In the relentless race to build more powerful AI, the standard playbook has been simple: bigger is better. To make a model smarter, we’ve historically just made it larger by adding more layers, more neurons, and more parameters. But this dense approach hits a massive wall. If you scale a model to trillions of parameters, and every single one has to fire for every single token, you end up with a system that is prohibitively slow and expensive.
The solution lies not in larger models, but in building sparser, more interoperable ones. This post will bridge the gap between the fundamental "brain" of AI and two advanced architectural leaps - Mixture of Experts (MoE) and shared embedding spaces - culminating in how the Voyage-4 series uses these techniques together to redefine efficiency.
High-level foundations: The "brain" of AI
To understand why advanced architectures like MoE are necessary, we first need to establish the core mechanics of how machines learn.
At the heart of modern AI is the neural network, a structure designed to mimic the human brain. Information flows from an input layer, through hidden layers where processing happens, to an output layer that makes a prediction. This processing is controlled by parameters - the collective term for the model's internal weights and biases. Think of these as the "knobs and dials" of the model's decision-making process.
Weights and biases
To visualize them, imagine you are scoring a house to decide if you should buy it:
- Weights (the importance multipliers): These determine how much influence a specific feature has on your score.
- Example: "Square Footage" is crucial, so it gets a high weight (for example, 10). "Color of the Front Door" is trivial, so it gets a low weight (for example, 0.1). If you want a mental model, imagine you give each feature a simple 0 to 10 score, and the weight just scales how much that feature counts.
Biases (the baseline value): This is the inherent value or starting point, independent of the specific variable features.
- Example: The house sits on land worth $1 million. This is a huge positive bias. Even if the house itself is a rundown shack (low weighted inputs), the total score remains high because the baseline (the land) provides so much value.
- Conversely, if the property comes with a significant debt or lien attached to the title, it has a negative bias. The house structure needs to be incredible (high weighted inputs) just to bring the total value into the positive.
MoE explained: Intelligent sparsity for deep learning
Mixture of Experts (MoE) is an architecture pattern that some deep learning models use, from LLMs like Mixtral 8x7B generating text, to embedding models like voyage-4-large encoding text into vectors.
The dense scaling problem
Every deep learning model eventually hits the same wall: dense scaling.
In a standard dense model, every parameter activates for every input. Want a smarter model? Add more parameters. But then you pay the price in speed and cost for everything you process. It's a brutal trade-off: capability vs. efficiency.
MoE breaks this trade-off by introducing sparsity. Instead of activating the entire network, MoE routes each input to only a small subset of specialized "experts." The result? You get the capacity of a massive model with the compute cost of a much smaller one.
Figure 1. Dense model vs. sparse model (MoE). Image credit: “A Visual Guide to Mixture of Experts” blog.
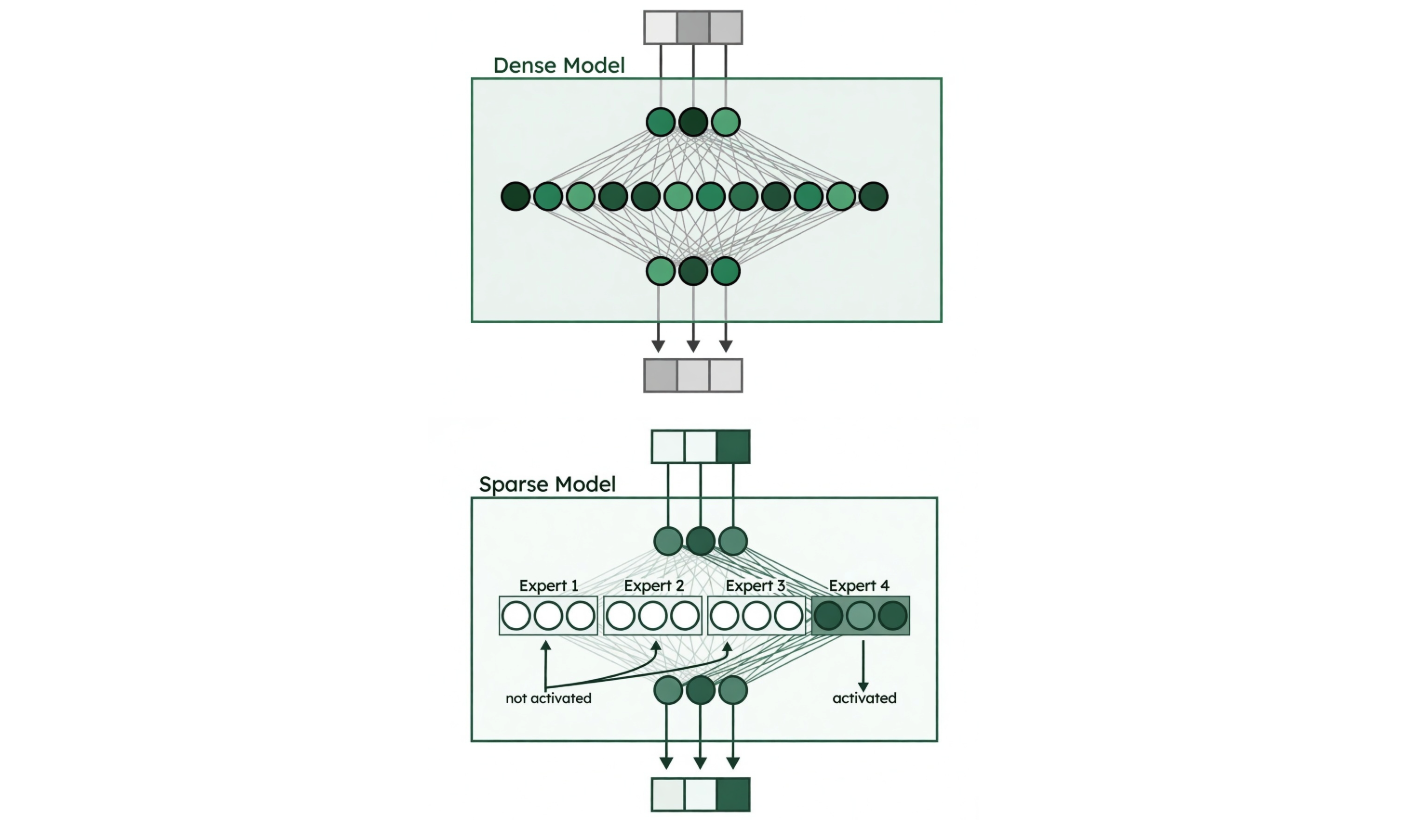
How it works: Replace dense layers with expert layers
In transformers, MoE typically replaces the Feed-Forward Network (FFN) layers with multiple smaller expert networks running in parallel. Each expert learns to specialize in processing specific patterns during training.
Important: Experts are not "domain experts" in subjects like Biology or History. Instead, each expert is a neural subnetwork that learns to specialize in certain statistical patterns in the data. They're essentially functional specialists that learn computational patterns - like a team of technicians where each member gets better at handling certain kinds of patterns - though these specializations are usually statistical and not directly interpretable. There’s a router that dynamically selects a small subset of these experts for each token, allowing the model to scale capacity without activating the entire network.
What do experts actually specialize in?
They don't specialize in topics like sports or science. Instead, they learn computational patterns such as:
Spatial relationships ("on", "under", "above")
Numerical patterns
Token frequency (one expert may activate for common words, another for rare terms)
Token distributions (for example, tokens that frequently appear together, like “New” and “York”)
When processing "the cat sat on the mat," one expert might activate "on" while another binds "cat" with "sat." These same experts apply across completely different topics - that's what makes them reusable and efficient.
Figure 2. Experts in sparse models. Image credit: “A Visual Guide to Mixture of Experts” blog.
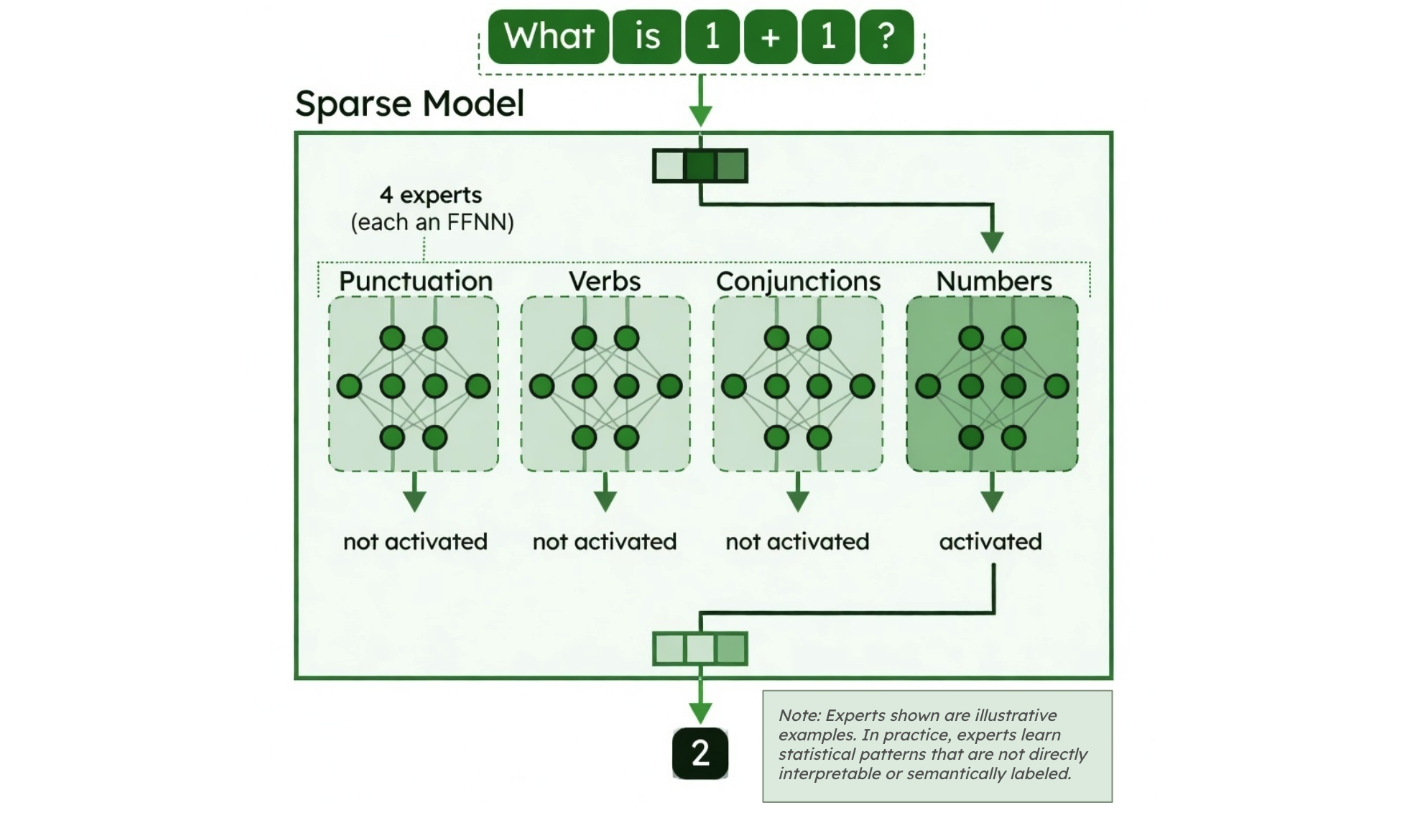
The routing process
Figure 3. Routing in MoE. Image credit: “A Visual Guide to Mixture of Experts” blog.
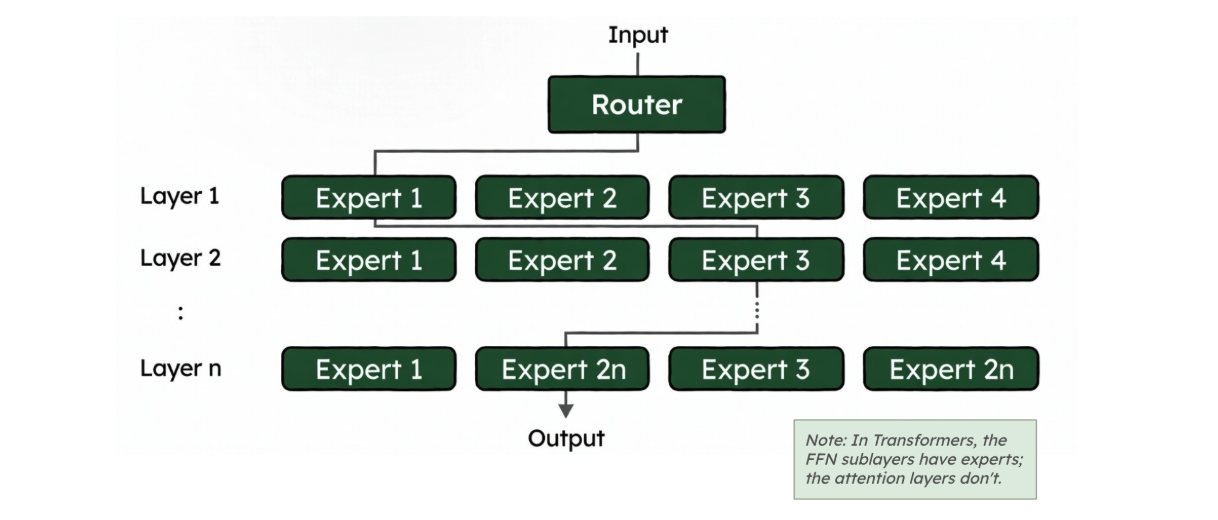
During both training and inference, when a token reaches an MoE layer, it goes through a router (or gating network) that dynamically selects which experts should process it:
Route: The router evaluates all available experts and selects the top-k most relevant ones for that specific token
Compute: Only the selected experts process the token - the rest remain inactive
Combine: The outputs are merged (weighted by the router's confidence scores) and passed forward
This happens independently for each token at each MoE layer, so different tokens in the same sequence can be processed by different expert combinations.
A simple analogy: Task force vs. full committee
Think of it like a work assignment:
Dense model = full committee: Every member participates in every decision. When processing "running" , all parameters activate, even if only some are relevant.
MoE model = task force: The router identifies which small subset of experts fits best, and only those are activated.
Note: Within the Voyage-4 series, the advanced mixture-of-experts (MoE) architecture is exclusive to the flagship voyage-4-large model, whereas the remaining models in the family utilize optimized dense architectures.
The interoperability innovation: Shared embedding spaces
While MoE optimizes how a model runs internally, we still face a major challenge when trying to use multiple embedding models together: interoperability. To solve this, the Voyage 4 series introduces an industry-first capability: shared embedding spaces.
The compatibility gap
Embeddings are the translation layer of AI, internalizing and then converting text or images into lists of numbers (vectors) where similar concepts are mathematically close. The reason why embedding architecture matters so much is that enterprise AI applications are often constrained by the retrieval step - i.e., the quality of the embeddings - rather than the LLM. If your system retrieves the wrong documents, even the smartest LLM cannot generate an accurate answer.
Historically, every AI model has its own unique coordinate system. Model A's vectors are complete gibberish to Model B. If you index billions of corporate documents using a massive, expensive model, you are locked in. You must use that exact same expensive model to process every single daily user search query. If you ever want to switch to a cheaper or faster model for queries, you are forced to re-embed your entire corpus from scratch.
Unlocking asymmetric retrieval
Figure 4. Shared embedding space in Voyage-4 models.
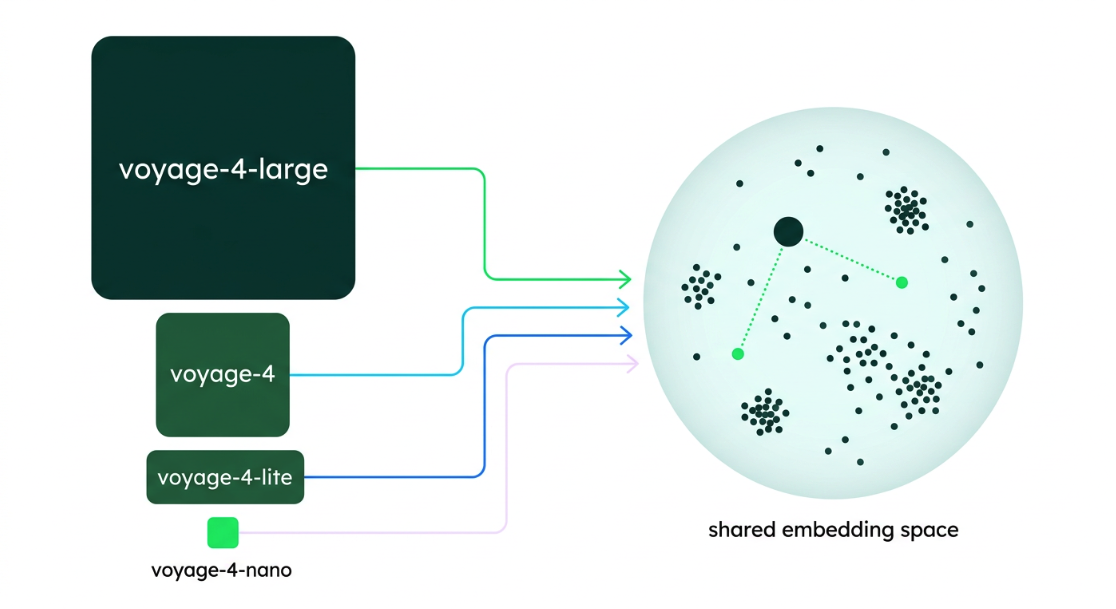
A shared embedding space forces different models - regardless of their size or architecture - to map text to the exact same coordinate system. All four models in the Voyage-4 family (large, base, lite, and nano) produce fully compatible embeddings that can be used interchangeably.
This interoperability unlocks a powerful technique called asymmetric retrieval: the practice of vectorizing queries and documents with different models to optimize for both cost and speed.
Asymmetric retrieval is most effective because of the economics behind real-world production systems. Usually, the upfront cost of vectorizing your document corpus is small relative to the cumulative cost of vectorizing millions of user queries over time. Documents are embedded once (or updated infrequently), while queries are embedded continuously at serving time.
Synthesis: The Voyage-4 model family
The Voyage-4 series represents the convergence of these two advanced techniques to solve real-world engineering constraints at scale.
1. MoE for state-of-the-art accuracy at low cost
The flagship voyage-4-large is built on an MoE architecture. By utilizing sparse experts, it outperforms dense competitors like OpenAI v3 Large by 14.05% in retrieval quality. Thanks to the MoE architecture that lowers serving costs, voyage-4-large offers 33% lower per-token costs than its predecessor, voyage-3-large. It offers the capacity to understand complex documents with the active efficiency of a smaller model.
2. Shared spaces for asymmetric efficiency
The entire family - voyage-4-large, voyage-4, voyage-4-lite, and the open-weight voyage-4-nano - operates in a single shared embedding space.
This enables a powerful, cost-saving workflow: You use voyage-4-large to create high-quality vectors for your database (a high accuracy, one-time cost). Then, you use a smaller model in the Voyage 4 series to generate the embeddings for live user queries.
The final result is a system that possesses the intelligence of the largest model but operates with the responsiveness and cost profile of the smallest.
The Voyage-4 asymmetric workflow
Ready to optimize your retrieval system? Because Voyage 4 models share an embedding space, you can tune query and document embeddings independently - use voyage-4-large to vectorize your documents once for maximum accuracy, then switch to voyage-4-lite for lightning-fast, cost-effective query processing with no re-indexing required. Here is the recommended workflow to maximize this advantage:
Optimize documents for accuracy (The heavy lift): Vectorize your massive document corpus once using the flagship voyage-4-large model. It catches every nuance and complex detail, acting as a one-time (or infrequent) cost.
Optimize queries for latency (The daily grind): Start by using a smaller model like voyage-4-lite for your live user queries. You get the ultra-fast, low-cost serving of a tiny model, but because it shares a space with the large model, it successfully retrieves the high-accuracy document representations.
Scale seamlessly: As your accuracy requirements evolve in production for different applications, you can seamlessly upgrade your query embedding model to voyage-4 or voyage-4-large without ever needing to re-vectorize your underlying corpus.
Next Steps
Learn more about Voyage AI on MongoDB through our product page.