Calling the MongoDB Atlas Administration API: How to Do it from Node, Python, and Ruby







Rate this tutorial


The real power of a cloud-hosted, fully managed service like MongoDB Atlas is that you can create whole new database deployment architectures automatically, using the services API. Getting to the MongoDB Atlas Administration API is relatively simple and, once unlocked, it opens up a massive opportunity to integrate and automate the management of database deployments from creation to deletion. The API itself is an extensive REST API. There's role-based access control and you can have user or app-specific credentials to access it.
There is one tiny thing that can trip people up though. The credentials have to be passed over using the digest authentication mechanism, not the more common basic authentication or using an issued token. Digest authentication, at its simplest, waits to get an HTTP
401 Unauthorized response from the web endpoint. That response comes with data and the client then sends an encrypted form of the username and password as a digest and the server works with that.And that's why we’re here today: to show you how to do that with the least fuss in Python, Node, and Ruby. In each example, we'll try and access the base URL of the Atlas Administration API which returns a JSON document about the underlying applications name, build and other facts.
You can find all code samples in the dedicated Github repository.
To use the Atlas Administration API, you need… a MongoDB Atlas cluster! If you don’t have one already, follow the Get Started with Atlas guide to create your first cluster.
The next requirement is the organization API key. You can set it up in two steps:
Create an API key in your Atlas organization. Make sure the key has the Organization Owner permission.
Add your IP address to the API Access List for the API key.
Then, open a new terminal and export the following environment variables, where
ATLAS_USER is your public key and ATLAS_USER_KEY is your private key.
You’re all set up! Let’s see how we can use the Admin API with Python, Node, and Ruby.
We start with the simplest and most self-contained example: Python.
In the Python version, we lean on the
requests library for most of the heavy lifting. We can install it with pip:The implementation of the digest authentication itself is the following:
As well as importing
requests, we also bring in HTTPDigestAuth from requests' auth module to handle digest authentication. The os import is just there so we can get the environment variables ATLAS_USER and ATLAS_USER_KEY as credentials, and the pprint import is just to format our results.The critical part is the addition of
auth = HTTPDigestAuth(...) to the requests.get() call. This installs the code needed to respond to the server when it asks for the digest.If we now run this program...

…we have our API response.
For Node.js, we’ll take advantage of the
urllib package which supports digest authentication.The code for the Node.js HTTP request is the following:
Taking it from the top… we first require and import the
urllib package. Then, we extract the ATLAS_USER and ATLAS_USER_KEY variables from the process environment and use them to construct the authentication key. Finally, we send the request and handle the response in the passed callback.And we’re ready to run:
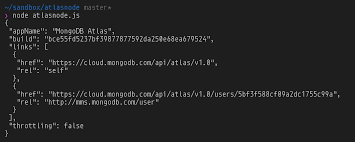
On to our final language...
HTTParty is a widely used Gem which is used by the Ruby and Rails community to perform HTTP operations. It also, luckily, supports digest authentication. So, to get the party started:
There are two ways to use HTTParty. One is creating an object which abstracts the calls away while the other is just directly calling methods on HTTParty itself. For brevity, we'll do the latter. Here's the code:
We require the HTTParty and JSON gems first. We then create a dictionary with our username and key, mapped for HTTParty's authentication, and set a variable to hold the base URL. We're ready to do our GET request now, and in the
options (the second parameter of the GET request), we pass :digest_auth=>auth to switch on the digest support. We wrap up by JSON parsing the resulting body and pretty printing that. Put it all together and run it and we get:
In this article, we learned how to call the MongoDB Atlas Administration API using digest authentication. We took advantage of the vast library ecosystems of Python, Node.js, and Ruby, and used the following open-source community libraries:
Requests for Python
urllib for JavaScript
httparty for Ruby
If your project requires it, you can implement digest authentication yourself by following the official specification. You can draw inspiration from the implementations in the aforementioned libraries.
Additionally, you can find all code samples from the article in Github.
With the authentication taken care of, just remember to be fastidious with your API key security and make sure you revoke unused keys. You can now move on to explore the API itself. Start in the documentation and see what you can automate today.
Rate this tutorial