Choosing a deployment paradigm requires considering your application needs for availability (both in general and in case of an outage), latency, compliance, and cost. There is no one "correct" paradigm for deployment. This section explores the architectures available to you to help you meet your deployment needs.
When deploying your database, you must first choose between deploying to a single region or multiple regions. The following diagram shows these options, which are explained further below:
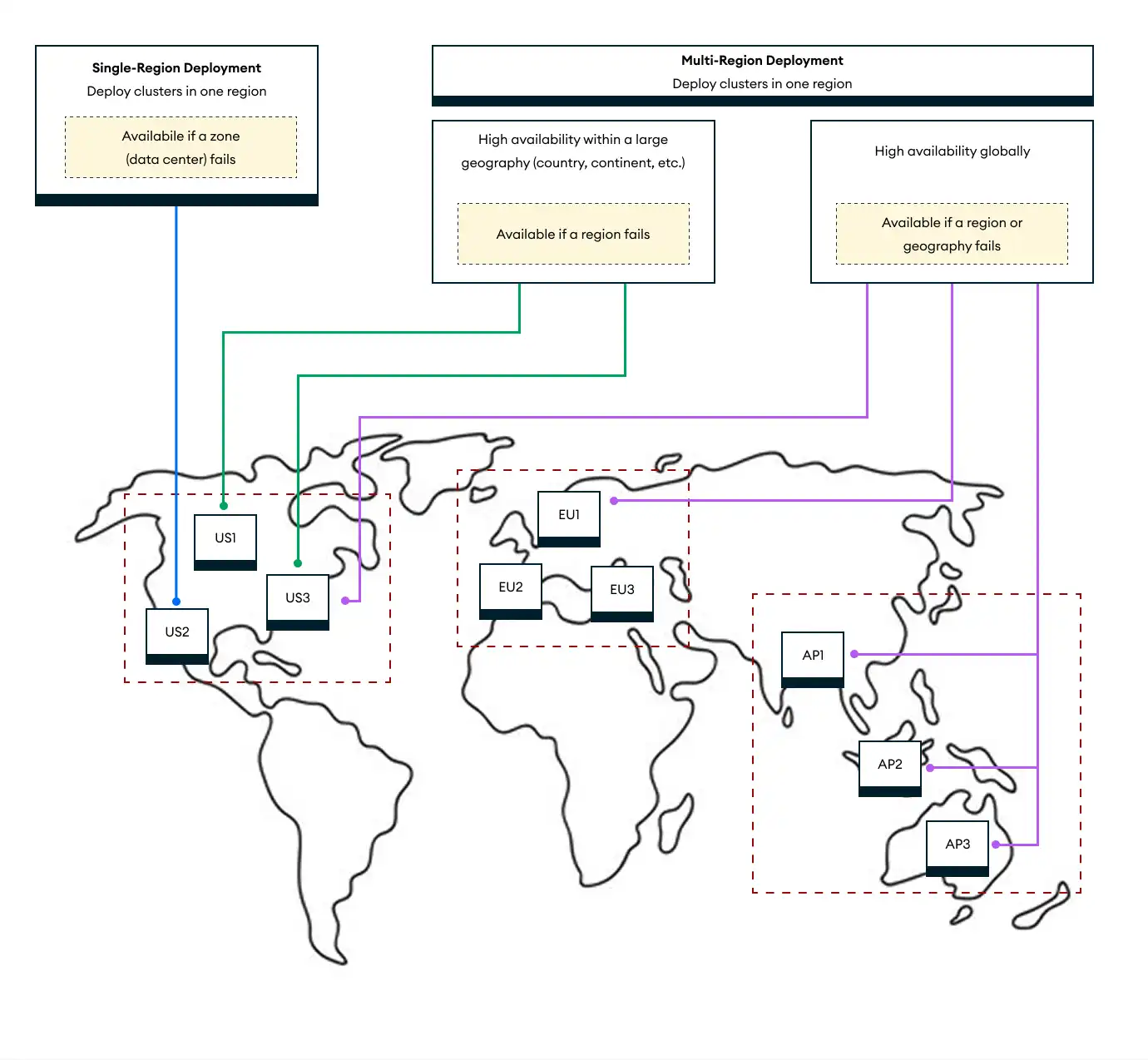
Single-Region Deployments
A Single-Region Deployment
is the simplest deployment option. In a single-region deployment, your
data is stored in one of a provider's regions (such as AWS's us-west-2
or Google's asia-northeast3). For those regions that have multiple
zones, Atlas always provides zone-level availability, your
cluster nodes are spread across the availability zones within a single
region. Therefore, if a single zone fails, your data is still available
in the other zones.
Note
Recommended regions have three availability zones, and are marked with a star icon in the Atlas UI.
With the simplicity and lower cost of a single-region deployment comes the risk of lower availability and potentially higher latency, depending on the distribution of your application's users.
Multi-Region Deployments
A multi-region deployment is a more complex deployment paradigm that provides higher availability and low latency across a larger geographic range than a single-region deployment. There are several types of multi-region deployments:
Multi-region in one geography: Deploys to multiple regions hosted by a single cloud provider within a single geography, defined as a large area like a country or continent. This ensures availability if any given region fails.
For example, you deploy clusters to the AWS regions
us-west-1andus-east-1, both of which are in the United States. Ifus-east-1becomes unavailable,us-west-1will continue to accept reads and writes at close to normal performance.Multi-region in multiple geographies: Deploys to one or more regions in two or more geographies. This ensures availability if any given region fails, or if an entire geographic area is unavailable.
For example, you deploy clusters in the AWS regions
us-east-1andus-east-2, both of which are in the United States, and a third cluster ineu-west-2, which is in Europe.Multi-cloud : Deploys to one or more regions hosted by multiple cloud providers. This provides the highest level of availability, ensuring your data is available if any given region fails or if an entire cloud provider fails.
For example, you deploy clusters in the AWS region
us-west-1and the Google Cloud regionus-east4.
Availability Considerations
Availability is often considered in terms of how resilient your clusters are to disruptions, while disaster recovery is how quickly your system can recover from an outage (RTO) and how much data might be lost in an outage (RPO). Because all Atlas instances always have current data, failovers do not require restoring of backups.
Atlas has replication built into your deployments, which means:
Database instances are kept tightly in sync with each other, typically in the range of milliseconds.
In the event of an outage, failover between database instances is fully automatic. It requires no human intervention, and takes only seconds.
When using the default writeConcern of
majority, then no data loss occurs during failover because all data was written to multiple locations preventing data loss. Additionally, the DB driver will automatically re-try any in-flight operation to ensure that they succeed.
This means that the RTO, RPO and Data Replication Frequency are effectively equal and your Atlas clusters are fully operational as long as a majority of the nodes are healthy.
Note
The maximum RTO and RPO should be considered holistically across both the entire cluster and how you deploy your application. Consider the full workload of your cluster to ensure it will support your requirements.
Deployment Paradigm Comparison
To figure out which deployment pattern is right for you, break down your applications by how critical they are to your core business. The more important the application (in other words, the more impact an outage has on your business), the more you should consider an architecture that automatically handles any outage event.
The following table provides a comparison of deployment paradigms to help you determine the best fit for your needs:
Priority Level | Description | RTO | Deployment Model | Relative Cost |
|---|---|---|---|---|
Tier 0 | Highest criticality applications. Requires fully-automated failover even in the event of regional outages. | 0 | $$$ | |
Tier 1 | Lower criticality applications. Can experience some downtime or maintenance windows without significant revenue impact. | > 1 hour and < 8 hours | $$ | |
Tier 2 | Lowest criticality applications. Can be down for 24 hours without significant revenue impact. | > 8 hours | $+ | |
Non-Production | Noncritical applications. Environments that are not directly responsible for revenue and are not customer-facing. Typically development and testing environments. | n/a | $0 and up |
Note
The cost of each deployment type depends on several factors, including the provider(s) you select, the number of regions you need, the amount of storage, and the processing power of the servers. For the latest pricing information, refer to the MongoDB Pricing.
Use Cases
When choosing your deployment paradigm, start by identifying the smallest number of regions that you can deploy to serve the widest geographical distribution of your users. Then, consider adding additional regions or cloud providers according to your requirements for availability, performance, and data sovereignty.
Consider the following use cases to help decide which deployment paradigm works for the geographical distribution of your application's users:
Users Mostly in One Geography
If the majority of your application's users are located in one geography, we recommend that you deploy to one or more regions within the same geography. While a single-region deployment can protect against an outage in a single availability zone, a multi-region deployment covers a larger geographical area and ensures availability during both zonal and regional outages. For even higher availability, you can deploy across multiple regions. These options all support low latency and simplify compliance with data sovereignty requirements because all user data is accessed and stored within the same geography.
To learn more about these deployment paradigms, see the following paradigm pages:
Users Distributed Across Multiple Geographies
If your application's users are distributed across multiple geographies, such as between the US and Europe, we recommend that you deploy to one or more regions in each geography. Deploying to one region in each geography where you serve customers provides low latency and availability in case of a geographical outage. You can also meet data sovereignty requirements by partitioning your data so that user data from each geography is hosted within that geography.
To ensure high availability in case of regional outages without increasing latency or violating data sovereignty requirements, you can also deploy to multiple regions in each geography. You can achieve the highest availability for a multi-region deployment by deploying clusters to multiple regions, in multiple geographies.
To learn more about these deployment paradigms, see the following paradigm pages:
Users Distributed Worldwide
If you are deploying an application to a worldwide audience, we recommend that you deploy a multi-region deployment across multiple geographies before considering a global deployment. In almost all cases, a multi-region deployment in multiple geographies can fulfill your requirements for high availability, low latency, and data sovereignty. In rare cases, you might need global Atlas deployments, which are the most complex multi-region deployment paradigms and require very careful planning.
To learn more about these deployment paradigms, see the following pages: