Large documents present a fundamental challenge in LLM applications—even with today's extended context windows, including entire documents is inefficient and drowns the signal in irrelevant information. Chunking solves this by breaking documents into smaller segments, allowing retrieval systems to surgically extract only the most relevant chunks into the LLM's context window. However, this precision comes at a cost—context loss.
When you isolate a chunk from its surrounding document, you strip away broader information essential for accurate responses. For example, a chunk stating “Either party may terminate this agreement with 90 days written notice” might match a termination query perfectly, but without knowing which contract or parties are involved, it cannot answer specific questions like “Can we terminate our agreement with Vendor Y immediately for security breaches?”
In this blog post, you will learn about Voyage AI’s voyage-context-3, a contextualized chunk embedding model that produces vectors encoding both chunk content and global document-level context, without any manual data augmentation. Specifically, we’ll cover the following:
What are contextualized chunk embeddings, and when to use them
How to generate contextualized chunk embeddings with Voyage AI
Evaluating retrieval quality: contextualized vs. standard embeddings on legal contracts
What are contextualized chunk embeddings?
Unlike traditional embeddings, which encode chunks in isolation, contextualized chunk embeddings encode both the chunk's content and relevant context from the source document within a single vector. The embedding model sees all of the chunks at once and can intelligently decide which global information from other chunks to inject into the individual chunk embeddings.
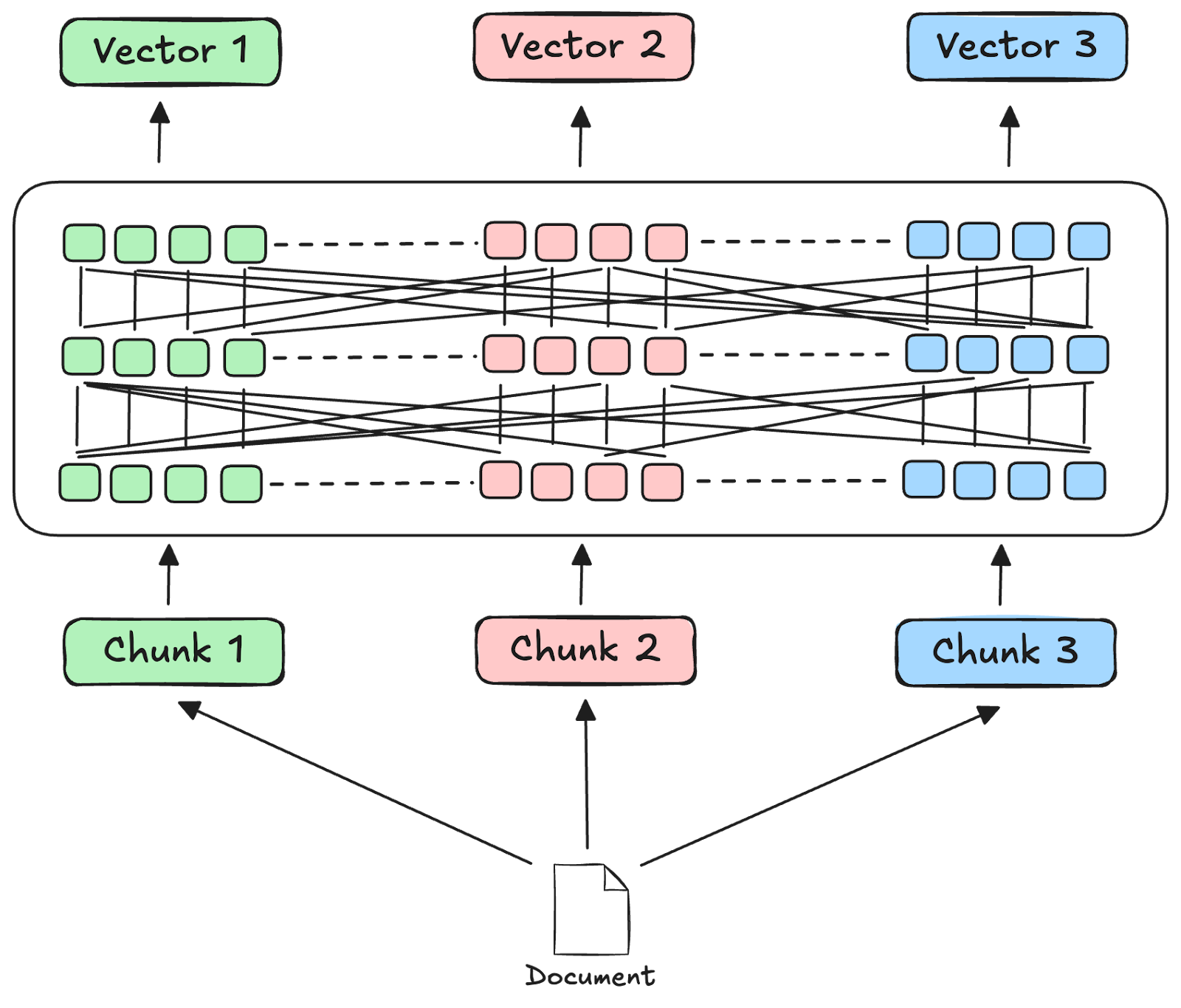
NOTE: The chunk content remains unchanged. Global information is only injected into the chunk embeddings.
When to use contextualized chunk embeddings?
Contextualized chunk embeddings offer the strongest tradeoff between retrieval accuracy and operational simplicity compared to other context augmentation methods, such as late chunking [1], contextual retrieval [2], and late interaction [3], which require manual post-processing, LLM calls for every chunk, or significantly more storage, respectively.
voyage-context-3 is a seamless drop-in replacement for standard, context-agnostic embedding models used in existing systems, requiring no downstream workflow changes while delivering superior retrieval performance.
Contextualized chunk embeddings are particularly valuable for long, unstructured documents—such as legal contracts, financial documents, research papers, and technical documentation—in which queries often require information that spans multiple sections or depend on document-level context, such as dates, company names, and product versions that may appear sparsely in the document.
For more details, including extensive evaluations on domain-specific and real-world datasets, see the voyage-context-3 release blog [4].
Using contextualized chunk embeddings in your application
In this tutorial, you will learn how to use contextualized chunk embeddings in your LLM applications. We will also evaluate the retrieval quality of contextualized versus standard embeddings on a dataset of legal contracts, where inaccuracies can have serious consequences.
Before we begin
About the data
We will use a small set of actual legal contracts from the CUAD dataset. Legal contracts typically start with a preamble identifying the parties involved:
This INTELLECTUAL PROPERTY AGREEMENT (this “Agreement”), dated as of December 31, 2018 (the “Effective Date”) is entered into by and between Armstrong Flooring, Inc., a Delaware corporation (“Seller”) and AFI Licensing LLC, a Delaware limited liability company (“Licensing” and together with Seller, “Arizona”) and AHF Holding, Inc. (formerly known as Tarzan HoldCo, Inc.), a Delaware corporation (“Buyer”) and Armstrong Hardwood Flooring Company, a Tennessee corporation (the “Company” and together with Buyer the “Buyer Entities”) (each of Arizona on the one hand and the Buyer Entities on the other hand, a “Party” and collectively, the “Parties”).
”However, throughout the rest of the document, parties are referenced only by role—"Buyer," "Seller," "Party," etc. So when you chunk the contract into smaller segments, later chunks lose critical context about the parties, potentially making them a good candidate for contextualized chunk embeddings. Let’s find out!
Where’s the code
The Jupyter Notebook for this tutorial is available on GitHub in our GenAI Showcase repository. To follow along, run the notebook in Google Colab (or similar), and refer to this tutorial for explanations of key code blocks.
Step 1: Install required libraries
Begin by installing the following libraries:
datasets: Python library to get access to datasets available on Hugging Face Hub
pdfplumber: Python library to parse and analyze PDFs
langchain-text-splitters: Text chunking utilities in LangChain
tiktoken: Token counting and encoding library
voyageai: Python library to interact with Voyage AI's APIs
Step 2: Setup prerequisites
In this tutorial, we will use Voyage AI’s voyage-context-3 to generate contextualized chunk embeddings. But first, you will need to obtain an API key and set it as an environment variable as follows:
Step 3: Download the dataset
Next, let’s download the dataset from Hugging Face.
The above code downloads the dataset using the load_dataset method of the datasets library. Hugging Face uses pdfplumber under the hood to load PDF datasets. This way, you can use utilities from the library to parse and analyze PDFs. We use the .pages attribute to access the pages of the PDF, and the extract_text method to extract the text from the PDF pages.
Step 4: Chunk the PDF content
Next, let’s chunk the PDFs in our dataset.
In the code above, we use the from_tiktoken_encoder method of the RecursiveCharacterTextSplitter class in LangChain to chunk the PDF content. This text splitter first splits text on a list of characters (separators) and recursively merges them until the specified chunk size (chunk_size) is reached. While a 15-20% chunk overlap is typically recommended to prevent context loss across chunks, we use no overlap here, allowing voyage-context-3 to automatically determine the optimal global context to inject into each chunk at embedding time.
For each page in every document, we split the text into chunks and store them along with a parent document ID (doc_id) and a unique chunk ID (chunk_id). We will need these IDs to evaluate retrieval quality later. A sample document is as follows:
Step 5: Embed the chunks
In this step, let’s define two helper functions, one to generate standard embeddings using voyage-3-large, a context-agnostic embedding model from Voyage AI, and another to generate contextualized chunk embeddings using voyage-context-3.
The above function uses the embed method of the Voyage AI API to generate embeddings using the voyage-3-large model. The embed method takes the following arguments:
input: The list of texts to embed
model: Embedding model to use
input_type: Can be set to either query or document. This is especially important for search/retrieval since this parameter is used to automatically prepend the inputs with an appropriate prompt to create vectors that are better tailored to the task.
Now let’s create the helper function to generate contextualized embeddings:
The above function is similar to the get_std_embeddings helper function with a few key differences:
Uses the contextualized_embed method of the Voyage AI API instead of the embed method.
The input parameter is a list of lists where each inner list can contain a query, document, or document chunks to be vectorized, and represents a set of texts that will be embedded together. For example, when embedding document chunks, each inner list contains chunks from a single document, ordered by their position in the document.
The output of the contextualized_embed method is a list of ContextualizedEmbeddingsResult objects, each representing the result for a query, document, or a set of document chunks. We parse this list of embedding objects to create a flattened list of embedding vectors.
Step 6: Evaluation
We now have everything we need to evaluate the retrieval quality from using contextualized versus standard embeddings on our legal dataset.
To do this, we’ve curated a set of questions that require global document-level knowledge, even if the actual answer is contained in a single chunk. Each entry in the evaluation dataset also includes the document ID and chunk ID of the "golden chunk,” i.e., the chunk containing the correct answer. This approach of evaluating retrieval quality by measuring whether the system surfaces known relevant items (in this case, the golden chunk) is standard practice across information retrieval, recommendation systems, and RAG applications.
A sample entry from our evaluation dataset is as follows:
We'll measure retrieval quality using two metrics:
Mean recall: The percentage of queries where the golden chunk appears in the top-k retrieved results.
Mean reciprocal rank (MRR): The average of 1/rank across all queries, where rank is the position of the golden chunk in the top-k results. This is an important metric, as presenting the most relevant information at the top is critical when working with LLMs.
Let’s define a helper function to calculate the metrics:
Given an entry from the evaluation dataset, the above code does the following:
Generates the query embedding using the helper functions from Step 5.
Calculates the pairwise dot product similarity between the query and chunk embeddings, essentially performing vector search on the chunks.
Identifies the top k chunks with the highest similarity scores.
Checks if the golden chunk appears in the top k results.
If the golden chunk is found in the top k list, sets the recall to 1 and the rank to the position of the golden chunk in the top k list. Otherwise, the recall is set to 0 and the rank to None.
Next, let’s use the above function to evaluate voyage-context-3:
The above code:
Converts chunked_docs created in Step 4 to a list of lists of document chunks as expected by the contextualized_embed method.
Generates chunk embeddings using the get_contextualized_embeddings helper function.
For each entry in the evaluation dataset, uses the calculate_metrics function to get the recall and rank of the golden chunk.
Calculates mean recall and reciprocal rank across the entire evaluation dataset.
Similarly, we evaluate the standard embedding model, voyage-3-large (see Step 6 in the notebook), and the results are as follows:
As seen above, voyage-context-3 significantly outperforms its context-agnostic counterpart, achieving 16.67% higher recall and 37.34% higher MRR on our evaluation dataset. This demonstrates that contextualized embeddings substantially mitigate the context loss problem inherent in traditional chunking.
Conclusion
In this tutorial, we learned about contextualized chunk embeddings and how to use them in LLM applications. Contextualized chunk embeddings are particularly valuable when working with long, unstructured documents, where queries often depend on broader document-level context that is typically lost during chunking. We demonstrated this by evaluating Voyage AI’s voyage-context-3 against voyage-3-large, their standard embedding model.
Register for a Voyage AI account to claim your free 200 million tokens and to try out voyage-context-3. To learn more about the model, visit our API documentation and follow us on X (Twitter) and LinkedIn for more updates.
References
[1] Late chunking
[3] Late interaction