caso de uso: IA genérica, Prevención del fraude
Industrias: Servicios financieros, Seguros, venta minorista
Productos y herramientas: MongoDB Atlas, clústeres deMongoDBAtlas, flujos de cambios de MongoDB, activadores deMongoDB Atlas,conector de transmisión de MongoDB Spark
emparejar: Databricks
Resumen de las soluciones
Esta solución muestra cómo compilar una aprendizaje automático-solución antifraude basada usando MongoDB y Databricks. Las principales características de la solución incluyen la completitud de datos a través de la integración con fuentes externas, el procesamiento en tiempo real para la detección oportuna de fraudes, el modelado de IA/aprendizaje automático para identificar posibles patrones de fraude, la supervisión en tiempo real para un análisis instantáneo y medidas de seguridad robustas.
El sistema facilita la facilidad de operación y fomenta la colaboración entre los equipos de desarrollo de aplicaciones y ciencia de datos. También es compatible con los CI/CD pipelines de extremo a extremo para garantizar sistemas actualizados y seguros.
Desafíos existentes
Las soluciones contra el fraude enfrentan los siguientes desafíos:
Visibilidad parcial de los datos desde los sistemas heredados: La falta de acceso a fuentes de datos relevantes dificulta la detección de patrones de fraude.
Problemas de latencia en los sistemas de prevención de fraude: Los sistemas heredados carecen de procesamiento en tiempo real, lo que provoca retrasos en la detección de fraude.
Dificultad para adaptar sistemas heredados: La inflexibilidad dificulta la adopción de tecnologías avanzadas de prevención de fraude.
Protocolos de seguridad débiles en sistemas heredados: la seguridad obsoleta expone las vulnerabilidades a ataques cibernéticos.
Desafíos operativos debido a la expansión técnica: La diversidad de tecnologías complica el mantenimiento y las actualizaciones.
Altos costos de operación de los sistemas heredados: El costoso mantenimiento limita el presupuesto para la prevención del fraude.
Falta de colaboración entre equipos: El enfoque en silos conduce a soluciones demoradas y mayores gastos en general.
El siguiente vídeo ofrece una visión general de los desafíos existentes y la arquitectura de referencia de la solución:
Arquitecturas de Referencia
La solución de fraude basada en aprendizaje automático es adecuada para industrias donde el procesamiento en tiempo real, el modelado de IA/aprendizaje automático, la flexibilidad y la colaboración entre equipos son esenciales. El sistema garantiza operaciones actualizadas y seguras a través de pipelines de CI/CD de extremo a extremo. Este sistema se puede aplicar a varias industrias, incluyendo:
Servicios financieros: Detección de fraude en transacciones
Comercio electrónico: Detección de fraudes en pedidos
Salud y seguros: Detección de fraudes en reclamaciones
El siguiente diagrama demuestra cómo interactúan MongoDB, AWS y Databricks para construir la arquitectura de la solución contra el fraude con tarjetas:

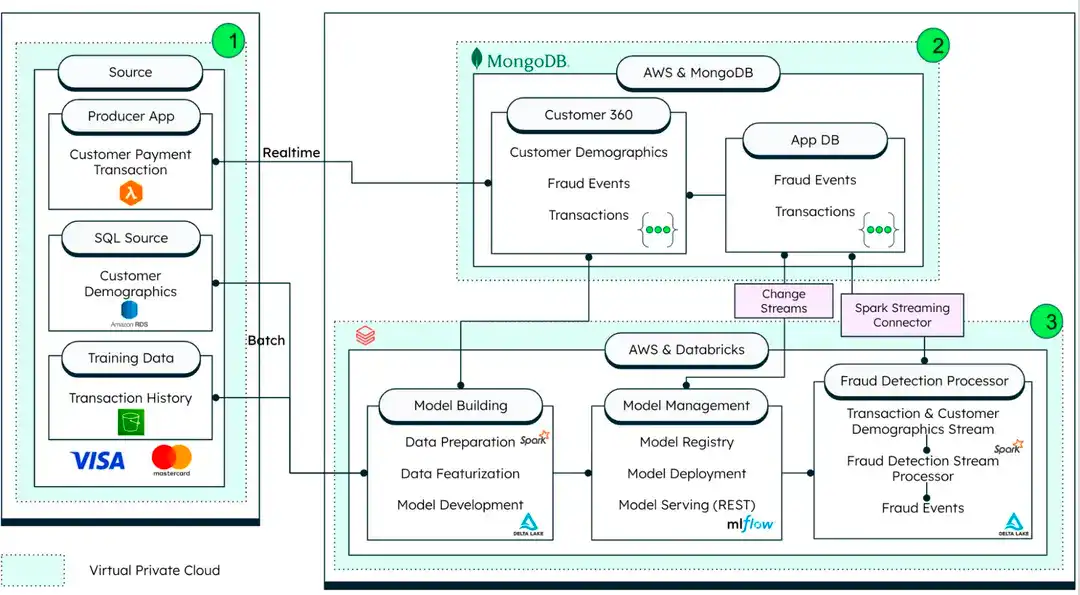
Figura 1. Arquitectura de soluciones para el fraude en tarjetas
Enfoque de modelo de datos

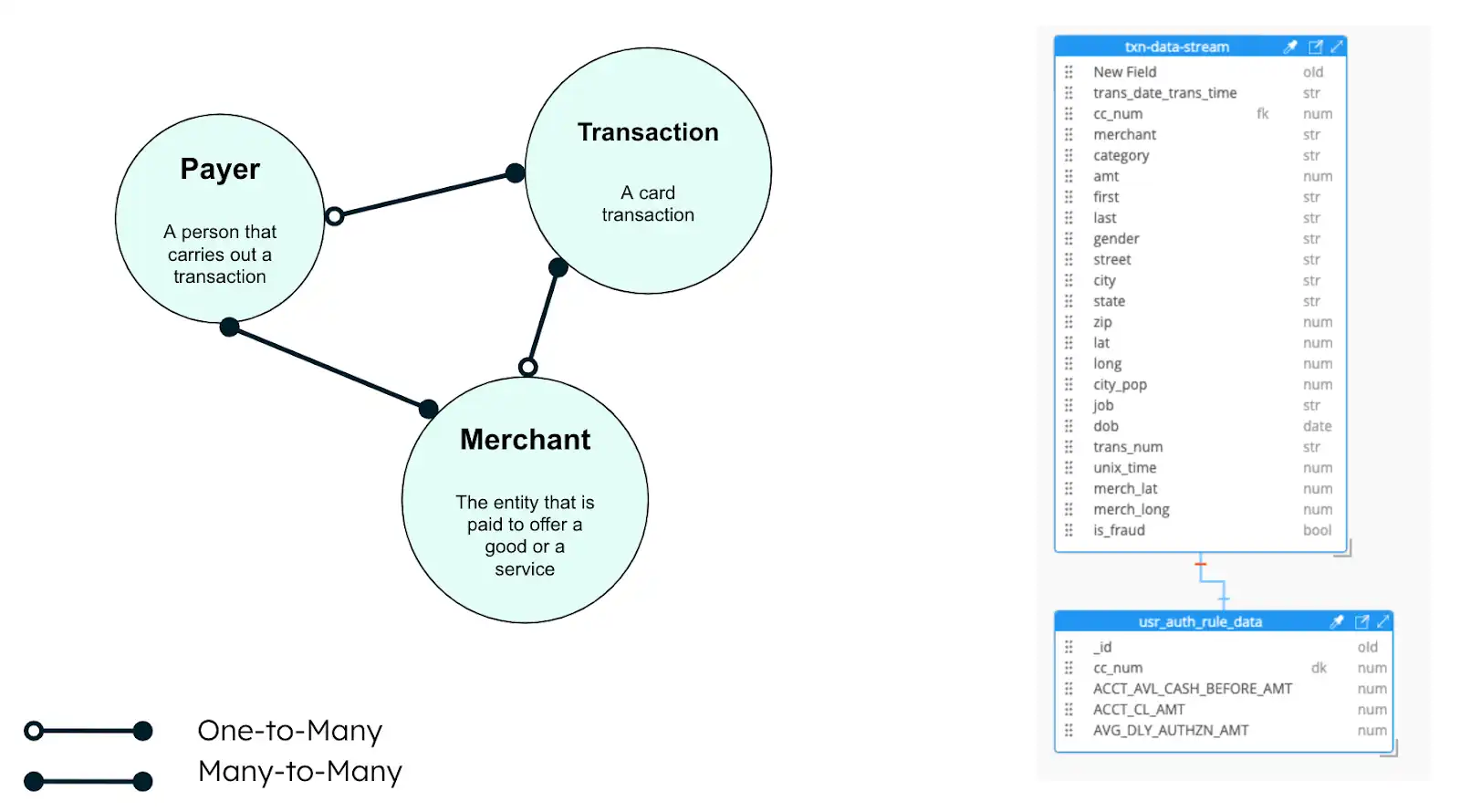
Figura 2. Modelo de datos de solución de fraude con tarjetas
El diagrama muestra tres entidades para las transacciones con tarjeta de crédito:
La transacción
El comerciante
El pagador
Las tres entidades utilizan el patrón de referencia extendida, que integra juntos campos de datos relevantes que se acceden con frecuencia. La aplicación de detección de fraude incluye campos de estas entidades en un solo documento.
Compilar la solución
La solución utiliza estos componentes:
fuente de datos
Aplicaciones de productor: La aplicación móvil del productor simula la generación de transacciones en vivo.
Fuente de datos heredada: La fuente de datos externa de SQL se usa para la demografía del cliente.
Datos de entrenamiento: los datos de transacciones históricas necesarios para el entrenamiento del modelo provienen del almacenamiento de objetos en la nube: Amazon S3 o Microsoft Azure Blob Storage.
MongoDB Atlas: sirve como el Almacén de Datos Operativos (ODS) para transacciones con tarjetas y procesa transacciones en tiempo real. La solución aprovecha el marco de agregación de MongoDB para realizar análisis dentro de la aplicación y procesar transacciones basadas en reglas preconfiguradas. También se comunica con Databricks para la detección avanzada de fraudes basada en IA/ML a través de un Spark Connector.
Databricks: Aloja la plataforma de IA/aprendizaje automático para complementar el análisis en la aplicación de MongoDB Atlas. El algoritmo de detección de fraude utiliza un notebook inspirado en el framework de fraude MLFlow de Databricks, y gestiona los MLOps para gestionar este modelo. El modelo entrenado es un endpoint REST.
fuente de datos
Primero, agrupe los datos de todas las fuentes relevantes, como se muestra en el diagrama de arquitectura anterior. El diagrama utiliza una arquitectura orientada a eventos para procesar datos de fuentes en tiempo real, como aplicaciones de productor, bases de datos SQL y conjuntos de datos históricos de entrenamiento.
Este enfoque permite obtener datos de aspectos como el resumen de transacciones, la demografía del cliente y la información del comerciante.
Además, esta arquitectura propuesta impulsada por eventos proporciona los siguientes beneficios:
Transacciones unificadas en tiempo real, que permiten recopilar en tiempo real datos de eventos de la tarjeta, como monto, ubicación y dispositivo de pago.
Ayuda a volver a entrenar los modelos de supervisión para combatir el fraude en tiempo real.
La aplicación productora es un script de Python que genera información de transacciones en vivo a una tasa predefinida.
MongoDB para la arquitectura de análisis controlada por eventos y orientada a la izquierda
MongoDB Atlas es una eficaz plataforma de bases de datos multi-nube para la clasificación de transacciones de fraude con tarjetas. Ofrece varias funcionalidades útiles, tales como:
Modelo de datos flexible para almacenar diversos tipos de datos.
Alta escalabilidad para satisfacer la demanda de transacciones.
Funcionalidades de seguridad avanzadas para apoyar el cumplimiento de los requisitos regulatorios.
Procesamiento de datos en tiempo real para la detección de fraudes rápida y precisa.
Implementación en la nube para almacenar datos más cerca de los clientes y cumplir con las regulaciones locales de privacidad de datos.
El MongoDB Spark transmisión Connector integra Apache Spark y MongoDB. Apache Spark, alojado por Databricks, permite el procesamiento y análisis en tiempo real de grandes cantidades de datos.
Change Streams y Atlas Triggers también tienen capacidades de procesamiento de datos en tiempo real. Puedes usar Atlas activador para invocar una llamada de servicio REST a un modelo IA/aprendizaje automático alojado en el marco Databricks MLFlow.
La solución de ejemplo gestiona la prevención de fraudes basada en reglas almacenando límites de pago definidos por el usuario y datos de configuración de usuario. Al filtrar las transacciones con estas reglas antes de invocar modelos de IA/aprendizaje automático, se puede reducir el costo de la prevención de fraudes.
Databricks como plataforma de operaciones de IA/ML
Databricks es una plataforma de IA/ML que desarrolla modelos para identificar transacciones fraudulentas. Una de sus características clave es la compatibilidad con análisis en tiempo real para sistemas modernos de detección de fraude.
Databricks incluye MLFlow, una herramienta para gestionar el ciclo de vida de aprendizaje automático de extremo a extremo. MLFlow permite a los usuarios rastrear experimentos, reproducir resultados e implementar modelos a escala, lo que facilita la gestión de flujos de trabajo complejos de aprendizaje automático.
MLFlow también proporciona observabilidad de modelos para el desempeño y la depuración. Esto incluye acceso a métricas y registros del modelo para mejorar la precisión del modelo con el tiempo. Estas características también apoyan el diseño de sistemas modernos de detección de fraudes basados en IA/aprendizaje automático.
Lecciones clave
Una solución contra fraude basada en ML con MongoDB y Databricks le proporciona las siguientes capacidades:
Integridad de los datos: Integrado con fuentes externas para un análisis de datos preciso.
Procesamiento en tiempo real: Habilita la detección oportuna de actividades fraudulentas.
Modelado de IA/ML: Identifica posibles patrones y comportamientos de fraude.
Monitoreo en tiempo real: Permite el procesamiento y análisis instantáneo de datos.
Observabilidad del modelo: Garantiza una visibilidad completa de los patrones de fraude.
Flexibilidad y escalabilidad: Se adapta a las cambiantes necesidades empresariales.
Medidas de seguridad robustas: protege contra posibles infracciones.
Facilidad de operación: Reduce las complejidades operativas.
Aplicación y colaboración en equipo de ciencia de datos: sincroniza los objetivos y la cooperación.
Soporte de pipeline CI/CD de extremo a extremo: Garantiza sistemas actualizados y seguros.
Autores
Shiv Pullepu, MongoDB
Luca Napoli, MongoDB
Ashwin Gangadhar, MongoDB
Rajesh Vinayagam, MongoDB