Multi-region Atlas deployments are clusters set up across more than one region. A multi-region deployment might have multiple regions within the same geography (a large area like a continent or country), or multiple regions in multiple geographies. Multi-region deployments:
Enhance protection in the case of a regional outage by automatically rerouting traffic to another region for continuous availability and a smooth user experience.
Improve performance and availability for some applications by locating data closer to users.
When considering if a multi-region deployment is right for you, you must assess the criticality of your application and how this corresponds to different RTO/RPO requirements. Resiliency exists on a spectrum between zero-downtime with a multi-region deployment to varying backup schedules on a single region deployment. The tradeoff is increased cost for more availability.
Refer to the Reliability section for more guidance on whether a multi-region deployment is right for your workload.
Note
Multi-region deployments are available only for M10 dedicated
clusters and larger.
Multi-Region Deployment Strategies
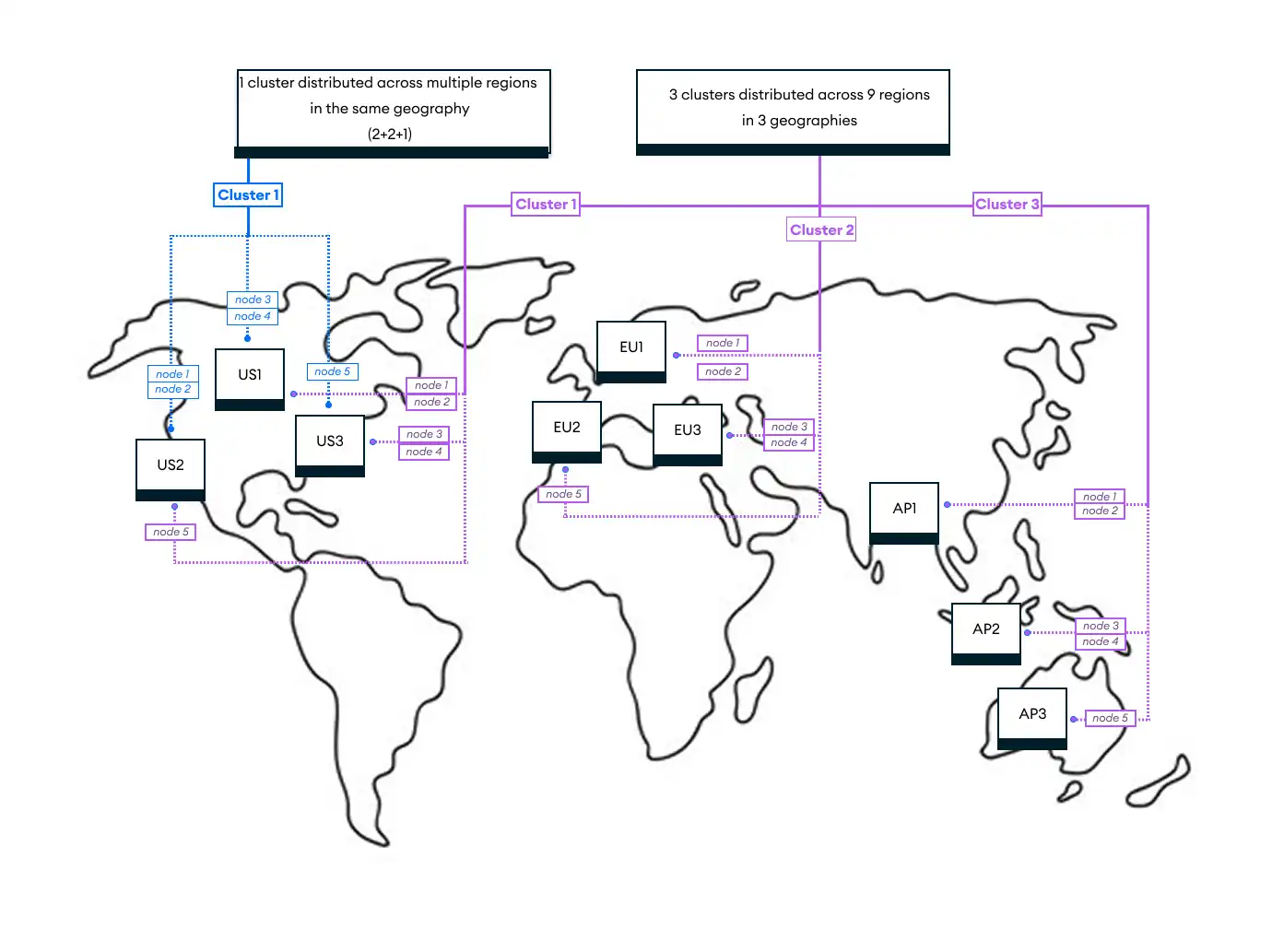
The following diagram shows 2 examples of a 2+2+1 topology, which is
discussed in detail below. It shows a single cluster with 5 nodes in 3
different regions: 2 nodes in US1, 2 in US2, and 1 in
US3.

5-Node, 3-Region Architecture (2+2+1)
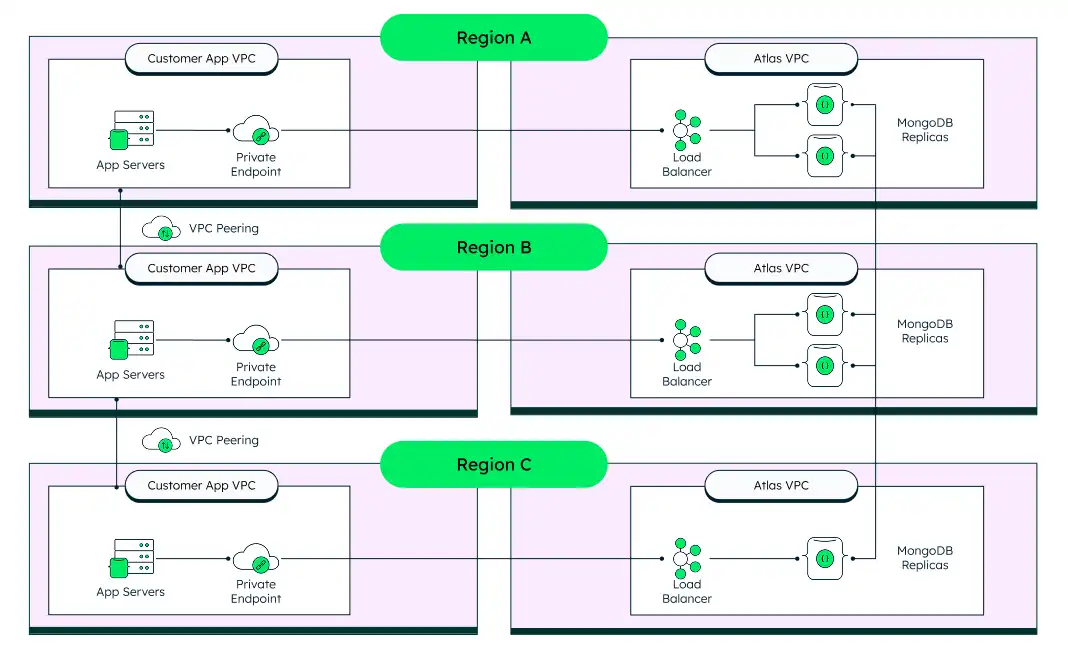
To achieve near-instant recovery in the case of a regional outage, we recommend an architecture that consists of a minimum of 5 nodes spread over 3 regions. This architecture ensures that regular maintenance operations can occur without forcing failover to a second region, while also ensuring automated failover and data loss protection in a full regional outage incident.
The following diagram shows details of this architecture:

Notes and Considerations
Use private endpoints to connect to the cluster, and VPC peering between your application server VPCs. VPC peering ensures that if a network connection is broken or Atlas in that region goes down, the application tier can still route to the primary node, first over the VPC peering, and then over the private endpoint.
This architecture has the highest cost due to network traffic between regions and having 5 or more data-bearing nodes.
This architecture provides the highest resiliency. There are no interruptions during Atlas operations (like an automated upgrade), and your application can sustain a full regional failure with no interruption and manual intervention required.
This architecture has the highest cost due to network traffic between regions and having 5 or more data-bearing nodes.
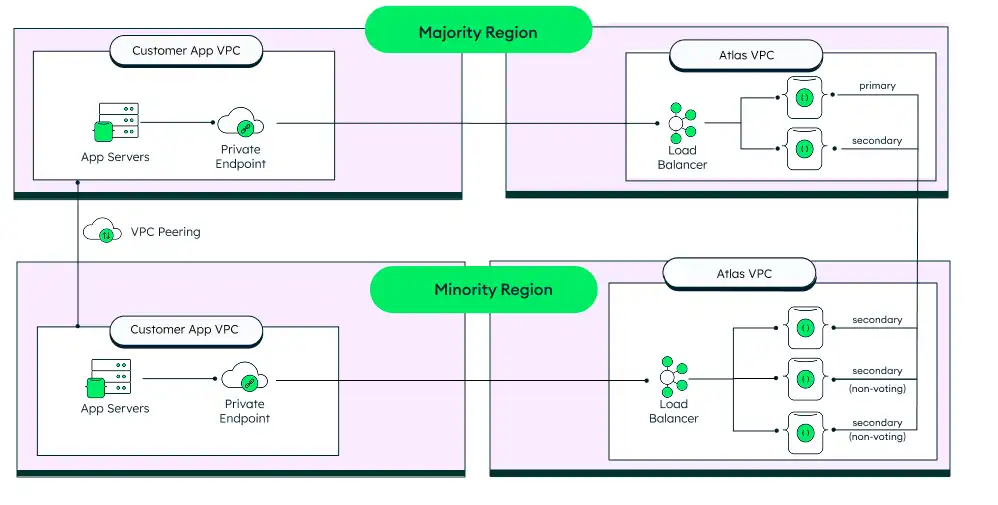
5-Node, 2-Region Architecture (2+3)
If your company is limited to only 2 regions, you can use a variation on the 5-Node, 3-Region architecture, in which you have 5 nodes distributed between two regions. The primary region has 2 electable nodes, and the secondary region has 1 electable node and and 2 read-only (non-voting) nodes.
This is not generally recommended if you can use 3 regions because the operator must manually intervene in order to failover if the majority region fails. However, it is an option for customers with only 2 approved regions.

Notes and Considerations
This architecture provides increased protection against data loss. If the minority region is lost, no user action is required because the majority region remains a fully functional cluster. If the majority region is lost, the system will still remain available in read-only mode until a majority of nodes are brought into an electable state. However, it may not provide complete data loss protection if some data has not yet been replicated to a secondary node after a failure. In this case, that data is unavailable until the primary region is recovered.
This architecture comes with some caveats:
If the majority region is lost, the minority region is not a fully-functional cluster; it does not have a primary and can only accept reads but not writes.
Because there is not a majority of voting nodes, it does not have a primary, and can only accept reads (not writes.)
To restore the functional cluster, an administrator needs to reconfigure the 2 read-only nodes to electable nodes. However, data loss is possible. During the outage, any new writes to secondaries are placed in a special collection for manual recovery. However, any writes to the primary that were not replicated to at least one secondary node before the primary went down are lost.To learn more, refer to Reconfigure a Replica Set During a Regional Outage or use the acceptDataRisksAndForceReplicaSetReconfig API parameter.
In sharded clusters, if your MongoDB process didn't replicate chunk migrations, the data inconsistency might cause orphaned documents.
Lower-Cost Variation
For further cost savings, you can design this architecture without the 2 read-only nodes. In addition to the caveats listed above, data size has a significant impact on your decision since the data needs to be synchronized to secondaries whenever adding new nodes to the cluster. For example, 1 TB of data averages 1 hour of recovery and synchronization time. We recommend having 2 read-only nodes in the minority region because they are already fully synchronized, and recovery to a fully functional cluster takes only seconds to minutes.
3-Node, 3-Region Architecture (1+1+1)
For less critical workloads that can tolerate interruptions, you can leverage a less expensive architecture by using 1 node in each of 3 regions. You have an electable node in each of the regions, which means if the primary node is unavailable, your cluster will fail over to a new region to ensure continued availability. However, if your app tier in the original primary region is still servicing user requests, there will be increased latency as requests are routed across multiple regions. Additionally, there will not be an ability to perform an optimized initial sync in the case of rebuilding a node.
Note
We do not generally recommend this configuration because regular, planned maintenance of Atlas nodes will cause temporary latency spikes.
Recommendations for Multi-Region Deployments
To learn how to configure multi-region deployments and learn about the different types of nodes you can add, see Configure High Availability and Workload Isolation in the Atlas documentation.
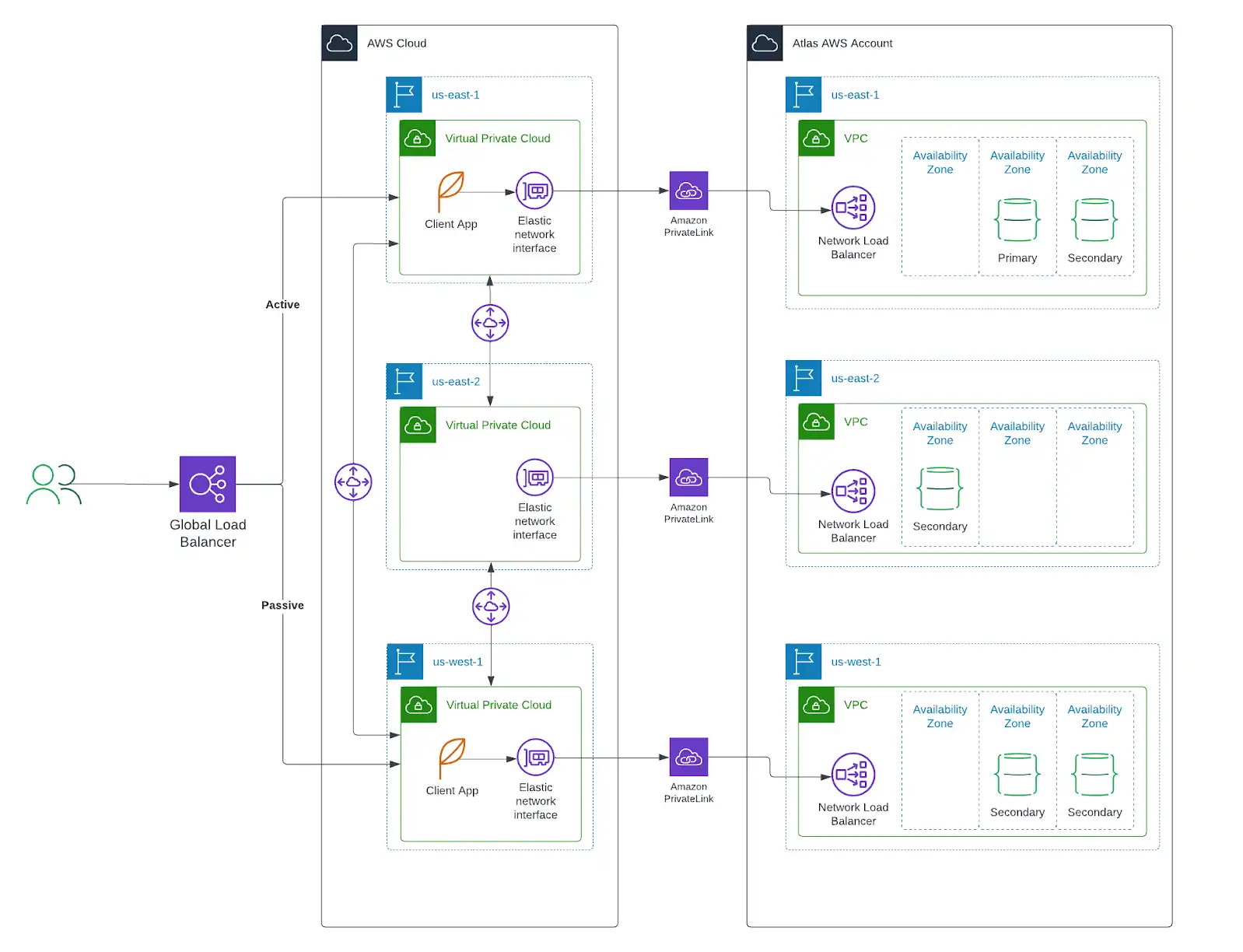
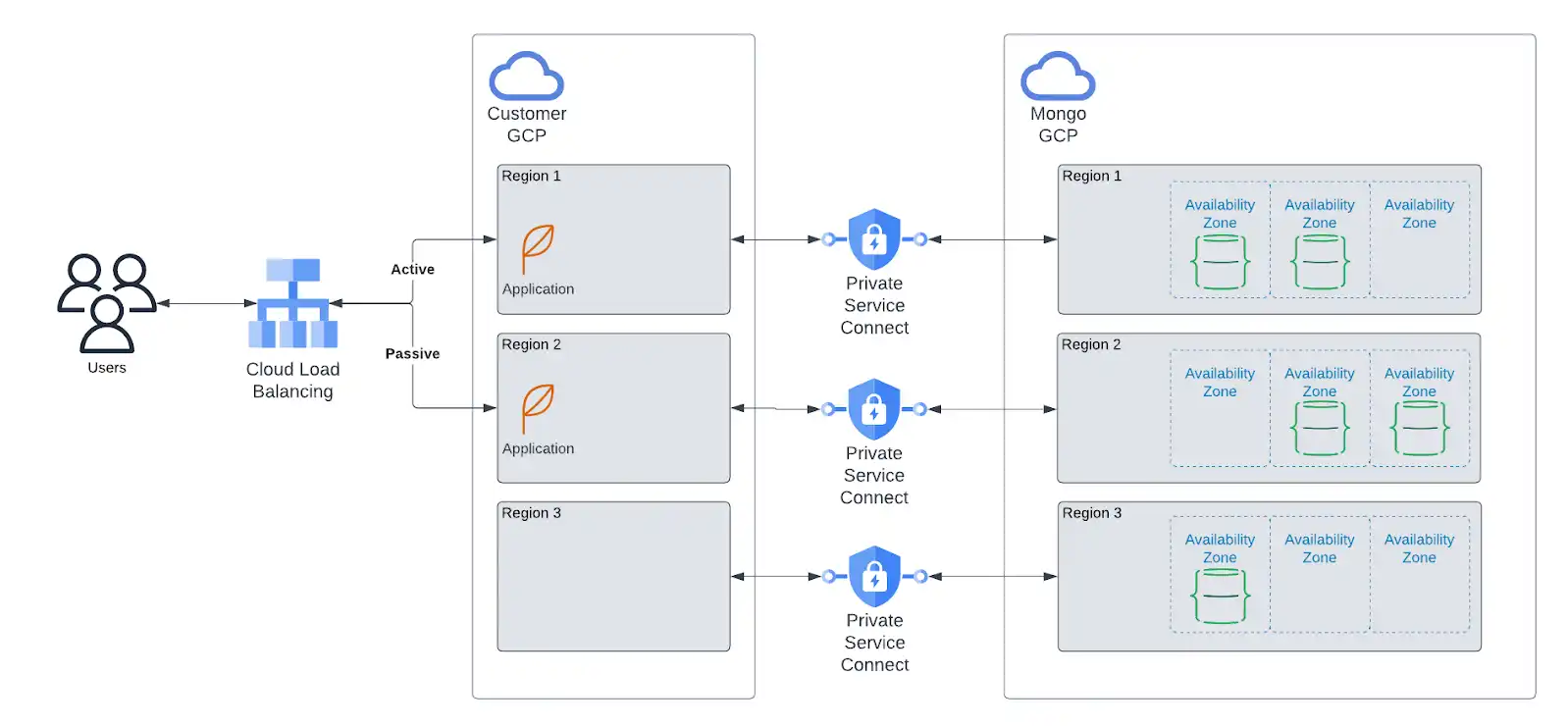
If your application is deployed on one of the following cloud providers, MongoDB strongly recommends that you deploy your Atlas resources to that same provider and region. Moreover, we suggest that you map the deployment of your application resources across regions to the deployment of your Atlas resources, as shown below.
Deploying your application resources alongside your Atlas resources:
Reduces latency for database operations executed by your application.
Allows for enhanced security with private endpoints that connect your self-managed cloud resources with your Atlas resources. Private endpoints offer the best level of network security, ensuring that traffic can only be initiated from your account.
Allows you more granular control over region-specific data storage.
Allows you to reroute traffic to healthy regions should an outage occur elsewhere.
To learn more about application and Atlas deployment recommendations, see:

Considerations
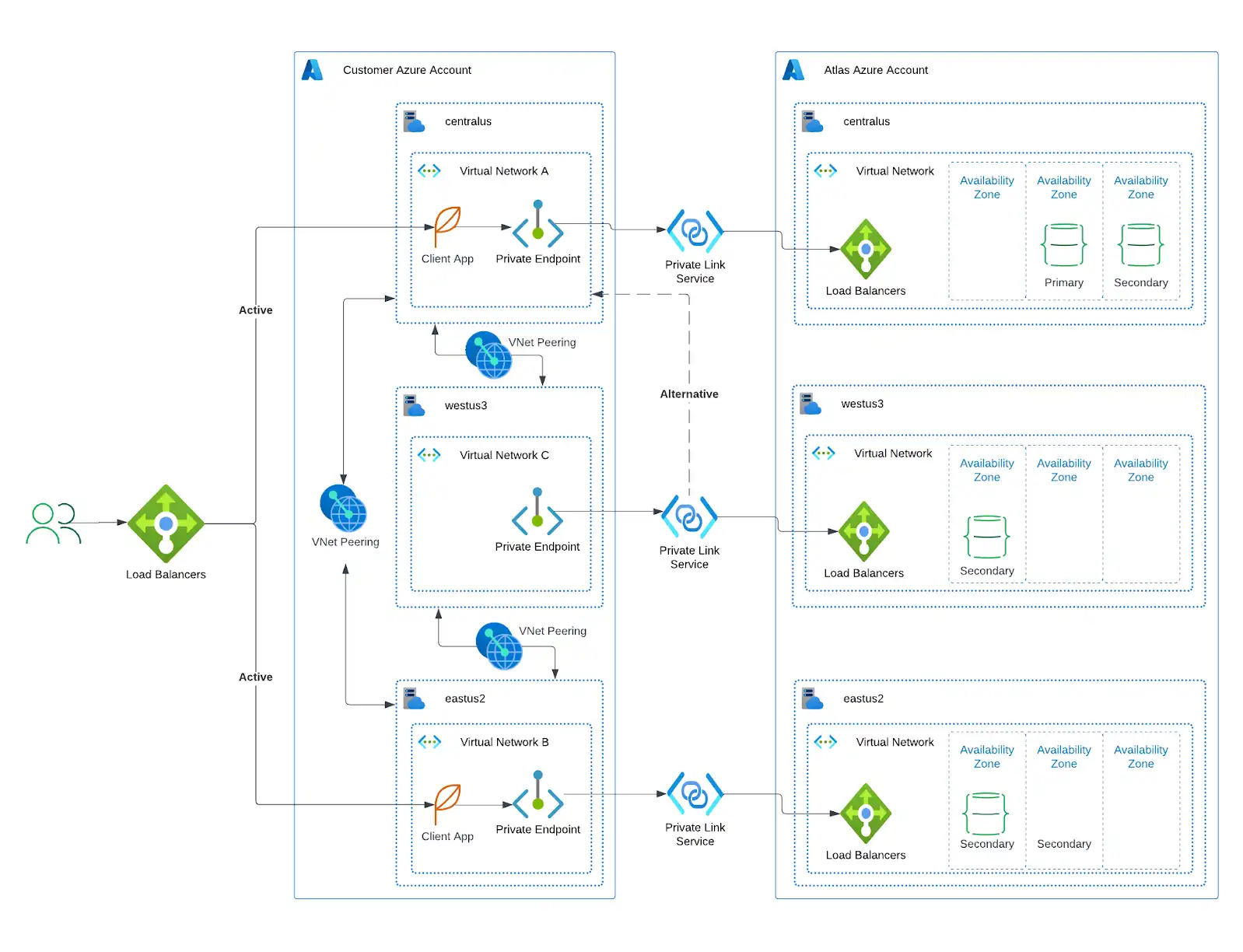
Azure supports cross-region private links.
You can create a link between multiple regions without the need for additional networking resources that would otherwise be required.
For example, if your application is deployed in
central-usandwest-us-3, and your Atlas cluster is deployed inwest-us-3andeast-us-2, you can create a private endpoint incentral-usthat links to the private link inwest-us-3.

To find recommendations for your Atlas cloud deployments, refer to the following resources:
Operational Efficiency
Security
Reliability
Performance
Cost Optimization