We all know that document sizes play a crucial role in both the cost and performance of a MongoDB database. MongoDB stores data in a developer-friendly, document-oriented format — JSON (more precisely, BSON, which is a binary-encoded superset of JSON). This flexible structure allows developers to model data naturally, similar to how it’s represented in application objects.
However, while MongoDB offers flexible schema design, it also enforces a maximum document size of 16 MB. This limit is intentionally designed to prevent performance degradation and ensure efficient memory and network utilization. Though 16 MB may seem large, especially compared to traditional row-based databases, it’s important to understand how document size affects overall performance, scalability, and cost.
Save costs by controlling document size
After identifying the nature of your workload — whether it is write-heavy, read-heavy, or balanced — one of the most effective levers for optimization lies in controlling document size. The size of individual documents directly influences both performance efficiency and cost of ownership on MongoDB Atlas.
At scale, document size impacts everything from network throughput to storage utilization, and even instance-level compute resource consumption, all of which contribute to the per-hour billing on Atlas.
The relationship between document size and cost
MongoDB Atlas bills based on the cluster tier (CPU, RAM, IOPS capacity) and storage consumed. While you can’t directly see a “document size” metric in your bill, larger documents indirectly drive higher costs through:
- Increased storage consumption: Larger documents take up more space on disk. Even with compression, the BSON structure, indexes, and journal logs consume more bytes. Over time, this directly increases Atlas storage usage, affecting your storage cost component.
- Higher compute usage (CPU and RAM): The database engine loads entire documents into memory for reads and writes. When documents are large, more RAM and CPU cycles are needed to deserialize, process, and return data — increasing compute utilization on your cluster. This can cause auto-scaling to higher cluster tiers, which come with higher hourly costs.
- Network transfer cost: MongoDB Atlas charges for data transfer between clusters, applications, and regions. Larger documents lead to higher outbound and internal replication traffic, increasing network cost. For global deployments or analytics workloads across regions, this can add up quickly.
From theory to practice: Document size optimization in action
Environment details
I have set up an AWS machine with 4 CPU cores and 16 GB of RAM, running on AWS Linux OS. This machine is configured with the load testing tools K6 and Grafana, which are tuned to execute parallel user tests and monitor the system’s performance as needed. I have prepared two datasets: one with a small average document size of 400 bytes, and another with a large document size of approximately 1 MB, as shown in the screenshots below.
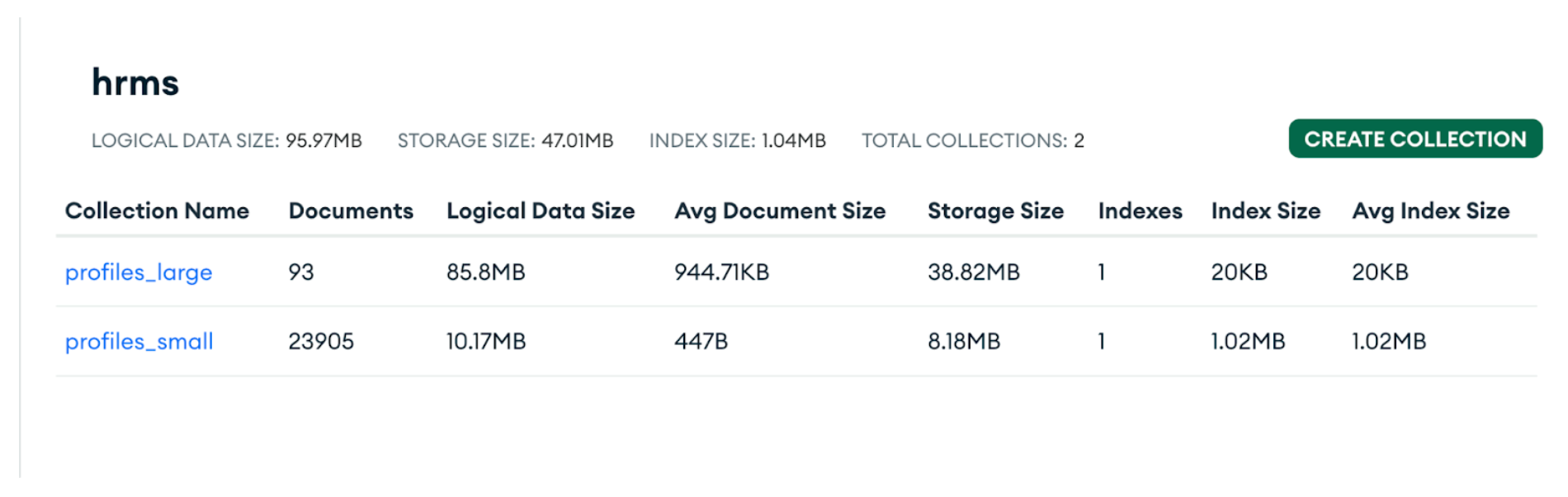
As you can observe, the average document size of profiles_large is 944.71 KB, and the average document size for profiles_small is 447B
MongoDB Atlas environment details
The tests will be run on an M30 cluster, which is a moderately sized MongoDB Atlas instance suitable for development, testing, and moderate production workloads. An M30 cluster typically includes 8 GB of RAM, 2 vCPUs, and 80 GB of storage (configurable). It provides a good balance between memory, CPU, and I/O throughput to handle concurrent operations efficiently.
For the load test, the cluster will handle 1,000 concurrent users for 1 minute, allowing us to evaluate performance metrics such as CPU usage, memory consumption, and operation latency to determine which workload consumes more resources under the same conditions.
Test results with 1 MB document size vs 400 B
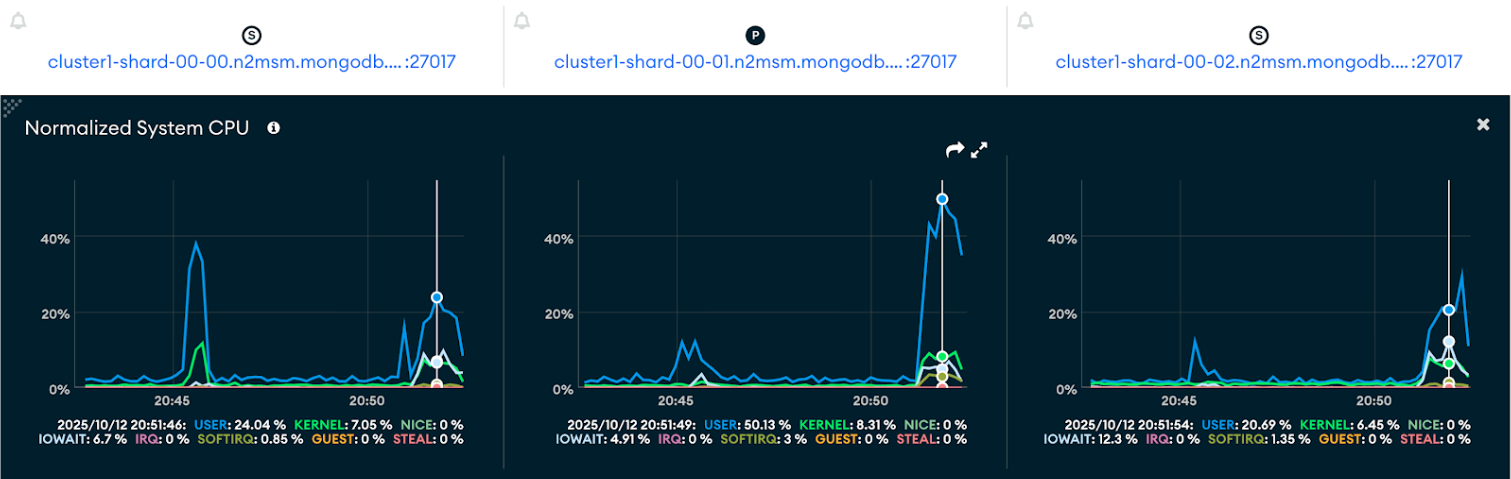
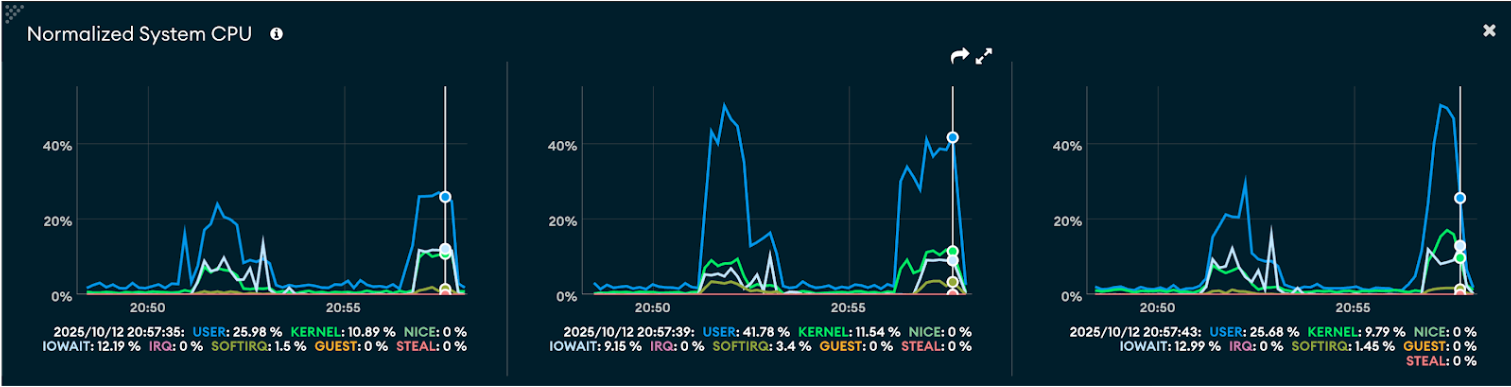
CPU utilization
- Large documents (~1 MB): CPU usage shows sharp spikes during peak ingestion, reaching over 50% utilization, reflecting the heavier load of processing larger payloads.
- Small documents (~400 MB): CPU utilization remains more balanced but frequent, indicating consistent processing overhead from handling a higher number of smaller requests.
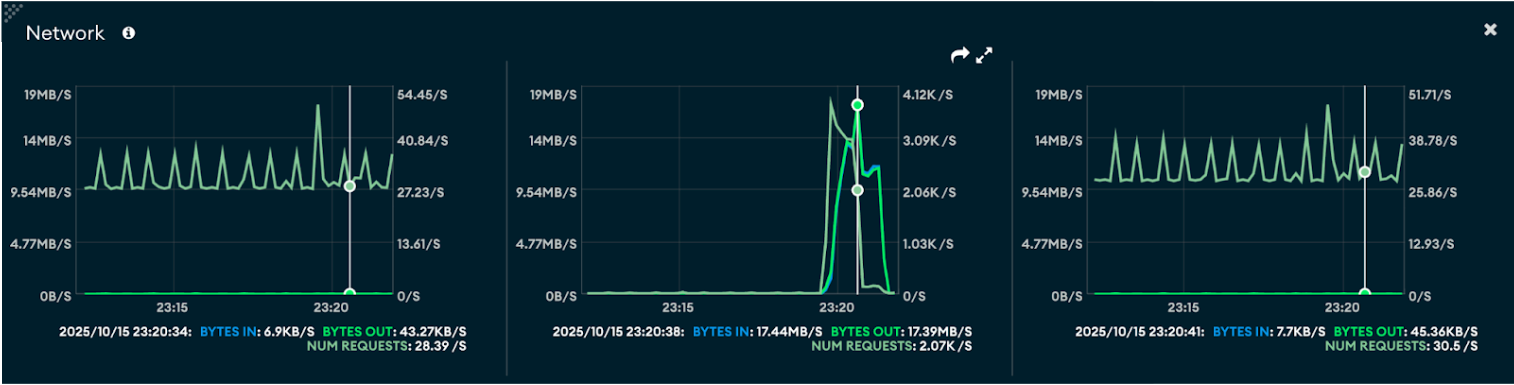
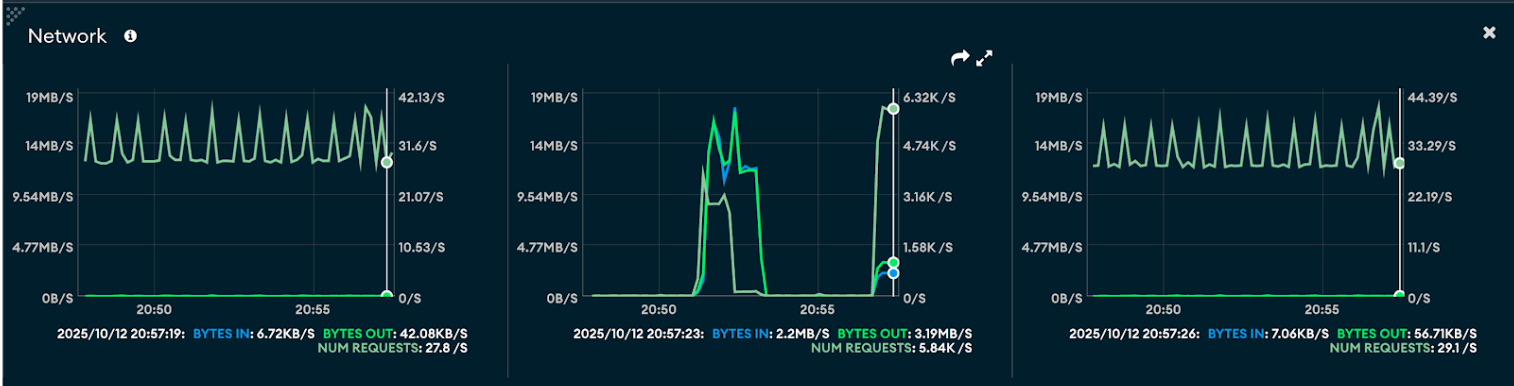
Network
- Large document size network: When processing documents of around 1 MB, the network shows noticeably higher bytes in/out per second and peak throughput. This indicates that larger document transfers consume more bandwidth and cause sharper traffic spikes, though the number of requests per second remains lower due to the larger payload size.
- Small document size network: With smaller documents (~400 bytes), the network utilization is comparatively stable and consistent, showing lower bytes in/out but a higher number of requests per second. This reflects a more request-intensive workload, generating smaller but more frequent operations.
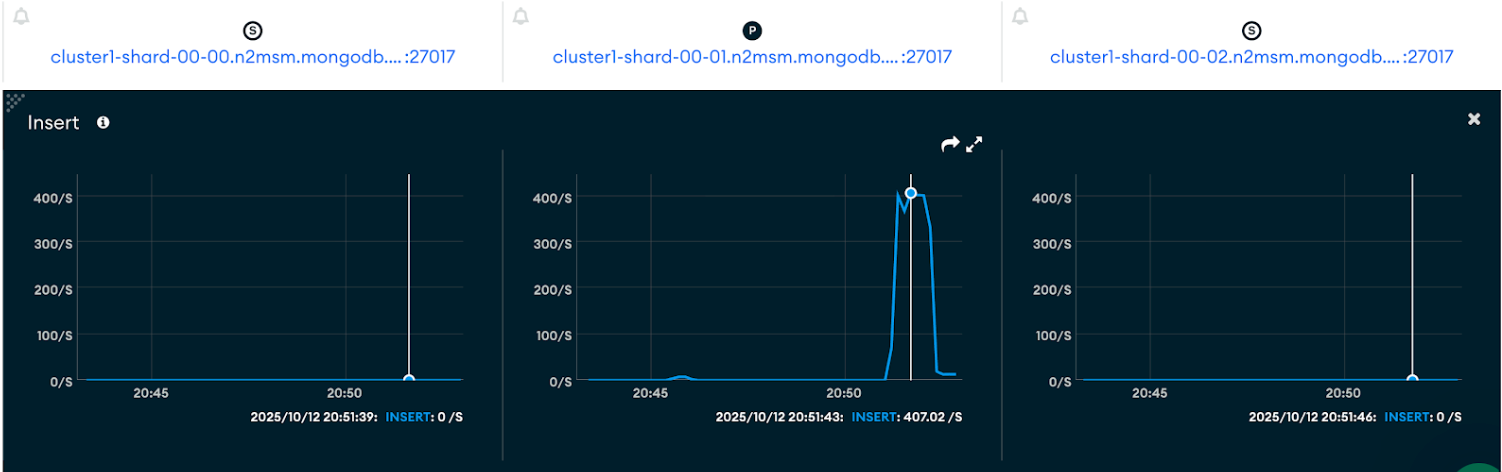
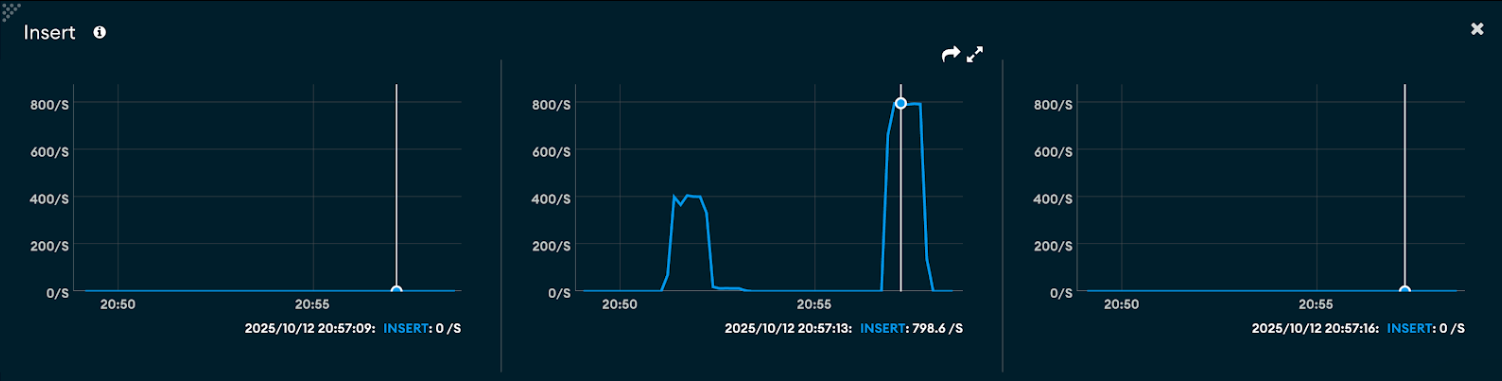
Insert throughput
- Large documents (~1 MB): Achieved around 400 inserts/sec, showing fewer but heavier write operations due to larger payloads.
- Small documents (~400 B): Nearly 800 inserts/sec, doubling throughput as smaller payloads allow faster write cycles.
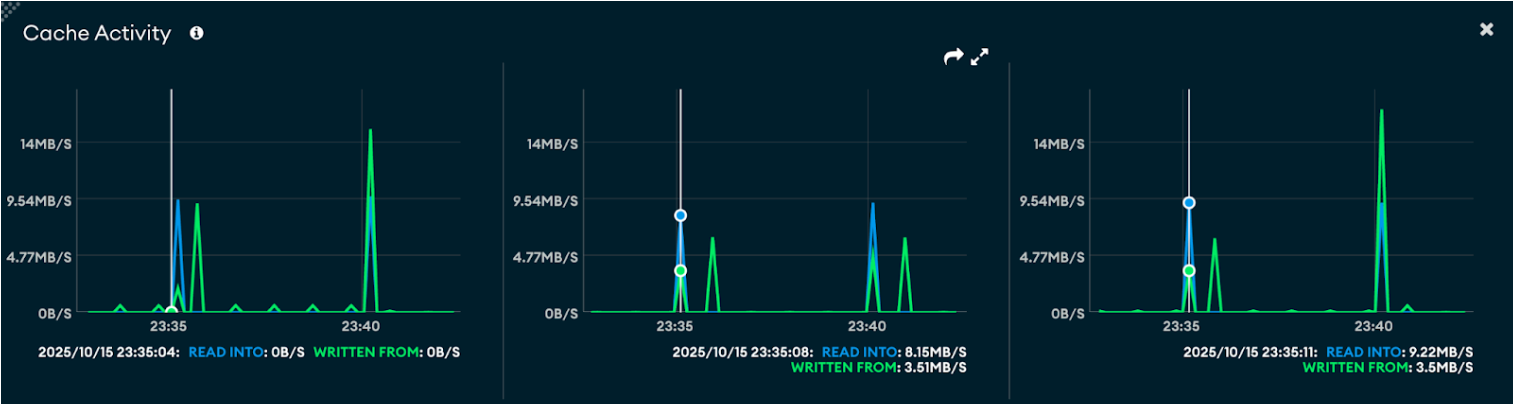
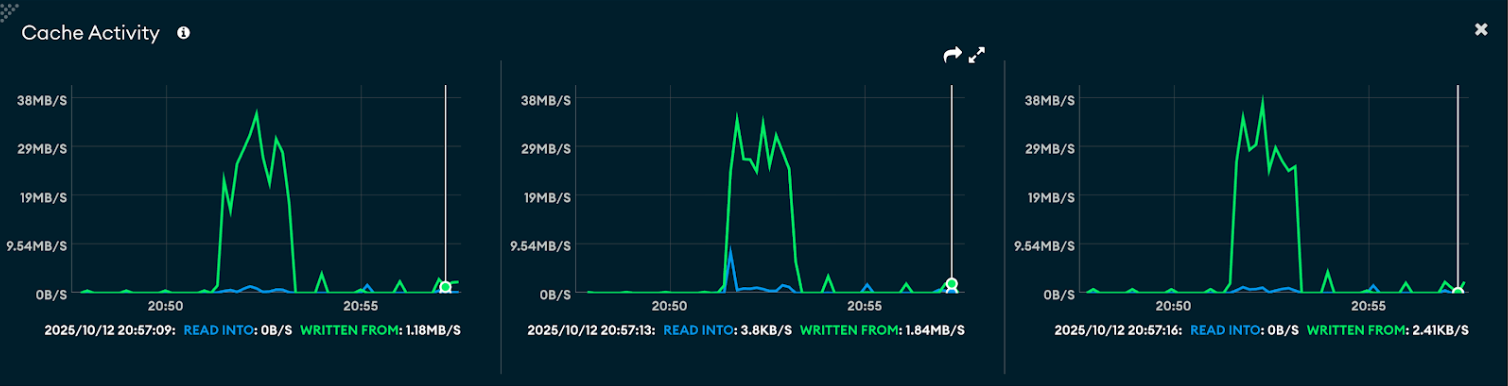
Cache/RAM usage
- Large documents (~1 MB): Cache shows higher spikes — read into ~9 MB/s and written from ~3.5 MB/s, indicating heavier use of cache during bulk writes.
- Small documents (~400 B): Cache activity remains low — read into ~0 B/s and written from ~2.4 KB/s, showing minimal caching due to smaller payloads and faster direct writes.
How to keep document size in control
We all know that the maximum BSON document size in MongoDB is 16 MB. However, it’s equally important to consider that these documents are often processed for a large number of users. Therefore, we need to be mindful of document size when designing and executing the application to ensure optimal performance and scalability. We need to follow some principles to keep the size of the document optimal, which depends on the kind of application and workload we are running.
1 - Keep bounded arrays as embeddings
In MongoDB schema design, a bounded array refers to an array that has a known and limited maximum size one that won’t grow indefinitely over time. When you know the number of items in an array will remain small and predictable, embedding that array within the parent document is both efficient and recommended.
Embedding works well for bounded arrays because it allows all related information to be stored together within a single document, enabling faster and more efficient data retrieval. Since everything is contained in one place, MongoDB can fetch all relevant data in a single query without requiring joins or $lookup operations. For example, if a user has a limited number of addresses or a few recent orders, embedding them directly in the user document provides better read performance. Additionally, MongoDB’s atomic operations at the document level ensure that updates to both the parent and embedded fields occur atomically. This approach also simplifies schema design and application logic, as small, tightly coupled relationships can be represented naturally without managing external references or performing multiple queries. By keeping related data self-contained, embedding reduces query latency and complexity, making it an ideal strategy for scenarios where the array size is known and remains within reasonable bounds.
2 - Keep larger strings like log traces in object storage
When dealing with large strings such as log traces, error dumps, or detailed diagnostic messages, it’s best to store them in object storage (like AWS S3, Azure Blob Storage, or Google Cloud Storage) rather than directly inside MongoDB documents. These types of data can be very large and unbounded, often growing over time or varying significantly in size. Storing them in MongoDB can quickly bloat your documents, increase memory usage, and degrade query performance.
Instead, you can store only the metadata and a reference (URL or object key) in MongoDB. This allows your application to efficiently query, filter, and manage logs without handling large string payloads during normal database operations. Object storage is also optimized for handling large, immutable objects and offers cost-effective scalability for this use case.
By offloading large text content to object storage and keeping only pointers in MongoDB, you maintain the performance and responsiveness of your database while still ensuring that detailed data remains easily retrievable when needed.
3 - Use references for unbounded arrays
When dealing with unbounded arrays — that is, arrays whose size can grow indefinitely or unpredictably over time — it’s best to use references instead of embedding them directly within a MongoDB document. Examples of such data include user messages, activity logs, transactions, or sensor readings. These arrays can grow continuously, and embedding them would cause the parent document to expand significantly, eventually approaching MongoDB’s 16 MB document size limit.
Using references means storing the related items (like messages or logs) in a separate collection, and linking them to the parent document using an identifier (e.g., user_id or parent_id). This approach keeps the parent document small and lightweight, ensuring that read and write operations remain efficient even as the dataset grows.
References are also more scalable because they allow you to handle large datasets with fine-grained control. You can paginate results, archive old records, or apply different indexing strategies on the referenced collection without affecting the core parent document.
In short, referencing is ideal for unbounded arrays because it prevents document bloat, improves scalability, and keeps your data model maintainable and performant as the volume of related data continues to grow.
4 - Do not store blobs directly in documents
Avoid storing binary large objects (BLOBs) such as images, videos, audio files, or other large media directly inside MongoDB documents. These files can be very large and cause documents to grow rapidly in size, negatively impacting performance, memory usage, and storage efficiency. Since MongoDB has a 16 MB document size limit, embedding large binary data can also lead to document fragmentation and slow retrieval times.
Instead, it’s recommended to store such large files in object storage (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) or use MongoDB’s GridFS if you want to keep everything within MongoDB. In these approaches, you store only the metadata and a reference (URL or ObjectId) in the document. This keeps your collections lightweight and query performance fast while still allowing easy access to the actual file when needed.
In summary, don’t store blobs directly in MongoDB documents — store them externally and reference them. This design ensures scalability, better resource utilization, and more efficient data management.
5 - Avoid null fields as part of the document
It’s a good practice to avoid including fields with null values in MongoDB documents unless they serve a specific purpose. Storing unnecessary null fields increases document size without adding any real value, leading to wasted storage space and less efficient indexing and querying. Over time, this can affect both performance and storage costs, especially in collections with millions of documents.
From a schema design perspective, null fields can also introduce inconsistencies in your data model. For example, having optional fields set to null instead of being omitted altogether can make queries and updates more complex — you’ll need to account for both missing and null cases in your logic (e.g., { field: null } vs { field: { $exists: false } }).
Instead of setting a field to null, it’s often better to omit the field entirely when it doesn’t have a value. This approach keeps documents compact and your schema flexible, allowing MongoDB to store and process data more efficiently. If you need to represent an explicit "no value" state for business logic, use nulls sparingly and only when they carry semantic meaning.
Conclusion
The analysis clearly highlights that document size and schema design choices have a direct impact on both performance and cost efficiency in MongoDB workloads. Large documents (around 1 MB) tend to create higher system strain — driving up CPU utilization, network bandwidth consumption, and cache pressure. These workloads often show short but sharp CPU spikes exceeding 50%, along with heavier network usage due to large payload transfers. As a result, they incur higher operational costs and require more compute and I/O capacity to maintain throughput.
In contrast, workloads built around smaller, well-structured documents (~400 bytes) demonstrate a more stable and efficient performance profile. With reduced processing overhead per operation, CPU utilization remains moderate and network activity lighter — with cache writes around 2.4 KB/s compared to multi-megabyte spikes for larger payloads. Despite higher operation volumes (~800 inserts/sec), these smaller documents deliver superior throughput and responsiveness at a lower cost.
However, document size is only part of the story. Effective schema design — such as embedding bounded arrays, using references for unbounded relationships, keeping large strings and BLOBs in object storage, and avoiding null fields — plays a crucial role in optimizing performance and scalability. These design principles not only improve efficiency but also ensure long-term maintainability as the dataset and user base grow.
Ultimately, the ideal schema balances storage efficiency, query performance, and operational cost. By following these best practices, teams can design data models that maximize MongoDB’s performance capabilities while keeping infrastructure costs under control.
Next Steps
Ready to optimize your MongoDB database? Dive deeper into MongoDB's Data Modeling documentation to master schema design, embedding, and referencing for peak performance and cost efficiency.
Discover more performance best practices, including indexing, query patterns, and hardware considerations.