As we've moved from simple large language model (LLM) interactions to building long-running AI agents, prompt engineering has naturally evolved into context engineering—optimizing not just system instructions but any information that lands in the LLM’s context window. This includes external knowledge, reasoning tokens, tool definitions and outcomes, short-term conversational history, long-term memory, and so on. Identifying and prioritizing the most important information at every LLM call is crucial, since all this content competes for the same limited real estate.
This is where rerankers come in. Purpose-built to optimize relevance ordering, rerankers have been used in search and retrieval systems for years. They’re now finding application in (RAG) and agentic systems, where prioritizing the right information is key to generating accurate, relevant, and coherent responses.
In this blog, you’ll learn about a relatively new class of rerankers, called instruction-following rerankers, and how to use them in your LLM applications as a context engineering tool.
What are (instruction-following) rerankers?
Rerankers are often used as a refinement step in a two-stage retrieval system. In the first stage, a retrieval algorithm (vector search, BM25, etc.) is used to produce a broad set of initial candidates. The reranker then scores each query-document pair and reorders the results by relevance, surfacing the most pertinent information at the top.
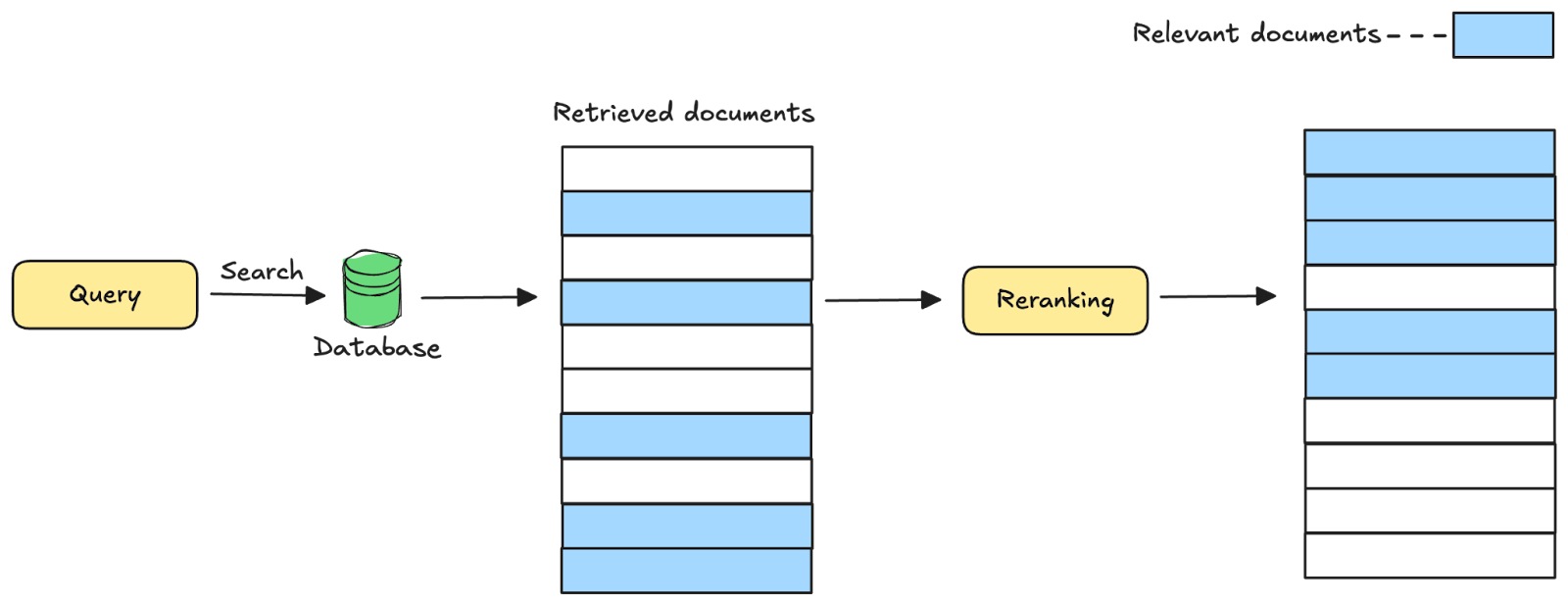
Instruction-following rerankers take this a step further by enabling users to dynamically steer the reranking process through explicit instructions alongside the query. These instructions can be used to specify the desired characteristics of the documents to be retrieved, which can vary across queries, use cases, and applications. The reranker then uses these instructions to adjust relevance scores and the document ordering accordingly.
How to use instruction-following rerankers
In the rest of this blog post, we’ll explore a few different scenarios you might come across when building AI applications and see how instruction-following reranking can improve outcomes. We’ll also show you how to implement them in your applications using Voyage AI’s rerank-2.5. The Jupyter Notebook containing all the code examples below is available on GitHub in our GenAI Showcase repository.
Scenario 1: Incorporating implicit business logic
Different domains and industries operate under implicit rules that shape what information matters most in any given context. For example, peer-reviewed clinical trials carry more weight than general medical websites in healthcare. Legal research must prioritize primary sources like statutes and case law over secondary commentary, with recency and jurisdictional relevance serving as critical signals.
These domain-specific hierarchies, quality indicators, and compliance requirements are rarely explicit in user queries. Instruction-following rerankers can incorporate these implicit operational rules and automatically surface information that aligns with professional standards and regulatory requirements, without forcing users to articulate them in their conversations.
Let’s say you’re building a RAG-based virtual assistant for a healthcare provider. You’ve created the knowledge base for this chatbot using data from several sources on the internet, including medical journals, medical websites, and online community forums. An example document from your knowledge base looks as follows, with the text field containing the content of a webpage or chunk, and the metadata object containing the name of the source and date of publication:
In a typical RAG workflow, you would extract information from the knowledge base using a technique like vector search. However, vector search treats all sources of information equally, whereas you want to prioritize certain sources over others. You can do this using an instruction-following reranker after the search step:
In the above example, the reranker is provided instructions outlining the priority order of different medical information sources. The reranker uses these to rank research-backed sources higher than less credible ones, thereby ensuring users receive evidence-based guidance, which is important in healthcare contexts.
A few things to note about the reranking step:
Instructions are prepended to the query using f"{instructions}\nQuery: {query}", similar to how you structure prompts for LLMs.
Structured data is formatted into a single string representation. Any metadata that must influence ranking should be embedded into the string.
The instruction-augmented query and formatted documents are passed to Voyage AI’s rerank method as the query and documents arguments, respectively.
The reranking results, with and without instruction-following, are as follows:
Query: How to treat migraines?
Instruction: Prioritize peer-reviewed journals, followed by advice from healthcare providers, then general websites, and finally forums.
As seen above, without instruction-following, the reranker prioritizes anecdotal experiences and general advice over clinical evidence.
Scenario 2: Handling different types of queries
Oftentimes, the AI applications you’re designing have a single overarching purpose—for example, documentation assistance, customer support, or coding assistance—but the types of queries users ask can span a broad range of topics and complexity.
Let’s say you’re building a RAG-based documentation assistant. Novice users of the chatbot might ask about basic concepts and terminology, while experienced users need code examples and advanced configuration options. Some users might also be troubleshooting specific issues and need workarounds quickly.
A simple vector search might not be sufficient to handle these different user needs. An effective approach is to categorize incoming queries (e.g., using an LLM), apply metadata filters (e.g., tags and content type) to your search based on that categorization, and then follow up with an instruction-following reranker that prioritizes different types of information based on the query type:
In the above code, note how the instructions for the reranker are set based on the query_type.
The reranking results, with and without instruction-following, are as follows:
Query: My query is not using the index I created
Instruction: Prioritize workarounds and step-by-step debugging instructions.
As seen above, rerank-2.5 is a strong reranker by default, but instructions help it align better with the user’s intent. Without instructions, the reranker retrieves a document about removing unused MongoDB indexes. With the troubleshooting instruction, it is replaced with a document about quick fixes for failing index builds, which is more directly relevant to troubleshooting why queries might not be using an existing index.
Scenario 3: Managing long-term memories and state
Long-term memory in the context of AI systems is facts, insights, and instructions learned by the system across multiple conversations. It is a critical component for AI systems to maintain consistency and coherence over time. As these systems accumulate more memories, they need a way to dynamically retrieve memories that are most relevant in the context of the current conversation.
Once again, semantic search is a common technique for memory retrieval. However, it treats all memories as equally valid and fails to account for changing preferences, recency, or the significance of memories. An instruction-following reranker on top of the semantic search enables you to prioritize memories based on factors beyond just semantic similarity.
Let’s take the example of a travel assistant agent that helps create complete travel itineraries, including making hotel bookings, restaurant reservations, etc. Let’s assume that the agent persists users’ travel, dietary, and budget preferences to a long-term memory store in MongoDB as follows:
Here’s how you can use instruction-following reranking to prioritize which memories are used by the agent to inform future itineraries:
The reranking results, with and without instruction-following, are as follows:
Query: Vacation ideas in March for my husband and me
Instruction: Prioritize recent booking patterns (last 12 months), safety concerns, and dietary restrictions.
As seen above, without instructions, the reranker does not prioritize the note about the user’s shellfish allergy, which would be key information for the agent to consider when planning future itineraries. Given the right instructions, the reranker can prioritize both recent preferences and important permanent truths about the user.
Conclusion
In this blog post, we explored how instruction-following rerankers can serve as a powerful context engineering tool in RAG and agentic applications. By enabling you to specify ranking priorities through natural language instructions, these models help ensure that your AI systems are contextually intelligent and surface the right information at the right time.
Next Steps
Register for a Voyage AI account to claim your free 200 million tokens and try out rerank-2.5. To learn more about the model, visit Voyage AI’s API documentation and follow them on X (Twitter) and LinkedIn for more updates.