Learn how the convergence of alternative data, artificial intelligence, and generative AI is reshaping the foundations of credit scoring.
Use cases: Gen AI
Industries: Financial Services, Insurance
Products and tools: MongoDB Atlas, Spark Streaming Connector, MongoDB Atlas Vector Search
Partners: LangChain, Fireworks.ai
Solution Overview
This solution shows how the convergence of alternative data artificial intelligence, and generative AI reshapes the foundations of credit scoring. Alternative credit scoring methods offer a more inclusive and nuanced assessment of creditworthiness, and can also overcome the challenges of traditional models.
This solution walks through a sample online credit card application process and shows how MongoDB supports credit scoring. You can also use a similar approach for other credit products such as personal loans, mortgages, corporate loans, and trade finance credit lines.
Challenges with Traditional Credit Scoring
Here are some examples of the challenges and limitations of traditional credit scoring models:
Limited credit history: Many individuals encounter hurdles in the form of limited or nonexistent credit history, making it difficult to prove their creditworthiness due to the lack of historical data.
Inconsistent income: Irregular income, typical in part-time work or freelancing, poses a challenge for traditional credit scoring models, which label individuals as higher risk, leading to application denials or restrictive credit limits.
High utilization of existing credit: Reliance on existing credit, leading to elevated credit utilization ratios, becomes a stumbling block in credit applications as applicants may face rejection or approval with less favorable terms.
Lack of clarity in rejection reasons: A lack of transparency in rejection reasons makes it difficult for customers to address the root cause and enhance their creditworthiness for future applications.
Build the Solution
The following solution shows how MongoDB transforms credit application in the following aspects of the process:
Simplify data capture and processing.
Enhance credit scoring with AI.
Explain the credit application declination.
Recommend alternative credit products.
Simplify Data Capture and Processing
Applying for credit products is often a challenging process for the following reasons:
Application process complexity: The credit card application process involves several time-consuming steps:
Choose a card: First, select a credit card that suits your needs. Research various cards, compare features, and understand their terms and conditions.
Eligibility check: Next, verify if you meet the eligibility criteria set by the bank. These criteria typically consider factors like your credit rating, age, income, and liabilities.
Document submission: Provide documents such as identity proof (like Social Security ID, passport, and/or driver's license), address proof (rental agreement, utility bills), and income proof (bank statements, salary slips, Form 16).
Application form: Fill out the credit card application form. You can do this online via the bank's website, net banking, or by visiting a branch. Some banks require physical documents, although digital processes are becoming more common.
Verification and references: Banks verify the authenticity of your documents and cross-check the information provided. This step also involves computing the probability of delinquency using AI/ML algorithms.
Redundant information collection: Banks often collect redundant data, such as:
KYC details: Even though they have access to your KYC (Know Your Customer) details, they still ask you to submit them repeatedly.
Income verification: Despite having information such as your salary, banking history, utility bills, rental payments, mobile payments and shopping expenditures the bank may request additional proof to verify these details.
Streamlining this process by eliminating redundant requests and leveraging existing data can enhance the user experience.
These application forms increase in complexity with other credit products such as auto loans, mortgages, and equity trade. Within an application form, there could be tabular and hierarchical information that needs to be filled in. MongoDB's flexible developer data platform natively supports JSON data and does not require documents to have the same schema, improving the ability to handle various types of data.
To simplify the data capture process and improve application performance, you can use JSON for the online credit application form. JSON has a structured data representation, which lets you organize the different details you need to store. The flexible data model aligns well with the dynamic nature of credit card application requirements, allowing you to store related data together even if that data does not have exactly the same shape. JSON is also generally understood by other developers, which enables collaboration and makes the data easy to understand at a glance.
MongoDB processes JSON documents well in credit applications due to its native support for JSON-like BSON format.
Enhance Credit Scoring with AI
Leverage Atlas, MongoDB's developer data platform to create a comprehensive user banking profile by combining relevant data points.
Here is an architectural diagram of the data processing pipeline for predicting the probability of delinquency and credit scoring:

Figure 1. Data processing pipeline diagram for credit scoring
The data pipeline for credit scoring a customer involves the following steps:
Data collection: First, the process collects data from various sources such as credit bureaus, open banking, fraud detection systems, and other relevant sources.
Data processing: The collected data is processed using tools like Spark Streaming Connectors to create a unified view of the customer's financial profile and store the same data as a single view in MongoDB Atlas.
Risk profile generation: From this unified view, risk profiles or product suggestions are generated. This involves using statistical methods to perform descriptive analytics and also artificial intelligence (AI) or machine learning (ML) techniques to identify patterns in the data to perform propensity scoring for risk.
Model development: Various machine learning algorithms can be used for credit scoring and decisions. Consider logistic regression, decision trees, support vector machines, and neural networks.
This tutorial employs the XGBoost (Extreme Gradient Boosted Trees) model, a machine learning algorithm commonly used for its predictive performance. The algorithm is a supervised learning method based on function approximation. The algorithm has the following capabilities:
Optimize specific loss functions.
Apply several regularization techniques.
Handle high-dimensional data.
Capture complex patterns for classification and regression.
The model supports its inference outcome, which helps explain the outcome of this predictive model.
Data transformation: Before risk profile scoring is performed, the raw user data is transformed using Spark (or a similar managed analytics framework). Data is collated across multiple sources to create a single and materialized view of data, which can be derived from the MongoDB Atlas collection directly to be used in model development and also various descriptive analysis tasks. This step can also involve model inference.
Decision collection: The final transformed data is populated into a decision collection. This helps banks and financial institutions to support their financial decisions and auditing purposes.
The goal is to accurately assess the creditworthiness of a customer to make informed lending decisions and financial product recommendations. The pipeline is a demonstration of existing risk-scoring pipelines maintained by organizations.
Explain the Credit Application Declination
Understanding the reasons for credit application declination is an essential part of the application. Learn how MongoDB and large language models (LLMs) can explain XGBoost model predictions (the model used in this tutorial).
Here is the architecture diagram explaining credit scoring using an LLM:

Figure 2. Credit scoring architecture diagram using an LLM
The risk profiling ML pipeline employed provides a probability score that defines the risk associated with the profile for product recommendation. This message is communicated back to the user in a standardized way where only the final status of the application is communicated to the end user. In the proposed architecture with LLMs, you can use prompt engineering to explain the reason for the final approved product status with valid reasons explained to the end customer.
Here, you can find the code and example responses. The code to generate a similar message can be done using Python in a Jupyter Notebook. The details on setting up MongoDB Atlas and fetching a connection string are available at this link.
Below is one example of a rejection explanation:

Figure 3. Example of a rejection explanation
This messaging to the customer is a form of explainable AI where the features used in the model to perform risk profiling are ranked and used as a part of the custom prompt to the LLM. This can help generate more descriptive reasons for the end customer to explain their user profile, as shown above. LLMs can also help summarize the list of descriptive reasons to provide a simplified view of the description.
In this demo, there are two approaches used to score the credit application. The credit application status is determined using an ML approach as described in the earlier section with the use of more than 20 credit-related features. Here is a subset of the top 15 most important features:

Figure 4. Feature importance chart
For more details on features used in this demo, look at the source code provided in the credit score GitHub repository.
To demonstrate the difference between the ML versus traditional credit scoring approach, consider how a typical traditional credit scoring method may score the same credit application but typically using only a handful of dimensions. The demo uses several features typically used by leading credit score providers:
The credit applicant's repayment history
Credit utilization
Credit history
Outstanding and number of credit inquiries
Recommend Alternative Credit Products
The credit institution should always try to cross-sell to the customer with a relevant product that meets their needs as they are already engaged in the process and application portal.
Financial institutions can implement a product recommendation system that provides a human-friendly explanation of the rationale for the new recommendation, which would open up new revenue opportunities that legacy systems today do not provide. Providing the rationales can create a personalized relationship with clients and increase the acceptance of the recommended product. Here is an example of a data architecture used to achieve this:

Figure 5. Recommendation system architecture
Atlas Vector Search is a feature that allows you to perform semantic search and generative AI over any type of data. It integrates your operational database and vector search in a unified and fully managed platform with a MongoDB native interface. You can create vector embeddings with machine learning models, then store and index them in MongoDB Atlas for retrieval-augmented generation (RAG), semantic search, recommendation engines, dynamic personalization, and other use cases.
RAG is a paradigm that uses vector search to retrieve relevant documents based on the input query. It then provides these retrieved documents as context to the LLMs to help generate a more informed and accurate response.
The tutorial above mentions technologies that can be used to solve a credit card product recommendation use case. The steps involved in the process are described below:
Load private data: Each credit card product has different offerings. These products change occasionally, and so do the fees charged for various lifestyle benefits such as movie tickets and concierge services. Storing product data in MongoDB as an operational data store (ODS) helps maintain changes yet builds vector indexes alongside.
The large data points can be suitably updated, deleted, inserted, or replaced according to the needs.
The credit card product descriptions are very large, so breaking them into smaller chunks helps retrieve relevant information accordingly.
You can leverage LLMs to shorten the product description to summaries that carry all the salient product features and costs. This change lets you quickly retrieve and recommend the relevant products.
LLM-powered recommendations: In this use case, the LLM is used as a recommender system where the user profile generated in the earlier stage can be used as an input to generate sub-queries that can be used to perform semantic similarity against the stored product vectors in MongoDB Atlas.
Product recommendation with personalized messaging: The recommended products are then used in a custom prompt to the LLM to generate relevant product recommendation summaries for the end user.
This helps the financial institution personalize the recommendation and offer relevant recommendations to the end customer, which drives higher conversion rates.
The product recommendation increases customer engagement and enhances user experiences by improving the "Likely to Recommend" score of the products on offer.
Here, you can find the code and examples of alternative product recommendations. Below are a few examples. You can use Python in a Jupyter Notebook to create code to both generate a product recommendation and customize the product recommendation description.
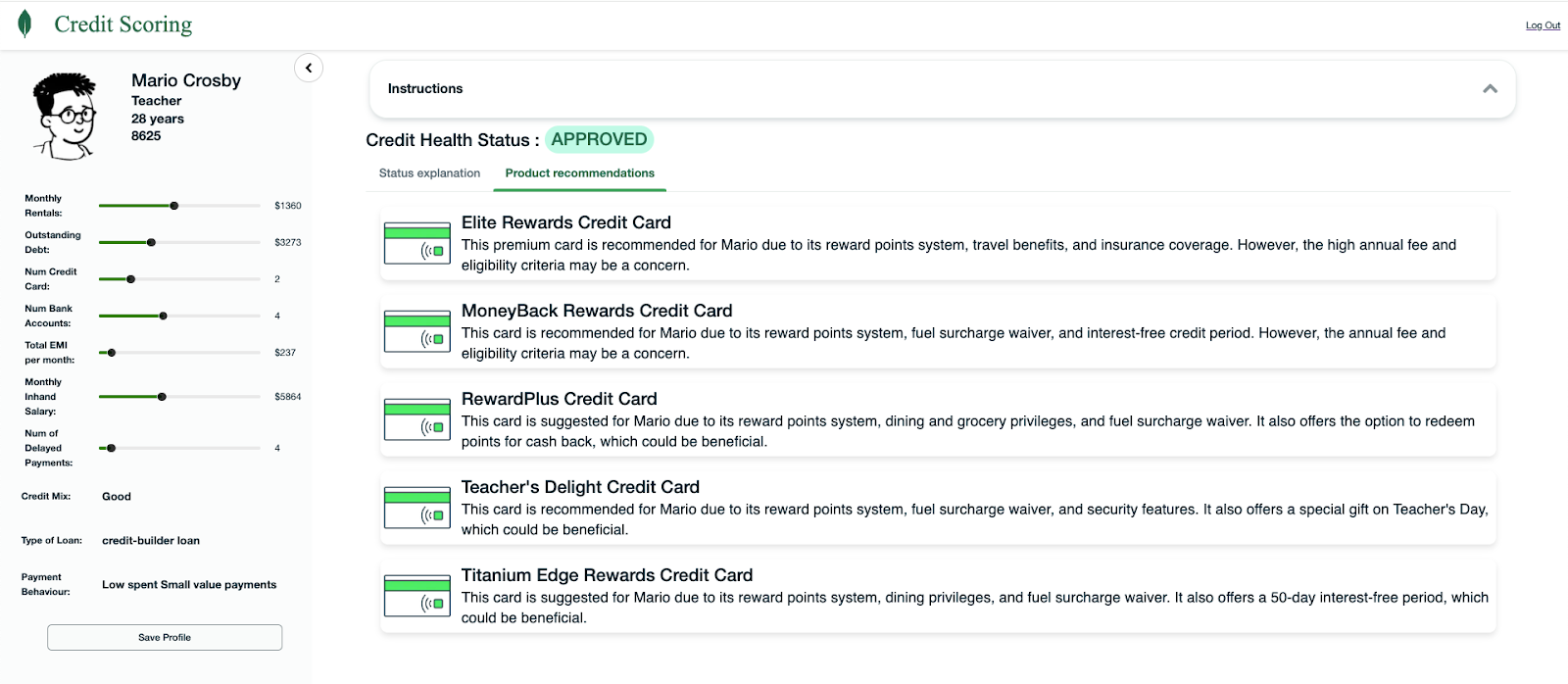
Figure 6. Example of an approved application
In conclusion, credit scoring is undergoing a transformative phase with the integration of generative AI. The synergy of technology and finance is shaping a future where credit decisions are not only accurate but also empowering for borrowers.
The code to demonstrate all the features of MongoDB for building such a solution is available in this GitHub repository. Fireworks.AI, a key AI partner of MongoDB, makes innovating with generative AI faster, efficient, and secure.
Key Learnings
Understand GenAI's capabilities: Synthesize diverse data sets to address the key limitations of traditional credit scoring models.
Provide explainable credit status: Use prompt engineering through LLMs to explain the reason for the credit status with valid reasons communicated to the end customer.
Challenge of traditional credit scoring models: Recognize the need for alternative credit scoring models that can adapt to evolving financial behaviors, handle non-traditional data sources, and provide a more inclusive and accurate assessment of creditworthiness.
Use alternative data: Understand the advantages of alternative data for more accurate credit scoring. This credit scoring model, for example, can be further improved with alternative data points such as utility bills, mobile phone bills, and education history.
Address hallucination: Mitigate hallucination risk by leveraging RAG to ground the model's responses in factual information from current sources, ensuring the model's responses reflect the most current and accurate information available.
Authors
Ashwin Gangadhar, Partner Solutions, MongoDB
Wei You Pan, Industry Solutions, MongoDB
Julian Boronat, Industry Solutions, MongoDB