty los enrutadoresmongos(para el enrutamiento de consultas).Los
mongotpods y losmongodnodos de cada fragmento (para la sincronización de datos).
Si utiliza un balanceador de carga administrado con un clúster fragmentado externo, especifique spec.loadBalancer.managed.externalHostname con un {shardName} marcador de posición (por{shardName}.search-lb.example.com ejemplo,). Exponga el servicio Envoy externamente para que los mongod nodos de cada fragmento puedan acceder a él mediante un nombre de host único para ese fragmento. El balanceador de carga lee el campo TLS SNI de las conexiones entrantes para determinar de qué fragmento proviene el tráfico y lo distribuye a los mongot pods que pertenecen a ese fragmento. Este enrutamiento basado en SNI es el único mecanismo que utiliza el balanceador de carga para distinguir el tráfico entre fragmentos, razón por la cual cada fragmento debe conectarse a través de un nombre de host diferente.
Configuración de Kubernetes
Configura y aplica el CR de MongoDBSearch con
spec.source.externalapuntando a tus hosts externos de MongoDB.Crea un secreto de Kubernetes para la contraseña del usuario de sincronización de búsqueda.
apiVersion: v1 kind: Secret metadata: name: search-sync-source-password stringData: password: "your-search-sync-password" Configure la red y el DNS para garantizar la conectividad bidireccional entre su MongoDB externo y los pods de búsqueda. Su entorno MongoDB externo debe poder resolver el nombre de host de su servicio de búsqueda
<search-service-hostname>().
Para obtener más información sobre la configuración de CR para que el mongot proceso se conecte a un mongod proceso externo, consulte Configuración de búsqueda de MongoDB y búsqueda vectorial.
Seguridad
La siguiente imagen ilustra la configuración de seguridad para el proceso mongot. Si el servidor MongoDB está dentro del clúster de Kubernetes, el operador de Kubernetes configura automáticamente la autenticación keyfile para MongoDB Search y búsqueda vectorial. Si el servidor MongoDB es externo, debes crear un secreto de Kubernetes que contenga la credencial keyfile del set de réplicas y referenciarlo en el CR MongoDBSearch .


Autenticación
El proceso mongot autentica las conexiones mongod mediante mTLS. Cuando habilitas el TLS, el proceso mongot utiliza el certificado TLS del servidor MongoDB como certificado de cliente para la autenticación. Este certificado se verifica en comparación con el certificado CA con el que está configurado mongot. Para que la autenticación funcione correctamente, debes configurar tanto mongot como mongod con TLS habilitado.
Al configurarse para indexar un recurso de MongoDB dentro del mismo clúster de Kubernetes, el operador de Kubernetes propaga automáticamente el certificado de CA mongod a mongot y habilita mTLS para las conexiones de consultas de búsqueda si tanto los recursos MongoDB como MongoDBSearch están configurados para TLS. Si el conjunto de réplicas de MongoDB se implementa fuera de Kubernetes, debe crear un secreto de Kubernetes que contenga el certificado de CA del conjunto de réplicas y referenciarlo en el campo MongoDBSearch.spec.source.external.tls.ca para habilitar la autenticación mTLS para las solicitudes de consultas de búsqueda.
Seguridad de capa de transporte (TLS)
MongoDBSearch puede proteger los datos y las credenciales en tránsito mediante TLS. Para los comandos de administración de índices y las consultas de búsqueda, configure el spec.security.tls campo y proporcione un certificado TLS. Puede dejar este campo vacío{} () para habilitar TLS con la configuración predeterminada.
Obsoleto desde la 1.8.0 versión: spec.security.tls.certificateKeySecretRef está obsoleto. Para implementaciones de conjuntos de réplicas, el operador de Kubernetes aún certificateKeySecretRef admite, pero debe migrar spec.security.tls.certsSecretPrefix a. Para implementaciones de clústeres fragmentados, no puede usar certificateKeySecretRef porque el operador de Kubernetes lee un mongot secreto de certificado de servidor independiente para cada fragmento.
spec.security.tls.certsSecretPrefix Es un campo opcional. Al especificarlo, el operador de Kubernetes antepone <certsSecretPrefix>- a todos los nombres de secretos de certificado que lee. El operador de Kubernetes lee los siguientes secretos de certificado:
mongot Certificados
Topología del clúster | mongot Certificado |
|---|---|
Set de réplicas |
|
Clúster fragmentado |
|
Certificados de balanceador de carga
Si se establece spec.loadBalancer.managed, el certificado del cliente del balanceador de carga es [<certsSecretPrefix>-]<name>-search-lb-0-client-cert. La siguiente tabla muestra los certificados del servidor del balanceador de carga:
Topología del clúster | Certificado |
|---|---|
Set de réplicas |
|
Clúster fragmentado |
|
El certificado TLS debe ser emitido y firmado por la misma CA que emitió el certificado de CA que utiliza el conjunto de réplicas de MongoDB.
Cuando tanto MongoDBSearch como MongoDB son implementados por el Operador de Kubernetes, la configuración subyacente mongot y mongod es gestionada en gran medida por el propio Operador de Kubernetes. Si implementa el conjunto de réplicas de MongoDB fuera del clúster de Kubernetes:
.spec.source.external.tlsEl campo debe rellenarse con un secreto de Kubernetes que contenga el mismo certificado CA que utilizó para configurar elmongod.searchTLSModeEl parámetro debe establecerse enrequireTLSen la configuraciónmongod.
Balanceador de carga mTLS
Sin un balanceador de carga, mongod se conecta directamente a mongot mediante mTLS. mongod presenta su propio certificado de cliente y mongot lo valida con una CA de confianza.
Si configura un balanceador de carga administradospec.loadBalancer.managed (), el proxy Envoy finaliza la conexión mTLS desde mongod y establece una nueva conexión mTLS mongot con. Debido a que el balanceador de carga finaliza y restablece la conexión, utiliza su propio certificado de cliente al conectarse mongot a, no el mongod certificado original. La mongot CA debe confiar en la autoridad de certificación que emitió el certificado de cliente del balanceador de carga. El operador de Kubernetes gestiona automáticamente la configuración TLS de Envoy. Requiere los siguientes certificados:
Certificado de servidor para el proxy Envoy, al que se
mongodconecta. El balanceador de carga utiliza este certificado para finalizar la conexión mTLS entrante.Certificado de cliente para el proxy Envoy, que el balanceador de carga presenta a
mongotal establecer la conexión mTLS ascendente.
Configure estos certificados como secretos de Kubernetes siguiendo la convención de nomenclatura spec.security.tls.certsSecretPrefix definida por. Consulte la configuración de búsqueda de MongoDB y la configuración de búsqueda vectorial para ver el patrón de nomenclatura completo.