In today's fast-paced digital landscape, businesses are constantly seeking innovative ways to stay competitive and deliver exceptional user experiences. However, many organizations find themselves hindered by the burden of outdated legacy applications, technical debt, and the subsequent impact on their customers.
The need of the hour is to pivot towards a solution that can revolutionize the way businesses operate: application modernization. By addressing the challenges of legacy applications, tackling technical debt, and leveraging modernization strategies, organizations can enhance customer impact, streamline processes, and confidently embrace the future.
In the journey toward application modernization, selecting the right database and database design plays a crucial role. Clients have the challenges of the correct method of refractoring, fear of touching the aged legacy code base, lengthy traditional modernization process, high uncertainty of business-as-usual (BAU) support, and difficulty to modernize the data layer.
To overcome these challenges, organizations are turning to modern database solutions like MongoDB Atlas, a popular NoSQL database. MongoDB offers agility and scalability, making it an ideal choice for modernizing applications. Its flexible schema allows for dynamic changes without disrupting functionality, and it offers horizontal scalability to handle large amounts of data and growing user demands.
Cloud-native databases, like MongoDB Atlas, further enhance modernization efforts. They provide fault tolerance, high availability, and elastic scaling, enabling organizations to design resilient and scalable systems. By leveraging MongoDB Atlas, businesses can optimize performance, adapt to changing needs, and ensure data availability.
In the pursuit of application modernization, carefully evaluating existing database structures, and embracing MongoDB Atlas, cloud-native databases can unlock the full potential of applications. This enables improved performance, flexibility, and scalability while minimizing the limitations posed by structured databases.
MongoDB Atlas
MongoDB is an Amazon Web Services (AWS) Partner with multiple AWS Competencies including Data & Analytics, Financial Services, and Government. MongoDB Atlas on AWS is the leading unified modern database that accelerates and simplifies how you build with data. MongoDB Atlas gives you the versatility you need to build sophisticated applications that can adapt to evolving customer and market demands. An intuitive document data model and unified query API provide a first-class developer experience, delivered in a cloud-native modern database built for resilience, scale, and the highest levels of data privacy and security. Power transactions, search, and application-driven analytics seamlessly through an elegant and integrated data architecture. With MongoDB Atlas, developers can focus on building their modern applications without worrying about the complexities of infrastructure provisioning, database setup, and ongoing maintenance. It provides features such as automated backups, monitoring, and built-in security measures to ensure data integrity and reliability. MongoDB Atlas empowers businesses to leverage the full potential of MongoDB's flexible document-based data model while benefiting from the scalability, availability, and ease of use offered by a cloud-based database service.
MongoDB on AWS
MongoDB Atlas on AWS combines best-in-class operational automation, scalability, and resilience of cloud-native services. It is available across 27+ AWS regions and has deep integrations with multiple AWS services. It enables organizations to leverage the cloud infrastructure provided by AWS to deploy, manage, and scale their MongoDB databases seamlessly. With features like automated backups, monitoring, and integration with AWS services like Amazon Elastic Compute Cloud and Amazon Simple Storage Service (Amazon S3), MongoDB on AWS empowers businesses to optimize performance, ensure data availability, and easily adapt to changing demands.
Accenture Data Factory
Accenture Data Factory solution is a tri-party solution from MongoDB, Accenture, and AWS leveraging MongoDB Atlas and AWS services. It’s an industry-leading solution, with highly experienced delivery teams working on the nuances of the application and database migration. It accelerates the migration process and provides 24X7 support across 27+ AWS regions.
The process includes the study of the current application architecture, decomposition of the legacy applications, and migration using the standard Re-imagine, Re-factor, and Modernization of applications.
The Data Factory refocuses the customer’s perspective from cost to value throughout the cloud journey.
The solution offering includes the Lift & Shift of self-managed databases, Legacy Modernization (Brownfield), and Modern Application Development (Greenfield) capabilities.
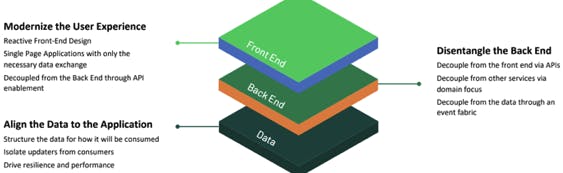
Lift & shift
This process of Lift & Shift is generally adopted in the customer-managed database. The Lift & Shift approach leaves the application architecture largely untouched, with the exception of migrating from self-managed on-premise infrastructure components into a modern, cloud-native / cloud-managed capability.
Lift & Shift provides comparatively quick benefits, limited to infrastructure and support cost reductions, but since the process undertakes no functional improvement, the same technical debt is carried to the cloud environment.
Legacy modernization
The Legacy Modernization process is a brown-field method of re-imagining legacy monolithic applications to harness the true potential of the cloud. It modernizes the existing application by decomposing the existing application and transforming them to the latest microservices and event-driven architecture, leveraging some of the existing legacy code bases, wherever it’s possible.
Accenture’s Refractory with Data offering operates inside this Legacy Modernization capability and helps unlock significant value trapped in legacy applications and codebases. See the detailed discussion below.
Modern application development
Modern Application Development provides a green-field approach where new applications are developed using modernized architectures like Microservices, Event-Based, Serverless, and others. For modern applications, NoSQL platforms, especially MongoDB Atlas on AWS provide the ideal solution for the data layer. A lengthy discussion of these advantages can be found in other whitepapers but can be summarized as follows:
NoSQL solutions scale linearly and nearly indefinitely for minimal risk at a very low cost compared with typical RDBMS alternatives
NoSQL solutions now offer the same ACID transaction guarantees and capabilities provided by RDBMS platforms – but also the modern architecture using a service layer for all database interactions reduces the critical complexity of ACID transactions at the data layer
NoSQL solutions provide seamless support and integration with DevOps and CI/CD driven deployment pipelines. NoSQL platforms like MongoDB Atlas allow updates to schema and core architectures without the pain of a database outage to make schema updates, data table reloads, and planning for rollbacks.
The Refractory with data approach to application modernization
Refractory provides a systematic approach to define a clear path from the current state of legacy applications to the desirable state of modern cloud-native microservices with modern data architectures
Refractory With Data follows a 4-step process:
Decompose and decouple the legacy application with functional wrappers
Improve and re-imagine code within each functional unit
Arrange functions into containers with clear domain boundaries
Re-architect legacy data structures (RDBMS) into domain-specific data components, typically in a NoSQL architecture ideal for Microservices
Decompose and decouple the legacy application
Decoupling the application's components promotes loose coupling, allowing for independent development and improved maintainability and Decomposing a legacy application involves breaking it down into smaller, more manageable components, enabling gradual modernization and enhanced scalability.
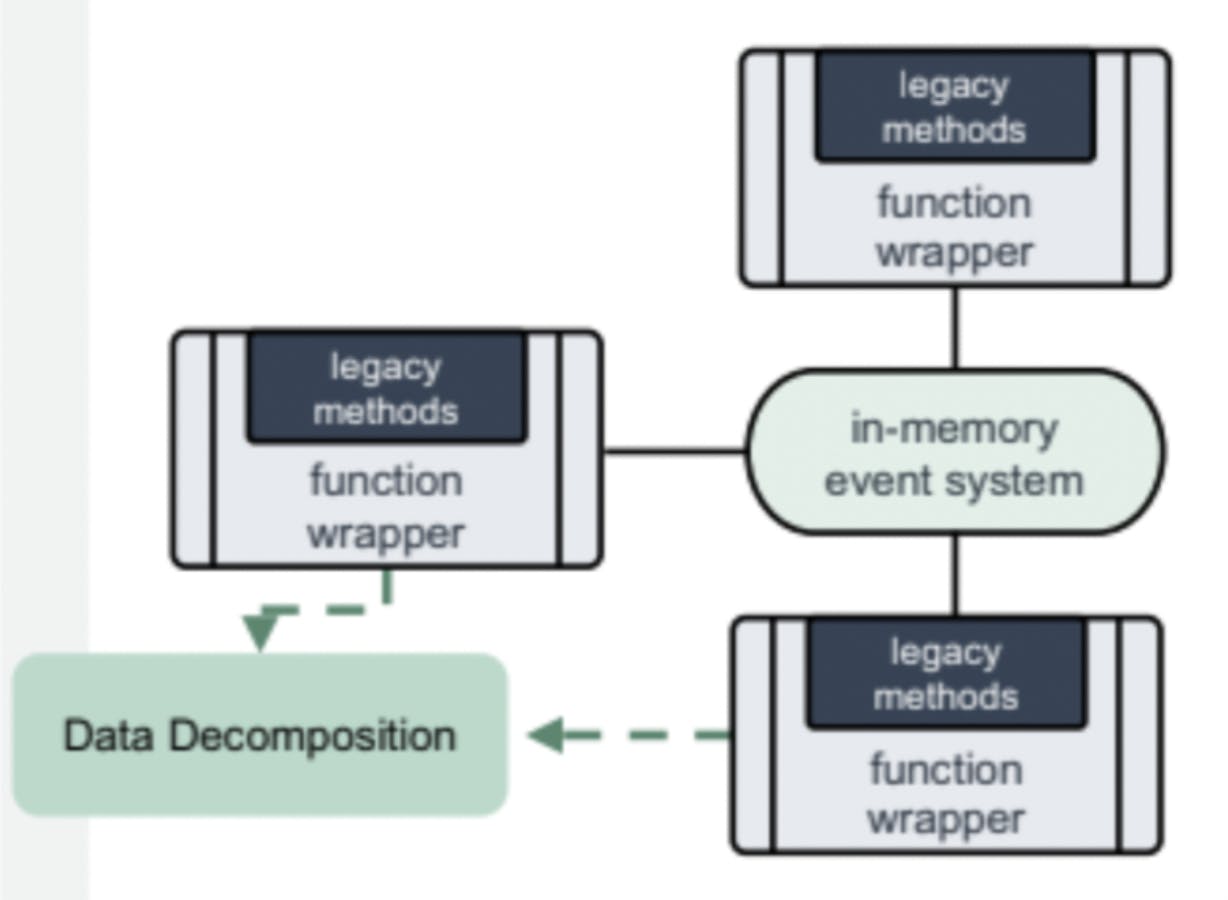
There are several methods commonly used for decoupling and decomposing legacy applications. Some of the methods are described below.
Functional decoupling
Functional decoupling of a legacy application is a process that involves isolating and separating its individual functionalities into modular and independent components. By decoupling the functions, organizations can achieve improved flexibility, maintainability, and scalability. This approach allows teams to work on specific functionalities without impacting the entire application, enabling parallel development and faster iterations. Functional decoupling reduces the dependencies and interdependencies within the legacy application, facilitating easier updates, bug fixes, and enhancements. It also paves the way for adopting modern architectural patterns, such as microservices or event-driven architecture, ultimately leading to a more agile and future-proof system.
Domain driven design (DDD)
DDD emphasizes understanding and modeling the core domains within a legacy application. By identifying bounded contexts and defining domain-driven architectures, businesses can decompose the application into smaller, cohesive units focused on specific domains. This method enhances modularity, and maintainability, and enables teams to work autonomously on different domains.
Improve and reimagine code
The data factory solution will look into each of the functional units and adopt the modernization process either through the Microservice Architecture or Event-Based architecture.
Microservices architecture
Decomposing the legacy application into a microservices architecture involves breaking it down into smaller, independent services that communicate with each other via APIs. Each microservice focuses on a specific business capability, making it easier to develop, test, and deploy. This approach enhances scalability, and flexibility, and enables teams to work on different services simultaneously. It’s also following multiple microservice architecture patterns that are suitable for various business demands. Some of the patterns are described below.
API Gateway pattern:
The API Gateway pattern acts as a single entry point for client applications to interact with multiple microservices. It consolidates requests from clients, performs authentication and authorization, and routes requests to the appropriate microservices. This pattern helps to centralize cross-cutting concerns like security, rate limiting, and request/response transformations, simplifying the client's interaction with the microservices.
Service registry pattern:
The Service Registry pattern is used to dynamically discover and locate microservices within a system. It involves a central registry that keeps track of registered services and their network locations. Microservices can register themselves with the registry and retrieve information about other services at runtime. This pattern promotes loose coupling between services, as they can be added or removed without requiring explicit configuration between them.
Circuit breaker pattern:
The Circuit Breaker pattern helps to handle faults and failures in microservice interactions. It adds a layer of protection to prevent cascading failures in a distributed system. The circuit breaker monitors requests to external services and, in case of failures or unresponsiveness, temporarily halts subsequent requests to allow the failing service to recover. This pattern enhances fault tolerance, and resilience, and prevents the system from becoming overwhelmed by failing services.
Event sourcing pattern:
The Event Sourcing pattern involves capturing and storing all changes to an application's state as a sequence of events. Instead of persisting in the current state, the system maintains an append-only log of events. The events can be replayed to reconstruct the system's state at any given point in time. This pattern enables auditing, and scalability, and provides a historical record of how the application's state evolved over time.
Saga pattern:
The Saga pattern helps maintain data consistency and coordination across multiple microservices during complex, long-running transactions. It decomposes a single transaction into a series of smaller, loosely coupled steps or compensating actions. If any step fails, compensating actions are executed to undo the changes made by previous steps. This pattern allows for eventual consistency and prevents partial updates or inconsistencies in distributed transactions. Each of these microservice patterns addresses specific challenges and provides guidelines for designing resilient, scalable, and loosely coupled microservice architectures. Implementing these patterns appropriately can help organizations build robust and manageable microservice systems.
Event-driven architecture (EDA)
It is an approach where components of the legacy application communicate and react to events that occur within the system. Events can trigger actions and updates across various services, enabling loose coupling and scalability. EDA promotes responsiveness, extensibility, and the ability to handle complex, real-time interactions.
Each of these decomposition methods offers a unique approach to modernizing legacy applications, and organizations may choose to adopt one or a combination of them based on their specific needs and constraints. The ultimate goal is to break down the monolithic nature of the legacy application, enabling agility, scalability, and improved software development practices.
Arrange functions into containers
Containerization and microservice architectures go hand in hand to enable scalable and efficient application development and deployment. Containerization involves encapsulating an application and its dependencies into lightweight, isolated units known as containers. These containers provide consistent environments across different platforms, ensuring that the application runs reliably, regardless of the underlying infrastructure. Microservice architectures, on the other hand, break down an application into smaller, independent services that can be developed, deployed, and scaled independently. By combining containerization with microservices, organizations can achieve greater agility, scalability, and ease of deployment. Containers provide a portable and consistent execution environment for microservices, allowing for rapid development, deployment, and scaling of individual services. This approach promotes modularity, and fault isolation, and enhances the ability to leverage cloud-native technologies, enabling organizations to efficiently build, deploy, and manage complex applications in distributed environments.
Re-architect legacy data structures
The refractory framework leverages MongoDB database schema design patterns to re-architect the legacy data structures. Each of these schema patterns satisfies a set of unique business requirements. Some of the patterns are described below:
Embedded data model:
This pattern involves embedding related data within a single document. It is suitable for one-to-one or one-to-many relationships where the embedded data is accessed and modified together. It improves read performance as the data is retrieved in a single document access, but updates can be more complex if the embedded data needs frequent modifications.
Normalized data model:
In this pattern, related data is stored in separate collections and linked using references or foreign keys. It is ideal for many-to-many relationships or scenarios where data updates are frequent. While it ensures data consistency and simplifies updates, it may require additional queries to fetch related data, potentially impacting read performance.
Tree structure model:
This pattern is suitable for hierarchical or tree-like data structures, such as categories, organizational charts, or comment threads. It uses a parent-child relationship to represent the hierarchy, allowing easy navigation and retrieval of hierarchical data. However, maintaining integrity and performing updates across the tree can be more complex.
Polymorphic data model:
This pattern handles scenarios where a field can accept different data types. It allows for storing different types of data within the same field, making the schema more flexible. This pattern can simplify the schema but may require additional logic to handle different data types correctly.
Bucket pattern:
The bucket pattern is used to optimize queries on large collections by partitioning the data into smaller "buckets" based on specific criteria, such as time ranges or ranges of values. It helps improve query performance by reducing the amount of data scanned in a query, but it requires careful planning and consideration of the query patterns.
It's important to note that the choice of schema design pattern depends on the specific requirements of the application, such as data relationships, read and write patterns, performance considerations, and scalability needs. Understanding these patterns and selecting the most appropriate one can help optimize the performance and efficiency of MongoDB database operations.
Customer references
We adopted the refractory model with one of the leading North America Insurance firms for modernizing their application landscape. The customer needed to modernize a huge monolithic application delivering to the needs of the customer. But with the monolith architecture the insurance firm was challenged with the agile business changes and innovation of their product. Release management was limited to only two releases per year due to the complex regression testing of the massive application spanning the mainframe and multiple technologies.
The solution was originally hosted on the Mainframe supported by an RDBMS database. Following the Refractory approach the application was modernized into Microservices on MongoDB Atlas on AWS. In the process, we also created a consolidated operational data layer to optimize the business layer of their application stack
The developer productivity increased by more than 70% by taking advantage of MongoDB’s integration with agile-friendly deployment processes and the number of product releases also increased considerably to 5 major and 350+ minor releases in a calendar year.
Recap
With the Data Factory solution, you can deploy, manage, and grow your database on AWS for customer needs without any major disruption, enabling organizations to leverage the power of data.