- Latest
- Highest Rated
Tutorial
RAG Evaluation: Detecting Hallucinations With Patronus AI and MongoDB
Detect hallucinations with Patronus AI's Lynx model and MongoDB Atlas. Use HaluBench for RAG system evaluation and implement generative AI apps.
Aug 15, 2024
Tutorial
Adding Semantic Caching and Memory to Your RAG Application Using MongoDB and LangChain
This guide outlines how to enhance retrieval-augmented generation (RAG) applications with semantic caching and memory using MongoDB and LangChain.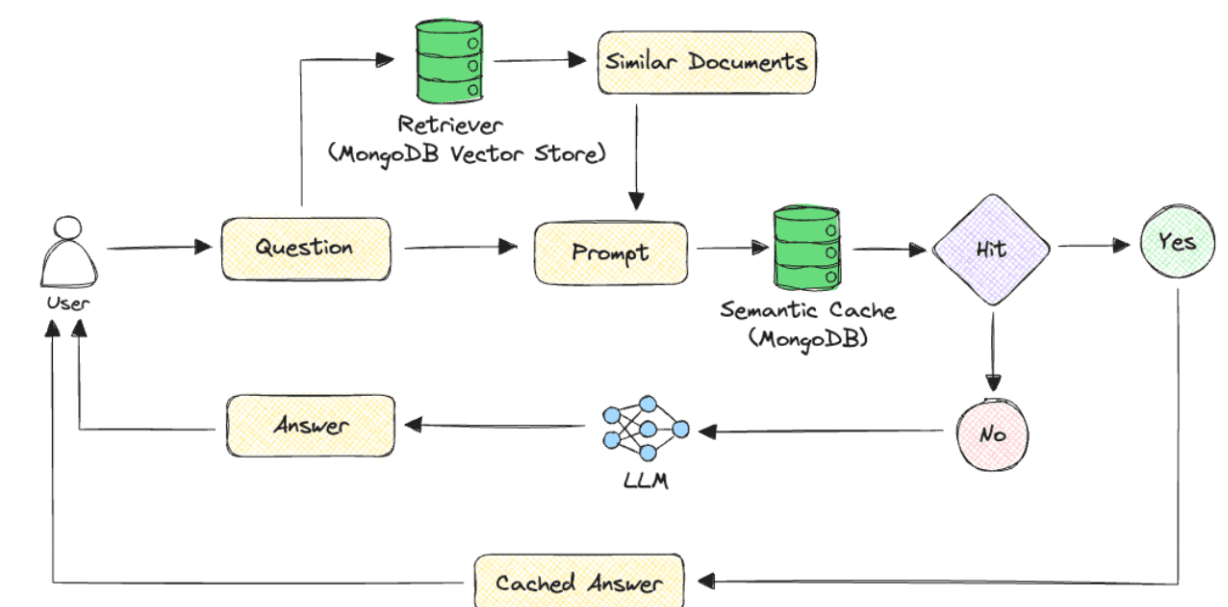
Aug 13, 2024
Tutorial
Building an AI Agent With Memory Using MongoDB, Fireworks AI, and LangChain
Leverage the capabilities of Fireworks AI, MongoDB, and LangChain to construct an AI agent that responds intelligently and remembers past interactions.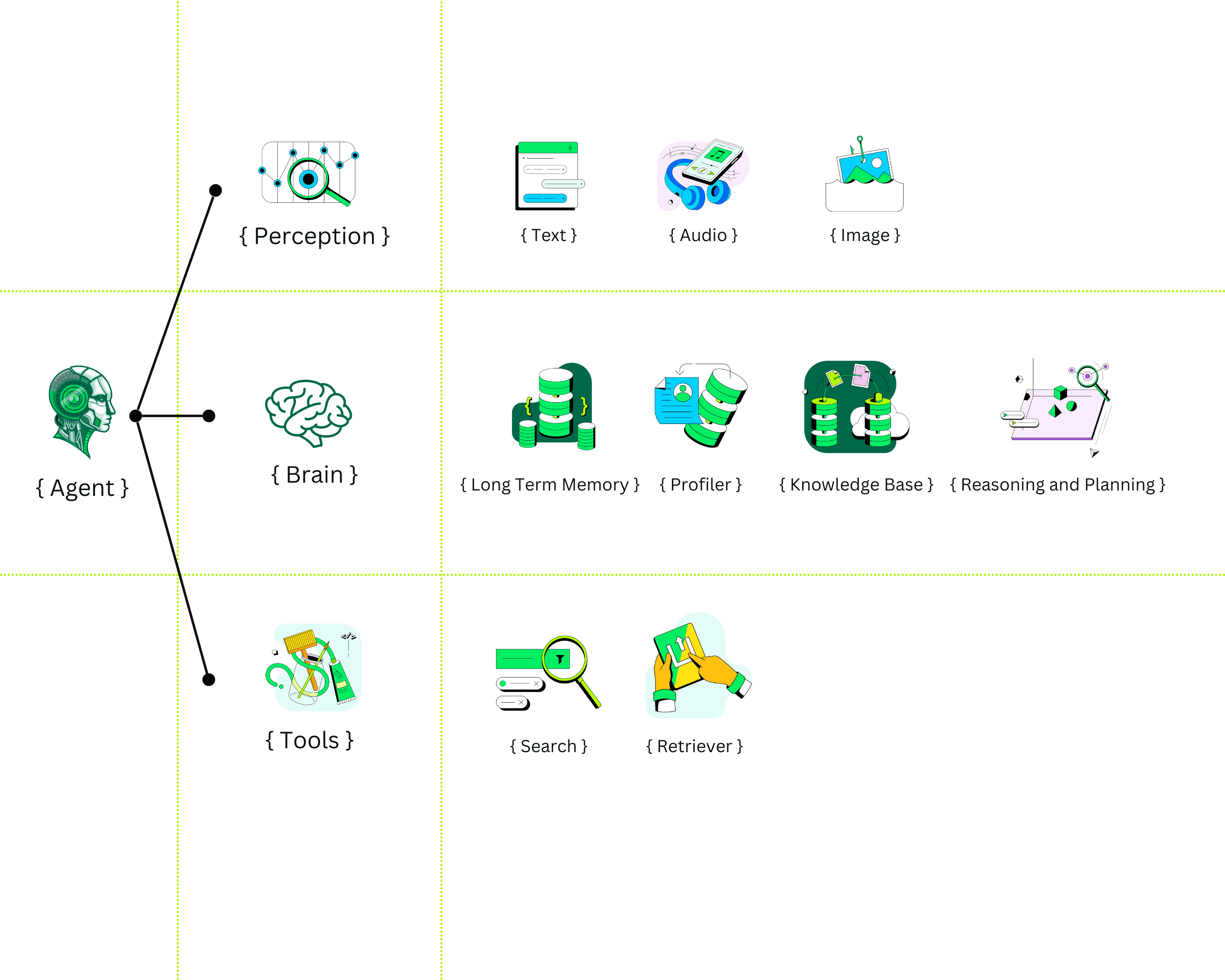
Aug 12, 2024
Tutorial
Confessions of a PyMongoArrowholic: Using Atlas Vector Search and PyMongoArrow to Semantically Search Through Luxury Fashion Items
Learn how to use PyMongoArrow and MongoDB Atlas Vector Search to semantically search through luxury items from the website Net-A-Porter.
Aug 09, 2024
Tutorial
How to Implement Agentic RAG Using Claude 3.5 Sonnet, LlamaIndex, and MongoDB
Learn to build advanced AI systems using Claude 3.5 Sonnet, LlamaIndex, and MongoDB. Implement agentic RAG for dynamic, tool-using AI applications with vector search capabilities.Jul 02, 2024
Tutorial
Using OpenAI Latest Embeddings in a RAG System With MongoDB
Explore OpenAI's latest embeddings in RAG systems with MongoDB. Learn to enhance AI responses in NLP and GenAI with practical examples.
Jul 01, 2024
Tutorial
How to Evaluate Your LLM Application
In this tutorial, we will see how to evaluate LLM applications using the RAGAS framework, taking a RAG system as an example.
Jun 24, 2024
Tutorial
Beyond Vectors: Augment LLM Capabilities With MongoDB Aggregation Framework
This article explores how MongoDB's aggregation framework overcomes the limitations of classic RAG by enabling direct analysis of entire collections within MongoDB.
Jun 20, 2024
Tutorial
How to Optimize LLM Applications With Prompt Compression Using LLMLingua and LangChain
Optimize LLM applications by implementing prompt compression techniques using LLMLingua and LangChain, reducing token count and operational costs without compromising response quality. This tutorial covers the definition, implementation, and benefits of prompt compression in LLM applications, RAG pipelines, and AI agents.Jun 18, 2024
