Overview
In this guide, you can learn the following foundational information about Apache Kafka and Kafka Connect:
What Apache Kafka and Kafka Connect are
What problems Apache Kafka and Kafka Connect solve
Why Apache Kafka and Kafka Connect are useful
How data moves through an Apache Kafka and Kafka Connect pipeline
Apache Kafka
Apache Kafka is an open source publish/subscribe messaging system. Apache Kafka provides a flexible, fault tolerant, and horizontally scalable system to move data throughout datastores and applications. A system is fault tolerant if the system can continue operating even if certain components of the system stop working. A system is horizontally scalable if the system can be expanded to handle larger workloads by adding more machines rather than by improving a machine's hardware.
For more information on Apache Kafka, see the following resources:
Kafka Connect
Kafka Connect is a component of Apache Kafka that solves the problem of connecting Apache Kafka to datastores such as MongoDB. Kafka Connect solves this problem by providing the following resources:
A fault tolerant runtime for transferring data to and from datastores.
A framework for the Apache Kafka community to share solutions for connecting Apache Kafka to different datastores.
The Kafka Connect framework defines an API for developers to write reusable connectors. Connectors enable Kafka Connect deployments to interact with a specific datastore as a data source or a data sink. The MongoDB Kafka Connector is one of these connectors.
For more information on Kafka Connect, see the following resources:
Building your First Connector for Kafka Connect from the Apache Software Foundation
Tip
Use Kafka Connect instead of Producer/Consumer Clients when Connecting to Datastores
While you could write your own application to connect Apache Kafka to a specific datastore using producer and consumer clients, Kafka Connect may be a better fit for you. Here are some reasons to use Kafka Connect:
Kafka Connect has a fault tolerant distributed architecture to ensure a reliable pipeline.
There are a large number of community maintained connectors for connecting Apache Kafka to popular datastores like MongoDB, PostgreSQL, and MySQL using the Kafka Connect framework. This reduces the amount of boilerplate code you must write and maintain to manage database connections, error handling, dead letter queue integration, and other problems involved in connecting Apache Kafka with a datastore.
You have the option to use a managed Kafka Connect cluster from Confluent.
Diagram
The following diagram shows how information flows through an example data pipeline built with Apache Kafka and Kafka Connect. The example pipeline uses a MongoDB cluster as a data source, and a MongoDB cluster as a data sink.
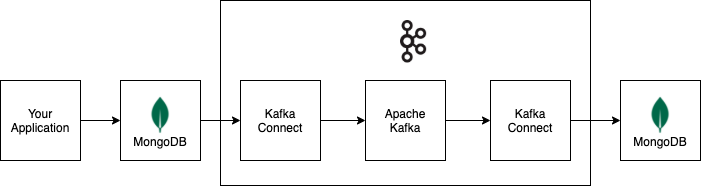
All connectors and datastores in the example pipeline are optional. You can replace them with the connectors and datastores you need for your deployment.