本指南介绍如何使用 Voyage AI模型执行语义搜索。本页包含基本和高级语义搜索使用案例的示例,包括带重新排名的搜索,以及多语言、多模式、上下文化数据数据块和大型语料库检索。
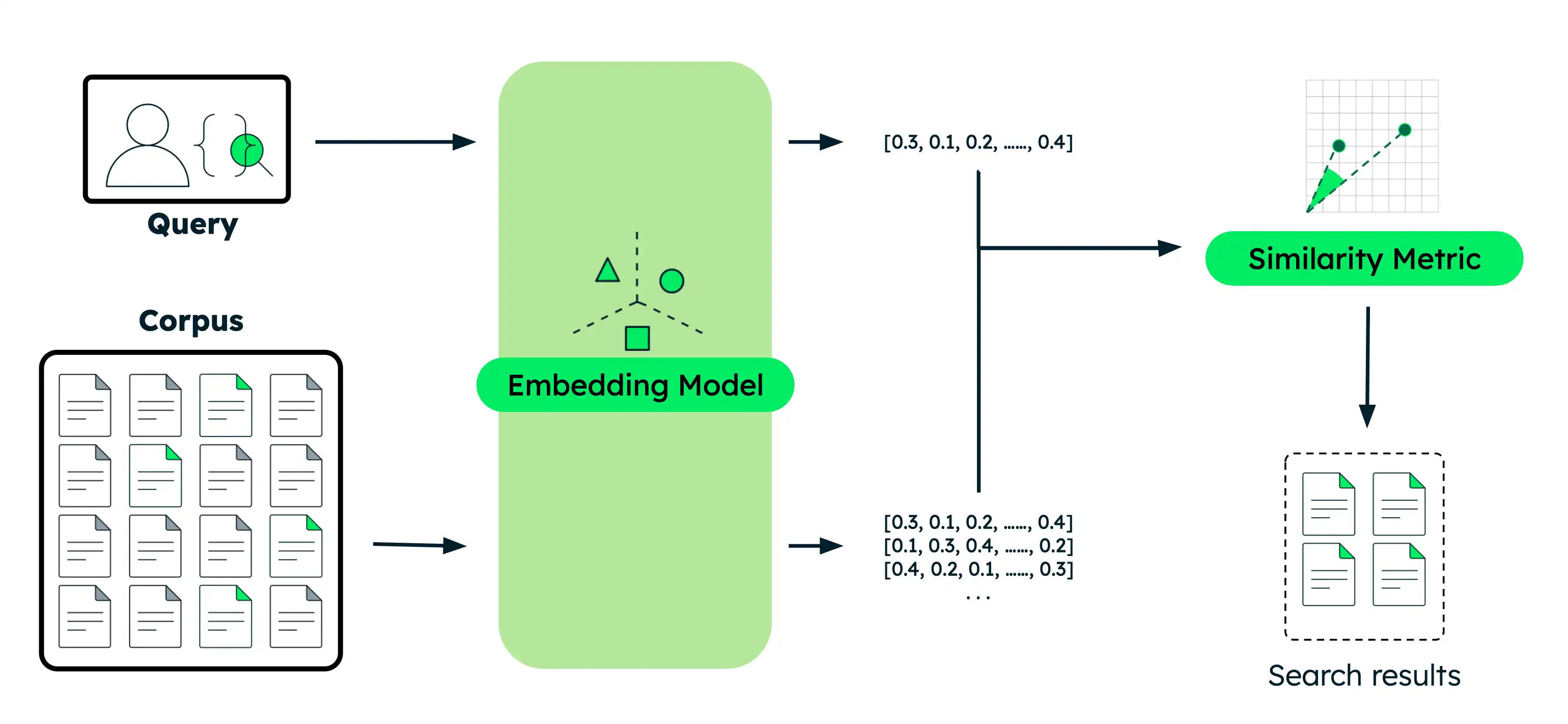
执行语义搜索
本节提供使用不同 Voyage AI模型的各种语义搜索用例的代码示例。对于每个示例,您都执行相同的基本步骤:
嵌入文档:将数据转换为能够捕捉其含义的向量嵌入。这些数据可以是文本、图像、文档数据块或大型文本语料库。
嵌入查询:将搜索查询转换为与文档相同的向量表示形式。
查找相似文档:将查询向量与文档向量进行比较,以确定语义上最相似的结果。
使用可运行版本的本教程以作为 Python 笔记本。
设置您的环境。
在开始之前,请创建项目目录、安装库并设立模型API密钥。
在终端中运行以下命令,为本教程创建新目录并安装所需的库:
mkdir voyage-semantic-search cd voyage-semantic-search pip install --upgrade voyageai numpy datasets 如果您还没有,请按照步骤创建模型API密钥,然后在终端中运行以下命令,将其作为环境变量导出:
export VOYAGE_API_KEY="your-model-api-key"
运行语义搜索查询。
展开每个部分以获取每种类型的语义搜索的代码示例。
在项目中创建一个名为
semantic_search_basic.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort documents by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices, 1): print(f"{rank}. {documents[idx]}") print(f" Similarity: {similarities[idx]:.4f}\n")
在终端中运行以下命令:
python semantic_search_basic.py
Query: 'When is Apple's conference call scheduled?' 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity: 0.2335 4. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Similarity: 0.1955 5. Photosynthesis in plants converts light energy into glucose and produces essential oxygen. Similarity: 0.1881 6. Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems. Similarity: 0.1601
在项目中创建一个名为
semantic_search_reranker.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents documents = [ "The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases.", "Photosynthesis in plants converts light energy into glucose and produces essential oxygen.", "20th-century innovations, from radios to smartphones, centered on electronic advancements.", "Rivers provide water, irrigation, and habitat for aquatic species, vital for ecosystems.", "Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET.", "Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature." ] # Search query query = "When is Apple's conference call scheduled?" # Generate embeddings for documents doc_embeddings = vo.embed( texts=documents, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(doc_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display results before reranking print(f"Query: '{query}'\n") print("Before reranker (embedding similarity only):") for rank, idx in enumerate(ranked_indices[:3], 1): print(f"{rank}. {documents[idx]}") print(f" Similarity Score: {similarities[idx]:.4f}\n") # Rerank documents for improved accuracy rerank_results = vo.rerank( query=query, documents=documents, model="rerank-2.5" ) # Display results after reranking print("\nAfter reranker:") for rank, result in enumerate(rerank_results.results[:3], 1): print(f"{rank}. {documents[result.index]}") print(f" Relevance Score: {result.relevance_score:.4f}\n")
在终端中运行以下命令:
python semantic_search_reranker.py
Query: 'When is Apple's conference call scheduled?' Before reranker (embedding similarity only): 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Similarity Score: 0.6691 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Similarity Score: 0.2751 3. Shakespeare's works, like 'Hamlet' and 'A Midsummer Night's Dream,' endure in literature. Similarity Score: 0.2335 After reranker: 1. Apple's conference call to discuss fourth fiscal quarter results and business updates is scheduled for Thursday, November 2, 2023 at 2:00 p.m. PT / 5:00 p.m. ET. Relevance Score: 0.9453 2. 20th-century innovations, from radios to smartphones, centered on electronic advancements. Relevance Score: 0.2832 3. The Mediterranean diet emphasizes fish, olive oil, and vegetables, believed to reduce chronic diseases. Relevance Score: 0.2637
在项目中创建一个名为
semantic_search_multilingual.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # English documents about technology companies english_docs = [ "Apple announced record-breaking revenue in its latest quarterly earnings report.", "The Mediterranean diet emphasizes fish, olive oil, and vegetables.", "Microsoft is investing heavily in artificial intelligence and cloud computing.", "Shakespeare's plays continue to influence modern literature and theater." ] # Spanish documents about technology companies spanish_docs = [ "Apple anunció ingresos récord en su último informe trimestral de ganancias.", "La dieta mediterránea enfatiza el pescado, el aceite de oliva y las verduras.", "Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube.", "Las obras de Shakespeare continúan influenciando la literatura y el teatro modernos." ] # Chinese documents about technology companies chinese_docs = [ "苹果公司在最新季度财报中宣布创纪录的收入。", "地中海饮食强调鱼类、橄榄油和蔬菜。", "微软正在大力投资人工智能和云计算。", "莎士比亚的作品继续影响现代文学和戏剧。" ] # Perform semantic search in English english_query = "tech company earnings" # Generate embeddings for English documents english_embeddings = vo.embed( texts=english_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for English query english_query_embedding = vo.embed( texts=[english_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product english_similarities = np.dot(english_embeddings, english_query_embedding) # Sort by similarity (highest to lowest) english_ranked = np.argsort(-english_similarities) print(f"English Query: '{english_query}'\n") for rank, idx in enumerate(english_ranked[:2], 1): print(f"{rank}. {english_docs[idx]}") print(f" Similarity: {english_similarities[idx]:.4f}\n") # Perform semantic search in Spanish spanish_query = "ganancias de empresas tecnológicas" # Generate embeddings for Spanish documents spanish_embeddings = vo.embed( texts=spanish_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Spanish query spanish_query_embedding = vo.embed( texts=[spanish_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product spanish_similarities = np.dot(spanish_embeddings, spanish_query_embedding) # Sort by similarity (highest to lowest) spanish_ranked = np.argsort(-spanish_similarities) print(f"Spanish Query: '{spanish_query}'\n") for rank, idx in enumerate(spanish_ranked[:2], 1): print(f"{rank}. {spanish_docs[idx]}") print(f" Similarity: {spanish_similarities[idx]:.4f}\n") # Perform semantic search in Chinese chinese_query = "科技公司收益" # Generate embeddings for Chinese documents chinese_embeddings = vo.embed( texts=chinese_docs, model="voyage-4-large", input_type="document" ).embeddings # Generate embedding for Chinese query chinese_query_embedding = vo.embed( texts=[chinese_query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product chinese_similarities = np.dot(chinese_embeddings, chinese_query_embedding) # Sort by similarity (highest to lowest) chinese_ranked = np.argsort(-chinese_similarities) print(f"Chinese Query: '{chinese_query}'\n") for rank, idx in enumerate(chinese_ranked[:2], 1): print(f"{rank}. {chinese_docs[idx]}") print(f" Similarity: {chinese_similarities[idx]:.4f}\n")
在终端中运行以下命令:
python semantic_search_multilingual.py
English Query: 'tech company earnings' 1. Apple announced record-breaking revenue in its latest quarterly earnings report. Similarity: 0.5172 2. Microsoft is investing heavily in artificial intelligence and cloud computing. Similarity: 0.4745 Spanish Query: 'ganancias de empresas tecnológicas' 1. Apple anunció ingresos récord en su último informe trimestral de ganancias. Similarity: 0.5232 2. Microsoft está invirtiendo fuertemente en inteligencia artificial y computación en la nube. Similarity: 0.4871 Chinese Query: '科技公司收益' 1. 苹果公司在最新季度财报中宣布创纪录的收入。 Similarity: 0.4725 2. 微软正在大力投资人工智能和云计算。 Similarity: 0.4426
搜索示例图像并将它们保存在项目目录中。以下代码示例假设您有猫、狗和香蕉的图像。
在项目中创建一个名为
semantic_search_multimodal.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np from PIL import Image # Initialize Voyage AI client vo = voyageai.Client() # Prepare interleaved text + image inputs interleaved_inputs = [ ["An orange cat", Image.open('cat.jpg')], ["A golden retriever", Image.open('dog.jpg')], ["A banana", Image.open('banana.jpg')], ] # Prepare image-only inputs image_only_inputs = [ [Image.open('cat.jpg')], [Image.open('dog.jpg')], [Image.open('banana.jpg')], ] # Labels for display labels = ["cat.jpg", "dog.jpg", "banana.jpg"] # Search query query = "a cute pet" # Generate embeddings for interleaved text + image inputs interleaved_embeddings = vo.multimodal_embed( inputs=interleaved_inputs, model="voyage-multimodal-3.5" ).embeddings # Generate embedding for query query_embedding = vo.multimodal_embed( inputs=[[query]], model="voyage-multimodal-3.5" ).embeddings[0] # Calculate similarity scores using dot product interleaved_similarities = np.dot(interleaved_embeddings, query_embedding) # Sort by similarity (highest to lowest) interleaved_ranked = np.argsort(-interleaved_similarities) print(f"Query: '{query}'\n") print("Search with interleaved text + image:") for rank, idx in enumerate(interleaved_ranked, 1): print(f"{rank}. {interleaved_inputs[idx][0]}") print(f" Similarity: {interleaved_similarities[idx]:.4f}\n") # Generate embeddings for image-only inputs image_only_embeddings = vo.multimodal_embed( inputs=image_only_inputs, model="voyage-multimodal-3.5" ).embeddings # Calculate similarity scores using dot product image_only_similarities = np.dot(image_only_embeddings, query_embedding) # Sort by similarity (highest to lowest) image_only_ranked = np.argsort(-image_only_similarities) print("\nSearch with image-only:") for rank, idx in enumerate(image_only_ranked, 1): print(f"{rank}. {labels[idx]}") print(f" Similarity: {image_only_similarities[idx]:.4f}\n")
在终端中运行以下命令:
python semantic_search_multimodal.py
Query: 'a cute pet' Search with interleaved text + image: 1. An orange cat Similarity: 0.2685 2. A golden retriever Similarity: 0.2325 3. A banana Similarity: 0.1564 Search with image-only: 1. dog.jpg Similarity: 0.2485 2. cat.jpg Similarity: 0.2438 3. banana.jpg Similarity: 0.1210
在项目中创建一个名为
semantic_search_contextualized.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np # Initialize Voyage AI client vo = voyageai.Client() # Sample documents (each document is a list of chunks that share context) documents = [ [ "This is the SEC filing on Greenery Corp.'s Q2 2024 performance.", "The company's revenue increased by 7% compared to the previous quarter." ], [ "This is the SEC filing on Leafy Inc.'s Q2 2024 performance.", "The company's revenue increased by 15% compared to the previous quarter." ], [ "This is the SEC filing on Elephant Ltd.'s Q2 2024 performance.", "The company's revenue decreased by 2% compared to the previous quarter." ] ] # Search query query = "What was the revenue growth for Leafy Inc. in Q2 2024?" # Generate contextualized embeddings (preserves relationships between chunks) contextualized_result = vo.contextualized_embed( inputs=documents, model="voyage-context-3", input_type="document" ) # Flatten the embeddings and chunks for semantic search contextualized_embeddings = [] all_chunks = [] chunk_to_doc = [] # Maps chunk index to document index for doc_idx, result in enumerate(contextualized_result.results): for emb, chunk in zip(result.embeddings, documents[doc_idx]): contextualized_embeddings.append(emb) all_chunks.append(chunk) chunk_to_doc.append(doc_idx) # Generate contextualized query embedding query_embedding_ctx = vo.contextualized_embed( inputs=[[query]], model="voyage-context-3", input_type="query" ).results[0].embeddings[0] # Calculate similarity scores using dot product similarities_ctx = np.dot(contextualized_embeddings, query_embedding_ctx) # Sort by similarity (highest to lowest) ranked_indices_ctx = np.argsort(-similarities_ctx) # Display top 3 results print(f"Query: '{query}'\n") for rank, idx in enumerate(ranked_indices_ctx[:3], 1): doc_idx = chunk_to_doc[idx] print(f"{rank}. {all_chunks[idx]}") print(f" (From document: {documents[doc_idx][0]})") print(f" Similarity: {similarities_ctx[idx]:.4f}\n")
在终端中运行以下命令:
python semantic_search_contextualized.py
Query: 'What was the revenue growth for Leafy Inc. in Q2 2024?' 1. The company's revenue increased by 15% compared to the previous quarter. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.7138 2. This is the SEC filing on Leafy Inc.'s Q2 2024 performance. (From document: This is the SEC filing on Leafy Inc.'s Q2 2024 performance.) Similarity: 0.6630 3. The company's revenue increased by 7% compared to the previous quarter. (From document: This is the SEC filing on Greenery Corp.'s Q2 2024 performance.) Similarity: 0.5531
在项目中创建一个名为
semantic_search_large_corpus.py的文件,并将以下代码粘贴到其中:
import voyageai import numpy as np from datasets import load_dataset from collections import defaultdict # Initialize Voyage AI client vo = voyageai.Client() # Load legal benchmark dataset corpus_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "corpus")["corpus"] queries_ds = load_dataset("mteb/legalbench_consumer_contracts_qa", "queries")["queries"] qrels_ds = load_dataset("mteb/legalbench_consumer_contracts_qa")["test"] # Extract corpus and query data corpus_ids = [row["_id"] for row in corpus_ds] corpus_texts = [row["text"] for row in corpus_ds] query_ids = [row["_id"] for row in queries_ds] query_texts = [row["text"] for row in queries_ds] # Build relevance mapping (defaultdict creates sets for missing keys) qrels = defaultdict(set) for row in qrels_ds: if row["score"] > 0: qrels[row["query-id"]].add(row["corpus-id"]) # Generate embeddings for the entire corpus print(f"Generating embeddings for {len(corpus_texts)} documents...") corpus_embeddings = vo.embed( texts=corpus_texts, model="voyage-4-large", input_type="document" ).embeddings # Select a sample query query_idx = 1 query = query_texts[query_idx] query_id = query_ids[query_idx] # Generate embedding for the query query_embedding = vo.embed( texts=[query], model="voyage-4-large", input_type="query" ).embeddings[0] # Calculate similarity scores using dot product similarities = np.dot(corpus_embeddings, query_embedding) # Sort by similarity (highest to lowest) ranked_indices = np.argsort(-similarities) # Display top 5 results print(f"Query: {query}\n") print("Top 5 Results:") for rank, idx in enumerate(ranked_indices[:5], 1): doc_id = corpus_ids[idx] is_relevant = "✓" if doc_id in qrels[query_id] else "✗" print(f"{rank}. [{is_relevant}] Document ID: {doc_id}") print(f" Similarity: {similarities[idx]:.4f}") print(f" Text: {corpus_texts[idx][:100]}...\n") # Show the ground truth most relevant document most_relevant_id = list(qrels[query_id])[0] most_relevant_idx = corpus_ids.index(most_relevant_id) print(f"Ground truth most relevant document:") print(f"Document ID: {most_relevant_id}") print(f"Rank in results: {np.where(ranked_indices == most_relevant_idx)[0][0] + 1}") print(f"Similarity: {similarities[most_relevant_idx]:.4f}")
在终端中运行以下命令:
python semantic_search_large_corpus.py
Generating embeddings for 154 documents... Query: Will Google come to a users assistance in the event of an alleged violation of such users IP rights? Top 5 Results: 1. [✓] Document ID: 9NIQ0Wobtq Similarity: 0.6047 Text: Your content Some of our services give you the opportunity to make your content publicly available ... 2. [✗] Document ID: gAk7Gdp0CX Similarity: 0.5515 Text: Taking action in case of problems Before taking action as described below, well provide you with adv... 3. [✗] Document ID: S87XwXaHCP Similarity: 0.5178 Text: Privacy and Data Protection Our Privacy Center explains how we treat your personal data. By using th... 4. [✗] Document ID: 8IRh1E2JDB Similarity: 0.5134 Text: OUR PROPERTY The Service is protected by copyright, trademark, and other US and foreign laws. These ... 5. [✗] Document ID: 50OXirZRiR Similarity: 0.5098 Text: Uploading Content If you have a YouTube channel, you may be able to upload Content to the Service. Y... Ground truth most relevant document: Document ID: 9NIQ0Wobtq Rank in results: 1 Similarity: 0.6047
关于示例
下表汇总了此页面上的示例:
例子 | 使用的模型 | 了解结果 |
|---|---|---|
基本语义搜索 |
| Apple 会议通话文档排名第一,明显高于不相关文档,体现了准确的语义匹配。 |
使用 Reranker 进行语义搜索 |
| 重新排名通过分析完整的查询-文档关系来提高搜索准确性。虽然单独嵌入相似度可以将正确的文档以中等分数排名第一,但重排序器显着提高了其相关性分数,从而更好地将其与不相关的结果区分开来。 |
多语言语义搜索 |
| Voyage 模型可跨不同语言有效执行语义搜索。该示例演示了英语、西班牙语和中文的三个独立搜索,每次搜索都正确识别各自语言中与科技公司收益最相关的文档。 |
多模态语义搜索 |
| 该模型支持交错的文本、图像和视频,以及仅图像和仅视频搜索。在这两种情况下,宠物图像(猫和狗)的排名明显高于不相关的香蕉图像,证明了视觉内容检索的准确性。与仅图像输入相比,带有描述性文本的交错输入产生的相似度分数稍高。 |
上下文化数据块嵌入 |
| 15%收入增长数据块排名第一,因为它链接到 Leafy Inc.文档。来自 Greenery Corp. 的相似 7% 增长数据块得分较低,这表明该模型如何准确地考虑文档上下文以区分其他方面相似的数据块。 |
使用大型语料库进行语义搜索 |
| 关于用户内容的参考标准文档在 154 个文档中排名第一,尽管语义复杂,但仍能有效地进行扩展检索。 |
- 访问嵌入
这些示例使用Python客户端
voyageai.Client(),它会自动从VOYAGE_API_KEY环境变量中读取API密钥。该API返回一个响应对象。使用.embeddings属性访问权限实际的嵌入向量:result = vo.embed(texts=["example"], model="voyage-4-large", input_type="document") embeddings = result.embeddings # List of embedding vectors - 计算相似度
这些示例使用 Numpy 的点积函数
np.dot()计算查询和文档嵌入之间的相似度分数。由于 Voyage AI嵌入被标准化为长度 1,因此点积在数学上等同于余弦相似度。为了按相似度对结果进行排名,这些示例使用 Numpy 的
argsort()函数显示前 N 个结果。负号按降序排序,因此相似度分数最高的最先出现。- 输入类型参数
input_type参数设立为query或document以优化 Voyage AI模型创建向量的方式。请勿省略此参数。要学习;了解更多信息,请参阅指定输入类型。
要学习;了解更多信息,请参阅访问 Voyage AI 模型或浏览完整的API规范。
什么是语义搜索?
语义搜索是一种根据数据的语义或根本的含义返回结果的搜索方法。与查找文本匹配的传统全文搜索不同,语义搜索会在多维空间中查找与搜索查询接近的向量。向量与您的查询越接近,它们在含义上就越相似。
例子
传统文本搜索仅返回精确匹配项,当用户使用与数据中不同的词语搜索时,结果会受到限制。示例,如果您的数据包含有关计算机鼠标和动物鼠标的文档,当您打算查找有关计算机鼠标的信息时搜索“鼠标”会导致不正确的匹配。
然而,即使没有词汇重叠,语义搜索也可以捕获单词或短语之间的根本的关系。在指示您正在寻找计算机产品时搜索“鼠标”会得到更相关的结果。这是因为语义搜索会将搜索查询的语义与数据进行比较,以仅返回最相关的结果,而不考虑确切的搜索词。

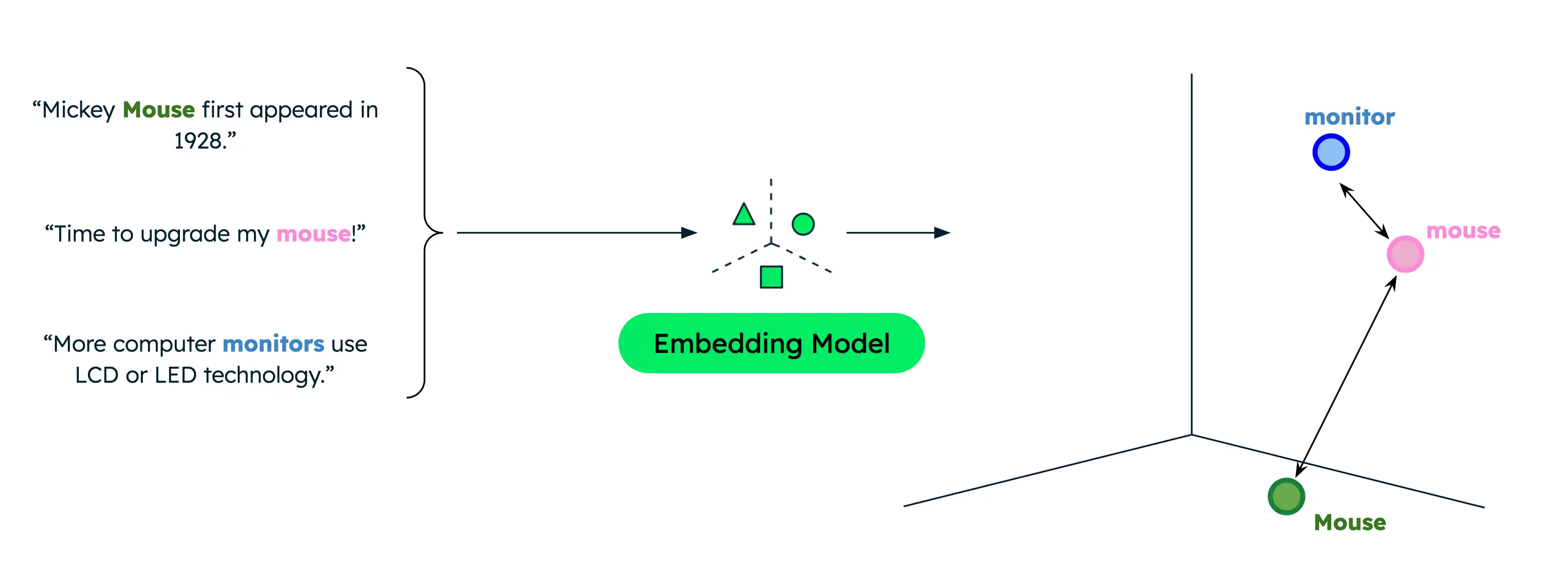
相似度函数可衡量两个向量彼此的接近程度,从而衡量它们的相似程度。常见函数包括点积、余弦相似度和欧几里得距离。Voyage AI嵌入标准化为长度 1,这意味着:
余弦相似度等同于点积相似度,而后者的计算速度更快。
余弦相似度和欧几里得距离会产生相同的排名。
生产环境中的语义搜索
将向量存储在内存中并实现自己的搜索管道适用于原型设计和实验,而将矢量数据库和企业搜索解决方案用于生产应用程序,以便从更大的语料库中执行高效检索。
MongoDB原生支持向量存储和检索,因此成为将向量嵌入与其他数据一起存储和搜索的便捷选择。要完成有关使用MongoDB Vector Search 执行语义搜索的教程,请参阅如何对Atlas集群中的数据执行语义搜索。
后续步骤
将语义搜索与LLM相结合,实现RAG应用程序。