Kubernetes provides a custom controller, known as the operator pattern or “operator,” for managing stateful applications and custom resources (CRs) within your application. In this article, let’s discuss more about Kubernetes operators in general, and learn about the MongoDB Controllers for Kubernetes (MCK) to effectively manage MongoDB instances in a Kubernetes application.
Table of contents
- What is Kubernetes used for?
- Why do you need a Kubernetes operator?
- What is a Kubernetes operator?
- MongoDB Controllers for Kubernetes
- FAQs
What is Kubernetes used for?
Kubernetes is an open-source orchestrator for containers that lets you better manage and scale your applications. You describe the pods and how they should interact with each other, and Kubernetes handles the rest. With Kubernetes, you can orchestrate many containers across several hosts, scale them as microservices, and deploy updates and rollbacks with zero downtime.
Kubernetes is great at managing stateless applications. You provide a configuration that describes the “desired state” of your deployment, and Kubernetes does the heavy lifting. For example, you can create a pod that spins up your static website. Then, you can instruct Kubernetes to manage three replicas of the application. In the event that a pod fails or goes down, Kubernetes will automatically restart it to achieve the desired state — three running replicas. You can also scale up or down the number of replicas while the application is running.
But what about stateful applications that need a persistent storage solution — for example, database systems like MongoDB, cloud storage services like AWS, or Network Access Storage (NAS) that needs to persist the data and state?
MongoDB is designed to be deployed in its own distributed systems, with replica sets for high availability and sharding for scalability. Kubernetes is designed to be a general-purpose container orchestrator — it doesn't have the knowledge to manage MongoDB topologies. Nor does it know how to provision database users or control other internal aspects of MongoDB. How can we manage a MongoDB cluster or any database using Kubernetes?
Why do you need a Kubernetes operator?
To answer the above questions, let us understand how a stateful application works.
Stateful applications require data to be persisted. If a pod is restarted, it is attached to the same data. For this, Kubernetes provides the StatefulSets API. You can access physical storage devices in the form of PersistentVolume objects, where each volume is associated with a single Kubernetes pod throughout its entire life cycle.
The problem comes when you have to upscale or downscale the application. Removing or adding pods becomes tough, as StatefulSets provide generic methods and may not be able to handle application-specific data migration and replication. Additionally, your application may still require human operators with in-depth knowledge of the specific domain to manage version upgrades and configuration changes.
Kubernetes operators solve this problem by automating the management of applications that require domain knowledge. Kubernetes operators track and manage objects called custom resources (CRs) that extend Kubernetes capabilities with domain-specific functionality.
What is a Kubernetes operator?
Kubernetes Operator is an application-specific controller to simplify the management of complex applications with limited manual intervention. Operators promote self-servicing and automation, leading to faster application development. A Kubernetes operator can automate:
- The process of deploying an application on demand.
- Application installation and upgrades with the required configuration.
- The scaling and monitoring of applications.
- Taking restore and backup of the application state.
- Recovery from failures.
For example, a database operator might extend the Kubernetes API with custom resources such as AtlasProject and AtlasDatabaseUser. These resources are deployed to Kubernetes clusters and are managed by the operator. The operator can be used to configure the number of members in a replica set by reconfiguring the database deployment, thus automating the scaling. The operator can also effectively manage authentication across different environments with a centralized configuration.
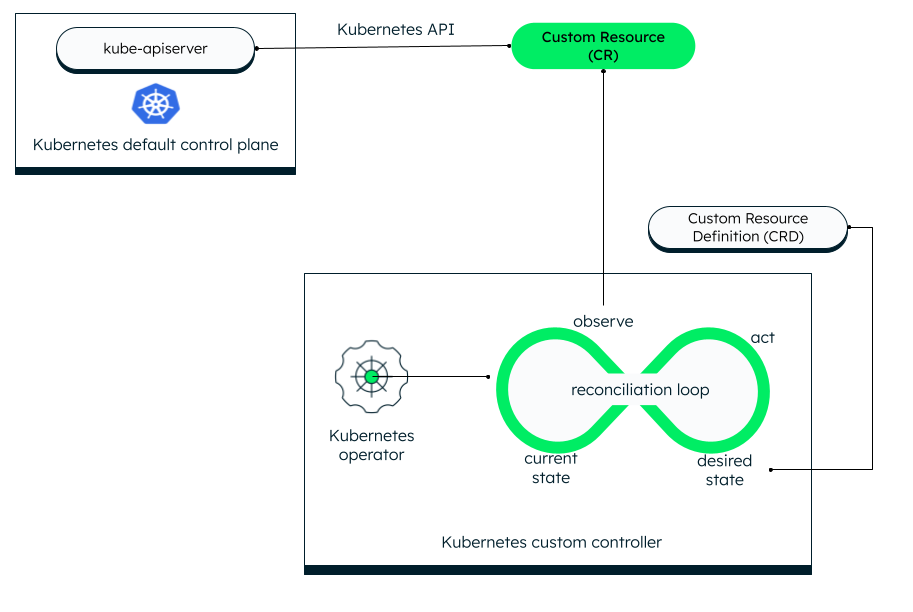
A Kubernetes operator consists of the following components:
Kubernetes API server
The kube-apiserver is a core component of the default Kubernetes control plane that lets you extend the functionality of your application via the Kubernetes API. The API server communicates with other Kubernetes controllers, like the operator controller, to automate application-specific tasks.
Custom resource
A custom resource is anything that your application needs or wants to run but the standard Kubernetes API does not provide by default. It can be an application-specific deployment, service, application configuration, database instance, declarative API (through custom controller), or API objects. While using the Kubernetes operator, the operator acts as a custom controller that watches a custom resource and encodes the domain-specific functionalities in the CR.
Custom resource definition
Kubernetes provides two ways to add custom resources, one of which is through the CustomResourceDefinitions (CRD). Using the other method — API aggregation — requires programming language knowledge, but it allows for more control over the resources.
CRDs are API objects that are easy to create and do not need any programming language knowledge.
When you install a custom resource into the Kubernetes API using CRD, the Kubernetes API server (kube-apiserver) creates a new RESTful resource path (endpoint). You can then create and manage custom objects through this endpoint URL. Custom objects contain custom fields stored as structured data in the custom resource. CRDs contain all the information on the structure, schema (validation), and behavior of a CR.
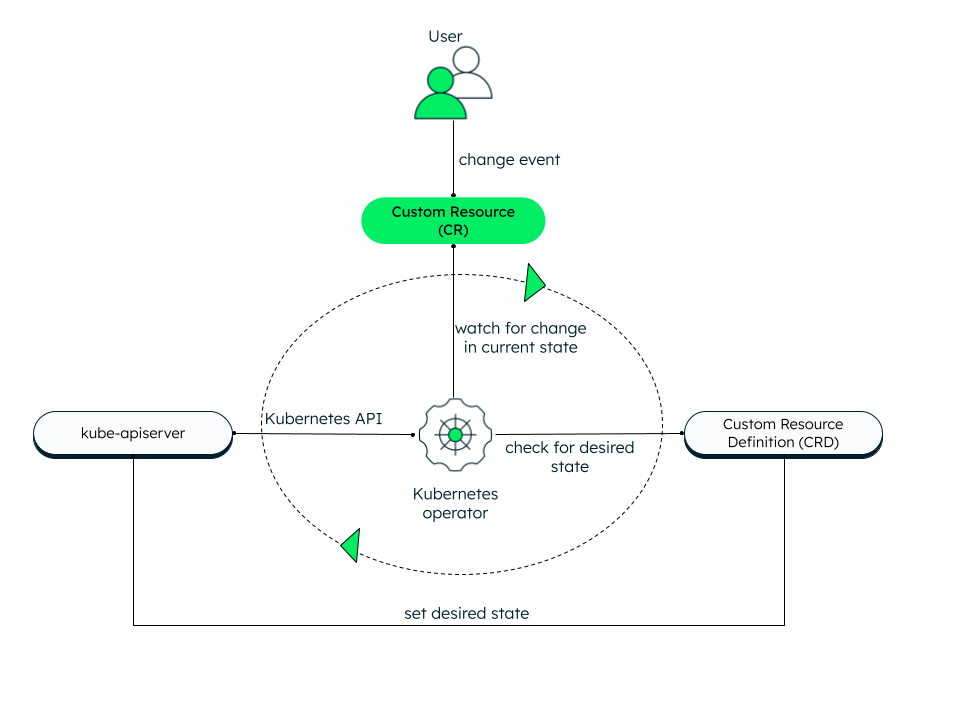
Reconciliation loop (Kubernetes control loop)
The reconciliation loop is an infinite loop that watches for change events in a custom resource. If there is an event, the Kubernetes operator’s custom controller checks for the declared desired state from the CustomResourceDefinition. If the actual state in the CR does not match the desired state, the operator makes the necessary changes to set the desired state in the cluster/application using the Kubernetes API. The Kubernetes operator can track events like add, update, and delete.
For example, if the operator has to perform a resource cleanup and notes that the actual state of the resource does not match the desired state, it can perform tasks like adjusting the configuration, creating a backup, restarting the pod, or deleting a service.
MongoDB Controllers for Kubernetes
Although you can create your own Kubernetes operator using the Operator Framework and the Operator SDK, many companies provide ready-to-use operators. It is beneficial to use the existing operators for easy maintenance, community support, and faster application development. With MongoDB Controllers for Kubernetes (MCK), your applications can self-manage MongoDB instances in Kubernetes.
MongoDB officially supports two Kubernetes operators:
Atlas Kubernetes Operator (AKO)— allows you to create and manage your cloud-based MongoDB Atlas projects and clusters
MongoDB Controllers for Kubernetes (MCK) — represents a merge of the previous MongoDB Community Operator and the MongoDB Enterprise Kubernetes Operator; enables MongoDB standalone instances, replica sets, and sharded clusters to be managed by Kubernetes; can also install and manage the Ops Manager
All of the operators make it possible to integrate MongoDB with your Kubernetes environment and the apps that you run there.
To create a forever-free cluster in MongoDB Atlas and control it from Kubernetes, check out the quick start guide.
