Realizing that I’ve been building storage engines for nearly two decades has led me to reflect on what’s changed. During that time, I’ve learned what it takes to build trust in my products. Happily, it’s a mutually beneficial equation: the safer I keep users' information, the less likely an emergency is to occur—and the more likely they are to trust and use my work.
The storage engine is responsible for all documents on each node in a replica set. The storage engine provides durability (once a document is inserted, it remains available until it is removed by the user) and facilitates concurrent reads and writes. The default storage engine for MongoDB is called WiredTiger, and the primary data structure used by WiredTiger to store users' information is a B+tree. A B+tree is similar to a B-tree, with the additional characteristic that internal nodes only store keys—not values. A B+tree data structure is an excellent choice for MongoDB due to its balanced performance across various data access patterns.
The more efficient WiredTiger is, the greater the value our customers derive from the hardware. A key tool for attaining that efficiency is in allowing multiple operations to happen at the same time. The more concurrency WiredTiger supports, the greater the value users derive from adding more CPUs and I/O bandwidth. Many approaches to maximizing concurrency involve reducing how long an operation holds an exclusive lock. A more extreme solution is to design algorithms that don’t require locks at all to coordinate concurrent access. WiredTiger utilizes such lock-free algorithms in key parts of our B+tree implementation to help optimize value for our customers. There are two sides to data access: reads and writes. This blog post describes how read operations use hazard pointers and write operations use lock-free skip lists to maximize the value our customers get from their hardware.
Our work shows that lock-free algorithms achieve a 50% improvement in throughput for read workloads, and up to four times greater throughput for update workloads.
History
The history of concurrency and performance in MongoDB is the story of two products: WiredTiger and MongoDB.
WiredTiger
WiredTiger's founders had previously developed BerkeleyDB, a storage engine that struggled with performance on the multi-core and multi-CPU machines that became prevalent after BerkeleyDB was originally implemented. As more threads accessed or modified the database, operations would wait for each other, preventing applications from fully utilizing CPU and I/O resources. BerkeleyDB attempted to address this by progressively reducing locking granularity, which increased the number of locks and made lock management a bottleneck. The following diagram shows lock granularity benefits and trade-offs.

The founders of WiredTiger reached for academic research into lock-free algorithms to find techniques that could be used to achieve this idealized model. The two algorithms explored in this blog are hazard pointers and lock-free skip list implementation.
MongoDB
Early releases of MongoDB used simple mechanisms to coordinate changes from multiple users that severely restricted concurrency. Concurrency matters to users because it directly impacts the performance and responsiveness of applications, especially in modern systems where many users or processes access and modify data simultaneously. As MongoDB acquired more demanding customers, we needed to support higher throughput; we achieved this by reducing the granularity of locking.

The 3.2 release of MongoDB corresponds to when WiredTiger was integrated as the default storage engine. Users started getting the benefit of minimal coordination between operations and much better utilization of their hardware.
B+trees
A B+tree is the data structure used by WiredTiger to store data in a format that can be efficiently stored and retrieved. A B+tree takes user-provided key/value pairs (record ID and document) and stores them in sorted order. It groups adjacent data together into small sets; such a set is called a page. A hierarchical index structure is maintained, which is used to efficiently find the page that contains a particular key/value pair. A simple B+tree has a structure like the following:
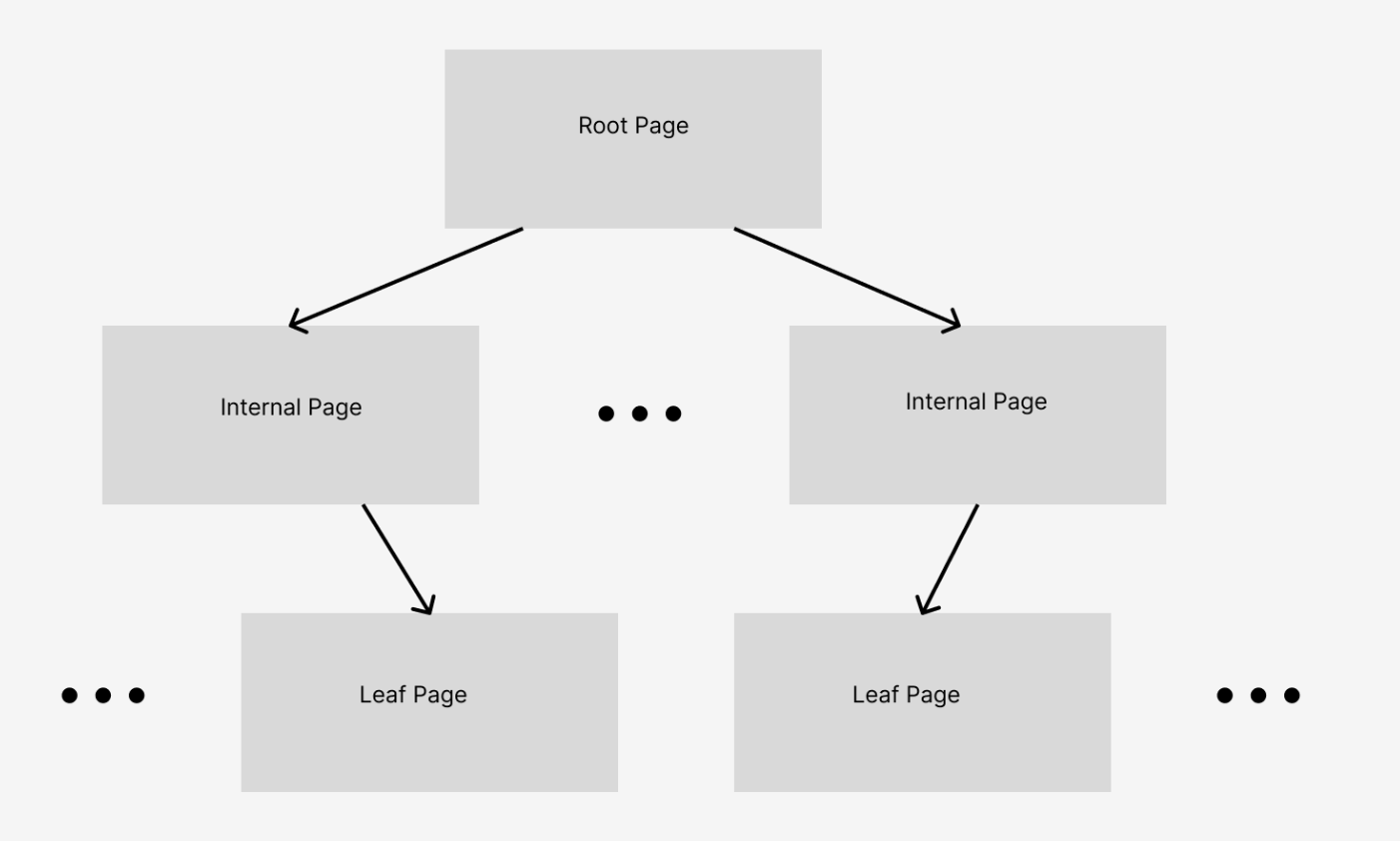
WiredTiger is a B+tree, which means that the root and internal pages only contain keys, and only leaf pages contain values. An interesting characteristic of the WiredTiger B+tree, which is relevant to our ability to implement lock-free algorithms, is that the on-disk and in-memory representations of the tree are different. Maintaining a different representation in memory is necessary for us to use data structures that are compatible with lock-free algorithms.
Lock-free read operations
Storage engines generally keep data in two places: the full set of key/value pairs resides on stable storage (think an SSD drive), and a subset of data (i.e., a working set) is held in memory. For applications with data sets larger than memory, it’s necessary to swap in-memory content for on-disk content. The necessity to swap content in the cache means that read operations must coordinate with cache management. Without coordination, you risk dangling pointers for cached data and crashes.
Consider an example search operation used for describing how a lock-based mechanism can ensure an actively used page is never removed by the cache manager. The search operation traverses through the root page, an internal page, and a leaf page to find the key/value pair it wants. A locking solution for that would have that search operation acquire a lock on the root page, search within the root page for the right internal page, acquire a lock on that internal page, search within that page for the leaf page it needs, acquire a lock on the leaf page, find the requested key/value pair and return it to the user. Once the user is finished with that key/value pair, the operation can release the locks on the pages it has acquired.
Finding that single value required acquiring and releasing three locks. Each lock is a shared resource—requiring coordinated access across threads. That doesn’t sound like much, until you multiply it by millions of lookups per second across dozens of threads. Such coordination points are expensive in modern CPU architectures.
Hazard pointers
WiredTiger uses a hazard pointer mechanism to coordinate between user operations accessing content in the cache and the cache manager reclaiming space. Hazard pointers coordinate access to a shared resource (in this case, a page in the cache) in a different way than locks. The goal of a hazard pointer is for it to be as cheap as possible for shared access, with the trade-off that it can be more expensive to acquire exclusive access. That is an appealing trade-off for cache management; the cache manager is out of the user call path, so additional overhead there doesn’t harm user performance.
I’ll explain the hazard pointer mechanism using the same search example as above. The search needs to traverse the same set of pages as per the locking example. Instead of acquiring a lock, the reader publishes the hazard pointer for a page as it traverses it. This publish operation is equivalent to assigning a variable that is only ever changed by this thread. Once the assignment is complete, the thread needs to ensure that other threads see the results of the assignment before proceeding. That step is called publishing—as in, the results of the assignment are published for other threads to observe.
When the search is finished, it needs to clear the hazard pointers. It is not necessary to publish this clear operation, since there is no requirement about when other threads observe the cleared hazard pointer.
If the cache manager wants to reclaim a page during cache eviction, it must review the hazard pointers published by each thread. If any thread is accessing the page, the manager can’t have exclusive access. If no thread is accessing the page, it can be removed. The removal is non-trivial. It’s necessary to ensure no thread starts using the page while it is being removed—that is handled via a related but separate mechanism with a protocol about sharing the state of a page.
When comparing locking versus hazard pointer implementations for a simple query, the locking method involves acquiring and releasing three locks (one for each of root, internal, and leaf pages). In contrast, the hazard pointer approach necessitates publishing changes to three memory locations. While this may seem minor in the context of database queries, experimental results demonstrate its significance within WiredTiger's already efficient operations. In a high-concurrency workload, those three lock acquisitions account for a third of the overall performance.
See how lock-free reads boost performance
This analysis compares the performance of MongoDB’s lock-free B+tree implementation with a version that includes locking.
Benchmarking note: All benchmarks were run on an AWS m7g.4xlarge. Results were reproducible with an error tolerance of less than 3% run-to-run. Numbers here are averages over five runs. A gist with additional context about the tests is here.
Read workloads:
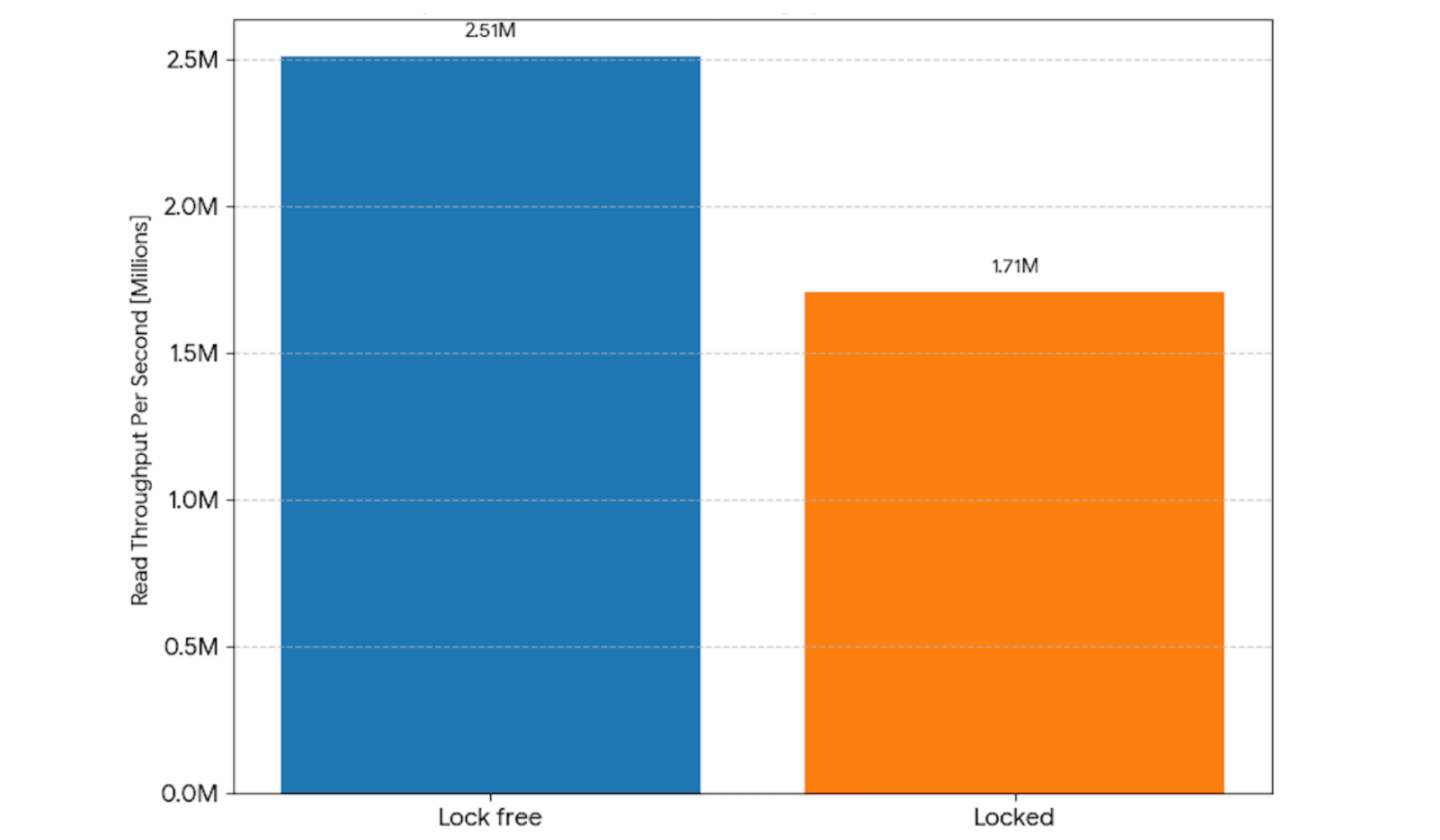
A benchmark involving five million records (5.8GB table, 10GB cache) and a 64-thread point-read workload demonstrated significant throughput gains without lock acquisition.
- With read locks: 1,707,232 operations per second.
- Without read locks: 2,507,566 operations per second.
- Performance Improvement: 47% increase in throughput.
Lock-free update operations
The other operation that requires coordination in a B+tree is when multiple operations are changing the data at the same time. In the following description, any data change (insert, modification, removal) is referred to as an update. One of the key jobs of a storage engine is to predictably allow sets of changes to a database to happen atomically (i.e., all or nothing). This is managed via transactions that allow users to group a set of changes together. There are cases where a user changes (or attempts to change) the same record (document, value) in a database at the same time. It is necessary for those changes to be coordinated. Coarse-grained locking might only allow a single change to the entire database at a time, or a single change to a table at a time. Finer-grained mechanisms might allow for multiple operations to coordinate at the page level or the record level.
For many lock-based storage engines, the page level is a good granularity choice. The finer the granularity of coordination, the more locks are required to manage the coordination. It is common for users to have millions of pages in cache and hundreds of millions of records. It is not practical to create and manage a lock for every record.
An update operation will search the tree to find the leaf page where its update belongs. In a storage engine with a lock based approach, the operation would acquire an exclusive lock on the page, and be free to add its change to the data structures while it held the lock. The write operation needs to wait for readers to finish before it can acquire exclusive access, and only a single write can proceed at a time.
Instead of this scheme, WiredTiger has implemented a data structure for in-memory pages that allows for lock-free changes to the content of the page.
Lock-free skip list
The data structure chosen by WiredTiger is a skip list, which can be thought of as a search-optimized singly linked list. A linked list can be represented as:
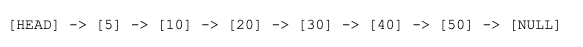
A skip list has “express lanes” that are sparsely populated linked lists that provide a mechanism for quickly traversing to the desired record. Consider the diagram below, where Level 2 and Level 3 are express lanes - the higher the number, the more express the lane.
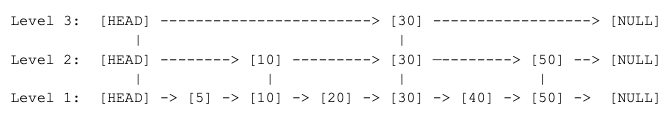
Simulating a search looking for record [40], it would start by looking at the Level 3 linked list. This example has record [30] there, which is less than [40], it would step down to Level 2, look at record [50], which is more than [40], so it would step down again to Level 1, where it would look at the next record and find [40] it is looking for.
Finding [40] here required three comparisons ([30], [50], [40]). Finding the record without the express lanes would have required five comparisons. The benefit of skip lists becomes much greater as the list becomes bigger. In WiredTiger, each level is approximately one quarter the size of the level below.
The key to implementing a lock-free skip list is for any operation wanting to change the content on the page to construct the change to the data structure, and then atomic-compare-and-swap (CAS) the change in place. If the atomic CAS operation fails, discard the changes and try again. If it has succeeded, then the change has been made and is visible to other operations. For the skip list, the CAS needs to succeed on the Level 1 list, but a best effort is made with changes to other levels—it is not necessary to populate the upper level lists, as they are supposed to be sparse. The reason lock-free algorithms are hard is that it is only possible to coordinate via a single change. It isn’t possible (practical? Most things are possible) to implement a lock-free doubly linked list, since both the forward and reverse pointers need to be changed, and that pair of changes can’t be made using a single CAS operation.
This lock-free approach to making an update to the database allows WiredTiger to avoid acquiring an exclusive lock on the page, at the expense of complexity in each thread retrying its change if another thread won the race to make a change. The visual representation of the skip list above makes it appear wasteful of memory—it is worth noting that only one copy of the data is present and shared by each level of the skip list—there is minimal memory overhead in the skip list implementation.
Requiring exclusive access can become arbitrarily expensive, since it forces every change to a page to serialize, i.e, take a slot in a queue waiting for its turn to make a change. Below are two example workloads that represent different database workloads.
Mixed read/write workloads:
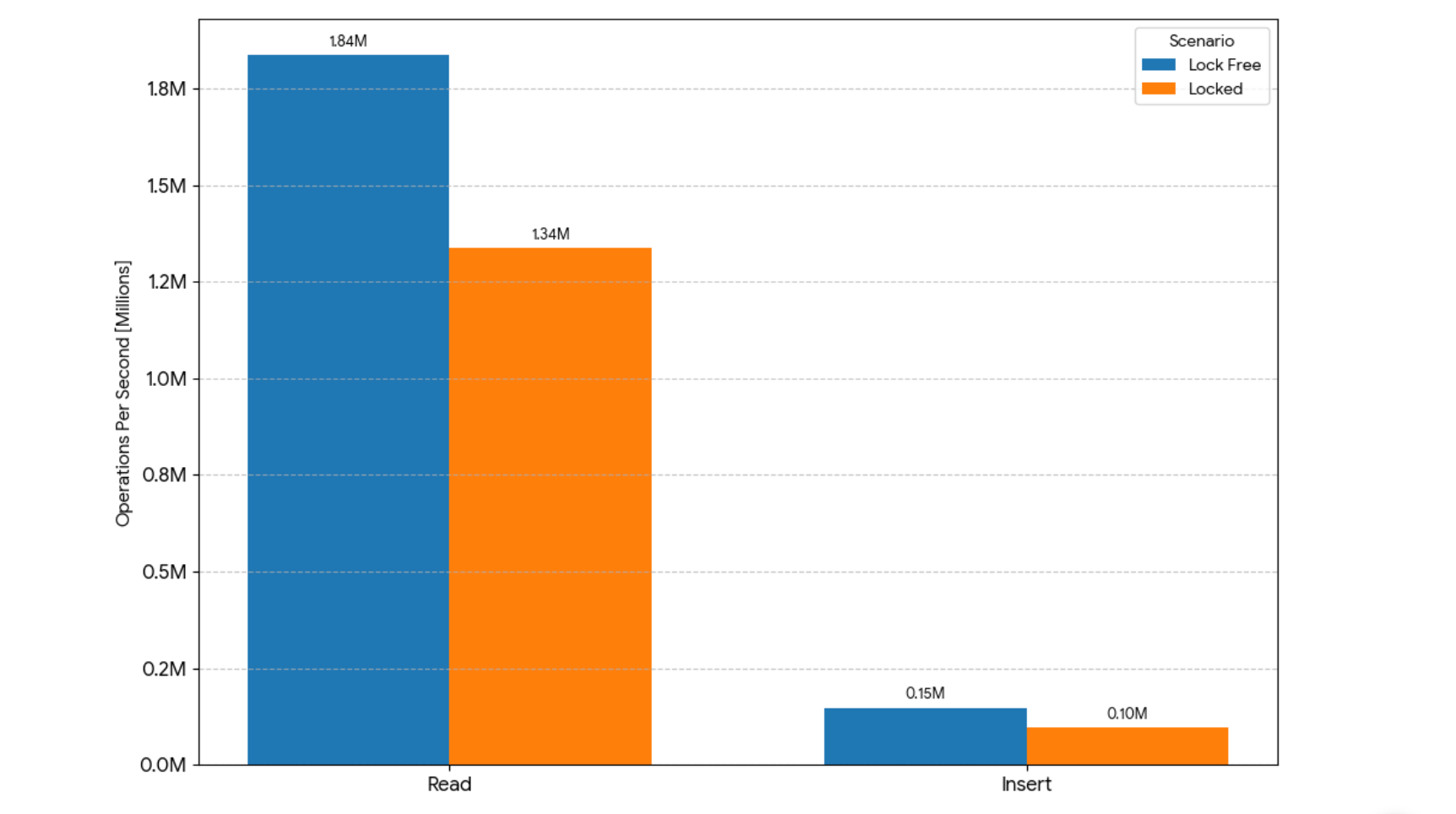
While in-memory read performance is important, the true challenge lies in workloads that modify database content simultaneously. A benchmark with mixed read and write operations revealed substantial improvements in a lock-free environment:
- With read/write locks: 96,287 inserts/second, 1,337,068 reads/second.
- Without read/write locks: 147,988 inserts/second, 1,836,968 reads/second.
- Performance improvement: 53% increase in insert throughput, 37% increase in read throughput.
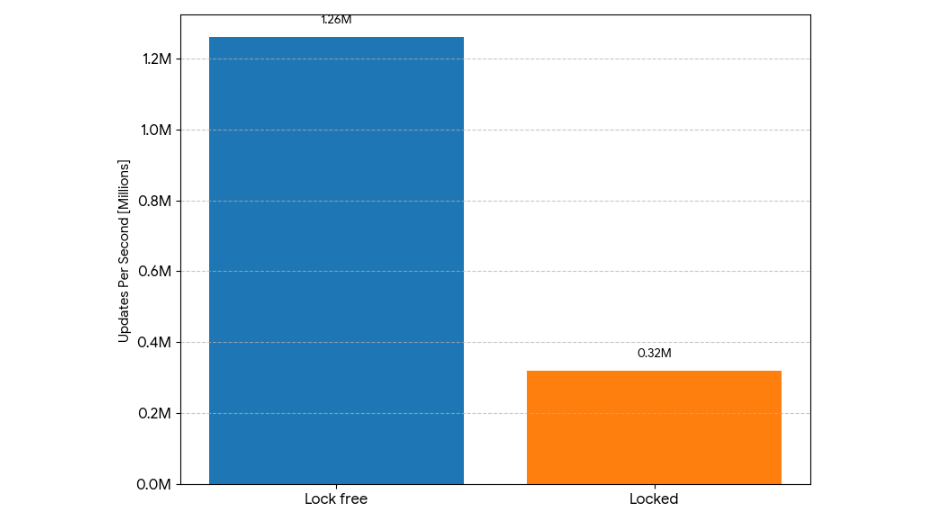
High-contention update workloads:
To further evaluate the impact of contention, a test was conducted with 128 threads simultaneously appending to the end of a key range. This scenario is particularly relevant for MongoDB, mimicking operations like Oplog writes and document additions to non-clustered collections.
- With write lock for updates: 319,903 inserts per second.
- Without write lock for updates: 1,259,630 inserts per second.
- Performance improvement: Nearly a 4x increase in throughput.
These results highlight the substantial performance advantages achieved by MongoDB's lock-free B+tree architecture across various workloads, particularly in scenarios involving contention and simultaneous modifications.
The results were generated on an AWS m7g.4xlarge.
Culmination
While implementing and debugging lock-free algorithms presents significant engineering challenges, the performance benefits for a database like MongoDB are clear. By minimizing coordination overhead and maximizing parallel execution, WiredTiger's lock-free B+tree architecture helps customers unlock the full potential of their hardware, leading to greater throughput and responsiveness for their applications.
Better hardware utilization also translates directly into cost savings for MongoDB users because they get more database operations per dollar spent on hardware. This commitment to advanced concurrency techniques ensures MongoDB remains a high-performance choice for demanding workloads in distributed environments.
Next Steps
Join our MongoDB Community to learn about upcoming events, hear stories from MongoDB users, and connect with community members from around the world.