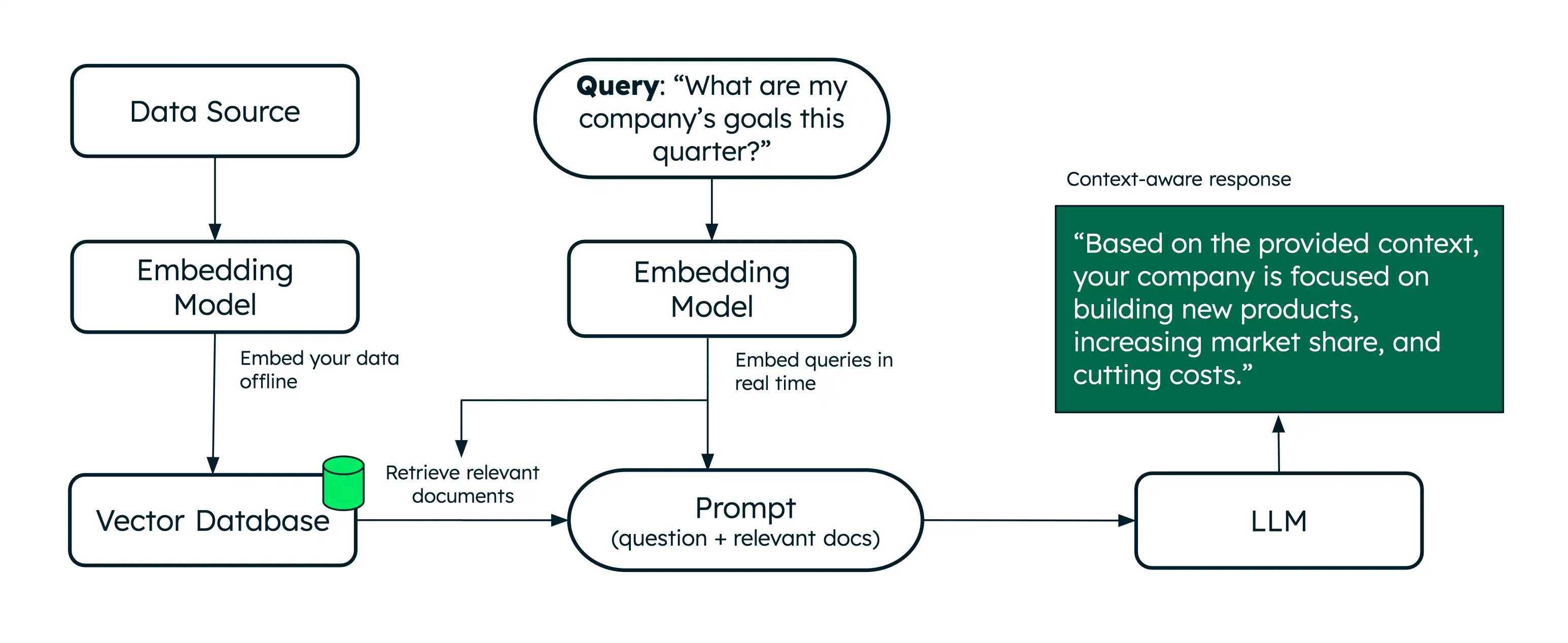
检索增强生成 (RAG) 是一种架构,它使用 语义搜索通过额外数据增强大型语言模型 (LLM),使其能够生成更准确的响应。
语义搜索根据含义检索相关文档,而 RAG 更进一步,将这些检索到的文档作为上下文提供给 LLM。这种额外的上下文有助于LLM对用户的查询生成更准确的响应,从而减少幻觉。Voyage AI提供一流的嵌入和重排序模型,为 RAG 应用程序的检索提供支持。
要在不编写任何代码的情况下试用 RAG,请使用 Playground 构建由 Voyage AI 提供支持的 AI 聊天机器人。要学习;了解更多信息,请参阅聊天机器人演示生成器。
Tutorial
以下教程演示了如何使用 Voyage 嵌入实现RAG。
您还可以通过克隆GitHub存储库。来使用本教程的代码。
为何使用 RAG?
在使用 LLM 时,您可能会遇到以下限制:
过时数据:LLM 在特定点之前的静态数据集上进行训练。这意味着他们的知识库有限,可能会使用过时的数据。
无权访问权限其他数据:法学硕士无权访问权限本地、个性化或特定领域的数据。因此,他们可能缺乏特定领域的知识。
幻觉:使用不完整或过时的数据时,法学硕士可能会生成不准确的响应。
RAG 通过添加检索步骤(通常由语义搜索提供支持)来实时获取相关文档,从而解决了这些限制。提供额外的上下文有助于法学硕士生成更准确的答案。这使得 RAG 成为构建AI聊天机器人的有效架构,而这些聊天机器人可提供个性化、特定领域的问答和文本生成功能。
什么是向量数据库?
向量数据库是专门为存储和高效检索向量嵌入而设计的数据库。虽然在内存中存储向量适用于原型设计和实验,但生产 RAG 应用程序通常需要向量数据库才能从更大的语料库中执行高效检索。
MongoDB原生支持向量存储和检索,因此成为将向量嵌入与其他数据一起存储和搜索的便捷选择。要学习;了解更多信息,请参阅MongoDB Vector Search 概述。
后续步骤
有关其他教程,请参阅以下资源:
要学习如何使用流行的 LLM 框架和AI服务实现RAG,请参阅MongoDB AI集成。
要构建AI助手并实现代理 RAG,请参阅使用MongoDB构建AI助手。